基于Neo4j的电力大数据建模及分析
2016-05-25马义松武志刚
马义松, 武志刚
(华南理工大学电力学院, 广东 广州 510640)
基于Neo4j的电力大数据建模及分析
马义松, 武志刚
(华南理工大学电力学院, 广东 广州 510640)
电力大数据的处理离不开大数据技术的支持,如何存储电力大数据并从中挖掘出有价值的信息来促进电网的发展是当前的研究热点。本文首先从数据存储方式和数据检索功能两方面对图数据库Neo4j进行详细介绍;然后提出基于Neo4j构建电网的全景数据库,根据电力网络拓扑建立设备映射表,将目前电网中分散、隔离的海量数据有序地整合起来,同时利用Neo4j自身封装的图论算法提出基于图论的电力数据聚类分析方法;最后基于Neo4j数据库分析了两个具体的算例,对Neo4j数据库的信息检索性能和数据聚类分析功能进行了测试。
电力大数据; Neo4j; 数据分析; 网络拓扑分析
1 引言
随着电网智能化、信息化不断发展,电力数据采集粒度越来越小,数据类型越来越多,精细化程度越来越高,电力大数据环境正在形成[1,2]。大数据为电力企业带来了新的发展机遇,大数据能够实现资源的优化配置,帮助建立更有效的用户需求侧管理系统,提高电网对灾难的预警和应对能力等。另一方面海量数据的产生也给电力系统信息平台建设带来巨大挑战[3-5],如何解决数据量剧增、数据结构复杂化带来的瓶颈是当前的研究热点。
电力数据根据数据类型的不同可以细分为结构化数据和非结构化数据,现代电网企业数据中非结构化数据体量呈爆炸性增长趋势,然而传统电网信息平台数据存储大多采用关系数据库,随着数据规模的膨胀与数据复杂程度的增加,数据平台已无法充分满足电网数据处理的需求。关系数据库不能很好地适应电力数据的动态性,易导致数据冗余和性能损失等问题,也不能支持类似“连接某设备的设备有哪些”等多层次的复杂数据结构查询。考虑到现代电力系统规模庞大、结构复杂,对电力系统复杂演化网络模型做实质性的研究需要一个更灵活高效的数据平台作为基础,这可借助于在IT业界中长期存在的另一类数据库模型NOSQL[6]。文献[7]提出利用NOSQL的列族存储技术Hadoop[8]对电力大数据进行处理,Hadoop能够对海量数据进行分布式处理,但Hadoop仅适用于数据能够被分解为键值对存储、且不需要考虑数据之间隐性结构关系的对象,而电网数据中往往包含着各种隐性结构关系,其数据结构往往和数据本身一样重要[9],而Hadoop并未显式利用电网的拓扑信息。
针对电力大数据动态变化且数据内在联系复杂的特点,本文提出利用图数据库Neo4j[10]对电力大数据进行建模和分析。文中首先介绍了Neo4j的数据存储方式和数据检索功能,然后阐述基于Neo4j构建电网全景数据库的一般方法,介绍其图论算法并提出基于图论的数据聚类分析功能,最后基于Neo4j分析了具体的电网算例,对其信息检索性能和数据聚类分析功能进行测试。
2 图数据库Neo4j
Neo4j是基于Java的高性能、高可靠性、可扩展性强的开源图数据库,完全兼容ACID,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。作为一种新兴的数据库技术,图数据库的内核是一种极快的拓扑引擎,重点关注大数据量以及数据内部复杂依赖的处理。
2.1 基于Neo4j的数据存储
Neo4j的信息建模包括节点、边和属性三种构造单元,如图1所示。每两个节点间可存在多条不同方向、类型的边,并且所有节点和边均具有可变的属性列表。
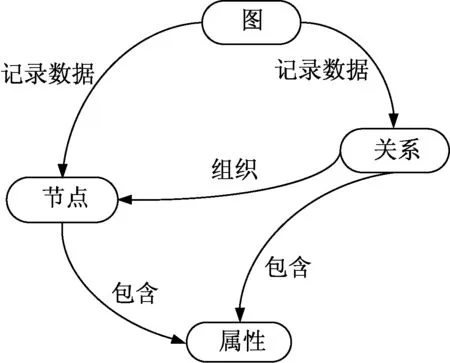
图1 Neo4j构造单元Fig.1 Structural unit of Neo4j
图数据库的创建和维护简单,每个节点对应于关系数据库中的一个记录,节点和边的属性则相当于记录中的字段,属性内容和个数可以动态变化,节点之间的边也可以自由删减并且不会影响已有数据结构的逻辑,这对于关系数据库来说是异常困难的[11]。
尽管电力系统的很多元件的模型都可以给出固定不变的数据结构,但也存在大量的元件类型需要经常改变其数据结构,甚至可能涌现出以前从来没有在电力系统里出现过的新的元件类型,再加上电网数据的动态变化经常会引起字段变化,增删字段会引起表的重构并导致关系数据库性能的耗损,频繁的字段操作更会造成存储结构的零碎化,使得访问性能下降。Neo4j中电网数据动态变化时则只需要修改相应节点、边的属性,有效地解决了关系数据库应对数据动态变化时能力不足的问题。
2.2 基于Neo4j的数据检索
关系数据库在遍历具有图数据结构的数据并抽取信息的能力上比较弱,互相链接数据的查询会导致大量的表链接(即所谓JOIN操作)。Neo4j可直接存储电力网络拓扑结构而不需将其映射成二维表,数据结构关系在录入时就已经建立完毕,对数据网络遍历的时间复杂度仅为O(n),利用图数据库的高度可扩展性可准确体现电力系统的演化特征。
Neo4j中集成了Traversal数据遍历接口以及Lucene数据索引功能,不仅能以相同速度遍历所有节点和边,而且遍历速度几乎不受构成图形的数据量影响,有利于实现快速的数据网络遍历。而且,Neo4j不仅提供了类似联机分析处理(Online Analytical Processing, OLAP)的分析方法,还集成了Dijkstra、A*等高性能的图论算法,可提供高性能的特征遍历、最短路径搜索等功能,这在基于二维表存储的关系数据库或者基于MapReduce并行分布处理的Hadoop等数据库技术中几乎是不可能实现的。本小节介绍的Neo4j具备的各类遍历算法在第3节的数据存储与第4节的数据分析中将得到应用。
3 基于Neo4j的电力数据整合
3.1 电力信息资源现状
电力信息化经过几十年的发展,已经积累了大量电力系统生产、运行管理和电力市场运营等方面的数据,具有良好的数据基础。但是由于各个时期的技术水平不同以及标准规范的差异,电力企业间大都是竖井式的、孤立存储的业务数据,甚至形成信息孤岛[12]。
电力大数据的信息价值具有隐蔽性,数据的共性和网络的整体特性往往隐藏在不同类型、分散存储的业务数据中,因此电力大数据的处理应该是对跨地域、跨时间、跨空间信息资源所构成的全景数据进行分析。
3.2 基于Neo4j数据资源的整合
电力企业各方面的业务数据实际上描述的是同一个实际电网,只是由于业务需求不同,对电网的映射方式及提取的信息有所差异。电网具有典型的拓扑特性,根据电网的拓扑结构特征建立设备映射表是进行电网数据整合的关键,而以图引擎为内核的图数据库Neo4j非常适合作为构建统一数据平台的载体。基于Neo4j建立设备映射表只需将设备抽象为节点,设备连接关系抽象为边,设备的电气属性和连接属性抽象为节点和边的属性(实际应用中需要更加详细的标准规范)。
Neo4j数据库的复用性和扩展性强,当网络中新增某个设备或者电气元件特性动态更新时无需进行大量修改,符合未来智能电网发展的需求;同时Neo4j中通过将关系型数据库中使用连接表来表达的连接和从属关系抽象为一个基本单元表达,能大大提高处理复杂关联数据时的运行效率。
基于Neo4j进行电力数据建模时可以遵循国际通用的公共信息模型(Common Information Model,CIM),以Neo4j数据库构建数据接口体系,从而互联不同的电网系统数据,如图2所示。数据建模具体描述规则如下。
(1)点:表示一个具体设备,根据研究的数据粒度大小不同而不同,即按实际需求的不同可以是一个变电站也可以为一个开关。
(2)边:表示设备间的关联,可以带方向。例如电气设备A和B是单向连通的话为A=>B或B=>A,双向连通则为A<=>B。
(3)属性:表示点和边的属性,不做任何具体约定且属性可以动态更新,适用于处理电网实时变化的复杂数据。所有的设备信息都转化为节点和边的属性存储到图数据库。
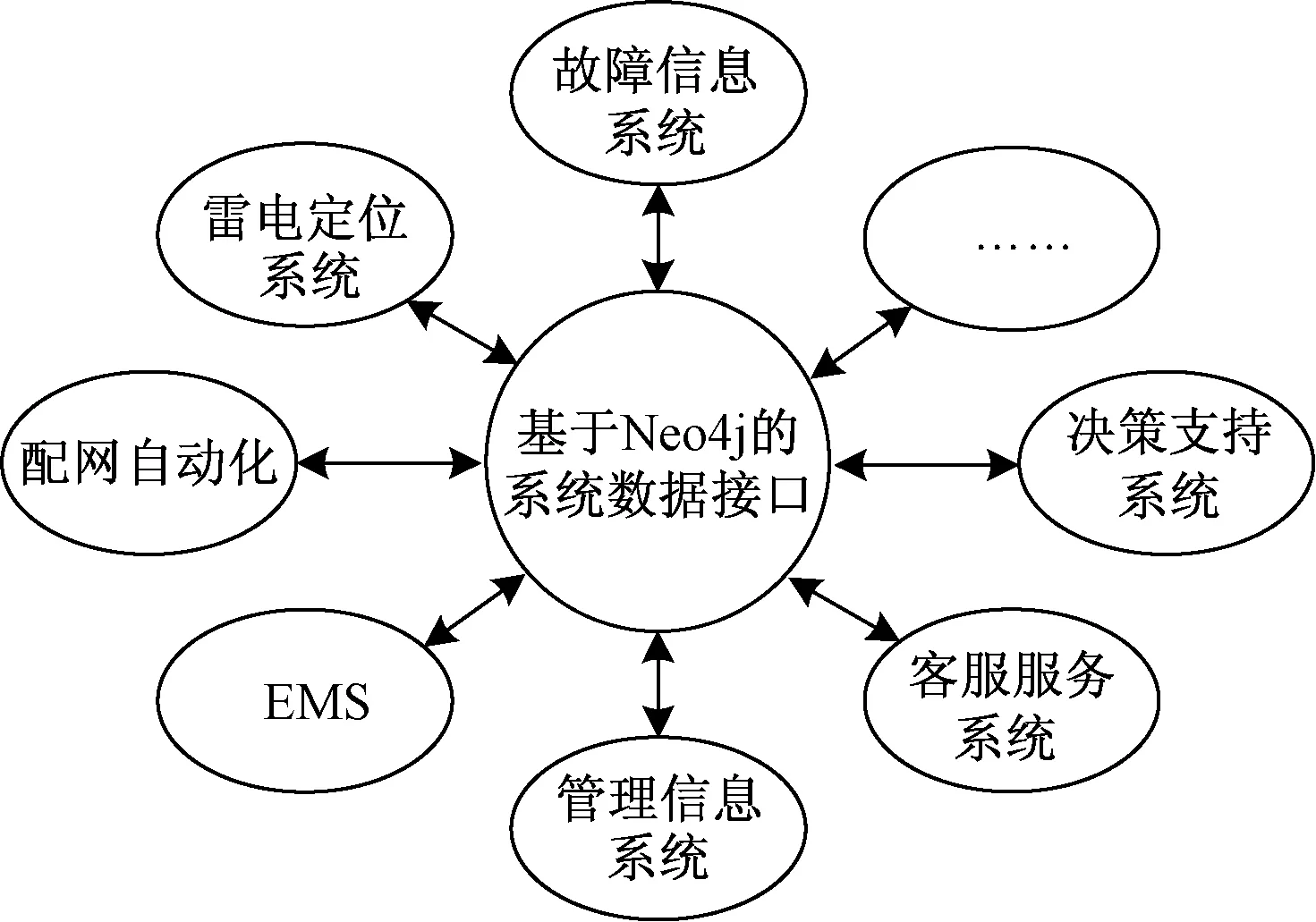
图2 基于Neo4j的系统接口体系Fig.2 Data interface architecture based on Neo4j
基于Neo4j进行电网数据整合不仅能够保证数据的完整性,而且能够兼顾电网的拓扑特性[13],有利于从图论的角度挖掘数据网络的基本参数,如复杂网络平均特征路径长度、节点度及度的分布、聚类系数、节点介数等特征参数。利用Neo4j高效的数据检索性能和丰富的图论算法功能还可以扩展出多种具有电力行业特色的拓扑算法[14,15],如基于节点连通性遍历的电网故障影响范围分析等。
4 基于Neo4j电力大数据聚类分析
目前大多数传统的聚类方法需要对电力数据进行预处理并人为给定聚类数目,聚类结果的有效性对指定的初始聚类中心较为敏感,并且对大规模电网数据的处理性能往往不能满足要求。本节基于图数据库Neo4j的图数据存储结构提出一种电力大数据聚类方法,动态拟合数据对象之间的相关性。该聚类方法无需预先深入认知数据和给定聚类个数,通过对集成的各类电力数据对象进行相似度的计算,从而实现关联度分析。本节提出的聚类方法主要分为两个部分:首先根据数据特征,计算数据对象之间的相似度;其次界定核心节点,从而为聚类提供参考的节点强度,并指定核心节点的强度为聚类时的核心度。相似度和核心度确定后就可进行聚类分析。
4.1 相似度计算
基于图数据库拟合数据对象间的相似度,将数据的聚类问题转换成网络的模块化问题。计算相似度之前需先计算数据对象间的相异度,根据对象间的不匹配率进行相异度计算,如式(1)所示:
(1)
式中,d(i,j)代表数据对象i和j之间的相异度;m为匹配的数目,即i和j取值相同状态的数目;p为全部数据的数目。在得到对象间的相异度后需将其转换为相似度,为计算方便需将其进行适当规范化处理。定义规范化的对象相似度计算如式(2)所示:
(2)
式中,dmax为数据集中所有对象间相异度的最大值;dmin为数据集中所有对象间相异度的最小值;相似度满足条件:0≤s(i,j)≤1。
4.2 节点强度计算
在空间聚类过程中,数据对象间的相似度越大,该节点的重要性越明显,在局部范围内具有较大的凝聚力。对一个数据网络G(V,E,S),其中V={v1,v2,…,vn}表示节点集合,E={e12,e13,…,eij,…}表示边集合,S={s12,s13,…,sij,…}表示节点的相似度集合,定义节点j的强度如式(3)所示:
(3)
F(j)取最大值的节点即该研究状态下数据对象的核心节点。以强度最大的节点作为初始对象,以其节点强度作为核心度,进行第一次聚类,然后将属于这个聚类的节点及其边移除,采用同样的方法依次处理数据网络的其他节点,最终完成聚类过程。
5 实际案例
本文首先在图数据库Neo4j和关系数据库MySQL[16]中分别建立南方A地区输电主网(下称A输电网)和南方B地区输电主网(下称B输电网)的数据模型,对Neo4j和MySQL进行信息检索性能的测试对比,并基于Neo4j统计数据模型的拓扑特征参数;然后以某地区45个220kV变电站综合负荷特性数据为研究对象,分别采用本文基于图论的数据聚类分析方法和模糊C均值算法进行聚类性能对比分析。结果表明基于图数据库Neo4j的电力数据处理不仅具备高效的信息检索能力,而且有更优的聚类性能和分类精度,在大数据研究背景下该优势将更加明显。
5.1 检索性能对比及网络特征参数分析
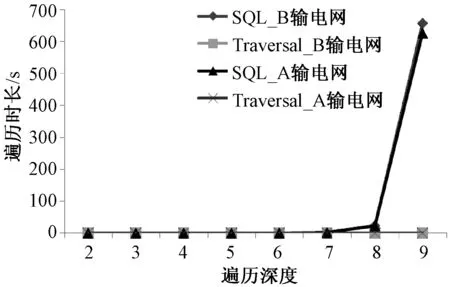
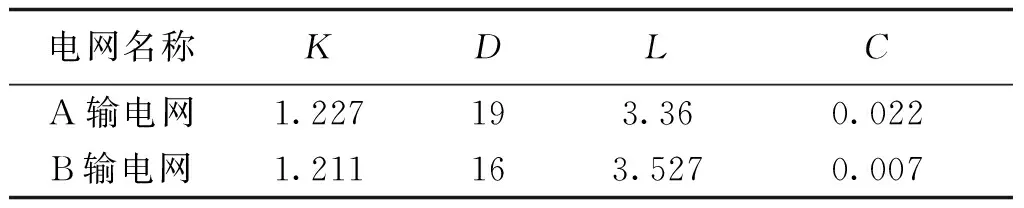
表1为A输电网和B输电网的数据模型信息。利用Neo4j的Traversal遍历接口和MySQL的SQL语句分别进行数据结构查询,查询分别执行10次,去除最短时间和最长时间,取其他8次查询时间的平均值作为查询时间。
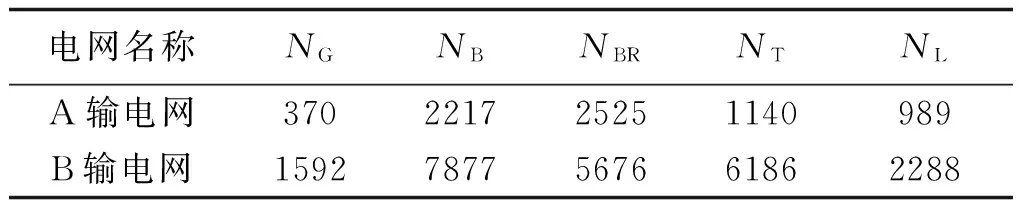
表1 电网数据模型参数
注:NG、NB、NBR、NT和NL分别代表电网发电机节点数、母线节点数、线路支路数、变压器数和负荷节点数。
Neo4j中Traversal遍历语句如下所示,其中参数k为遍历深度(即起始点的第k层邻接点):
Path=Traversal.description().breadthFirst().Relation-ships(RelTypes.OUT,Direction.BOTH).evaluator(Evaluators.excludeStartPosition()).evaluator(Evaluators.toDepth(k)).traverse(node);
MySQL主要的SQL查询语句如下所示,其中参数k为遍历深度:
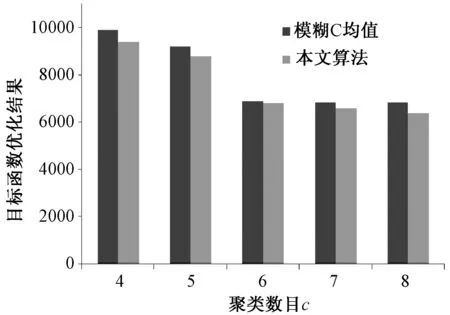
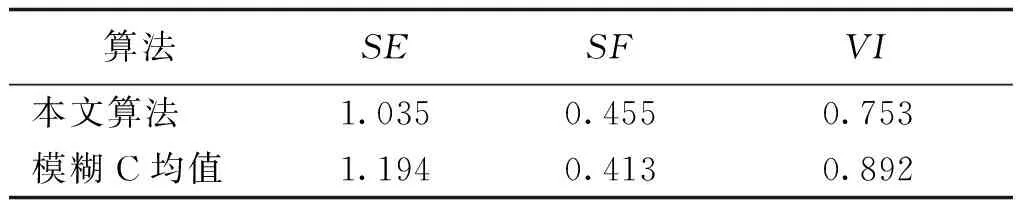
for (inti=1;i sql="select IF(bus.BusID=branch.I_ID,branch.J_ID, branch.I_ID)as ID from branch JOIN bus ON bus.BusID=branch.I_ID or bus.BusID=branch.J_ID WHERE bus.BusID IN ("+ sql +")";} A电网中以525kV节点LB-H为遍历起始点,B电网中则以20kV节点LuoLa3为遍历起始点,遍历时长与遍历深度的变化关系如图3和图4所示。由图可见,遍历深度较低(低于6)时Traversal和SQL的检索性能相当,两者遍历时间接近;但随着遍历深度增加,SQL语句的遍历时长明显增加,Traversal则相对稳定,由图4可见遍历深度为9时Traversal的时长已远远低于SQL。图数据库这一优点在进行电力系统连锁故障分析等特定任务时显得尤为重要。 图3 查询结果(最大遍历深度6)Fig.3 Query results (biggest traversal depth of 6) 图4 查询结果(最大遍历深度9)Fig.4 Query results (biggest traversal depth of 9) 表2为电网的拓扑特征参数,基于Neo4j统计出了数据模型的平均度数、平均特征路径长度和聚类系数等特征参数。 表 2 电网拓扑特征参数 注:K、D、L和C分别代表电网的平均度、网络直径、平均特征路径长度和聚类系数。 限于篇幅,只给出基于Neo4j图论算法的平均特征路径长度程序,如下所示。 public Path findShortestPath(Node fnode, Node tnode,int N) {PathFinder path=finder.findSinglePath(fnode, tnode); 实验组患者主诉良好达到100%(55例),并表示愿意再次接受检查治疗;常规组患者主诉良好,且表示愿意再次接受诊疗的患者占比76.36%(42例),两组数据比较具有统计学意义(P<0.05,X2=14.7423)。 return path;} shortestPath.add(findShortestPath(fnode, tnode,N)); for (Path shortest: shortestPath) {count=count+shortest.length();} APL=2*count/((N-1)*N); 一般认为介数和度数较高的联络节点在保障电网连通性的同时有导致连锁故障发生的潜在风险[17]。Neo4j能够根据电力系统实时工作状态形成相应的数据模型,并利用自身优越的拓扑检索功能找出这些存在风险的节点,由于算例中节点数较多,本文程序设置以找出风险最大的5个节点为目标,运行结果如表3所示。 表3 风险节点检索 利用Neo4j能够快速地实现电网数据模型的搭建并对其进行特征参数的分析,这对于大型电网的脆弱性评估和研究电网中故障传播的内在机理具有重要的意义[18,19]。 5.2 聚类性能对比 表4为某地区变电站六大用电行业的典型负荷特性数据,该数据为标准化后的负荷容量百分比。 表4 综合负荷特性数据 聚类数目c是影响模糊C均值算法性能及最终聚类结果的关键参数,本文算法不需预先给定聚类个数,而是通过聚类过程得出该参数。本文将从“农业~居民用电”6种负荷中分别抽取k(2≤k≤6)种类型进行聚类分析,并利用本文算法计算得到不同的聚类数目c,再根据得到的聚类数目设置模糊C均值算法的聚类数目c。针对不同c值,应用二种算法分别仿真50次,去除最大值和最小值,取其他48次的平均值作为目标函数优化结果。两种算法的目标函数优化结果如图5所示。 图5 优化结果对比Fig.5 Comparison of optimal values 由图5可见,在相同的聚类数目下,本文算法的目标函数最优解始终优于模糊C均值算法,聚类性能更加高效,对不同聚类数目的适应能力更强。为了检验聚类结果的可信度,本文在相同的聚类数目c=5时,分别计算二种算法的分离熵SE、分离系数SF和模糊划分有效性VI指标检验聚类结果的有效性,如表5所示。 表5 有效性评价 较好的聚类算法应该使得各聚类中心间的距离尽量大,各样本元素与其对应的聚类中心距离尽量小,即SE接近0或1、SF接近1并且VI接近0时聚类结果越有效,分类更加精确。由表5可见本文算法的聚类结果更加可信。 本文提出利用图数据库Neo4j作为电网的统一数据平台对电力大数据进行存储和分析。Neo4j可以处理内在关系复杂、动态变化的数据,同时能够高效地执行多重操作。Neo4j中还集成了多种高性能的查询方法,能够对数据模型中的风险节点等关键信息快速地进行检索,这解决了传统关系数据库应对电力大数据性能不足的问题,同时基于数据库图存储的结构提出的数据聚类方法能够实现电力大数据的快速聚类分析。本文分别在MySQL和Neo4j中搭建了两个输电网的数据模型,并进行了相应的信息检索,分析了其特征参数,验证了Neo4j对数据网络参数的数据检索和信息提取能力的高效性。此外,通过对某地区45个变电站负荷数据的聚类对比分析可得,本文提出的基于图论的聚类方法具备更高效的聚类性能和更精确的分类效果。Neo4j是基于Java开发的开源数据库,兼容多种操作平台,结合其他功能强大的数据分析工具可以进一步开发基于Neo4j的电力大数据处理技术,在电力系统大数据分析领域具有广阔的应用前景。 [ 1] Xi Fang, Satyajayant Misra, Guoliang Xue, et al.Smart grid, the new and improved power grid: A survey [J]. IEEE Communications Surveys and Tutorials (COMST), 2012, 14(4): 944-980. [ 2] 张文亮,汤广福,查鲲鹏,等 (Zhang Wenliang, Tang Guangfu, Zha Kunpeng, et al.).先进电力电子技术在智能电网中的应用 (Application of advanced power electronics in smart grid) [J].中国电机工程学报(Proceedings of the CSEE), 2010, 30(4):1-7. [ 3] 宋亚奇, 周国亮, 朱永利 (Song Yaqi, Zhou Guoliang, Zhu Yongli). 智能电网大数据处理技术现状与挑战(Present status and challenges of big data processing in smart grid) [J]. 电网技术 (Power System Technology), 2013, 37(4): 927-935. [ 4] 徐彭亮, 何光宇, 梅生伟, 等 (Xu Pengliang, He Guangyu, Mei Shengwei, et al.). 上海AEMS与EMS数据交换平台的设计和实现(Research of data exchange between AEMS and EMS) [J]. 电工电能新技术 (Advanced Technology of Electrical Engineering and Energy), 2014, 33(1): 74-77. [ 5] 毛鹏, 李颖, 李健, 等 (Mao Peng, Li Ying, Li Jian, et al.). 遵从OSI体系的CIM数据一致性测试框架研究(Research on framework of CIM conformance test based on OSI architecture) [J]. 电工电能新技术(Advanced Technology of Electrical Engineering and Energy), 2013, 32(1): 81-84. [ 6] Not only structured query language, NOSQL [DB/OL]. http://www.NOSQL-database.org/. [ 7] Lin Lu, Hongbin Dong, Chao Yang, et al. A novel mass data processing framework based on Hadoop for electrical power monitoring system [A]. 2012 Asia-Pacific Power and Energy Engineering Conference (APPEEC)[C]. Shanghai, China, 2012. 1-4. [ 8] Apache software foundation, Apache Hadoop [DB/OL]. http://hadoop.apache.org/. [ 9] 蔡泽祥, 王星华, 任晓娜 (Cai Zexiang, Wang Xinghua, Ren Xiaona). 复杂网络理论及其在电力系统中的应用研究综述 (A review of complex network theory and its application in power systems) [J]. 电网技术 (Power System Technology), 2012,36 (11): 114-121. [10] Neo4j Org. The Neo4j mannual v2.1 - SNAPSHOT [DB/OL]. http://docs.neo4j.org/chunked/snapshot/. 2014-04-09. [11] 王余蓝 (Wang Yulan). 图形数据库NEO4J与关系据库的比较研究 (Comparison of graphic database NEO4J and relational database) [J]. 现代电子技术(Modern Electronics Technique), 2012, 35(20): 77-79. [12] Robin Hecht, Stefan Jablonski. NoSQL evaluation: A use case oriented survey [A]. Proceedings of 2011 International Conference on Cloud and Service Computing [C]. 2011. 336-341. [13] 石俊杰, 李毅松, 彭清, 等 (Shi Junjie, Li Yisong, Peng Qing, et al.). 国家电网公司调度系统数据整合总体方案的思考 (Consideration on the overall scheme of data integration of the China State Grid Corp dispatching system) [J]. 电力信息化 (Electric Power Information Technology), 2006,4 (6): 28-31. [14] 吴文传, 张伯明 (Wu Wenchuan, Zhang Boming). 基于图形数据库的网络拓扑及其应用 (A graphic database based network topology and its application) [J]. 电网技术(Power System Technology), 2002, 26(2): 14-18. [15] 蒋厚明, 孙昊, 孔震 (Jiang Houming, Sun Hao, Kong Zhen). 一种基于图形数据库的快速电力网络拓扑分析方法 (A quick electric network topology technology based on graph database) [J]. 计算机系统应用(Computer Systems & Applications), 2012, 21(12): 173-176. [16] Oracle Corporation. MySQL community server (GPL) [DB/OL]. http://www.mysql.com/downloads/. [17] 丁明, 韩平平 (Ding Ming, Han Pingping). 基于小世界拓扑模型的大型电网脆弱性评估算法 (Small-world topological model based vulnerability assessment algorithm for large-scale power grid) [J]. 电力系统自动化 (Automation of Electric Power Systems), 2006, 30(8): 7-10. [18] 曹一家, 陈晓刚, 孙可 (Cao Yijia, Chen Xiaogang, Sun Ke). 基于复杂网络理论的大型电力系统脆弱线路辨识(Identification of vulnerable lines in power grid based on complex network theory) [J]. 电力自动化设备 (Electric Power Automation Equipment), 2006, 26(12): 1-5. [19] 陈为化,江全元,曹一家,等 (Chen Weihua, Jiang Quanyuan, Cao Yijia, et al.). 基于风险理论的复杂电力系统脆弱性评估 (Risk-based vulnerability assessment in complex power system) [J]. 电网技术 (Power System Technology), 2005, 29 (4): 12-17. Modeling and analysis of big data for power grid based on Neo4j MA Yi-song, WU Zhi-gang (Electric Power College, South China University of Technology, Guangzhou 510640, China) The process of big data for power grid requires the support of big data technology. The topics such as how to store the big data for power grid and how to mining out valuable information to promote the development of the grid are very hot currently. In this paper, both data storage and data retrieval function of the graph database Neo4j are introduced in detail firstly. Secondly, a method to build panoramic database based on Neo4j is proposed, which can integrate the scattered and isolated data in power grid with large-scale orderly according to the device mapping table based on power network topology. Furthermore, with the help of graph theory algorithm packaged in Neo4j, clustering methods for analysis of big data in power grid can be put forward. Finally, two real power grids are analyzed based on Neo4j, while the performance of information retrieval and data clustering analysis with Neo4j is tested as well. big data for power grid; Neo4j; data analysis; network topology analysis 2015-03-19 国家高技术研究发展计划(863计划)资助项目(2012AA050209) 马义松(1990-), 男, 广东籍, 硕士研究生, 研究方向为电力系统运行与控制; 武志刚(1975-), 男, 吉林籍, 副教授, 博士, 研究方向为电力系统仿真、 复杂网络理论在电力系统的应用。 TM769 A 1003-3076(2016)02-0024-07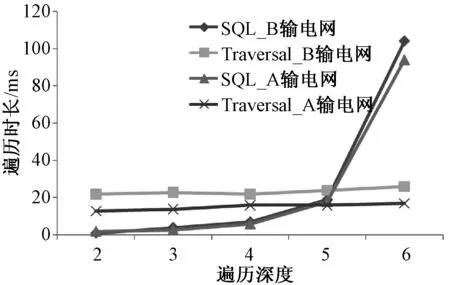

6 结论
