基于单类支持向量机的异常声音检测
2016-05-25陈志全乔树山
陈志全,杨 骏,乔树山
(中国科学院大学 微电子研究所,北京 100029)
基于单类支持向量机的异常声音检测
陈志全,杨 骏,乔树山
(中国科学院大学 微电子研究所,北京 100029)
提出基于单类支持向量机的异常声音在线检测算法。该算法针对公共场合正常的环境声音,训练一个单类支持向量机模型,用来判断声音是否属于正常的环境声音,若不是则属于需要进一步识别的异常声音。采用窗长2秒的滑动窗对声音进行分窗,对每一个窗内的声音分帧并提取梅尔倒谱系数,短时能量,频谱质心,短时平均过零率等特征。采用基于帧之间互相关系数的方法对声音自动分段。最后对分段声音的判别结果进行中值滤波。当有连续多个帧被判别为异常时判定有异常声音出现。最后检验了算法在地铁背景条件下六类异常声音的漏检率和每小时误检次数,结果表明算法能有效检测到异常声音的发生而且误检次数较低。
单类支持向量机;异常声音检测;特征提取;音频监控
近些年随着信息化和网络化技术的发展,安全监控在国防和社会安全中的作用越来越突出。现在的监控系统主要由摄像头采集监控区域的影像视频信息来完成监控,但是仅仅基于视频的监控系统有其自身的一些缺陷。首先:一个摄像头只能监控一个方向,要做到更好的实时监控,需要摄像头能够移动到事件发生的区域;其次,视频监控容易受光线影响,同时在一些私人场合不利于保护个人的隐私;最后,图像是二维信号,处理相对复杂,计算量较大。与图像相比,声音信号具有很多优点:是一维信号,复杂度低;分布广泛,易获取;包含信息量大。区域内的异常声音能够有效的揭示异常状况以及突发事件。这些优点可以很好的弥补视频监控的不足。通过检测和识别环境中的声音信息,监控系统对特定区域或区域进行重点关注,监控会更加的自动化智能化。这对于智能监控以及安全防护具有极其重要的意义。
音频监控主要由两个阶段构成:异常声音检测;异常声音识别。异常声音指在正常环境下不应该发生的声音如:枪声,尖叫,爆炸,玻璃破碎声等。当前,关于异常声音监控的研究主要关注于几类异常声音的分类。文献[1]针对典型的异常声音的频谱分布特性,提出一种矫正过滤波器通带位置,大小以及类型的MFCC。这种方法能够改善某类声音的识别率,但是当声音类别增加时,并不能有效的获取所有异常声音的频谱分布状况。文献[2]提出将MFCC以及短时能量作为混合特征训练高斯混合模型(Gauss Mixture Model,GMM),能够一定程度提高声音的识别率,文献[3]在研究枪声的发生原理,频谱分布特点的基础上,提出基于经验模态分解方法的枪声特征的提取方法,提高了公共场所枪声的识别率,但是只能针对枪声这一大类声音。
在异常声音检测方面,文献[4]采用支持向量机(Support Vector Machine,SVM)检测是否有欢呼声和掌声,文中将音频按0.5 s滑动分窗,并对每一个窗内的判别结果进行平滑。最终获得的F-value为79.71%。文献[5]采用4个OC-SVM分别对四类异常声音进行建模,将待识别的声音输入4个模型,比较模型输出选择其中一个作为声音的类别,其实质是一个声音识别算法,当声音种类较少时能够有效识别声音的种类,但种类较多时很难比较模型之间的输出进而得出正确的分类。文献[6]针对室内异常声音检测问题,提出一种基于集成学习的异常声音检测方法:先将声音按帧提取特征,然后将每一帧声音按内容分为不同的类别,接着利用一个异事件检测器对连续帧进行判别,此方法引入了环境的上下文作为判断的一个依据,但是不适合环境较为复杂的情况。
文中主要关注于异常声音的检测阶段,为此提出一种基于单类支持向量机 (One-Class Support Vector Machine,OCSVM)的异常声音检测算法。对公共场合的背景声音构建一个OC-SVM模型,用来判定一段声音是否属于正常声音,否则判定为异常声音。算法在多种公共场合声音下能够有效的检测到6种异常声音的发生且误检次数较低[7-8]。
1 ONE-CLASS SVM简介
单类支持向量机 (One-Class Support Vector Machine,OC-SVM)最先由Bernhard Schölkopf提出。他基于支持向量机(Support Vector Machine,SVM)最大分类间隔和分离超平面的思想,将单类分类问题视为一个特殊的二类分类问题,在特征空间中寻求一个超平面最大化样本点和原点之间的距离。给定训练集s={x1,x2……xl},xi∈Rd其中xi是单类样本,在文中对应公共场合的正常声音。给出从Rd到高维特征空间χ的非线性映射函数φ使得φ(xi)∈χ。OC-SVM的目标就是在高维特诊空间里建立一个超平面w·φ(x)-ρ=0,将高维空间中的样本点和原点以间隔ρ分开,其中w是超平面的法向量,p是学习超平面的截距.为了让超平面尽量远离原点,最大化原点到样本点之间的距离来寻找最优超平面。一个二维空间中的最优超平面。如图1所示。
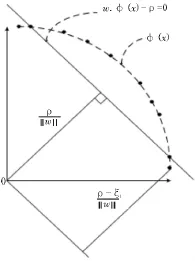
图1 单类支持向量机超平面示意图
类似二分类支持向量机,为了提高算法的鲁棒性OCSVM也引入了松弛变量ξ,优化问题表示为:
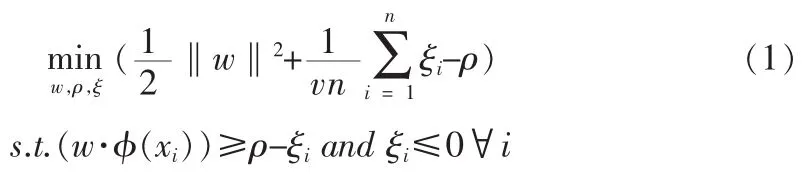
其中,w∈χ和ρ∈R是超平面的参数。v∈(0,1]是提前定义好的百分比参数,表示边界支持向量率的上界 (分类错误率)。为了求解此问题引入拉格朗日函数α。最终决策函数为:
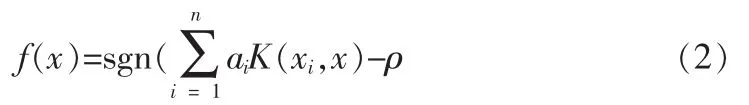
其中决策函数值大于零时预测样本为正类样本,否则样本属于异常。
2 特征参数提取
特征往往决定了分类算法的效果,好的特征组合能极大的提高算法的效果,所以,特征提取也往往是声音识别和检测研究的一个重要的方向。文中从常见的音频特征中选取一部分作为特征组合。常见的音频特征如下:
2.1 短时能量
短时能量指信号在一段(文中是指一帧,帧长25 ms)时间内的能量值,通过短时能量的变化一定程度上也能反映出信号在时域的幅度的变化情况。计算公式如下:

2.2 短时平均过零率
短时过零率指信号在一帧内符号改变的次数,它粗略的估计出了信号的频率变化情况。短时过零率的计算公式如下:

2.3 梅尔倒谱系数(Mel Frequency Cepstrum Coefficients,MFCC)
MFCC是语音识别中最常用也是效果最好的特征,也是非语音识别最常用的特征之一。它通过将标准频率取对数映射到Mel频域,更加的符合人耳对不同频段的听觉响应特点。对信号作在Mel频域作傅里叶变换,并经过一组部分重叠的滤波器组获取不同频段上的信号的能量,最后通过离散余弦变换去除耦合即可得到声音信号的 MFCC特征。文中MFCC阶数为12阶。
2.4 频谱质心(Spectral Centroid,SC)
频谱质心是指信号对数能量谱的重心,它描述了信号能量谱的形状,揭示能量谱中高频及低频的比重,反映了信号在频域的分布情况。频谱质心得计算公式如下:
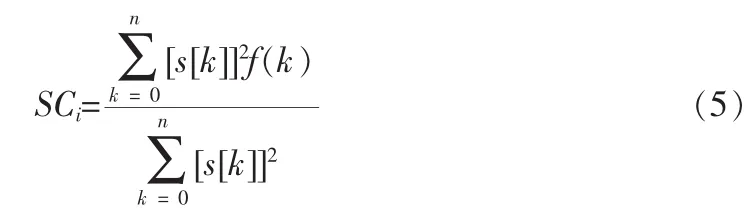
其中f(k)指信号的频率,s[k]指信号对应频率的幅度。
3 异常声音在线检测系统结构
由前所述,我们只考虑判断一段声音是否属于环境中的声音,如果不是可以判定其为异常声音(枪声,爆炸,玻璃破碎,尖叫,碰撞等)。我们对公共场合声音建立一个OC-SVM模型用来检测声音是否属于环境中的正常声音。对于每段声音通过窗长为2 s的滑动窗将其分段,对每一段声音分帧并提取其特征,然后计算相邻帧之间特征的互相关系数,互相关系数高过阈值的相邻帧之间合并为同一段声音,(阈值设为0.9)当声音的长度超过0.3 s时将其列为待识别声音,将其每一帧的特征输入OC-SVM模型中,判断每一帧信号是否异常。同时对每一段内的判别结果进行中值滤波,最后判断是否为异常声音,系统的结构流程如图2所示。

图2 异常声音检测系统结构
系统的结构由以下几个部分构成。
3.1 滑动分窗及提取特征
对于在线的异常声音检测,并不能知道事件的时间长度,因此我们先对声音滑动分窗,窗长2 s,窗移0.2 s。然后对每一窗口内的声音进行分帧,帧长25 ms,帧移50%。接着对每一帧提取特征组合,特征如前所诉主要MFCC,SC,短时能量和短时平均过零率构成。
3.2 自适应分段
对于在线的异常声音检测,事先并不知道异常声音的长度以及其端点,虽然可以采用端点检测的方法判定声音的起始点,但是由于环境中有各种声音混叠在一起,而且在每个声音的不同部分信号的强度时不一样的,一般声音的前面部分信号较强,尾部较长但是强度逐渐较弱,要准确的检测异常声音的端点难度较大。根据我们统计收集到的数据,异常声音长度范围最短(如单个手枪枪声)在 0.3 s左右,文中采用自适应的方法对信号分段。基于相邻帧之间的特征的互相关系数,当互相关系数高过设定的阈值时,多个帧合并为一块,继续计算下一帧和上一段的相关系数,然后合并不同的块,重复上述步骤直至不能再合并。具体流程见图3。
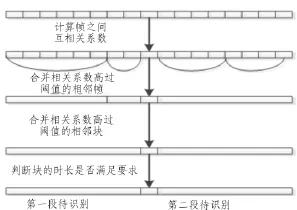
图3 自适应分段示意图
3.3 结果判断
对于每一段声音,我们对每一帧提取特征,将特征输入到OC-SVM模型中对其进行判断是否为异常。假设一段待识别的声音可以分为n帧,则OC-SVM就有多个判断结果,由于模型的判别准确度不可能为100%,所以所有的帧级的结果不可能完全正确。为此对判别的结果进行中值滤波,规则如下:
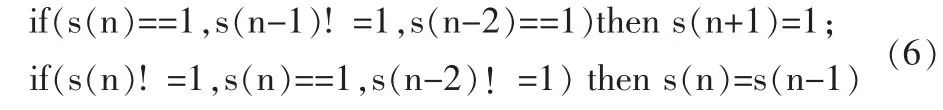
其中s(n)指一帧信号的检测结果,为1指信号为正常,否则为异常。我们认为当中间一帧与相连的帧判别结果不相同时,我们认为这是一种误分类。
对待识别的声音段帧级的识别结果进行中值滤波后,我们统计连续被判定为异常的帧的数目,设定一个比例阈值γ,当异常帧的比例超过阈值γ,我们判定此段声音为异常声音。当一个异常声音有一段被检测到的时候,判定这个异常声音被检测到了,否则判为漏检。另外当一段正常声音被检测为异常声音时判定为出现一次误检。
4 实验结果及分析
4.1 声音资源来源
由于还没有统一公开的异常声音音效资源,本文的音效资源主要来自网络,包括findsound.com上的声音资源以及ideal sound 6 000 series中的部分资源。其中有6种异常声音包括枪声,爆炸声,尖叫声,玻璃破碎声,警报声,撞击声等。6种异常声音的长度从约0.3 s至2 s不等。采样率为44.1 kHz。背景声音采用的是录取的北京地铁北土城站大厅的声音,总时长为60分钟。 背景声音主要包括人说话的声音,脚步声,拉动行李箱的声音,大厅中电视机的声音,地铁经过时发出的声音以及电机的声音等等。具体细节可见表1。

表1 各类声音资源信息
4.2 实验结果及分析
测试时,我们将异常声音按照信噪比公式(7)加入到地铁环境正常声音中。
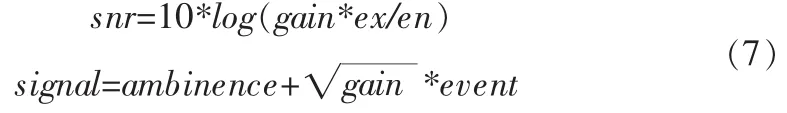
其中ex指异常声音的平均能量,en是环境声音的平均能量,event指异常声音事件,ambinece指公共场合背景声音。对于每个异常声音,我们每隔4 s的位置放置一次。对应每个异常声音分别产生时长20 min的声音,六类异常声音总共有41 967个异常事件,总时长4 960分钟。训练阶段用40分钟的地铁环境声音作为训练,剩下的20分钟作为测试。OCSVM的参数和分别设置为10和0.001。文中首先测试和对比了采用固定窗长为2 s的方法和采用自适应分段算法的效果,结果表明采用相比固定窗长的算法,自适应分段能有效降低漏检率和误检次数。实验结果见表2。
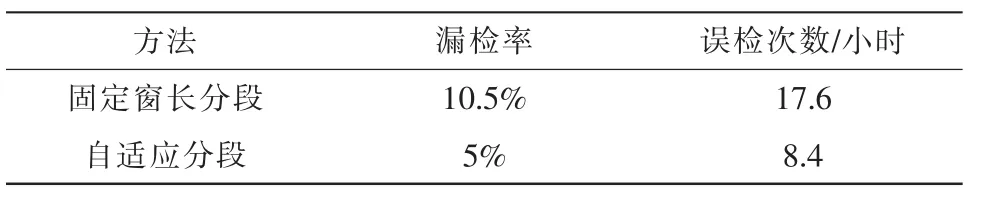
表2 两种分段方法的效果对比(γ=0.7,信噪比为20 db)
最后本文测试了在5 db,10 db,15 db,20 db信噪比条件下各类异常声音的漏检和误检次数。由前所述结果判断阶段,异常声音的判定比例γ将会影响异常声音的误检和漏检。γ过高则将会降低误检次数,但是漏检也会增加,反之γ过低则提高误检次数,降低漏检。我们测试了在不同的比例下的检测效果,具体结果见表3。
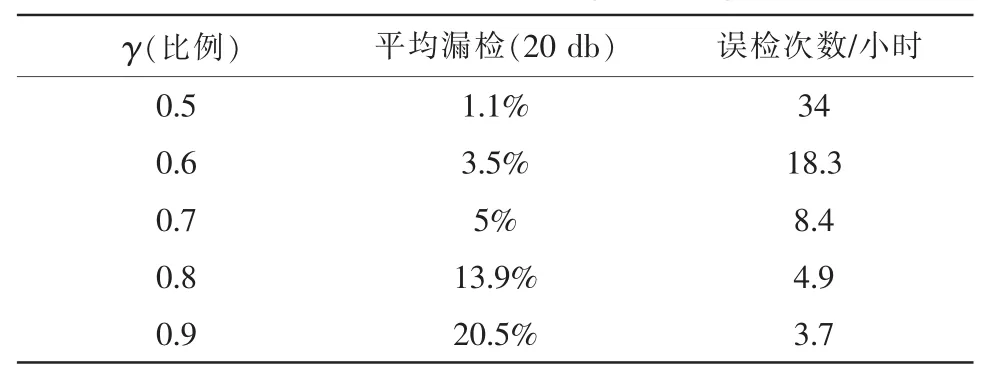
表3 不同判别比例下的漏检率和误检次数
由表3可知γ起到一个平衡误检和漏检的作用,最后我们测试了不同的信噪比条件下,各类异常声音的漏检率,结果见表4。
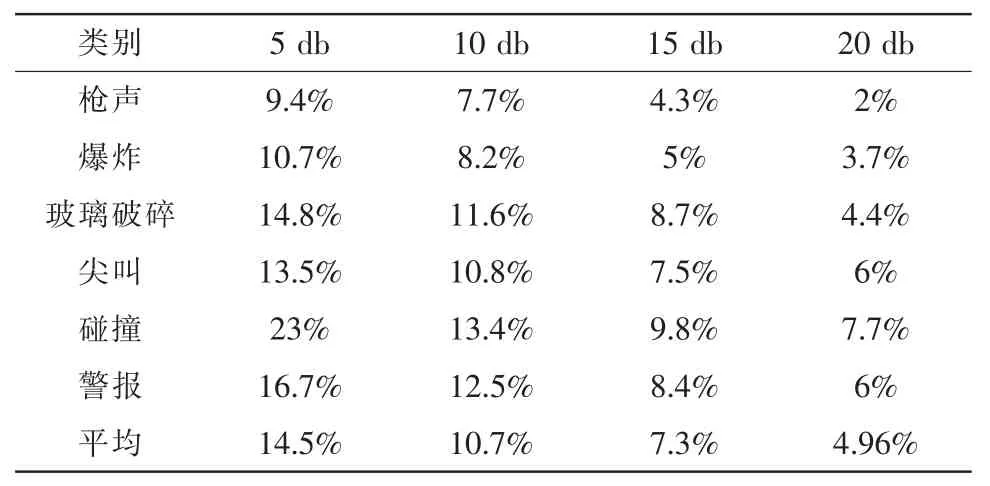
表4 各类异常声音漏检率(γ=0.7)
由结果可见:6种异常声音的平均漏检率都相对较低。枪声和爆炸声特征相对明显,能够被很好的检测到。总体上检测效果较好,符合预期。
5 结束语
文中提出了一种基于OC-SVM的异常声音在线检测算法。用一个单分类OC-SVM模型描述环境中的正常声音。并采用滑动窗对环境声音进行分窗,采用一个基于互相关系数的自适应分段方法对信号分段从而找到待检测的声音。同时我们对帧级判断结果进行中值滤波,用一个比例阈值对待检测段判断是否为异常声音。结果表明能够有效的检测到异常声音的发生且误检次数较低。对于在线的音频监控,如果算法时间复杂度过高带来了较长的延时则会影响系统的时效性,所以计算时间复杂度是需要研究的一个方面。
[1]栾少文,龚卫国.公共场所典型异常声音的特征提取[J].计算机工程,2010,7(7):208-210.
[2]吕霄云,王宏霞.基于MFCC和短时能量混合的异常声音识别算法[J].计算机应用,2010,30(3):796-798.
[3]Zhang Z,Li W,Gong W,et al.An improved EEMD model for feature extraction and classification of gunshot in public places[C]//2012 21st International Conference on,Pattern Recognition(ICPR),2012:1517-1520.
[4]LI Lu,GE Fengpei,ZHAO Qingwei,et al.A SVM-Based Audio Event Detection System[C]//2010International Conference on ,Electrical and Control Engineering (ICECE),2010:292-295.
[5]Aurino F,Folla M,Gargiulo F,et al.One-Class SVM based approach for detecting anomalous audio events[C]//2014 International Conference on,Intelligent Networking and Collaborative Systems(INCoS),2014:145-151.
[6]Younghyun Lee,Han DK,Ko Hanseok.Acoustic signal based abnormal event detection in indoor environment using multiclass adaboost[J].IEEE Transactions on Consumer Electronics,2013,59(3):615-622.
[7]龚小章.特定声识别与定位系统 [J].电子科技,2011(8):36-38.
[8]王全,王长元,穆静,等.车辆行车实时目标区域特征提取及分类训练[J].西安工业大学学报,2015(11):888-892.
Abnormal sound detection based on one class support vector machine
CHEN Zhi-quan,YANG Jun,QIAO Shu-shan
(Institute of Micro-Electronics,University of Chinese Academy of Sciences,Beijing 100029,China)
This paper proposes an abnormal sound detection method based on one-class support vector machine.For the normal sound in the public environment,we build an one-class support vector machine model to detect whether a piece of audio belong to the normal environment,if not,it is an abnormal sound needed to recognize.We apply a slipping window of two seconds length on the sound,frame the sound and extract features including Mel Frequency Cepstrum Coefficients(MFCC),Spectral Centroid(SC),Short term energy(STE).We calculate the Cross Correlation Coefficient of the adjacent two frames,and use the Cross Correlation Coefficients to implement the segmentation automatically.Then distinguish whether one frame is abnormal,finally we apply median filter on the result.If there are more than certain successive frames are abnormal,we think the sound is a abnormal sound.Then we examine our algorithm on the background sound of subway,the result shows that our method can detect abnormal sounds effectively and the false alarm time is low.
one class support vector machine;abnormal sound detection;feature extraction;audio surveillance
TN912
A
1674-6236(2016)23-0019-04
2016-03-22稿件编号:201603305
中科院性战略性先导科技专项(XDA06020401)
陈志全(1989—),男,贵州毕节人,硕士研究生。研究方向:信号处理、模式识别。
