基于机器学习的专利文本分类算法研究综述
2016-05-18刘红光马双刚刘桂锋
刘红光 马双刚 刘桂锋
(江苏大学科技信息研究所镇江212013)
基于机器学习的专利文本分类算法研究综述
刘红光 马双刚 刘桂锋
(江苏大学科技信息研究所镇江212013)
总结国内外专利文本分类情况,简要叙述基于机器学习的专利文本分类的一般框架,介绍专利文本分类的文本预处理、特征提取、文本表示、分类器构建及效果评价等过程。将应用于专利文本分类的机器学习算法分为单一分类算法和组合分类算法着重探讨:单一分类算法主要有NB算法、ANN算法、Rocchio算法、KNN算法、SVM算法等;组合分类算法主要有两种组合算法,如NB-KNN算法、Rocchio-KNN算法、KNN-SVM算法、SVM-其它算法,还有多种组合算法。指出各种机器学习算法应用在专利文本分类上的优势与不足,从专利文本预处理、特征提取、专利文本表示、分类器的构建、新方法的探索等五个方面对专利文本自动分类技术进行展望。
专利文本自动分类机器学习朴素贝叶斯支持向量机
Key wordspatent document;automatic classification;machine learning;Naive Bayes;Support Vector Machine
1 引言
专利申请数量的不断增加,产生了爆炸式增长的专利文本。一个国家的发展和民族的进步,越来越多地依赖于科技创新,而专利文本中蕴含着丰富的创新性科学技术信息,如何从专利文本中获取这些技术信息,从而获得有用的专利情报,进而为国家和民族的发展战略提供帮助,成为国内外专家研究的重点。专利文本分类作为基础性工作,在专利检索、专利聚类、专利挖掘等方面有着重要的作用,因此,专利文本自动分类技术应运而生。
国外如欧洲、美国和日本,对专利的自动分类研究起步较早[1],我国的专利研究起步相对较晚,但是近些年也开始逐步重视专利文本分类的自动化,取得了很大的进展。专利文本分类研究主要分为理论研究和实践研究两大方面,理论研究主要包括专利文本分类的方法、特征提取方法以及各种机器学习算法等方面的研究,如屈鹏和王惠临[2]详细分析了术语作为专利文本分类特征的适用性、主权项字段分类研究和相近主题对分类结果的影响等专利文本分类的基础性问题;He和Han[3]介绍了基于TRIZ理论的专利文本分类系统,并与支持向量机算法、朴素贝叶斯算法和决策树算法构建的分类结果比较,实验证明,该系统取得了更优的分类效果;Liu和Shih[4]提出基于专利网络分析的混合专利分类方法,并与采用K近邻等三个机器学习算法的分类进行比较;Chiu和Huang[5]采用蜜蜂交配优化算法获得的关键词概率结合词频来提取特征,并采用支持向量机算法进行分类;Fall、T rcsvári和Benzineb等[6]基于IPC分类号,在英语和德语专利文本分类中对朴素贝叶斯算法、支持向量机算法、K近邻算法进行比较,最后发现支持向量机算法的分类效果最好。实践研究主要探讨专利文本分类在专利申请、专利检索、专利聚类分析、战略决策等方面的应用,如Krier和Agrave[7]基于欧洲专利分类系统进行专利自动分类,以便将相关专利申请分配给技术背景接近的审查员;Lai和Wu[8]提出了应用于企业研发技术定位的专利分类方法;Li和Shawe-Taylor[9]进行跨语言的专利文本分类与检索研究。
为了更加清晰地把握专利文本分类算法的最新发展趋势,本文利用文献调研法对专利文本分类的研究成果进行详细地梳理和分析,在对基于机器学习的专利文本分类的一般框架进行简要叙述的基础上,着重介绍了专利文本分类算法的研究现状,最后从五个方面对相关研究进行展望。
2 专利文本分类一般框架
专利文本分类分为训练和分类两个过程。笔者研究之后,得出基于机器学习的专利文本分类的一般框架如图1所示:
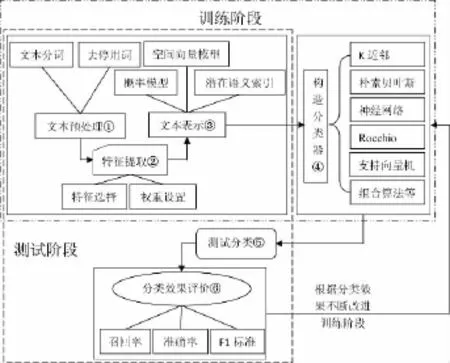
图1 专利文本自动分类的一般框架
训练阶段利用训练专利文本集,经过①~④过程,得到分类器;测试阶段对测试专利文本集也经过①~③过程,并利用训练阶段得到的分类器对其进行⑤~⑥过程,并根据评价后的结果对训练阶段不断地进行改进,最后得到比较精确地分类准确率。
2.1 专利文本预处理
专利文本预处理是从专利文本中提取特征词来表示专利文本的处理过程,它的主要任务是进行专利文本分词和去除停用词。去除停用词即是去除与专利文本分类关系不大的符号和词语,比较简单,本文不做赘述。
西文如英文、德文等的文本分词可以利用空格符号,实现起来比较简单;而中文之间没有明显的分词界限,相对比较复杂。中文分词的难点在于歧义词的切分和专利术语的识别,专利文本的撰写格式比较规范,歧义现象较少,因此相关专家学者专注于专利术语的识别。经过研究发现,单纯注重词频的分词方法很容易将一些在专利文本中出现较少但很重要的专利术语忽略,需要先将这些专利术语识别并抽取出来,如蒋健安、陆介平、倪巍伟等[10]用基于后缀数组统计的方法来获得相应领域的词汇构成领域词典,能够有效地提取出领域词汇;谷俊[11]抽取出文档词元,计算词元权重并筛选出热点词元,通过词间距测算对热点词元进行组配,经权重计算和阈值筛选后得到术语集,最后由专家人工判定识别出有效的新技术术语;屈鹏和王惠临[12]通过对专利术语的抽取方法进行研究,从专利文本中抽取出比较生僻的专业词汇,然后进行有效识别;侯婷、吕学强和李卓[13]提出一种层次过滤的专利文本术语抽取方法。
2.2 专利文本特征提取
专利文本特征提取的难点在于特征的选择和权值的计算。专利文本的特征空间维数过大将导致分类效率低下且分类准确率不高,因此需要降低专利文本特征空间的维数,选择出对分类贡献比较大的词汇用于分类;词汇的权值在分类过程中被计算处理,权值大小代表了词汇对分类起到的作用大小。
常用的特征选择方法有文档频次、互信息量、信息增益、X2统计量(CHI)等,在专利文本分类中一般采用信息增益的方法来进行特征选择。关于特征提取的相关研究[14]表明:尽管各种特征提取方法的差异不是很明显,但信息增益方法的性能相对较好。
最常见的权值计算方法包括布尔加权法、词频统计法、TF/IDF权值法以及TFC权值计算法,其中TF/IDF权值法应用最为广泛,但传统的TF/ IDF权值计算法没有考虑词汇位置对词汇权重的影响,胡冰和张建立[15]通过在TF/IDF的基础上引入类间分散度加权因子和位置权重因子,考虑了位置对词汇的影响,取得了不错的效果。
2.3 专利文本表示
专利文本表示是对专利文本进行形式化处理,使计算机能够理解自然语言文本的过程。一般文本表示模型有概率模型、潜在语义索引模型和向量空间模型等。
向量空间模型易于操作,在专利文本分类领域中应用最广,其缺点在于假设特征词项之间线性无关,而在专利文本中词项之间存在着语义联系,因此该假设不能保证计算结果的可靠性,丁月华、文贵华和郭炜强[16]提出了一种核向量空间模型,将专利文本特征转换到高维特征空间,在高维空间中实现原空间中的非线性判别函数,巧妙地解决了这个问题。
2.4 专利文本分类器的构造
应用机器学习算法对经过良好表达的专利文本进行分类实验,并不断优化实验使分类效果达到最优的过程,即为专利文本分类器的构造过程。分类器是文本分类系统的核心模块,是各种分类算法的具体表现形式,所以如何训练构造分类器是专利文本分类过程中的关键问题。
构造一个具有良好效果的分类器,需要选择合适的机器学习算法,训练完成后要不断地对分类器进行实验验证,并根据验证结果调整分类器的各项参数,使其达到最优。
3 专利文本分类算法
应用于专利文本分类的机器学习算法主要分为两类,即单一分类算法和组合分类算法。单一分类算法是指只使用一种机器学习算法应用于专利文本的自动分类,组合分类算法是指使用两种或多种机器学习算法应用于专利文本的自动分类。
3.1 单一分类算法
在专利文本分类领域应用比较广泛的算法有朴素贝叶斯算法(Naive Bayes,NB)、人工神经网络算法(Artificial Neural Networks,ANN)、Rocchio算法、K-近邻算法(K-Nearest Neighbor,KNN)、支持向量机算法(Support Vector Machine, SVM)等,在一般文本分类领域中应用比较广泛的决策树算法侧重的是单层次的分类,与专利文本多层次多分类的情况不符,因此应用较少,本文不做叙述。
(1)NB算法。NB算法是一种统计学分类方法,其基本思路是计算文本属于类别的概率,文本属于某类别的概率等于文本中每个特征词属于类别的概率的综合表达。
NB算法能运用到大型数据库中,方法简单、易实现,分类准确率高、速度快,算法稳定,利用这些优点,郭炜强、文军和文贵华[17]基于NB算法设计了一个专利文本分类系统,具有较好的分类准确率;IBM的研究人员[18-19]用NB算法构建了一个层次结构的分类系统,用于对专利等文本进行层次性分类,成功地在12个子类三个层次的小规模测试中提高了分类效率,但是对一些无法准确判断类别的文本可能会直接分类至较浅的层次。
(2)ANN算法。ANN算法是采用感知器进行分类,一般包括训练部分和测试部分,训练部分首先将训练专利文本的特征项构造输入神经元,然后通过不断迭代调整得到输入与输出的连接权值矩阵;测试部分根据训练部分得到的权值矩阵,得到待分类专利文本的特征项输出值,也即该待分专利文本的所属分类。
ANN算法具有很强的非线性拟合能力,可映射任意复杂的非线性关系,而且学习规则简单,便于计算机实现,因此在专利文本分类领域得到了广泛的应用,Trappey、Hsu、Trappey等[20]利用向后传播的ANN算法构建了一个专利文本分类系统,专利文本分类效率和准确率都大大提高;马芳[21]采用改进后的径向基函数神经网络(RBFNN)算法完成专利文本的训练和分类,兼顾了专利信息大规模与非结构的特性;李生珍、王建新、齐建东等[22]提出了一种基于后向传播神经网络的专利文本自动分类方法,与一般神经网络算法相比,提高了系统的灵活性和准确性。
Winnow[23]算法是一种类感知器的人工神经网络算法,能够同时学习一系列的超平面而被应用在多标签分类的情况,Koster、Seutter和Beney[24]利用Winnow算法在欧洲专利局进行专利文本分类,提出多分类问题比单分类问题的准确度低的原因在于多分类问题中的噪音比较大,初步解决了多分类问题精确度较低的问题。
(3)Rocchio算法。Rocchio算法[25]基于向量空间模型和最小距离,根据算术平均为每类专利文本集生成一个代表该类的中心向量,确定待分类专利文本的空间向量,计算该向量与每类中心向量间的距离(相似度),最后判定该待分类专利文本属于与其距离最近的类。
Rocchio算法的训练阶段生成所有类别的中心向量,在分类阶段,系统采用最近距离判别法把专利文本分类到与其最相似的类别中,针对类间距离大而类内距离小的类别分布情况,该算法能达到较好的分类效果。该算法计算简单、迅速、容易实现,在实际应用中一般先用其对分类文本进行粗分类,再用其它算法进一步细分。
(4)KNN算法。KNN算法是一种基于类比的分类方法,在训练过程中,KNN生成所有训练文本的特征向量,在测试过程中比较测试文本的特征向量与所有训练文本特征向量的相似度,从中找出K个最接近的训练文本,然后将测试文本分到这K个近邻中所处最多的类别中去。
KNN算法依靠周围有限的邻近的样本来确定所属类别,较其他方法更为适合于类域重叠较多的待分样本集,在专利文本的分类中得到了广泛的应用,日本国家科学咨询系统中心(NACSIS)策划主办的NTCIR(NACSIS Test Collections for IR)在theme以及F-term的专利文本分类实验中,KNN取得了最好的结果;Kim和Choi[26]利用KNN算法进行专利文本分类,达到了74%的改善性能;Richter和MacFarlane[27]用KNN算法设计了两个(一个注重元数据,另一个忽略元数据)相似的专利文本分类系统并对其进行比较,关注元数据的系统取得了更高的准确率。国内这方面研究也较多,季铎、蔡云雷、蔡东风等[28]提出基于共享最近邻的KNN专利文本自动分类方法,在NTCIR-8专利分类评测任务中充分验证了其有效性;苑迪文[29]基于KNN算法并对其进行改进,设计并实现了一个专利文本分类系统,取得了比传统KNN算法更优的效果。
(5)SVM算法。SVM算法的训练过程是要找到一个超平面,使得这个超平面的正反例分别落在两侧,在所有超平面中与正反例的距离最大且到最近的正反例的距离相等,然后对未知类别的专利文本,计算其位于超平面的一侧,即为其分属的类别。
SVM算法凭借高维灾难问题处理得当、数据稀疏性以及文本特征相关性不敏感、准确率很高的优势,在专利文本分类中得到了广泛的应用:Chen和Chang[30]利用开放源代码的LibSVM对专利文本的分类进行学习和预测,并提出了一个三阶段专利文本分类法;Wu、Ken和Huang[31]提出一个基于新的遗传算法SVM的专利分类系统,在应用不同的内核后均取得了80%以上的准确率;上海交通大学的吕宝粮教授及其团队[32]基于SVM算法,实现了一个改进的并行化最小最大模块化SVM(Min-Max Modular Support Vector Machine,M3-SVM)算法,在大规模专利文本分类问题上比SVMlight算法更加准确,更加节省时间。
3.2 组合分类算法
传统的单一的机器学习算法都有自身的缺点,NB算法假设文本中各个特征词之间是相互独立、互不影响的,但是专利文本特征词之间存在明显的相关关系,因此存在一定的偏差;ANN算法把一切问题的特征转变成数字,推理转变成数值计算,丢失了不少信息;Rocchio算法受分类之间距离影响较大,故而在实际的分类系统很少用其来解决具体的分类问题;KNN算法在判断一篇新的专利文本的类别时,需要把它与现存所用训练文本都比较一遍,比较耗时,而且当训练样本不平衡时,可能导致待分类专利文本的K个邻居中大容量样本占多数;SVM算法在不同分类问题中核函数参数的选择较复杂,分类精度不高,大规模分类的训练时间较长,在大样本环境下,计算的周期过长、降低了运算速率。
因此,针对单一算法的缺点,国内外一些专家学者在研究过程中越来越多地采用组合的分类算法,以求对单一算法扬长避短,取得更好的分类效果。相关研究一般采用两种组合算法,应用多种组合算法的分类相对较少,但是也有专家进行了研究。
3.2.1 两种组合算法
(1)NB-KNN算法。NB算法基于概率论,对缺失数据不敏感,规避了KNN算法对数据分布不平衡导致的分类错误,而KNN算法在类域重叠较多的样本集中有着优势,两个算法的结合可以有效地实现优势互补,劣势互消,Larkey[33]基于美国的专利分类体系,将NB算法和KNN算法相结合开发出一个专利分类系统,NB算法利用专利子类之间的相关关系选择不同的类别构造更多的分类,KNN算法基于向量空间模型,可以在系统中表示文档结构,使得系统在实际中得到了较好的应用。
(2)Rocchio-KNN算法。Rocchio算法基于中心度理论,在类别区分度比较大的分类中效果明显,KNN算法在小范围类间区分度比较小的分类中,能取得很好的效果,Rocchio算法与KNN算法结合,适用于专利文本分类大类之间区别大而小类之间区别较小的情况,蒋健安、陆介平、倪巍伟等[10]设计的层次分类算法先采用Rocchio算法进行专利大类的区分,再对各个大类之间的文本采用KNN方法进行小类的细分,由于大类之间的区分度比较大,因此可以使用Rocchio算法,而相同大类之间的小类分别较小,采用KNN算法更能区分。
(3)KNN-SVM算法。KNN算法将每类中所有的支持向量都作为代表点,可以改善SVM算法只将一个点作为代表点的不足,李程雄、丁月华和文贵华[34]提出并分析了结合SVM算法和KNN算法的组合改进算法SVM-KNN,当样本和SVM最优超平面的距离大于给定的阈值,即样本离分界面较远,则用SVM分类,反之用KNN算法对测试样本分类,比单一的算法取得了更优的分类效果。
(4)SVM-其它算法。SVM算法在专利文本分类中得到了广泛的应用,取得了更好的效果,但是单一的SVM算法存在着缺点,需对其进行改进,或者将其与其它的方法结合,张晓宇[35]提出多分类器融合和主动学习的方法来分类专利文本,其中在每个子分类器中利用SVM算法对每个专利类别进行训练,都取得了更好的效果。
3.2.2 多种组合算法专利文本分类的研究是一个不断探索的过程,没有哪一个单一算法或者组合算法能够实现完美的分类,因此可以综合多种算法的优势,Liu、Liao、Pi等[36]构建了一个结合了NB算法、KNN算法和Rocchio算法的专利文本分类系统,应用在实际的分类过程中,取得了比单一分类器更加稳定的效果。
3.3 各种算法的优缺点比较
笔者通过对相关文献的仔细梳理和深入比较,总结出各种算法或算法组合的优缺点,如表1所示。
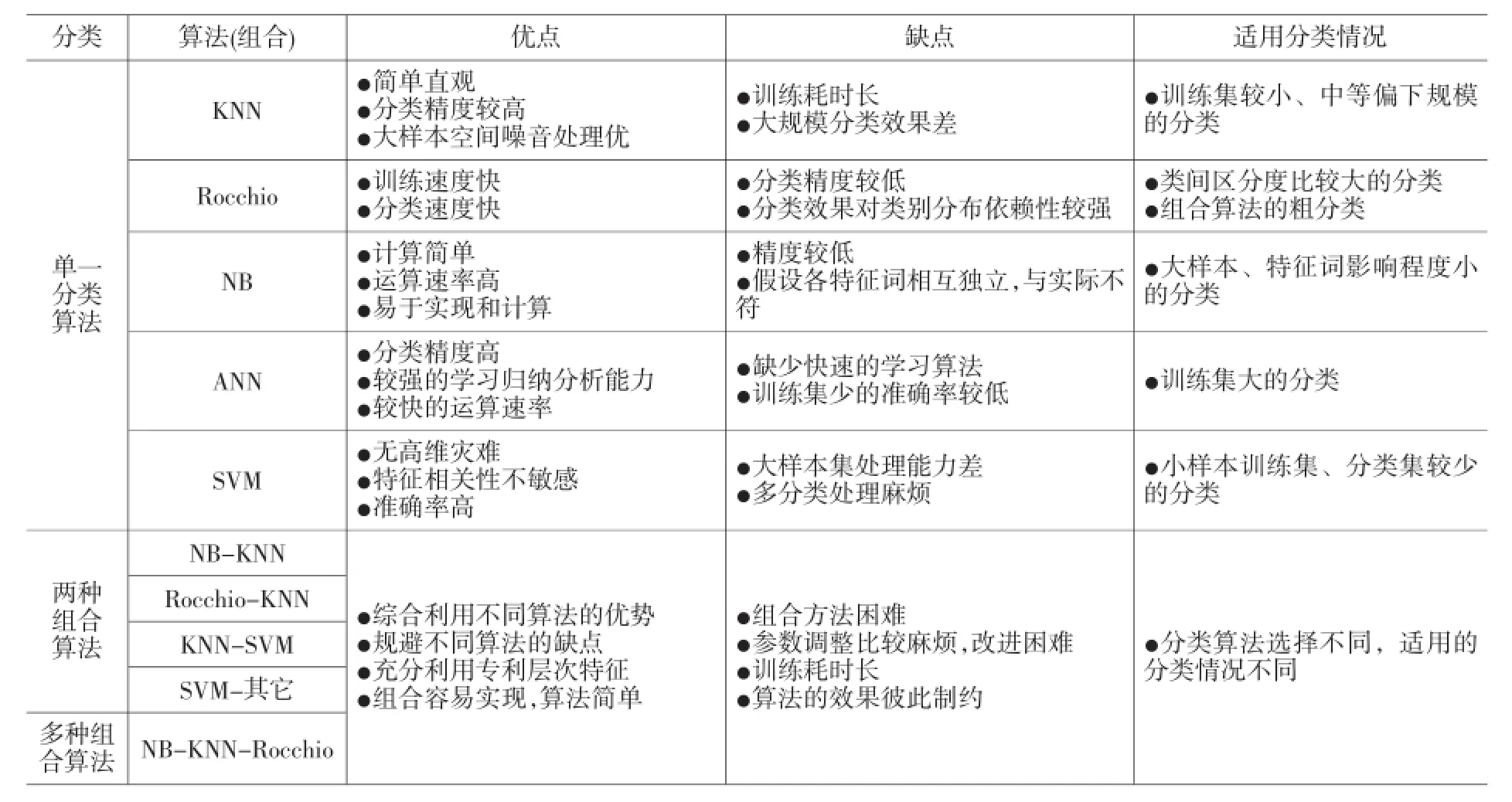
表1 各种算法的优缺点
4 总结和展望
由于专利文本分类是大规模、多层次结构、多标号和不均衡的文本分类问题,大多数传统的机器学习算法都是针对小规模、单标号且平衡的问题设计的,无法很好地解决类似专利分类这样的问题。因此在专利文本分类的研究过程中,从文本预处理到分类器构建的各个环节都有很大的发展潜力。
4.1 总结
欧美发达国家比较注重实践,在各自专利分类体系(如IPC等分类体系)和大型专利数据库的基础上构建了许多自动分类系统,并将其实际运用到了专利预分类、检索和分类中,能够比较合理的进行改进和创新;而我国在专利自动分类中的研究大部分处于理论阶段,构建的几个系统可移植性不高,并没有很好的运用到实际中去。
在整个专利文本的自动分类过程中,相关专家学者抓住了自动分类这个主干,对分类过程中的每一个枝节进行了研究改进,或是专注于一个枝节,或是专注于多个枝节,取得了很好的分类效果,也使得研究能够顺利进行下去。
4.2 展望
本文从专利文本预处理、特征提取、专利文本表示、分类器的构建、新方法的探索等五个方面对专利文本自动分类进行展望。
(1)文本预处理:带有专业术语与生僻词的中文分词系统亟需出现。专利文本与普通文本不同,其中掺杂着大量的专业术语或特指词汇,因此在专利文本预处理过程中,需要特别注意专业术语与生僻词。现有的比较成熟、应用广泛的中文分词系统如中科院的ICTCLAS中文分词系统,在对专利文本中生僻词的处理中还存在一些问题,而专利领域跨专业的特性使得专业术语及生僻词太多,也不太可能建立专利领域通用的词典,因此如何找出更加精确的中文分词系统对后期专利文本的成功分类将起到很大的作用。
(2)特征提取:特征选择和权值计算的改进至关重要。特征选择很重要,因为这关系到后边分类的效果,在一篇文本之中,特征词的选取不能单纯的依靠一种办法,很多时候要综合利用多种办法,以应对待分类样本由于分布不同而产生的误差。
权值的计算一般采用TF/IDF方法,但是专利文本的特殊性使得学者在进行专利文本的分类时,根据其特点选择不同的改进方法,加入一些考虑因素及影响因子,考虑特征词之间的关系等,得到了比较好的实验效果。
在以后的研究中,可以继续研究特征的选择和权值的计算,设计更加精确的方法,使得被表示成向量空间模型的专利文本特征能够充分的代表文本,以取得更加精确的分类效果。
(3)专利文本表示:常用模型的改进和新模型的引进齐头并举。在专利文本表示中,概率模型、潜在语义索引模型使用的不多见,大部分专利文本表示用的都是向量空间模型,而向量空间模型应用于专利分类中也存在着很多的问题,如维数不好控制,即如果一部分样本比较分散,而另一部分样本比较集中的话,分类结果会非常差。因此,需要对向量空间模型改进,或者提出一种更好的文本表示办法,以更好的应用于专利分类。
(4)分类器构建:多种机器学习算法相融合成为主流。在专利文本分类算法上,传统的文本分类采用的算法普遍含有移植性差的缺点,因此以后的研究将更加专注于机器学习算法的创新以及改进符合专利文本特点的分类算法。通过对相关文献的研究,发现采用多种机器学习算法相融合的方法更加适合专利文本的特点,更能取得精确的分类效果。因此以后的研究可以注重多种机器学习算法的融合,找到不同算法的结合点,除去不同算法中不相适应的部分。另外,可以研究更加精确的分类算法,更好地运用到专利文本分类中去。
(5)新方法的研究探索:突破或创立新的方法迫在眉睫。文本分类的研究取得了很大的成果,专家在研究专利文本分类的时候自然而然地借鉴了一般文本的分类方法。而专利文本分类与一般文本分类虽有很大的相似之处,但专利文本是一种特殊的文本,如果机械的借鉴或是应用传统的文本分类方法,肯定收不到最好的效果。因此以后的研究方向可以集中在方法的创新,另辟蹊径,找到新方法应用于专利文本的分类。
[1]Fall C J,Benzineb K.Literature survey:Issues to be considered in the automatic classification of patents[R].2002.
[2]屈鹏,王惠临.专利文本分类的基础问题研究[J].现代图书情报技术,2013(3):38-44.
[3]He C,Han T L.Pattern-oriented associative rule-based patent classification[J].Expert Systems with Applications, 2010,37(3):2395-2404.
[4]Liu D,Shih M.Hybrid-patent classification based on patentnetwork analysis[J].Journal of the American Society for Information Science and Technology,2011,62(2):246-256.
[5]Chiu C,Huang P.Application of the honeybee mating optimization algorithm to patent document classification in combination with the support vector machine[J].International Journal of Automation and Smart Technology,2013,3(3):179-191.
[6]Fall C J,T rcsváriA,Benzineb K,et al.Automated categorization in the international patent classification[C]//ACM SIGIR Forum,2003,37(4):10-25.
[7]Krier M,Agrave F Z.Automatic categorisation applications at the European patent office[J].World Patent Information,2002 (24):187-196.
[8]Lai K K,Wu S J.Using the patent co-citation approach to establishanewpatentclassificationsystem[J].InformationProcessing&Management,2005(41):313-330.
[9]Li Y,Shawe-Taylor J.Advanced learning algorithms for crosslanguage patent retrieval and classification[J].Information Processing&Management,2007,43(5):1183-1199.
[10]蒋健安,陆介平,倪巍伟,等.一种面向专利文献数据的文本自动分类方法[J].计算机应用,2008,28(1):159-161.
[11]谷俊.专利文献中新技术术语识别研究[J].现代图书情报技术,2012(11):53-59.
[12]屈鹏,王惠临.面向信息分析的专利术语抽取研究[J].图书情报工作,2013,57(1):130-135.
[13]侯婷,吕学强,李卓.专利术语抽取的层次过滤方法[J].现代图书情报技术,2015(1):24-30.
[14]Peters C,Koster C H.Uncertainty-based noise reduction and term selection in text categorization[M].Heidelberg:Springer, 2002:248-267.
[15]胡冰,张建立.基于统计分布的中文专利自动分类方法研究[J].现代图书情报技术,2013(Z1):101-106.
[16]丁月华,文贵华,郭炜强.基于核向量空间模型的专利分类[J].华南理工大学学报(自然科学版),2005,33(8):58-61.
[17]郭炜强,文军,文贵华.基于贝叶斯模型的专利分类[J].计算机工程与设计,2006,26(8):1986-1987.
[18]ChakrabartiS,DomB,Indyk P.Enhanced hypertext categorization using hyperlinks[J].Sigmod Record,1998,27(2):307-318.
[19]Chakrabarti S,Dom B,Agrawal R,et al.Using taxonomy,discriminants,and signatures for navigating in text databases[C]//Proceedings of the 23rd VLDB Conference,1997:446-455.
[20]Trappey A J C,Hsu F C,Trappey C V,et al.Development of a patent document classification and search platform using a back-propagation network[J].Expert Systems with Applications,2006,31(4):755-765.
[21]马芳.基于RBFNN的专利自动分类研究[J].现代图书情报技术,2011,27(12):58-63.
[22]李生珍,王建新,齐建东,等.基于BP神经网络的专利自动分类方法[J].计算机工程与设计,2010(23):5075-5078.
[23]Littlestone N.Learning quickly when irrelevant attributes abound:A new linear-threshold algorithm[J].Machine learning,1988,2(4):285-318.
[24]Koster C H A,Seutter M,Beney J.Multi-classification of patent applications with Winnow[C]//Perspectives of System Informatics.Berlin Heidelberg:Springer,2003:546-555.
[25]Sebastiani F.Machine learning in automated text categorization[J].ACM computing surveys(CSUR),2002,34(1):1-47.
[26]Kim J H,Choi K S.Patent document categorization based on semantic structural information[J].Information processing& management,2007,43(5):1200-1215.
[27]Richter G,MacFarlane A.The impact of metadata on the accuracy of automated patent classification[J].World Patent Information,2005,27(1):13-26.
[28]季铎,蔡云雷,蔡东风,等.基于共享最近邻的专利自动分类技术研究[J].沈阳航空工业学院学报,2010,27(4):41-46.
[29]苑迪文.基于KNN的专利文本分类算法研究[D].焦作:河南理工大学,2012.
[30]Chen Y L,Chang Y C.A three-phase method for patent classification[J].Information Processing&Management,2012,48 (6):1017-1030.
[31]Wu C H,KenY,Huang T.Patent classification system using a new hybrid genetic algorithm support vector machine[J].Applied Soft Computing,2010,10(4):1164-1177.
[32]Mahr B,Huanye S,Ye Z,et al.Patent Classification Using Parallel Min-Max Modular Support Vector Machine[C]// Mahr B,Huanye S.Autonomous Systems-Self-Organization, Management,and Control.Berlin:Springer Netherlands,2008:157-167.
[33]Larkey L S.A patent search and classification system[C]// Proceedings of the fourth ACM conference on Digital libraries.ACM,1999:179-187.
[34]李程雄,丁月华,文贵华.SVM-KNN组合改进算法在专利文本分类中的应用[J].计算机工程与应用,2006,42(20):193-195.
[35]Zhang X.Interactive patent classification based on multiclassifier fusion and active learning[J].Neurocomputing,2014, 127:200-205.
[36]Liu S H,Liao H L,Pi S M,et al.Patent Classification Using Hybrid Classifier Systems[J].Advanced Materials Research, 2011,187:458-463.
(责任编校骆雪松)
A Review of Research on Patent Document Classification Algorithms Based On Machine Learning
Liu Hongguang,Ma Shuanggang,Liu Guifeng
Institute of Science and Technology Information,Jiangsu University, Zhenjiang 212013,China
This article firstly summarized the patent document classification at home and abroad,and then based on machine learning,briefly described the general framework of patent document classification,followed by an introduction to text preprocessing,feature extraction,text representation,classifier building and the evaluation process of patent document classification.Also this article paid more attention to discussing the machine learning algorithms in patent document classification which could be divided into single algorithm and combined algorithms.Single algorithm mainly consisted of NB algorithm,ANN algorithm, Rocchioalgorithm,KNN algorithm,and SVM algorithm;combined algorithms could be classified into bi-algorithm(e.g.NB-KNN algorithm,Rocchio-KNN algorithm,KNN-SVM algorithm,and SVM-other algorithm)and multi-algorithm.In addition,the advantages and disadvantages of the application of various kinds of machine learning algorithms to patent document classification were pointed out,and future development of automatic patent document classification techniques were also presented from 5 aspects(text preprocessing,feature extraction,text representation,classifier building and the exploration of new methods of patent document classification).
G350
刘红光,女,1956年生,副教授,硕士生导师,研究方向为情报分析,发表论文30余篇;马双刚,男,1990年生,2013级图书情报与档案管理专业硕士研究生,研究方向为情报分析,发表论文1篇;刘桂锋,男,1980年生,博士,副研究馆员,硕士生导师,副所长,研究方向为情报分析,发表论文20余篇,主编教材1部。
