说话人识别中基于Fisher比的特征组合方法
2016-05-14谢小娟曾以成熊冰峰
谢小娟 曾以成 熊冰峰

摘要:为了提高说话人识别的准确率,可以同时采用多个特征参数,针对综合特征参数中各维分量对识别结果的影响可能不一样,同等对待并不一定是最优的方案这个问题,提出基于Fisher准则的梅尔频率倒谱系数(MFCC)、线性预测梅尔倒谱系数(LPMFCC)、Teager能量算子倒谱参数(TEOCC)相混合的特征参数提取方法。首先,提取语音信号的MFCC、LPMFCC和TEOCC三种参数;然后,计算MFCC和LPMFCC参数中各维分量的Fisher比,分别选出六个Fisher比高的分量与TEOCC参数组合成混合特征参数;最后,采用TIMIT语音库和NOISEX92噪声库进行说话人识别实验。仿真实验表明,所提方法与MFCC、LPMFCC、MFCC+LPMFCC、基于Fisher比的梅尔倒谱系数混合特征提取方法以及基于主成分分析(PCA)的特征抽取方法相比,在采用高斯混合模型(GMM)和BP神经网络的平均识别率在纯净语音环境下分别提高了21.65个百分点、18.39个百分点、15.61个百分点、15.01个百分点与22.70个百分点;在30dB噪声环境下,则分别提升了15.15个百分点、10.81个百分点、8.69个百分点、7.64个百分点与17.76个百分点。实验结果表明,该混合特征参数能够有效提高说话人识别率,且具有更好的鲁棒性。
关键词:说话人识别;Fisher准则;梅尔频率倒谱系数;线性预测系数;Teager能量算子
中图分类号:TN912 文献标志码:A
Abstract: In order to improve the accuracy of speaker recognition, multiple feature parameters should be adopted simultaneously. For the problem that each dimension comprehensive feature parameter has the different influence on the identification result, and treating them equally may not be the optimal solution, a feature parameter extraction method based on Fisher criterion combined with Mel Frequency Cepstrum Coefficient (MFCC), Linear Prediction Mel Frequency Cepstrum Coefficient (LPMFCC) and Teager Energy Operators Cepstrum Coefficient (TEOCC) was proposed. Firstly, parameters of MFCC, LPMFCC and TEOCC from speech signals were extracted, and then the Fisher ratio of each dimension of MFCC and LPMFCC parameters was calculated, six components were selected respectively by using Fisher standard to combine with TEOCC parameter into a mixture feature which was used to realize speaker recognition on the TIMIT acousticphonetic continuous speech corpus and NOISEX92 noise library. The simulation results show that the average recognition rate of the proposed method by using Gauss Mixed Model (GMM) and Back Propagation (BP) neural network compared with MFCC, LPMFCC, MFCC+LPMFCC, parameter extraction method for MFCC based on Fisher criterion and the feature extraction method based on Principal Component Analysis (PCA) is increased by 21.65 percentage points, 18.39 percentage points, 15.61 percentage points, 15.01 percentage points, 22.70 percentage points in the pure voice database, and by 15.15 percentage points, 10.81 percentage points, 8.69 percentage points, 7.64 percentage points, 17.76 percentage points in 30dB noise environments. The results show that the mixture feature can improve the recognition rate effectively and has better robustness.
Key words:speaker recognition; Fisher criterion; Mel Frequency Cepstrum Coefficent (MFCC); Linear Prediction Coefficient (LPC); Teager Energy Operator (TEO)
0 引言
随着语音信号处理技术的进步,语音信息服务正走向智能化,说话人识别(Speaker Recognition, SR)[1]已被广泛地应用于信息安全领域、通信领域、司法领域和军事等领域[2]。而如何从说话人的语音信号中提取出能表征说话人个性、易分类且不随时间空间变化的有效特征参数是说话人识别的关键。
目前,常用的特征参数主要有线性预测倒谱系数(Linear Prediction Cepstral Coefficent, LPCC)和梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficent, MFCC)[3]。近几年来,针对这两种特征参数,人们提出了许多种改进的方法。
文献[4]利用语音信号的相关特性和人耳听觉感知特性,将LPCC和MFCC组合作为特征参数来提高说话人识别系统性能;文献[5]组合了LPCC、MFCC及其一阶、二阶差分参数来进行说话人识别,但识别率只有小幅度提高,并且识别速度慢,需要大量的时间,实时性不够好;文献[6]研究了在LPCC和MFCC中加入基于Bark子波滤波器组的特征参数来提高语音识别率的方法;文献[7]利用主成分分析(Principal Component Analysis,PCA)方法组合LPCC、MFCC和一阶微分参数来改善说话人识别性能;文献[8]提出了一种在MFCC基础上增加归一化短时能量参数和一阶差分作为特征参数的改进算法;文献[9]采用非线性幂函数对人耳的听觉特性进行模拟,得到新的MFCC及其差分和加权倒谱系数的组合特征参数来提高说话人识别准确率。由此可见将两种或两种以上的不同特征参数直接组合,虽然有利于提高说话人识别系统的性能,但实际上,组合参数不仅会增加特征参数的维数,而且有冗余信息。
为了解决直接组合参数不理想的问题,可对特征参数中各维分量对识别贡献进行评价。目前常用的评价方法有两种,利用Fisher准则得到特征向量的最佳投影方向(分离度最大)[10]和通过增减特征分量的方法来判断特征分量对识别的贡献程度[11]。甄斌等[12]采用增减特征分量的方法研究了MFCC各维倒谱分量对说话人识别和语音识别的贡献,但是该方法计算量较大,同时受环境影响较大;鲜晓东等[13]通过Fisher比有效地选择MFCC、逆梅尔倒谱系数(Inverted Mel Frequency Cepstrum Coefficient, IMFCC)和中频梅尔倒谱系数(Midfrequency Mel Frequency Cepstrum Coefficient, MidMFCC)三种参数,组合成一种混合特征参数(以下记为XF特征参数),缩短了计算时间,提高了系统识别率, 因此利用Fisher准则来分析特征向量,确定特征分量的可分离性是一种有效的方法。
本文将结合声道特征、人耳的线性感知特性和非线性能量特性,通过计算MFCC和LPMFCC,然后利用Fisher准则,选择其中可分离程度较大的特征分量,与Teager能量算子倒谱参数(Teager Energy Operators Cepstrum Coefficient, TEOCC)组成一种混合特征参数,进行说话人识别。
1 语音特征参数提取
1.1 MFCC参数提取
MFCC考虑了人耳的听觉特性,将频谱转化为基于Mel频标的非线性频谱,然后转换到倒谱域上;由于充分考虑了人的听觉特性,而且没有任何提前假设,MFCC参数具有良好的识别性能和抗噪能力[3]。
MFCC参数提取过程如图1所示,其中预处理包括预加重、分帧、加窗和端点检测,DFT(Discrete Fourier Transform)表示快速傅里叶变换,DCT(Discrete Cosine Transform)表示离散余弦变换。
1.2 LPMFCC参数提取
线性预测系数(Linear Prediction Coefficient, LPC)是表征声道模型的线性时变系统的参数,它反映了说话人的声道特性,在说话人识别中具有广泛的应用。但LPC在所有频率上都是线性逼近语音的,这与人耳的听觉特性不一致,并且它对噪声的影响特别敏感,包含了语音高频部分的大部分噪声细节,从而会影响系统的性能。由于语音信息主要集中在低频部分,Mel滤波器组在低频区域的分布比较集中,所以借鉴MFCC,将实际频率的LPC系数转化为Mel频率的LPC系数,得到线性预测梅尔参数(Linear Prediction Mel Frequency Cepstrum Coefficient, LPMFCC),这样使声道特征和人耳听觉特征结合了起来,应用于说话人识别系统会有更好的识别效果。
LPMFCC参数提取算法如下:
1)对语音信号进行预处理,包括预加重、分帧、加窗和端点检测;
2)计算每帧语音信号的LPC系数;
3)每帧信号的LPC系数经过DFT得到离散频谱,然后计算功率谱;
4)将上述功率谱通过Mel滤波器组进行滤波处理,并计算对数功率谱;
5)将对数功率谱经过离散余弦变换得到LPMFCC。
1.3 TEOCC参数提取
Teager能量算子(Teager Energy Operators, TEO)是由Kaiser[14]提出的一种非线性差分算子,不仅具有非线性能量跟踪信号特性,能够合理地呈现信号能量的变换,而且能够消除信号的零均值噪声影响,增强语音信号,同时进行信号特征提取。
由此可以看出,TEO能消除零均值噪声的影响。而通常所用的能量估计方法没有这种消除噪声的能力,将非线性的TEO引入到语音信号的特征提取中,不仅能更好地反映信号的能量变化,而且能消除噪声对语音信号的影响,从而达到更好的检测效果。
Teager能量算子倒谱参数(TEOCC)提取算法如下:
1)对语音信号进行预处理,包括预加重、分帧、加窗和端点检测;
2)根据式(1)计算每帧语音信号的平均TEO;
3)计算对数TEO,并作离散余弦变换得到1维TEOCC。
1.4 混合特征参数提取
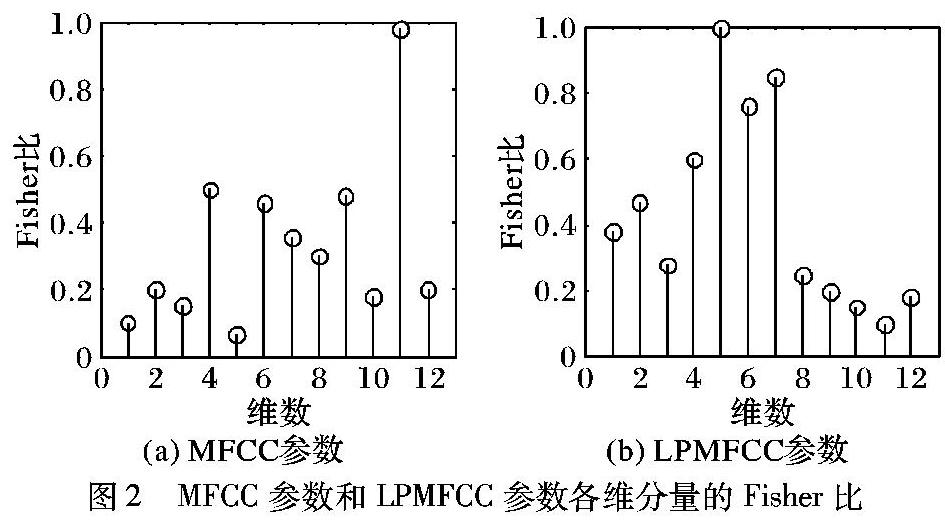
MFCC、LPMFCC和TEOCC三种特征参数分别表征了语音信号在人耳感知、声道和非线性能量方面的特征,以及体现了三种特征参数对噪声的敏感程度,可以结合这三种特征对语音信号进行描述。但是,将它们直接叠加组合会产生一些问题。如果MFCC和LPMFCC两种参数各提取12维,TEOCC参数提取1维,那么将会得到25维参数,增加了特征参数的维数,不仅增大了计算量,而且增加了系统训练和识别时间。同时由于各维特征参数对识别的贡献程度不一样,有些参数可能包含大量的冗余信息甚至是干扰信息,如果将它们同等对待,最终会影响识别效果,所以必须对各维参数进行特征选择,选出那些可分离性最优且能有效地表征语音信号的特征分量,从而达到降维的目的并得到最优的识别性能。在模式识别中特征参数的类别可分离性可以用Fisher比来判别。
混合特征参数的提取算法如下:
1)对语音信号进行预处理,包括预加重、分帧、加窗和端点检测;
2)分别对预处理后的语音信号提取12维MFCC参数、12维LPMFCC参数和1维TEOCC参数;
3)从MFCC和LPMFCC两种特征参数中各选择Fisher比(即区分度)最大的6个维数分量进行组合,记作MFCC+LPMFCC特征参数,然后将其与TEOCC参数组合成13维混合特征参数。
2 实验结果及分析
为了验证本文提出的混合特征参数的有效性和实时性及其在噪声环境下的识别性能,采用了TIMIT语音数据库[16]和NOISEX92噪声数据库[17]进行了仿真实验。设置TIMIT语音库说话人闭集70个人(男40个,女30个),每个说话人录制10段语句、7段用于模型训练和3段用于测试。实验中对预处理后的语音分别提取12维MFCC、12维LPMFCC、12维MFCC+LPMFCC、18维XF特征参数和13维本文混合特征参数,进行说话人识别实验;为了进一步论证基于Fisher比的特征抽取方法的有效性,提取了12维PCMLT参数与之进行对比分析实验,其中PCMLT参数是基于PCA的MFCC、LPMFCC和TEOCC的组合特征参数,提取过程是对预处理后的语音信号提取12维MFCC和12维LPMFCC进行PCA降维处理,分别得到6维特征参数,然后与TEOCC组合成新的特征参数。所有实验都是在Windows 7操作平台上运行,所有的识别结果均是通过多次测试平均统计得到。
2.1 实验一
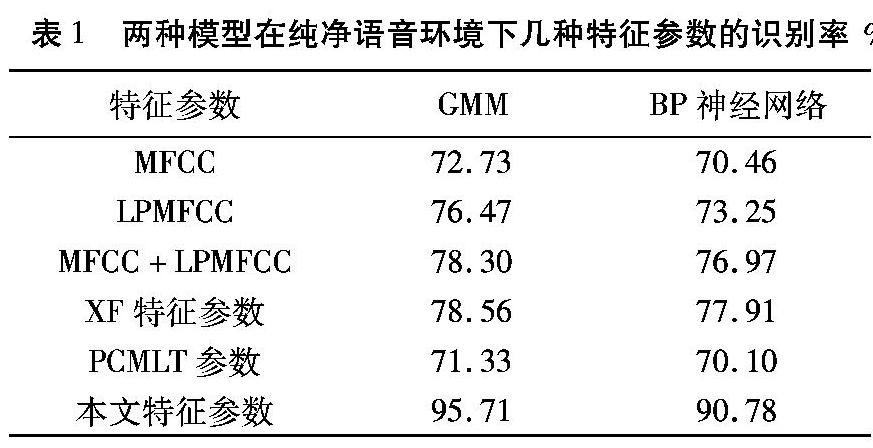
测试在纯净语音环境下特征参数的识别性能。实验采用高斯混合模型(Gaussian Mixture Model, GMM)和反向传播(Back Propagation, BP)神经网络为分类器分别进行测试,并记录了在纯净语音下不同特征参数的识别结果。其中GMM的混合阶数均为8阶;分别设置12维、13维和18维特征参数的BP神经网络输入层隐含层输出层结构的神经元数为127570、137570和187570,并设置网络参数:学习率η=0.35,动态参量a=0.85,训练精度E≤e-5。如表1所示,记录了两种模型在纯净语音环境下几种特征参数的识别率。
从表1可以看出,在基于Fisher比提取的MFCC和LPMFCC特征中引入TEOCC特征,识别率有明显提高。而基于PCA特征抽取方法,虽然能减小特征参数之间的相关性、突出差异性,保留特征参数中一些重要的“成分”,舍去一些冗余的、包含信息量很少的“成分”,但是不能完全地保留最有效和最重要的信息,其识别效果反而变差。在GMM下,本文特征参数与MFCC、LPMFCC、MFCC+LPMFCC、XF特征参数和PCMLT参数相比, 识别率有显著的提升,分别提高了22.98个百分点、19.24个百分点、17.41个百分点、17.15个百分点和24.71个百分点。同样在BP神经网络为分类器测试下,虽然6种特征参数识别率相比GMM下的识别率均有小幅度下降,但本文特征参数识别率与MFCC和LPMFCC、MFCC+LPMFCC、XF特征参数和PCMLT参数相比仍然有大幅提升,分别提升了20.32个百分点、17.53个百分点、13.81个百分点、12.87个百分点和20.68个百分点。这综合说明了在纯净语音环境下本文方法具有更好的识别效果。
2.2 实验二
测试在噪声环境下特征参数的识别性能。为每个说话人的测试语音加入NOISEX92噪声数据库中生活较常见的噪声进行实验,并记录了特征参数的识别性能,仿真结果如图3所示。
从仿真结果可以看出,在不同的噪声以及不同的信噪比下,本文提出的特征参数对说话人识别性能改善明显,与MFCC、LPMFCC、MFCC+LPMFCC、XF特征参数、PCMLT参数相比,平均识别率在30dB信噪比下分别提高了15.15个百分点、10.81个百分点、8.69个百分点、7.64个百分点与17.76个百分点,在0dB信噪比下分别提升了7.82个百分点、7.72个百分点、2.88个百分点、2.73个百分点与9.13个百分点。实验结果表明本文特征参数鲁棒性较MFCC参数、LPMFCC参数、MFCC+LPMFCC参数、XF特征参数以及PCMLT参数要强,主要是由于MFCC参数考虑了人耳的听觉特性,LPCC能够体现说话人的声道特征,对元音有较好的描述能力,且通过Fisher比选择出了可分离性最优且能有效地表征语音信号的特征分量,而TEOCC参数不仅反映了语音信号非线性能量特征,还能够消除噪声对语音信号的影响,所以本文特征参数结合了这几种特征参数的优点,识别性能和噪声鲁棒性都得到了进一步提高。
2.3 实验三
正确率的高低是检验所用算法性能的一个指标,但在实际应用中还要考虑其实时性问题。实验采用了Matlab串行和并行计算两种方法定量描述各个算法的运行时间,其中串行计算是基于单线程串行处理数据和任务,而并行计算是利用Matlab并行计算工具箱,在多核和多处理器计算机上执行数据并行和任务并行的算法,将串行Matlab应用程序转换为并行Matlab应用程序,从而提高计算机处理速率。具体的并行计算处理方法如下:
1)初始化Matlab并行计算环境;
2)利用Parallel Computing Toolbox(并行计算工具箱),使用parfor(并行for循环)和spmd(单程序多数据)注释代码段,几乎不需要修改全部代码,对串行Matlab代码进行并行转换,缩短算法运行时间;
3)终止Matlab并行计算环境。
表2是在采用串行计算下六种特征参数进行说话人识别的时间比较。表3是采用并行计算下本文特征参数在不同GMM混合度的识别时间。从表2可以看出,在串行计算下,无论哪个混合阶数,本文方法与MFCC、LPMFCC、MFCC+LPMFCC与XF特征方法相比,所用时间最长。时间的增加是由于本文方法增加了1维TEOCC特征参数,增大了计算的复杂度,使特征提取时间增多,增大了系统训练和识别时间。从表3可以看出,当采用并行计算时,本文方法的实时性得到了进一步提高。与串行计算相比,其识别时间几乎缩短了一半,具体处理时可采用该方法来获得更好的实时性。
3 结语
通过综合MFCC和LPMFCC以及TEO等特征,提出了基于Fisher线性判别准则,将这三种特征有效地相结合的说话人识别方法。Matlab软件仿真,采用TIMIT语音库和NOISEX92噪声库进行说话人识别实验,结果表明,在纯净语音条件下本文提出的混合特征参数方法平均识别率比MFCC方法、LPMFCC方法、MFCC+LPMFCC方法、XF特征方法与PCMLT方法分别提高了21.65%、18.39%、15.61%、15.01%与22.30%;并且在噪声条件下本文方法说话人识别性能较MFCC、LPMFCC、MFCC+LPMFCC与XF特征方法以及PCMLT方法均更优,且具有更好的鲁棒性。但是由于本文方法增加了1维TEOCC特征参数,相比MFCC、LPMFCC与MFCC+LPMFCC方法稍微增大了系统训练和识别时间,所以还需要进一步研究改进。
参考文献:
[1]MEHLA R, AGGARWAL R K. Automatic speech recognition: a survey[J]. International Journal of Advanced Research in Computer Science and Electronics Engineering (IJARCSEE), 2014, 3(1): 45-53.
[2]赵力. 语音信号处理[M]. 北京: 机械工业出版社, 2003:1-4.(ZHAO L. Speech Signal Processing[M]. Beijing: China Machine Press, 2003: 1-4.)
[3]王炳锡,屈丹,彭煊.实用语音识别基础[M].北京:国防工业出版社,2005:147-149. (WANG B X, QU D, PENG X. Practical Fundamentals of Speech Recognition[M]. Beijing: National Defense Industry Press, 2005: 147-149.)
[4]YUJIN Y, PEIHUA Z, QUN Z. Research of speaker recognition based on combination of LPCC and MFCC[C]// Proceedings of the 2010 IEEE International Conference on Intelligent Computing and Intelligent Systems. Piscataway, NJ: IEEE, 2010, 3: 765-767.
[5]余建潮,张瑞林.基于MFCC和LPCC的说话人识别[J].计算机工程与设计, 2009, 30(5): 1189-1191.(YU J C, ZHANG R L. Speaker recognition method using MFCC and LPCC features [J]. Computer Engineering and Design, 2009, 30(5): 1189-1191.)
[6]张晓俊,陶智,吴迪,等.采用多特征组合优化的语音特征参数研究[J].通信技术,2013, 45(12): 98-100. (ZHANG X J, TAO Z, WU D, et al. Study of speech characteristic parameters by optimized multifeature combination[J]. Communications Technology, 2013, 45(12): 98-100.)
[7]JING X, MA J, ZHAO J, et al. Speaker recognition based on principal component analysis of LPCC and MFCC[C]// Proceedings of the 2014 IEEE International Conference on Signal Processing, Communications and Computing. Piscataway, NJ: IEEE, 2014: 403-408.
[8]宋乐,白静.说话人识别中改进特征提取算法的研究[J]. 计算机工程与设计, 2014, 35(5): 1772-1775.(SONG L, BAI J. Study of improving feature extraction algorithm in speaker recognition[J]. Computer Engineering and Design, 2014, 35(5): 1772-1775.)
[9]岳倩倩,周萍,景新幸. 基于非线性幂函数的听觉特征提取算法研究[J]. 微电子学与计算机,2015,32(6):163-166. (YU Q Q, ZHOU P, JING X X. The auditory feature extraction algorithm based on powerlaw nonlinearity function[J]. Microelectronics & Computer, 2015, 32(6): 163-166.)
[10]李梦超.基于说话人识别的特征参数提取改进算法的研究[D].南京:南京师范大学,2014:27-36. (LI M C. The modified extractionalgorithms of feature parameters based on speaker recognition[D]. Nanjing: Nanjing Normal University, 2014: 27-36.)
[11]KANEDERA N, ARAI T, HERMANSKY H, et al. On the importance of various modulation frequencies for speech recognition[C]// Proceedings of the 5th European Conference on Speech Communication and Technology. Rhodes:ISCA, 1997: 1079-1082.
[12]甄斌,吴玺宏,刘志敏,等.语音识别和说话人识别中各倒谱分量的相对重要性[J].北京大学学报(自然科学版),2001,37(3):371-378.(ZHEN B, WU X H, LIU Z M, et al. On the importance of components of the MFCC in speech and speaker recognition[J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2001, 37(3): 371-378.)
[13]鲜晓东, 樊宇星. 基于Fisher比的梅尔倒谱系数混合特征提取方法[J]. 计算机应用, 2014,34(2):558-561. (XIAN X D, FAN Y X. Parameter extraction method for Mel frequency cepstral coefficients based on Fisher criterion[J]. Journal of Computer Applications, 2014, 34(2): 558-561.)
[14]KAISER J F. On a simple algorithm to calculate the “energy” of a signal[C]// Proceedings of the 1988 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 1990: 381-384.
[15]李晋徽,杨俊安,项要杰.基于高斯滤波器及费舍尔准则的特征提取方法[J].电路与系统学报, 2013, 18(2): 400-404. (LI J H, YANG J A, XIANG Y J. The feature sets extracting method based on Gaussian filter and Fisher criterion[J]. Journal of Circuits and Systems, 2013, 18(2): 400-404.)
[16]LI Q, REYNOLDS D A. Corpora for the evaluation of speaker recognition systems[C]// Proceedings of the 1999 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 1999, 2: 829-832.
[17]VARGA A, STEENEKEN H J M, TOMLINSON M, et al. The NOISEX92 study on the effect of additive noise on automatic speech recognition[R]. Malvern: DRA Speech Research Unit, 1992.
