基于时间上下文跟踪学习检测的指尖跟踪方法
2016-05-14侯荣波康文雄房育勋黄荣恩徐伟钊
侯荣波 康文雄 房育勋 黄荣恩 徐伟钊


摘要:针对在基于视频的空中签名认证系统中,现有方法无法满足指尖跟踪的准确性、实时性和鲁棒性要求的问题,在对比研究目前常用的多种跟踪方法的基础上,提出一种基于时间上下文的跟踪学习检测(TLD)方法。在原始TLD算法的基础上引入时间上下文信息,即相邻两帧间指尖运动具有连续性的先验知识,自适应地缩小检测和跟踪的搜索范围,以提高跟踪的速度。对12组公开的1组自录的视频序列的实验结果表明,改进后的TLD算法能够准确地跟踪指尖,并且跟踪速度达到43帧/秒;与原始TLD跟踪算法相比,准确率提高了15%,跟踪速度至少提高1倍,达到了指尖跟踪的准确性、实时性和鲁棒性要求。
关键词:目标跟踪;指尖跟踪;跟踪学习检测算法;时间上下文;人机交互
中图分类号:TP242.6 文献标志码:A
Abstract:In the video based inair signature verification system, the existed methods cannot meet the requirement of accuracy, real time, robustness for fingertip tracking. To solve this problem, the TrackingLearningDetection (TLD) method based on temporal context was proposed. Based on the original TLD algorithm, the temporal context massage, namely the prior knowledge that the movement of fingertip is continuity in two adjacent frames, was introduced to narrow the search range of detection and tracking adaptively, thereby improving tracking speed. The experimental results on 12 public and 1 selfmade video sequences show that the improved TLD algorithm can accurately track fingers, and tracking speed can reach 43 frames per secend. Compared with the original TLD tracking algorithm, the accuracy was increased by 15% and the tracking speed was increased more than 100%, which make the proposed method meet the realtime requirements for fingertip tracking.
Key words:object tracking; fingertip tracking; TrackingLearningDetection (TLD) algorithm; temporal context; human computer interaction
0 引言
在广泛的计算机视觉应用的系统中,比如智能监控、人机交互、医疗诊断、导航制导等,目标跟踪是这些系统的重要组成部分[1]。
虽然目前的文献提出了许多跟踪算法,但是目标跟踪仍然是个尚未解决的极具挑战性的问题。因为在目标运动过程中,目标姿态的变化、光照强度的变化、目标遮挡等因素会导致目标的外形发生改变,给跟踪带来了极大的难度。一个有效的目标模型是跟踪算法极为重要的一部分得到广泛关注。按照目标的模型,跟踪算法可以分为生成模型和判别模型两类。
生成模型的跟踪算法通常是通过学习来建立一个目标模型,然后利用它来计算图像中每一点的分数,分数最高的则为目标。Black等[2]实现了通过学习一个离线的子空间模型来表示跟踪目标。增强视觉跟踪(Incremental Visual Tracking, IVT)方法[3]则是通过利用增量子空间模型来应对目标外观的变化。L1跟踪器利用目标和简单模板的稀疏线性组合来为目标建模,但L1跟踪器的计算量相当大,从而限制了它在实时系统的应用。Li等[4]利用正交匹配跟踪算法来进一步改善L1跟踪器,有效地解决了优化问题。胡昭华等[5]利用多种特征联合的稀疏表示了跟踪目标,克服了单一特征描述目标能力较差的缺点,充分发挥了不同特征目标能力的优点。Zhang等[6]提出的基于时空上下文的跟踪算法(SpatioTemporal Context, STC),利用目标与其周围背景的联系,包括距离及其方向和像素特征,来表示目标,通过计算目标似然的最大值来确定目标的位置,该算法能够很好地解决目标被遮挡问题,但当目标消失然后出现后,由于缺少检测模块,无法对目标进行跟踪。
判别模型的跟踪算法则是把跟踪问题当作是一个二值分类问题,通过利用一个分类器来区分目标和背景,这是目前最常用的跟踪算法。Avidan等[7]通过利用支持向量机(Support Vector Machine, SVM)分类器来改善光流法来用于对目标的跟踪,而Collin[8]证明了大多数判别特征可以通过在线学习来更好地区分目标与背景。此外,Grabner等[9]提出了一种在线Boosting算法来选择特征。但上述三种跟踪算法只用到了一个正样本和少量的负样本来更新分类器,当目标外观模型的更新受到噪声的干扰时,就会导致目标漂移而使得跟踪失败。Grabner等[10]提出了一种在线的半监督的boosting算法来解决漂移问题,Babenko等[11]运用了多示例学习(Multiple Instance Learning,MIL)算法来实现在线跟踪,MIL算法采用了密集采样的方法来解决更新分类器时训练样本少的问题,提高了跟踪器的鲁棒性,但是训练如此多的样本需要消耗大量的计算时间。郭鹏宇等[12]提出了在线混合随机朴素贝叶斯跟踪器方法,通过融合纹理和形状两类特征,以及分类器误差调整混合系数,实现分类器的在线学习和更新。Zhang等[13]把压缩感知采样方法应用到跟踪算法中,该方法将正负样本通过尺度变换,对样本量进行扩充,然后将这个多尺度的样本空间的样本通过稀疏矩阵投影到低维空间中。如此一来,既保证了样本的准确度,又有效地降低了计算量。Sun等[14]提出了目标上下文预测的跟踪算法(Tracking with Context Prediction, TCP),把目标附近的物体和目标的特别部分当作辅助目标,利用传统的跟踪算法跟踪辅助目标来预测目标的位置。Zhang等[15]提出的结构保留目标跟踪 (Structure Preserving Object Tracker, SPOT)方法,把单个目标分割成多个小块,然后利用个小块间的联系来表示目标,从而很好地解决了由于目标遮挡而导致跟踪失败的问题。
对于在不确定的环境下的长时间跟踪问题,仅仅通过学习目标的描述或判别特征无法确保跟踪系统的鲁棒性。Yang等[16]提出一种有上下文意识的跟踪算法(ContextAware Tracking, CAT)来跟踪目标周围区域而不是目标本身。该算法充分利用了有利于跟踪的一些辅助目标,使之对目标具有一致的运动关联性,从而避免了目标的漂移问题。Saffari等[17]提出了一种多类的增强线性规划(Linear Programming Boosting, LPBoost)算法来解决跟踪问题。该算法把跟踪问题看成是一个多类的分类问题,虽然在简单环境下,它能很好地跟踪目标,但是当环境变得复杂时,包括目标遮挡,光照强度变化情况下,跟踪效果会变得很差。Grabner等[18]运用了一种有用的目标特征——支持向量的清晰度来预测目标的位置,当目标不可见时,该算法利用强运动耦合,运用一些相关联的空间上下文信息来确定目标,但是,该算法的检测需要大量的时间,并且目标的运动难以预测。
本文算法在原始的跟踪学习检测(TrackingLearningDetection, TLD)算法[19]的基础上,提出基于时间上下文的TLD目标跟踪算法。TLD跟踪算法是基于跟踪、检测和学习的长时间跟踪未知物体的算法,具有强鲁棒性,但算法跟踪速度较慢,无法满足应用的实时跟踪需求,为此,国内外研究人员在TLD的基础上进行了改进算法的设计和研究[20-21]。本文则通过引入时间上下文信息,利用相邻两帧间目标运动连续性的先验知识,来缩小检测和跟踪的搜索范围,由此来提高跟踪的速度。实验表明,改进后的TLD算法能够准确地跟踪捏合三指尖等物体,并且跟踪速度是原始TLD跟踪算法的至少2倍,能够达到指尖跟踪的实时性要求。
1 基于时间上下文的TLD跟踪算法
TLD是一种单目标长时间跟踪算法。该算法的主要特点在于将传统的检测算法和跟踪算法相结合来解决被跟踪目标在被跟踪过程中发生的形态变化、尺度变化、部分遮挡等问题。同时,通过PN(Positive constraint、Negative constraint)在线学习机制不断更新检测模块的目标模型及相关参数和跟踪模块的“显著特征点”,利用了跟踪、学习、检测三个模块的优势互补,实现目标的有效跟踪,但速度上仍然无法满足空中签名过程中的指尖跟踪。通过对自建系统所采集的空中签名视频进行分析,本研究发现,尽管在书写签名的过程中指尖运动速度有时会比较快,但通过高速摄像头所采集的视频中连续两帧间的指尖运动距离有限,指尖目标相距不会很远,因此本文提出了基于时间上下文的TLD跟踪算法,适当地缩小检测、跟踪范围来避免不必要的检测以及部分背景的影响,进而提高算法的跟踪速度和算法的准确率。算法的具体跟踪流程如图1所示。
1.3 目标模型更新
采用如下的策略来将一个新的已赋予标签的图像片添加到目标模型当中:只有当最近邻分类器赋予的标签同学习模块赋予的标签相矛盾时,才将其添加到目标模型当中。但这样一来,添加到目标模型的样本就略显偏少,为了解决这个问题,定义一个参数m=Sr-θNN来代表分类盈余。对于一个图像片p而言,如果其分类盈余m<λ,也将这个样本添加到目标模型当中。显然,添加到目标模型的图像片随λ的增大而增多,也就是得到一个更好的分类决策边界。为了在目标模型的更新速度和精度之间得到一个很好的平衡,本文将λ设置为0.1。
1.4 基于时间上下文的指尖检测模块
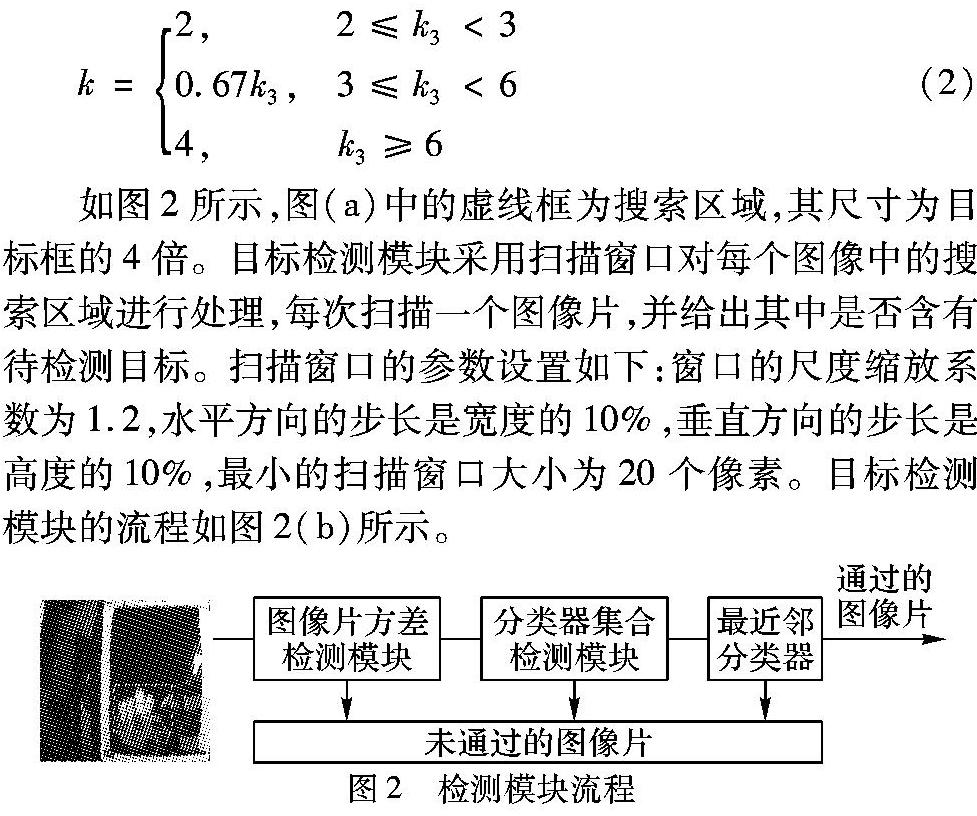
如图2所示,图(a)中的虚线框为搜索区域,其尺寸为目标框的4倍。目标检测模块采用扫描窗口对每个图像中的搜索区域进行处理,每次扫描一个图像片,并给出其中是否含有待检测目标。扫描窗口的参数设置如下:窗口的尺度缩放系数为1.2,水平方向的步长是宽度的10%,垂直方向的步长是高度的10%,最小的扫描窗口大小为20个像素。目标检测模块的流程如图2(b)所示。
可见TLD的检测模块采用的分类器是一个级联分类器。每个可能出现待检测目标的区域,依次经过图像区方差检测模块、分类器集合检测模块、最近邻分类器检测模块三个部分,任意一个部分都可以判定当前检测区域是否含有检测目标。只有依次通过这3部分的检测区域才被认定含有检测目标。
1)图像片方差检测模块:该模块是级联分类器检测模块的第一个子模块,该模块首先利用积分图来计算每个待检测图像片的方差。方差小于某个阈值的区域就被认定为包含前景目标。
2)分类器集合检测模块:该模块的输入是方差检测模块判定包含前景目标的图像片。分类器集合含有N个基本分类器,每个基本分类器所提取的特征为由像素比较获得的13位二值码。对于每个图像片而言,当所有基本分类器的后验概率的平均值如果大于50%时,就可认定当前图像片含有前景目标。
3)最近邻分类器:对待检测图像片而言,如果Sr(p,M)>θNN,那么该图像片就被认定为含有前景目标,本文取θNN=0.6。
1.5 跟踪模块
TLD的跟踪模块是一种在中值流跟踪方法的基础上增加了跟踪失败的检测算法的新跟踪方法。中值流跟踪方法通过利用目标框来表示被跟踪目标,并在连续的相邻帧之间估计目标的运动。中值流跟踪算法的前提假设是被跟踪的目标是可见的,这也就意味着,当目标被完全遮挡或者目标离开当前场景时,跟踪肯定失败。可用如下策略来应对这些情况:di代表中值流跟踪中某一个特征点的位移,而dm代表所有特征点位移的中值,可定义位移残差|di-dm|,如果残差大于10个像素,就可认为跟踪失败。这种方法可以很好地发现由于被跟踪目标移动过快或者被遮挡而造成的跟踪失败。当系统跟踪失败时,不返回目标框。
1.6 学习模块
在第一帧中,学习模块利用下面的方法生成带标签的样本来训练一个初始的检测器。生成带标签样本方法是:在目标框内生成正样本。首先在距离初始目标框最近的扫描窗口中选择10个区域,并且在每个区域内部利用几何变换生成20个仿射的区域。也就是在每个区域内部进行±1%范围的偏移、±1%范围的尺度变化、±10°的平面内旋转操作,并且可以在每个像素上增加方差为5的高斯噪声。在设定范围内随机地设置偏移、尺度变化、旋转的大小,对每个区域都进行20次这种几何变化,如此一来,10个区域就生成了200个仿射变化的区域版本。这200个区域可以作为正样本,而负样本则是通过初始目标框的周围并在搜索范围内选取,由于图片中大部分区域都是负样本,因此负样本无需进行几何变化。
在跟踪的第一帧对目标模型进行初始化后,利用PN学习来对模型进行不断的更新。PN学习包含四个部分:1)一个待学习的分类器;2)训练样本集:一些已知类别标签的样本;3)监督学习:一种从训练样本集中训练分类器的方法;4)PN experts:在学习过程中用于产生正样本和负样本的表达函数。PN学习过程如图3所示。
2 指尖的跟踪效果
为了分析基于时间上下文的TLD跟踪算法对指尖的跟踪效果,本项目录制了由14个同学书写的814个空中签名视频进行实验。由于人正常签名时,指尖的运动较快,为了能够跟踪获得书写轨迹足够的点以便获得完整的个人签名信息,本文采用分辨率为640×480的高速摄像头录制手指签名的视频。除此之外,对于视频的采集,本文还作了以下几方面的限制:1)签名者的手腕不可以出现大幅度的摆动,并且签名范围被限定在一个17cm×25cm的矩形区域内;2)背景简单,背景颜色统一为棕色。
为了能够更好地复现跟踪算法在各个测试视频上的跟踪结果,尽量降低由于初始化指尖跟踪区域的差别而导致的跟踪效果的差异,本文为选取指尖跟踪区域定了一个标准,初始化区域是一个正方形,它的面积为包含拳头的矩形区域面积的1/14,中心为三捏合指尖的中心。
2.1 指尖跟踪实验结果
本文利用成功率和帧率来分析算法对指尖的跟踪效果,其中成功率SR(Success Rate)和帧率FPS(Frames Per Second)的计算方法如下:
2.2 指尖跟踪效果分析
通过对实验结果进行分析,本研究发现改进后的TLD算法,在光照强度大、环境简单,指尖快速运动的情况下,对于指尖的上、下、左、右偏时都取得较好的效果,具有强鲁棒性。对比与原始的TLD跟踪算法,不足之处在于,当指尖运动发生突变时会出现跟踪不准确甚至是失败。部分跟踪效果如图4所示,为了进一步清晰地说明跟踪效果,本文将指尖跟踪结果的轨迹显示在图5中。从图中可以看出跟踪的轨迹能够完整准确地展现个人的空中签名,这为空中签名数据库的构建以及后续空中签名的认证奠定了良好的基础。
3 与常用跟踪算法的比较
为了进一步评估基于时间上下文的TLD跟踪算法的跟踪效果,本研究选用13组视频序列进行实验。这13组视频序列包括12组公开的以及1组本项目录制的,它们包含了遮挡、剧烈光照强度变化、姿势与尺度的变化、非刚性变换、背景群集、运动模糊和目标运动速度等影响跟踪效果的因素,视频帧的相关信息见表2。本章将提出的改进跟踪算法与最新的5种主流跟踪算法进行了比较。对于每一种跟踪算法,本项目运用了作者提供的原始代码或是二进制码,将其中的参数设置到最好的跟踪结果进行了实验。这五种跟踪算法分别是: CSK(Circulant Structure Tracker)[22]、STC、Struck(Structured Output Tracker)[23]、CT(Compressive Tracker)和TLD。由于每种跟踪算法的跟踪效果都有一定的随机性,因此,对于每一个视频序列,本研究都重复实验了10遍并以平均值作为最终的结果。由于,视频序列Car、 Jumping中的目标分别存在向右、上下快速运动的情况,搜索区域的比例系数K分别取为2.8、5。本文的跟踪算法是在i53210M 2.50GHz CPU、8GB RAM、Windows 7操作系统的计算机上用C++编程实现。
表3表明,改进的TLD跟踪算法在Car、David、Pedestrian、Fingers、FaceOcc2、Walking测试视频上的跟踪成功率较高,在大多数的测试视频上的跟踪成功率高于TLD,如,David、Fingers、FaceOcc2、Walking。对于David测试视频,改进的TLD的成功率远大于TLD的成功率,主要原因在于,David视频的前部分序列中人脸目标和背景都是黑色的,TLD在整张图像中检测目标,背景对目标模型影响较大,检测器逐渐引入了错误的目标模型,最终导致跟踪失败;而改进的TLD因为限制了检测区域,减少了背景的影响,所以跟踪成功率有了较大的提高。对于Jumping视频,由于人脸模糊且人的快速跳动,同时改进的TLD缩小了检测区域,其检测器的负样本较少,因此改进的TLD的检测模块的分类效果较TLD差。对于Skiing测试视频,由于视频中的目标较小,特征不明显并且目标快速运动的同时发生旋转,目标外观发生了巨大的变化,导致实验中的几种跟踪算法只能跟踪视频的前几帧,跟踪成功率较低。
在计算CLE时,由于算法在一些图像中判断为没有目标,因此本文不计算这种情况的CLE值,表5为跟踪算法在每一个标准视频中有跟踪到目标的帧数,从表中可以得知,只有TLD和改进的TLD在跟踪过程出现判断为没有目标的情况,其他几种跟踪算法在每一帧视频中都会给出一个目标区域。在Animal测试视频中,由于动物以及相机的运动,导致TLD和改进的TLD无法准确地跟踪目标,在部分视频帧中丢失了目标。在Tiger1测试视频中,TLD和改进的TLD跟踪到目标少的原因在于视频中目标的遮挡、外观变化、旋转以及光照强度发生变化的影响。表4表明,改进的TLD的CLE值普遍较小,取得最小的平均CLE值。对于大部分的测试视频,改进的TLD的CLE值较TLD的CLE值小。只有在Skiing视频中,改进的TLD的CLE值远大于TLD的CLE值,这是因为改进的TLD在视频中有较多帧是跟踪错误的。
表6表明,对于大部分的测试视频,改进的TLD的FPS是TLD的2~3倍,其中,对于Fingers、Girl、Sylvester分别是5、10、8倍。改进的TLD的平均速度为43frame/s,达到了实时跟踪的要求。
3.2 跟踪算法比较的定性分析
图6是本文跟踪算法和常用的5种跟踪算法的部分跟踪效果图。由于CSK没有测试Car视频,Struck没有测试David视频,因此,图6(e)、(f)分别没有Car、David的跟踪效果图,具体的分析如下(#x表示第x帧)。
1)光照强度、目标尺度和姿态的变化:在这些测试视频中存在着大量的光照强度发生变化的情况。在David视频中,David由于从黑暗处走向亮处,光照强度发生巨大的变化,同时David的脸部尺度和姿态在一些帧也发生了变化。大多数文献在测试这个视频时都会忽略开始时脸部完全黑暗的一部分,本次实验对整个视频进行测试。本算法和STC在这6种跟踪算法中跟踪效果最好。在Girl视频中,目标在平面外旋转,姿态发生变化,同时光照强度和目标姿态也发生了变化,本算法能够准确跟踪目标。
2)目标遮挡和姿态的变化:在FaceOcc2视频中,人脸受到了严重的遮挡,以及它的姿态也发生了极大的改变。CSK、Struck和本算法能够准确跟踪。在Car视频中,当目标被遮挡时,TLD、Struck和本文的算法能准确地跟踪目标。
3)目标的快速运动:在Fingers视频中,由于指尖的快速运动,导致了三捏合指尖的外观极度模糊,给跟踪带来极大的挑战。只有TLD和本算法能够准确跟踪,本算法具有最高的成功率,因为本算法中的检测模块是由三个分类器级联而成的,并且在跟踪过程中,借助学习模块有效的更新,能够准确地检测目标。
4 结语
为了解决TLD算法跟踪速度慢的问题,满足空中签名认证系统的实时性需求,本文提出了基于时间上下文的TLD跟踪算法,引入时空上下文信息,即利用相邻两帧间目标运动连续性的先验知识,缩小搜索范围以提高跟踪速度。实验表明,本文的跟踪算法能够准确跟踪指尖,跟踪获得的签名字迹能够完整准确地反映了个人的空中签名。同时,算法的跟踪成功率和跟踪速度都优于原始的TLD算法,其中平均跟踪速度达到了43帧/s,达到跟踪的实时性标准。但算法仍存在不足,当指尖的运动发生突变或拐弯时,算法容易跟踪失败。今后将会在检测和跟踪方面结合目前常有的方法的优点来改善TLD跟踪算法的性能,使其更好地应用在基于视频的签名认证系统当中,乃至其他的与目标跟踪相关的应用系统。
参考文献:
[1]YILMAZ A, JAVED O, SHAH M. Object tracking: a survey[J]. ACM Computing Surveys, 2006, 38(4): Article No. 13.
[2] BLACK M J, JEPSON A D. Eigentracking: robust matching and tracking of articulated objects using a viewbased representation [J]. International Journal of Computer Vision, 1998, 26(1): 63-84.
[3] ROSS D A, LIM J, LIN RS, et al. Incremental learning for robust visual tracking [J]. International Journal of Computer Vision, 2008, 77(1): 125-141.
[4] LI H, SHEN C, SHI Q. Realtime visual tracking using compressive sensing [C]// CVPR 2011: Proceedings of the 2011 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2011: 1305-1312.
[5]胡昭华,徐玉伟,赵孝磊,等.多特征联合的稀疏跟踪方法[J].计算机应用,2014,34(8):2380-2384. (HU Z H, XU Y W, ZHAO X L, et al. Sparse tracking algorithm based on multifeature fusion [J]. Journal of Computer Applications, 2014, 34(8): 2380-2384.)
[6]ZHANG K, ZHANG L, LIU Q, et al. Fast visual tracking via dense spatiotemporal context learning [C]// ECCV 2014: Proceedings of the 13th European Conference on Computer Vision, LNCS 8693. Berlin: SpringerVerlag, 2014: 127-141.
[7]AVIDAN S. Support vector tracking [C]// CVPR 2001: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2001, 1: 184-191.
[8]COLLINS R T, LIU Y, LEORDEANU M. Online selection of discriminative tracking features [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(10): 1631-1643.
[9]GRABNER H, GRABNER M, BISCHOF H. Realtime tracking via online boosting [C]// BMVC 2006: Proceedings of the 2006 British Machine Vision Conference. Nottingham, UK: BMVA Press, 2006, 1: 47-56.
[10]GRABNER H, LEISTNER C, BISCHOF H. Semisupervised online boosting for robust tracking [C]// ECCV 2008: Proceedings of the 10th European Conference on Computer Vision, LNCS 5302. Berlin: SpringerVerlag, 2008:234-247.
[11]BABENKO B, YANG M, BELONGIE S. Robust object tracking with online multiple instance learning [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(8): 1619-1632.
[12]郭鹏宇,苏昂,张红良,等.结合纹理和形状特征的在线混合随机朴素贝叶斯视觉跟踪器[J].光学学报,2015,35(3):0315002. (GUO P Y, SU A, ZHANG H L, et al. Online mixture of random naive Bayes tracker combined texture with shape feature [J]. Acta Optica Sinica,2015,35(3): 0315002.)
[13]ZHANG K, ZHANG L, YANG MH. Realtime compressive tracking [C]// ECCV 2012: Proceedings of the 12th European Conference on Computer Vision, LNCS 7574. Berlin: SpringerVerlag, 2012: 864-877.
[14]SUN Z, YAO H, ZHANG S, et al. Robust visual tracking via context objects computing [C]// Proceedings of the 2011 IEEE International Conference on Image Processing. Piscataway, NJ: IEEE, 2011: 509-512.
[15]ZHANG L,van der MAATEN L J P. Preserving structure in modelfree tracking [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(4): 756-769.
[16]YANG M, WU Y, HUA G. Contextaware visual tracking [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(7): 1195-1209.
[17]SAFFARI A, GODEC M, POCK T, et al. Online multiclass LPBoost [C]// CVPR 2010: Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2010: 3570-3577.
[18]GRABNER H, MATAS J, VAN GOOL L, et al. Tracking the invisible: learning where the object might be [C]// CVPR 2010: Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2010: 1285-1292.
[19]KALAL Z, MIKOLAJCZYK K, MATAS J. Trackinglearning detection [J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(7): 1409-1422.
[20]周鑫,钱秋朦,叶永强,等.改进后的TLD视频目标跟踪方法[J].中国图象图形学报,2013,18(9):1115-1123. (ZHOU X, QIAN Q M, YE Y Q, et al. Improve TLD visual target tracking algorithm [J]. Journal of Image and Graphics, 2013, 18(9):1115-1123.)
[21]金龙,孙涵.TLD视频目标跟踪方法改进[J].计算机与现代化,2015(4):42-46. (JIN L, SUN H. An improve TLD visual target tracking method [J]. Computer and Modernization, 2015(4): 42-46.)
[22]HENRIQUES J F, CASEIRO R, MARTINS P, et al. Exploiting the circulant structure of trackingbydetection with kernels [C]// ECCV 2012: Proceedings of the 12th European Conference on Computer Vision, LNCS 7575. Berlin: SpringerVerlag, 2012: 702-715.
[23]HARE S, SAFFARI A, TORR P H S. Struck: structured output tracking with kernels [C]// ICCV 2011: Proceedings of the 2011 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2011: 263-270.
