基于复述的中文自然语言接口
2016-05-14张俊驰胡婕刘梦赤
张俊驰 胡婕 刘梦赤

摘要:针对传统以句法分析为主的数据库自然语言接口系统识别用户语义准确率不高,且需要大量人工标注训练语料的问题,提出了一种基于复述的中文自然语言接口(NLIDB)实现方法。首先提取用户语句中表征数据库实体词,建立候选树集及对应的形式化自然语言表达;其次由网络问答语料训练得到的复述分类器筛选出语义最相近的表达;最后将相应的候选树转换为结构化查询语句(SQL)。实验表明该方法在美国地理问答语料(GeoQueries880)、餐饮问答语料(RestQueries250)上的F1值分别达到83.4%、90%,均优于句法分析方法。通过对比实验结果发现基于复述方法的数据库自然语言接口系统能更好地处理用户与数据库的语义鸿沟问题。
关键词:数据库自然语言接口;词向量;复述;自然语言表达;机器学习
中图分类号:TP391.1 文献标志码:A
Abstract:In this paper, a novel method for Chinese Natural Language Interface of Database (NLIDB) based on Chinese paraphrase was proposed to solve the problems of traditional methods based on syntactic parsing which cannot obtain high accuracy and need a lot of manual label training corpus. First, key entities of user statements in databases were extracted, and candidate tree sets and their tree expressions were generated. Then most relevant semantic expressions were filtered by paraphrase classifier which was obtained from the Internet Q&A training corpus. Finally, candidate trees were translated into Structured Query Language (SQL). F1 score was respectively 83.4% and 90% on data sets of Chinese America Geography (GeoQueries880) and Questions about Restaurants (RestQueries250) by using the proposed method, better than syntactic based method. The experimental results demonstrate that the NLIDB based on paraphrase can handle the semantic gaps between users and databases better.
Key words:Natural Language Interface of DataBase (NLIDB); word vector; paraphrase; natural language expression; machine learning
0 引言
随着现代信息技术的发展以及数据的海量式增长,人们希望以更自然、便捷的方式从数据库中获取信息,数据库自然语言接口(Natural Language Interface of DataBase, NLIDB)应运而生,旨在帮助用户使用熟悉的自然语言(如中文)从结构化存储系统中获取信息,消除计算机与人之间的“隔阂”。
Rodolfo等[1]从不同角度分析、总结了目前主流的NLIDB系统,大体分为两类:一类是以规则匹配、句法分析或语义规则[2-6]等为主要技术手段,分析用户查询语义然后转换为结构化查询语言(Structured Query Language, SQL),即自然语言到SQL的直接映射;另一类是首先将自然语言翻译成一种中间层表示的逻辑查询语言,再转换为SQL[7-9],这种方法由于具有数据库无关、领域适应性等特点,成为近年来该领域研究的热点。然而,以上方法的难点在于需要直接处理用户灵活多变的查询语义,由于目前词法分析、句法分析技术尚未达到足够高的正确率,语义分析阶段的错误将导致最后生成的SQL不符合用户查询意图。
近来,一些学者将NLIDB转换为最优结构筛选问题,即对用户输入首先生成可能的候选结构集,再借用规则或统计学方法对其排序,最后取分数最高的候选结构转换为SQL[10-13]。目前上述方法主要依赖人工编写规则以及标注语料,不便于跨领域使用。根据文献[1]总结的查询问题发现,仅依靠输入语句与数据库模式很多情况无法筛选出正确结构,例如,问句“有多少人居住于亚拉巴马州?”“亚拉巴马州有多少公民?”“亚拉巴马州的人数几何?”查询目标都应匹配到数据库属性“人口”。为弥补这种语义差异,文献[14-15]使用信息抽取方法从大规模文本中学习出词汇与知识库实体之间的映射关系,但实际中,该方法受限于知识库的大小以及信息抽取的准确度。
综合以上问题,本文提出了一种基于复述的中文自然语言接口(Paraphrase Natural Language Interface, PaNLI)实现方法。PaNLI使用网络问答平台提供的大量“类似问题”“相关知识”作为复述(paraphrases)训练语料,这些语料涉及领域广泛且来自用户的真实提问,训练得到的复述分类器能更好地解决NLIDB语义鸿沟问题。PaNLI首先提取出句子中可映射到数据库元素的实体词,并通过子树遍历等操作得到候选树集与初始排序;其次根据候选结构匹配的属性句法类别结合规则模板生成若干个形式化的自然语言表达;最后利用训练得到的支持向量机模型(Support Vector Machine, SVM)分类器计算输入语句与形式化自然语言表达的语义相关度,重新排序候选树集,将得到的最优候选树转换为SQL。
使用机器学习方法处理分类问题时,关键点在于对问题抽取合适的特征表示,以往句子表示通常使用词袋模型,即不考虑词语顺序以及关联信息。本文提出一种富语义的句子级特征表示方法,使用Word2Vec工具[16]在大量未标注文本上训练得到词语的低维向量表示,结合依存句法分析结果,得到句子的多维语义特征表示。实验表明该特征表示方法能有效提高复述分类精度。
1 系统组成
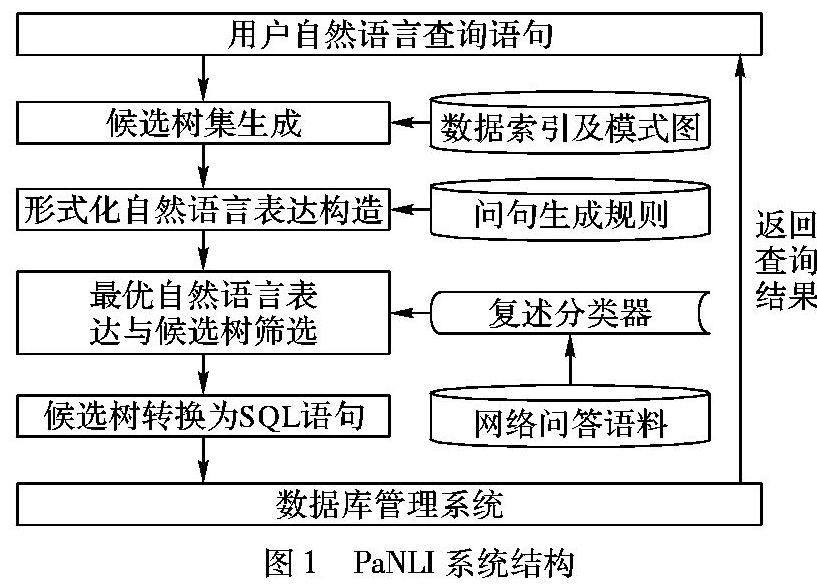
数据库自然语言接口PaNLI系统结构如图1所示,主要由以下4个模块构成:1)候选集生成;2)形式化自然语言表达构造;3)最优自然语言表达与候选树筛选;4)候选树转换为SQL语句。
1.1 数据库预处理
数据库预处理包含索引以及模式图建立。为提高查全率,首先,采用基于信息检索的细粒度分词方法[17]对数据库中的模式及实例分词建立索引;其次,将数据库模式G(V,E)视为一个有向图结构,其中V包含关系名以及属性名两种节点,E分为关系属性边和主键外键边。对E中每条边e赋予一个0~1的权值ω(e),值越高表明连通性越强,本文依据包含e的实例数量与实例总量的比值来设置边的初始权值。
1.2 候选结构建立
文献[10]以句子的依存句法分析为输入,生成多个候选SQL语句,使用机器学习方法计算SQL与句子短语结构树之间的相似程度,该方法不足之处在于SQL语句与自然语言从结构以及语法上都有很大差异,虽然可以将两者以树结构表示,但是其所表达的语义无法证明具有相似性。
本文中,该模块使用预建立的词表匹配出用户输入语句中的数据库实体词,以此生成包含正确语义结构的候选树集。对每一个候选树,根据其匹配属性的句法类别结合规则模板构造出若干形式化自然语言表达,使得语义相似度计算发生在同类型语言中,计算结果更加合理。
1.3 复述分类器
该模块利用网络问答平台提供的主题类似问题作为原始语料,首先使用分类方法过滤掉部分杂质语句,在筛选出的语料中人工标注少量复述问句对;然后应用半监督学习方法扩充复述语料;最后训练得到一个基于支持向量机的排序复述分类器。本文使用该分类器对生成的自然语言表达按照语义相近程度排序,该方法提供了两方面的优势:1)复述方法避免了对用户的原语句直接语义分析,使得转换的正确率不会过于依赖预定义规则以及句法分析的正确率;2)用户时常隐晦地表达查询谓词,例如,问句“有多少人居住在亚拉巴马州?”其中“居住”与属性“人口”有语义关联关系,复述方法尤为适合解决这种语义鸿沟问题。
1.4 结构化查询语句生成
SQL生成是将经过筛选的符合预定义的语义规则(见第2章)的候选结构树,按照数据库模式图进行调整(包括插入路径缺失节点、属性关系名替换等)转换为数据库能直接执行的结构化查询语句的过程。将候选结构树转换为SQL的方法与生成自然语言表达的方法类似,故本文不再单独描述。
2 候选树集生成
给定一个输入查询语句q及数据库DB,首先抽取出若干可映射到数据库元素的实体词WD以及对应的数据库元素S,其次由WD生成符合语义规则的候选树集Tq。在关系数据库中,定义数据库元素S包括关系名R、属性名A以及属性值V。为简化生成过程,预先将具有固定表达的聚类函数词(如,最多、总和、平均值等)以及逻辑操作词(如,大于、等于、并且等)分离出来。
生成算法的基本思想是通过子树移动操作来遍历(WD,S)可能的树结构,考虑到候选树集随着WD增加呈指数级增长,在子树移动的过程中根据模式图以及语义规则裁剪掉不可能生成正确结构的子树。候选树生成算法表述如下:
3 形式化自然语言表达构造
以往的NLIDB系统侧重于自然语言到结构化语句的单方向研究,而一个用户友好的系统应同时具备逆向翻译功能[19],即把执行语句以用户熟悉的语言呈现。本文中,该逆向过程除了用于结果呈现,更重要的作用是作为候选树筛选的“中间自然语言”,使用复述方法计算语义相似度。
文献[20]使用基于图的多种合并方法将SQL转换为自然语言表达。这里,候选树是由模式图路径生成得到的直观结构,仅需使用若干固定模板即可完成转换。表1中归纳了形式化自然语言表达构造模板(加粗的词为表格中S(a)类别),其中关系名、属性值、聚类函数、操作符由S(r)、S(v)、AGGR、OPR表示,S(a)为属性名的句法类别。生成的问句分为两类,分别以“……是多少”、“……是什么”结尾或以疑问词“哪些……”开头,然后关系名S(r)作为句子描述部分的起始词,其后包含属性值S(v)、聚类函数AGGR、操作符OPR,本文根据模式中属性名S(a)所属的句法类别(NP、VP等)构造句子顺序并添加必要的结构助词。
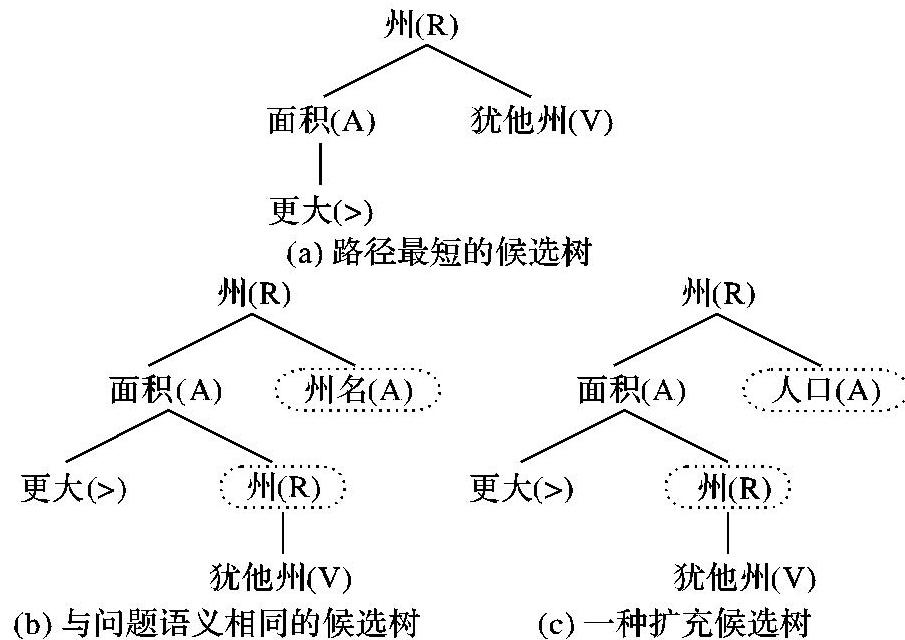
在生成的候选树结构中,根节点关系名作为句子描述部分的起始词,若其直接子节点包含属性值则使用第一种类型的问句模板,否则使用以“哪些”开头的第二种模板。属性值S(v)通常作为条件限定where的组成部分,从而不包含S(v)子节点的关系名或属性名作为句中的查询目的,其在模板中紧靠疑问代词。当候选树的结构较复杂时,本文使用模板合并的方法构造长问句,例如图2中的候选树(c),结合表1的模板规则1、4生成问句“哪些州的面积大于犹他州的面积,其人口是多少?”,合并过程中使用代词“其”连接多条规则,避免生成冗余的自然语言表达。
数据库模式中每个主外键关系R都有一个R′与其互为逆关系(例如,“首都”和“所属国家”)。对每一个候选结构树t,本文生成具有相同语义的结构树t′,其中关系R由R′替代。由逆关系建立的候选结构使用不同的规则模板生成自然语句,实体在规则中交换主语和宾语位置。最后将t′生成的自然语句添加到结构树t的对应形式化自然语言表达集中。对美国地理问答数据集(GeoQueries880),每条用户查询,平均对应生成132条形式化自然语句。
4 复述方法
复述,通俗来讲,就是对相同语义的不同表达[21],在机器翻译、自动问答、信息抽取以及自然语言生成等领域有着诸多应用[22],但目前复述语料抽取方法不够完善,构建一个含有大量复述句对的语料库周期长且资源获取困难。
在NLIDB系统研究中,本文主要关注问句形式的复述语料,通过对百度知道、搜狗问问等平台的观察发现,大量具有相同含义的提问以“类似问题”“相关知识”等形式在主题页面中展现,
例如,百度知道用户的提问“有多少人居住在上海?”,该页面的其他类似问题包括“上海现在住的人口有多少?”“居住于上海的,目前大概有多少人口?”等。对于搜索引擎本身,其后台积累了大量用户搜索、提问日志,通过聚类、挖掘等操作可以将具有类似语义的提问归结起来,本文以页面中的提问以及类似问题作为一个基本块(平均包含1条主题问句以及5条类似问题),大量抽取以块为单位的复述训练语料。
4.1 语料处理
从网络上抽取得到的原始语料中包含枚举、事实、概念等多种问题类型,NLIDB系统不同于自动问答系统,不能处理例如“中国为什么要进行改革开放?”这种概念性问题。本文将问题类型分为可处理(枚举、需求、事实、是非)与不可处理(概念、推荐、评价)两类,使用复旦中文问答系统问题标注集作为语料,按照文献[23]中的方法训练得到一个二值分类器,过滤掉不可处理问题及其类似问题,由于该分类目的是筛选出不可处理的杂质语料,减少人工筛选工作量,其分类准确度不会影响最后结果。筛选出的可处理数据中以块为基础使用少量人工标注出语义相同(复述语料标记为1)以及语义不同(非复述语料标记问0)的问句对,最后得到4800条人工标注训练集。网络问答平台中用户提问覆盖多个领域,对于自然语言接口系统,通过观察发现领域相关联的问答语料更能提升系统转换效果,从而对训练复述集,本文根据其在网络平台中的所属类别将问句分类。实际应用时,针对不同的查询领域本文选择不同的分类复述语料。
4.2 训练数据扩充
在人工标注的少量复述语料基础上,本文使用基于协同训练的半监督学习方法扩充训练语料,其核心思想是:对于一个未标注样本,如果SVM、随机森林以及最大熵中两个分类器的判别一致,则将该样本进行标记,并将其纳入另一个分类器的训练样本;如此重复迭代,直至所有训练样本都被标记或者三个分类器不再有变化。
4.3 向量空间模型
在模型训练之前需使用合适的方法表示句子,传统的文本处理方法词袋模型(BagOfWords, BOW),将文本拆解为单词,以单词作为矢量空间的维度,以每个单词在文本中出现的频率作为文本矢量对应维度的值。BOW的缺点是忽略了词语在文本中出现的先后次序,并且没有考虑词语的语义信息(实验5.2节)。
词向量模型最早由Hinton提出,它将所有词映射到一个低维实数向量空间,语义相近的词在向量空间中的距离也更近。本文使用文献[16]所提出的Word2Vec工具设置窗口大小为5的CBOW模型以及hierarchical softmax方法,在中文维基百科上训练得到词语语义的Word Embedding模型。Word2Vec是一个无隐含层的神经网络,直接训练词的N维(本文中设置N为50)实数向量与内部节点向量的条件概率。训练结果中,任意两个词的语义相关程度可以通过计算两个词对应向量的余弦相似度得到。
除了词向量,本文同时还考虑依存句法关系的低维向量特征表示。本文使用斯坦福依存句法分析器[24],依存弧标记δ={amod,tmod,nsubj,csubj,dobj,…}是相对离散的标签集合,也有类似词语的语义相关性。例如amod(形容词修饰)与num(数词修饰)更相近而不是nsubj(名词性主语)。本文使用与词语相似的方法,将训练语料中的依存关系标记映射到向量空间模型,窗口大小设为3。
4.4 句子特征提取
特征提取是采用统计机器学习方法解决分类问题中至关重要的一个部分。本文所面向的处理对象是相对简短的问句,问句中通常包含较少的词,因此所含特征信息也相对较少。实际训练中本文考虑问句3方面的特征:词、词性以及依存句法关系。由于问句长度为变量,而训练特征维度固定,本文提出一种句子特征提取算法,结合Transitionbased句法分析[25]思想提取特征词,添加对应的词性以及依存关系特征,算法具体表述如下:
算法2 Feature_Selection。
输入 经过分词的复述问句对,词性标注,依存句法关系,Word Embedding模型,特征词数N。
输出 K维特征。
第一步 候选词添加。跟随文献[25],对arcstandard句法分析系统本文选择栈缓冲区(stack and buffer)中前3个词加入候选词集,并将依存关系中的SUBJ、OBJ以及MOD类型所包含的词加入队列Queue1及Queue2。
第二步 特征词添加。循环地从Queue1及Queue2中分别取出第一个词性为核心词性(名词、动词、形容词或疑问代词)的词语w1和w2,计算其在词向量空间上的余弦相似度θ,若θ大于阈值参数τ(0<τ<1),则将w1,w2分别添加到词语列表wordList1与wordList2中,当词语长度大于N时结束循环。如果计算得到θ小于参数τ,则加入备选列表backList1与backList2。
第三步 补足特征词。若某个结果列表中的词语数量小于3则分别计算其备选列表中的词与另条问句中的核心词性的词向量距离,并取相似度最高的词补足结果列表。若此时仍结果列表仍不足N个词,则将句中剩余词按上述方法添加。
第四步 特征生成。对每条问句,取结果列表中的N个词的实数向量总和的平均值、对应的词性标注以及依存关系类型以连接方式添加到特征向量中。
实验中发现,特征词数为3时,在系统运行效率以及准确度上的平衡最好。
4.5 最优结构树筛选
根据第4.4节提取的特征,本文使用基于径向基核函数(Radial Basis Function,RBF)的SVM模型训练得到复述分类器。由于支持向量机为判别式模型,不能直接计算特征与类别的联合概率,本文使用基于投票的SVM方法[26]得到语义相似度值P(Nt),从而候选树的总得分由如下公式得到:
5 实验结果与分析
5.1 实验数据与设置
实验包括2部分:首先是基于SVM的复述问句分类精度测试,主要观察不同大小数据集以及不同特征组合对复述分类效果的影响,测试数据为从百度知道、搜狗问问等平台抽取的“类似问题”“相关知识”经过问题处理、扩充最后得到57000条问句对,其中正例38150条(问句对为复述),反例18850条(问句对不为复述)。
其次,自然语言到SQL转换的系统测试。由于目前中文方面缺少统一的NLIDB系统测试平台,本文将英文中常用的问答测试集,美国地理问答语料(GeoQueries880)以及餐饮问答语料(RestQueries250)经过多人翻译、校对得到汉语问答测试集,简称Geo880CN、Rest250CN。为对比本文PaNLI系统的效果,本文使用当时在英文GeoQueries880上取得最好成绩的Precise [27]及基于句法分析的树核函数系统[10]作为基准,测试在不同大小、不同领域数据集的转换效果。
PaNLI以及对比系统实现使用Java语言编写,JDK版本为1.8。实验代码运行于Linux系统FedoraLiveDesktopx86,CPU 2.6GHz双核Inter Corei5,8GB 1600MHz DDR3L内存。
5.2 复述分类测试
特征词数N是实现复述问句准确分类的重要因素,同时为保证系统实际运行有效性,实验将测试上述因素对分类准确度及一条查询语句转换时间的影响。实验使用数据集的80%作为训练集,剩余20%作为测试集,使用LIBSVM作为训练及测试工具,RBF核函数惩罚因子参数C设为1。
由表2知,随着特征词数增加,系统耗时等幅增加,意味着对用户较长的等待时间,当词数达到5个时分类准确率开始下降,此时过多词数使得特征维数增加,并且引入数据杂质(如,句中“的”“是”等停用词)。实际应用中本文选择特征词数为3,在系统运行效率以及准确度上的平衡较好。
表3给出了多种特征组合下,SVM采用不同核函数的分类精度,选取的特征包括问句词袋模型表示(BOW)、词向量模型(Word Embedding)、词性标注(PartOfSpeech,POS)、依存句法关系枚举表示(Dependency Relation)及实数向量表示(Dependency Embedding)。
由表3可以看出,使用词向量模型、词性及依存关系组合作为特征,在不同大小数据集上的分类精度都好于其他特征组合,相对于传统的词袋模型,词向量特征对分类效果有显著提升。依存关系枚举表示与向量空间表示也对结果准确度影响,一种直观理解是,具有相似的上下文句法关系的标记在语义上更相近,在分类时这种相似性如同词语,能更好地捕捉句子特征。在4种核函数中,RBF核函数在数据量增大的情况分类效果更好,因而在系统测试中,使用基于RBF核函数的SVM作为复述分类器。
5.3 系统测试
该部分测试系统将自然语言转换为SQL语句的效果,实验中本文将数据Geo880CN按照句子长度以及句子数量切分为Geo100CN、Geo250CN、Geo500CN、Geo660CN、Geo880CN五种数据集,句子数量以及句子长度依次递增,其中Geo880CN包含所有的880条问句,餐饮数据Rest250CN直接使用全部250条查询作测试。评价指标选择数据挖掘中常用的F1值:
F1=2*P*RP+R(3)
其中:P为准确度,即测试语句中正确转换为SQL语句的数量占所有测试语句数量的比例;R为召回率,指正确转换为SQL语句的数量与能够正确识别并转换的查询语句数量比值。
由图3可以看出本文提出的复述方法PaNLI与树核函数法,Precise在Geo880CN五种切分数据集上F1值的变化。实验结果表明在美国地里问答数据集上复述方法PaNLI在不同大小的数据集上优于树核函数方法与图匹配方法,当问句数量增加到880时,复述方法F1值为83.4%,与其他系统相比下降更平稳。树核函数由于人工编写语料有限,某些语义差异无法涵盖。基于最大流匹配的Precise系统主要依赖图结构的搜索及字符串表层对应,而使用汉语数据集测试时同一个问题有多种表达方式,难以直接匹配,从而表现较差。PaNLI训练语料来源于网络平台上用户的真实提问,对复述问句捕捉更好,即使用户表达方法不同,很多情况下本文也能筛选出正确的候选结构。
表4为本文所建系统在餐饮问答语料(Rest250CN)上的查询转换结果。相较树核函数,PaNLI在准确度上略低1.7%,原因是Rest250CN包含更多复杂长问句,例如“在柏林市的弗雷德里希大街有哪些餐馆的面条做的比较好吃?”,这些句子在短语结构树上与文献[10]提出的SQLTree相似度较高,更易筛选出正确SQL,但缺点是训练阶段需提供正确、完整的SQLTree。召回率方面复述方法比树核函数高5%,PaNLI更易识别出具有相同含义的形容词、动词,比如复述语料“……好吃吗?”与“……哪个更美味”其中“好吃”与“美味”有较隐晦的相似性,从而帮助系统更多识别出能够转换的查询。综上所述,相比其他NLIDB系统,本文提出的基于复述方法的PaNLI有如下几点优势:1)训练语料来源于网络,语义覆盖面更广,具有领域适应性;2)人工干预部分只需少量筛选复述语料,较编写大量逻辑表达式以及语法规则成本更低;3)本文复述方法更适用于汉语多样化的口语表达,能有效避免语言本身歧义性以及词法分析、句法分析错误导致最后生成SQL错误,语义鸿沟问题更少。
6 结语
本文提出的基于复述NLIDB系统实现方法,避免了对用户语句的直接分析,利用网络问答语料训练得到的复述分类器筛选出语义最相近的自然语言表达。网络问答语料覆盖面广且易于获取,避免费时的人工标注操作。在训练过程中,提出一种结合依存句法分析器的句子级别特征提取方法。实验表明该句子特征表示能有效提高分类准确度,在测试集上均超过现有取得较好效果的系统。在今后的研究中进一步引入机器学习中深度学习方法,提取句子深层次特征,提高分类准确度。
参考文献:
[1]RODOLFO A, JUAN J, MARCO A, et al. Natural language interfaces to databases: an analysis of the state of the art[C]// Recent Advances on Hybrid Intelligent Systems. Berlin: Springer, 2013, 451:463-480.
[2]AHMAD R, KHAN M, ALI R. Efficient transformation of natural language query to SQL for Urdu[C]// Proceedings of the 2nd Conference on Language and Technology. [S.l.]: Society for Natural Language Processing, 2009:53-60.
[3]POPESCU A, ARMANASU A, ETZIONI O, et al. Modern natural language interfaces to databases: composing statistical parsing with semantic tractability[C]// Proceedings of the 20th International Conference on Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2004:141-147.
[4]孟小峰, 王珊. 中文数据库自然语言查询系统NCHIQL设计与实现[J]. 计算机研究与发展, 2001, 38(9):1080-1086. (MENG X F, WANG S. Design and implementation of a Chinese natural language interface to database (NCHIQL) [J]. Computer Research and Development,2001, 38(9): 1080-1086.)
[5]RODOLFO A, JUAN J, MARCO A. Semantic model for improving the performance of natural language interfaces to databases[C]// Proceedings of the 10th Mexican International Conference on Advances in Artificial Intelligence, LNCS 7094. Berlin: SpringerVerlag, 2011: 277-290.
[6]许龙飞, 杨晓昀, 唐世渭. 基于受限汉语的数据库自然语言接口技术研究[J]. 软件学报, 2002, 13(4):537-544.(XU L F, YANG X Y, TANG S W. Study on a database natural language interface technique based on restrictive Chinese[J]. Journal of Software, 2002, 13(4): 537-544.)
[7]MINOCK M, OLOFSSON P, NSLUND A. Towards building robust natural language interfaces to databases[C]// Proceedings of the 13th International Conference on Natural Language and Information Systems: Applications of Natural Language to Information Systems. Berlin: SpringerVerlag, 2008, 5039:187-198.
[8]WARREN D, PEREIRA F. An efficient easily adaptable system for interpreting natural language queries[J]. Computational Linguistics, 1982,8(3/4):110-122.
[9]WEISCHEDEL R. A hybrid approach to representation in the Janus natural language processor[C]// Proceedings of the 27th Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 1989:193-202.
[10]GIORDANI A, MOSCHITTI A. Automatic generation and reranking of SQLderived answers to NL questions[C]// Proceedings of the 2nd International Workshop on Trustworthy Eternal Systems via Evolving Software, Data and Knowledge, Volume 379 of the series Communications in Computer and Information Science. Berlin: SpringerVerlag, 2013: 59-76.
[11]LI F, JAGADISH H. Constructing an interactive natural language interface for relational databases[J]. Proceedings of the VLDB Endowment,2014,8(1):73-84
[12]POON H. Grounded unsupervised semantic parsing[C]// Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2013:1-10.
[13]GIORDANI A, MOSCHITTI A. Generating SQL queries using natural language syntactic dependencies and metadata[C]// Proceedings of the 17th International Conference on Applications of Natural Language to Information Systems, LNCS 7337. Berlin: Springer, 2012:164-170.
[14]BERANT J, CHOU A, FROSTIG R, et al. Semantic parsing on freebase from questionanswer pairs[C]// Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2013:1533-1544.
[15]CAI Q, YATES A. Largescale semantic parsing via schema matching and lexicon extension[C]// Proceedings of the Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2013:423-433.
[16]MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[C]// Proceedings of the Advances in Neural Information Processing Systems. Nevada: NIPS, 2013: 3111-3119.
[17]曹勇刚, 曹羽中, 金茂忠,等. 面向信息检索的自适应中文分词系统[J]. 软件学报, 2006, 17(3):356-363. (CAO Y G, CAO Y Z, JIN M Z, et al. Information retrieval oriented adaptive Chinese word segmentation system[J]. Journal of Software,2006, 17(3):356-363.)
[18]ESPAABOQUERA S, CASTROBLEDA M, ZAMORAMARTNEZ F, et al. Efficient viterbi algorithms for lexical tree based models[C]// Proceedings of the 2007 International Conference on Advances in Nonlinear Speech Processing. Berlin: SpringerVerlag, 2007, 4885:179-187.
[19]SIMITSIS A, IOANNIDIS Y. DBMSs should talk back too[C]// Proceedings of the 4th Biennal Conference on Innovative Data Systems Research. [S.l.]: arXiv, 2009:62-70.
[20]KOUTRIKA G, SIMITSIS A, IOANNIDIS Y E. Explaining structured queries in natural language[C]// Proceedings of the 2010 IEEE 26th International Conference on Data Engineering. Piscataway, NJ: IEEE, 2010:333-344.
[21]BARZILAY R, MCKEOWN K. Extracting paraphrases from a parallel corpus[C]// Proceedings of the 39th Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2002:50-57.
[22]赵世奇, 刘挺, 李生. 复述技术研究[J]. 软件学报, 2009, 20(8):2124-2137.(ZHAO S Q, LIU T, LI S. Research on paraphrasing technology[J]. Journal of Software, 2009, 20(8):2124-2137.)
[23]ZHANG D. Question classification using support vector machines[C]// Proceedings of the 26th Annual International ACM SIGIR Conference on Research & Development in Information Retrieval. New York: ACM, 2003:26-32.
[24]CHANG P, TSENG H, JURAFSKY D, et al. Discriminative reordering with Chinese grammatical relations features[C]// Proceedings of the 3rd Workshop on Syntax and Structure in Statistical Translation. Stroudsburg, PA: Association for Computational Linguistics, 2009: 51-59.
[25]ZHANG Y, NIVRE J. Transitionbased dependency parsing with rich nonlocal features[C]// Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2011:188-193.
[26]SHEN L, JOSHI A K. An SVM based voting algorithm with application to parse reranking[C]// Proceedings of the 7th Conference on Natural Language Learning at HLTNAACL. Stroudsburg, PA: Association for Computational Linguistics, 2003:9-16.
[27]POPESCU A M, ETZIONI O, KAUTZ H. Towards a theory of natural language interfaces to databases[C]// Proceedings of the 8th International Conference on Intelligent User Interfaces. New York: ACM, 2003: 149-157.
