基于Rent规则的片上网络局部化特性流量生成算法
2016-05-14周玉瀚韩国栋沈剑良姜奎
周玉瀚 韩国栋 沈剑良 姜奎


摘要:针对传统片上网络(NoC)流量模型的空间分布不符合实际应用中通信局部化特性、网络带宽开销大的问题,提出一种基于Rent规则的NoC局部化特性流量生成算法。该算法通过建立有限Mesh结构的通信概率分布模型,并利用通信概率矩阵对各节点匀速发包获得合成流量,实现通信局部化。实验模拟了不同局部化程度、不同网络尺寸的合成流量;仿真结果表明,与Random Uniform、Bit Complement、Reversal、Transpose、Butterfly等5种传统合成流量相比,该算法合成流量的局部化程特性更好、网络带宽开销更低,接近实际通信流量。
关键词:片上网络;Rent规则;流量生成算法;流量模型;通信局部化
中图分类号:TP301.6 文献标志码:A
Abstract:In view of the problems that the spatial distribution of traffic model in traditional Network on Chip (NoC) was not consistent with the communication locality in practical applications and the overhead of network bandwidth is large, a novel algorithm for flow generation with NoC localized characteristic based on Rent rule was proposed. By establishing the communication probability distribution model with finite Mesh structure, the communication probability matrix was used to send packets to each node uniformly and obtain synthesis flows, and the locality was realized. The experiment simulated on flow with different locality degree and different network size. The results show that the proposed algorithm has better performance in flow locality, which is more close to the actual flows compared with five algorithms including Random Uniform, Bit Complement, Reversal, Transpose and Butterfly. In addition, the overhead of network bandwidth is lower.
Key words:Network on Chip (NoC); Rent rule; traffic generation algorithm; flow model; communication locality
0 引言
片上系统(System on Chip,SoC)往往集成几十个甚至上百个核心互相通信,需要扩展性很强的通信架构。片上网络(Network on Chip,NoC)结构是一种可行的解决方式,其思想源自计算机网络,如数据包通信和分布式系统。与SoC相比,NoC主要的优势是通信的并发性、可扩展性和可重用性。
NoC设计的主要步骤包括系统架构设计、流量建模、性能评估。其中,流量建模作为一个重要方面,规定了通信节点间的传输特征、网络中每个通信事件,为设计人员提供定量、定性的分析。流量模型包括数据包空间分布、数据包注入率和包长度[1-2]三方面,而空间分布是分析网络流量状况的核心,常用于分析、设计网络结构和路由算法、测试NoC网络结构性能。
然而,现有流量模型并不能模拟实际NoC应用流量的非均匀和局部化特性,也不易随系统尺寸调整空间分布,网络带宽开销大。常见描述网络流量空间分布的模型多采用随机化的均匀分布模型,如Uniform Random和Nearest Neighbor模型,后者虽然有固定比例的流量流向半径为r的邻近节点,但其余空间节点为Uniform Random流量;Bit Reversal、 Butterfly、Transpose等数字排序模型则指定源、目的节点对通信。而实际应用中的流量行为,如:快速傅里叶变换(Fast Fourier Transform, FFT)、 Barnes、 Cholesky、 Radix等,空间分布非均匀且具有很强的流量局部化特性,邻节点通信比远端通信更为频繁[3],因此,研究模拟局部化特性的流量最贴近实际应用,在结构设计和任务映射阶段,提高局部化通信可大大降低通信复杂度[4],是解决片上通信问题的重点研究方向。
2007年以来陆续有研究学者将超大规模集成电路(Very Large Scale Integration,VLSI)领域的Rent规则引入NoC的描述通信局部化, Greenfield等将该规则应用于网络带宽,提出了网络带宽版本的Rent规则,指出集成电路中一个模块内的IP数量与该模块所需的外界通信带宽呈指数关系。Heirman等[3]通过实验发现流行的多核处理器(Chip Multicore Processor, CMP)标准应用的流量模式服从Rent规则,但没有人采用Rent规则设计流量生成方法,并作为NoC应用流量的一般模拟方法。
本文通过Rent规则对NoC流量局部化特性建模,提出了有限Mesh结构中的局部化特性流量生成算法。该算法通过建立Rent通信概率矩阵(Communication Probability Matrix, CPM),并由NoC各节点二分法依CPM概率选择目的节点发包, 可生成不同局部化率、不同尺寸网络的流量,测试NoC拓扑研究拓扑结构的灵活性和扩展性;同时,合成流量的平均带宽占用率低,可作为NoC任务映射的设计标准。
式(2)为网络中模块间的通信局部化模型,然而其前提假设是模块位于无限VLSI网格中,不能直接用于实际Mesh流量生成。本文研究对象是尺寸有限的2D mesh结构,首先基于式(2)给出有限Mesh结构中任意两节点的Rent通信概率分布模型(Communication Probability Distribution, CPD)。
1.2 有限Mesh结构Rent通信概率分布模型
片上网络仿真中,通信概率分布CPD(i, j)(m,n)指源节点S(i, j)与目的节点D(m,n)通信的概率。尺寸有限的2D Mesh结构中CPD的变化是有限的,将式(2)在有限跳步空间内进行截断。不同节点(x,y)的最远传输距离DMAX与节点间的位置相关,由几何分析,定理1指出了Mesh结构中最大可能跳步距离,定理2指出了最多可达的节点数量,2D Mesh中跳步示意如图1所示。
式(4)、(5)即为有限Mesh网络中Rent通信概率分布模型,由直接推导自Rent定义的式(2)截断并归一化而来。可验证网络流量对于一个簇(GK2)是遵循Rent规则的,例外为:当G=K2时,所有的通信均发生在簇的内部,外部带宽B=0。
2 基于通信概率矩阵的流量生成算法
系统中的通信可以视为一张图G=G(P(i, j),Ω(C)),每个节点是图的顶点(i, j)Ω(C),节点对间的通信概率P(i, j)是边的权值。对于Mesh同构NoC结构,网络通信图可通过CPM描述;各节点按CPM指定概率生成目的地址并匀速发包,即得所需的网络流量。本算法的CPM是开放的,可通过替换CPD模型生成相应流量,本文仅考虑Rent规则流量。
Mesh NoC流量生成主要包含CPM计算和Mesh NoC流量生成两部分,下面分别详细介绍,流量生成流程如图2所示。
最后,在NoC仿真平台中,各节点以1 packet/cycle速率发送数据包至目的节点,形成网络流量。通过全网络的流量统计,可分析生成流量的跳步距离、数据包数量等信息。
3 实验验证与分析
3.1 实验环境与方法
流量生成实验环境包含两部分,CPM生成程序(由C++代码编程实现)和Mesh NoC系统(由HNOCS仿真平台搭建)。HNOCS是NoC仿真器由C++语言描述,可单独配置链路带宽、单向链路的虚通道数量,支持任意拓扑结构,在flit和数据包的层面提供一系列丰富的仿真统计参数。系统环境为:Ubuntu10.04(安装有gccversion 4.1.2)。
此外,本文在HNOCS中搭建了流量CPM读取和流量生成模块。HNOCS平台的仿真参数设置为:K×K BaseMesh结构,基于信用的流量反压流控机制,数据包大小为8 flit,每个IP核产生1000~30000个数据包,每种配置场景下仿真运行100μs,预热稳定运行时间为50μs。
为了对比分析,采用了5种传统合成流量模式:Random Uniform、Bit Complement、Reversal、Transpose、Butterfly,以及由文献[12]提供的8种实际应用流量:S(32288)编/解码、H264720p/1080p编解码、Robot、Fpp、FFT(1024)、Sparse(分别包含4×4、8×8、16×16尺寸Mesh NoC各节点的实际通信数据)。
实验方法为:首先,由CPM生成程序得到多种尺寸、Rent系数的CPM数据;其次,由HNOCS仿真平台中Mesh网络中各个节点读取CPM数据,计算目的地址并按均匀速率发包;最后,通过统计各节点的发包跳步距离、数量,分析生成流量特性。
3.2 合成流量局部化特性验证与分析
本算法通过调整Rent系数,可生成不同局部化程度、不同网络尺寸的流量。本文将Rent合成流量与传统合成流量(Uniform、 Transpose等)8种实际流量进行局部化特性的对比分析。
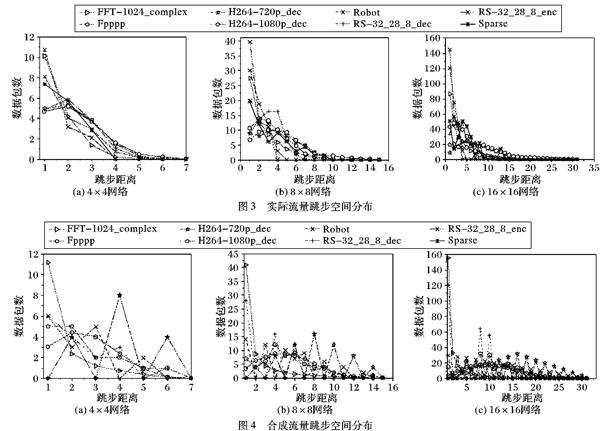
首先生成Rent(0.7)的流量(文献[9]指出实际应用估计Rent系数为0.7),对比了三种网络尺寸下,实际流量、合成流量跳步空间分布,如图3、4所示。
从图3、4可以看到不同尺寸下各跳步距离数据包数量的统计,验证了Rent合成流量的局部化特性:短距离的数据包占多数,远距离的数据包占少数。在不同尺寸下传统合成流量的局部化特性较弱,而Rent流量均具有良好的局部化特性。对比实际应用的流量空间跳步,传统合成流量中远距离跳步的数据包较多,如Complement方法,与实际流量差距大,且网络尺寸越大差距越明显(由于Complement定义中选取的测试点为离散情况,故奇数跳步点没有収包)。Rent流量的局部化特性更接近实际流量。
为了更好地分析流量的局部化特性,本文将网络中的数据包按跳步距离分类。定义传输距离为1跳的包为邻节点包(Neighbor),传输距离介于1和2+K/8之间的是局部包(Local)(K是Mesh的网络尺寸),传输距离大于2+K/8的是全局包(Global)。在较大规模的16×16、32×32、64×64三种尺寸Mesh网络中,9种Rent系数(0.1~0.9)下合成流量的局部化特性分析如图5所示。
由图5可见,随着Rent系数增大,局部包比例仅小幅增加,而全局包比例快速上升、邻节点包比例迅速下降,表明局部化程度在下降。随着网络尺寸增大,局部包的比例上升,全局包比例下降,表明局部化程度在提高。这与带宽版本Rent规则对Rent系数的含义[7]吻合。
将合成流量数据包按跳步距离分类,对比分析如图6所示。可以看到Rent(0.7)流量中邻节点和局部数据包占多数,全局数据包比例下降。其余合成流量局部化特性较弱,且网络尺寸越大全局数据包比例越大。如Complement模型的局部化特性较差,没有邻节点间的数据包,在1024节点规模时全局数据包比例超过了80%。
流量的局部化分析表明,局部化特性越弱,全局数据包比例越大,且随网络尺寸增大而增加。全局包是引起网路延迟的主要因素,NoC设计需处理好全局数据包才适应大规模的片上网络通信。本文算法可作为模拟实际流量局部化特性的一种简单方法,同时生成的Rent流量也可作为任务映射的优化目标,减少全局包所带来的影响。
3.3 合成流量网络带宽开销分析
由表1数据,可以看出Rent合成流量更接近实际应用平均路由带宽的均值。在Rent系数为0.7时最吻合(在4×4尺寸下,误差仅为3.2%),Rent系数越大合成流量带宽开销越小,反之则带宽开销越大,这与文献[9]中Rent系数分析结论一致。而Uniform与实际应用误差最高达到218%,其余合成流量误差也都较大,且误差随网络尺寸增加而增大。
通过图7可以发现更大尺寸网络中,Rent流量的带宽需求曲线仍然接近实际流量曲线,不同Rent系数带来一定波动,但范围不大(在节点数量达到4096时平均路由带宽开销不超过5.023packet/cycle)。而Uniform、Transpose等流量的带宽需求与实际差距较大,平均路由带宽的需求在以指数形式增长:节点数量每增加4倍,路由带宽需求增加1倍。这将导致路由间的连线数量需要指数增长,这样的增长是不可接受的。
对于VLSI设计,随机摆放器件也会导致连线和金属层需求的指数增长;但实际设计中,局部化通信强的器件会被邻近放置,从而减少连线,提高频率和性能。在NoC设计中对应VLSI器件放置的工作是任务映射。Hu等[13]对一个较小的5×5阵列,采用通信感知的任务映射方式,相比随机映射降低NoC功耗60%。对于较小尺寸的网络,随机流量带来的影响可以接受,但当设计几百到上千个模型的片上系统时,随机带来以指数增长的非局部化通信流量将不可接受。
综上,Rent合成流量具有较低的网络带宽开销,带宽开销与节点数量关系与实际流量吻合;本文算法可以模拟实际流量负载的网络带宽开销特性,与传统的合成流量模式相比更加实际;可辅助设计高效的应用和更好的任务映射技术。
3.4 NoC拓扑性能测试评估
合成流量可作为测试基准,测试不同拓扑结构通信性能。针对256节点的较大规模系统,对比了Mesh、CMesh和CHMesh三种拓扑结构的性能,其中CMesh与CHMesh均为分簇互连的层次化Mesh结构:底层仍然为2D Mesh结构,可应用本算法生成负载流量。平均延迟和吞吐对比分别如图8、9所示。
从图8、9中可看出,Rent流量下三种拓扑的平均延迟和吞吐性能均较传统合成流量更优。Rent流量下饱和拐点更低,饱和后的延迟也远小于后两种流量。此外,可以看出CMesh与CHMesh较Mesh拓扑的延迟性能好,CHMesh的吞吐性能最高。这是因为层次化的Mesh互连结构连通性更高,且CHMesh底层节点分簇的结构可提高局部化通信性能,获得了低延迟和高吞吐。
因此,本文算法生成的Rent流量可从通信局部化特性、带宽需求方面详细评估NoC拓扑,而不需要求助于具体应用驱动的负载。
4 结语
本文采用Rent规则建立了有限Mesh结构中NoC流量通信概率分布模型,提出了具有局部化特性NoC合成流量生成算法。算法首先计算通信概率矩阵,再由NoC各节点生成网络流量,通过调整Rent系数灵活改变流量的空间局部化程度。生成的Rent合成流量局部化特性较传统合成流量强,平均路由带宽需求较低,且与实际流量更加吻合。
本文算法可作为模拟实际流量负载的空间分布、带宽开销特性的一种简单方法,评估NoC设计;同时可被用于辅助设计高能效的应用和更好的任务映射技术,从而降低网络带宽开销,提高系统性能。但该方法对时间方面如突发业务和时变Rent系数的负载没有考虑,增加以上两方面内容是未来的工作方向。
参考文献:
[1]TEDESCO L, MELLO A, GARIBOTTI D, et al. Traffic generation and performance evaluation for meshbased NoCs[C]// Proceedings of the 18th Symposium on Integrated Circuits and Systems Design. Piscataway, NJ: IEEE, 2005: 184-189.
[2]DUATO J, YALAMANCHILI S, NI L. Interconnection Networks[M]. San Francisco, CA: Morgan Kaufmann, 2003: 569-592.
[3]HEIRMAN W, DAMBRE J, STROOBANDT D, et al. Rents rule and parallel programs: characterizing network traffic behavior[C]// Proceedings of the 2008 International Workshop on System Level Interconnect Prediction. New York: ACM, 2008: 87-94.
[4]QIAN Z, BOGDAN P, TSUI C Y, et al. Performance evaluation of multicore systems: from traffic analysis to latency predictions (embedded tutorial)[C]// Proceedings of the 2013 IEEE/ACM International Conference on ComputerAided Design. Piscataway, NJ: IEEE, 2013: 82-84.
[5]RENT T M. Rents rule: a family memoir[J]. IEEE SolidState Circuits Magazine, 2009, 2(1): 14-20.
[6]DONATH W E. Wire length distribution for placements of computer logic[J]. IBM Journal of Research and Development, 1981, 25(2/3): 152-155.
[7]GREENFIELD D, BANERJEE A, LEE J G. Implications of Rents rule for NoC design and its faulttolerance[C]// Proceedings of the 1st International Symposium on NetworksonChip. Washington, DC: IEEE Computer Society, 2007: 283-294.
[8]BEZERRA G B P, FORREST S, FORREST M, et al. Modeling NoC traffic locality and energy consumption with Rents communication probability distribution[C]// Proceedings of the 12th ACM/IEEE International Workshop on System Level Interconnect Prediction. New York: ACM, 2010: 3-8.
[9]HEIRMAN W, DAMBRE J, STROOBANDT D, et al. Rents rule and parallel programs: characterizing network traffic behavior[C]// Proceedings of the 2008 International Workshop on System Level Interconnect Prediction. New York: ACM, 2008: 87-94.
[10]CHRISTIE P, STROOBANDT D. The interpretation and application of Rents rule[J]. IEEE Transactions on Very Large Scale Integration Systems, 2000, 8(6): 639-648.
[11]DAVIS J A, DE V K, MEINDL J D. A stochastic wirelength distribution for GigaScale Integration (GSI), Part I: derivation and validation[J]. IEEE Transactions on Electron Devices,1998, 45(3):580-589.
[12]LIU W C, XU J, WU X W, et al. A NoC traffic suite based on real applications[C]// Proceedings of the 2011 IEEE Computer Society Annual Symposium on VLSI. Washington, DC: IEEE Computer Society, 2011: 66-71.
[13]HU J C, MARCULESCU R. Energyaware mapping for tilebased NoC architectures under performance constraints[C]// Proceedings of the 2003 Asia and South Pacific Design Automation Conference. New York: ACM,2003: 233-239.
