海量数据实时处理算法设计与分析
2016-05-14李敏
李敏
【摘要】本论文针对海量数据的处理分析设计了相应的算法,主要是通过预处理、分布缓存和复用中间结果三种方法对MapReduce算法进行优化处理。本文的实验部分会对房价方面的数据用hash算法进行分析和处理。通过实验得出结论,该算法可以处理海量数据。
【关键词】海量数据 MapReduce算法 hash
一、背景以及现状
随着互联网的发展,在许多科学领域,信息数量呈指数型增长。截止到2011年全球信息总量为1.8ZB[1]。海量数据的时代已经来临,然而面对海量数据该如何存储,如何有效的处理,及时有效的处理了这些数据对于各行各业乃至整个社会的发展有着重要的意义。过去的几年里单机的性能得到发展,硬件也得到发展。但在理论上这些硬件技术的发展是有限的。现今的多核技术就是并行技术发展的一个实例[2]。
二、MapReduce的技术特征
1)横向扩展与纵向扩展。对于MapReduce集群的构建采用低廉且容易扩展的低端商用服务器,考虑到大量数据存储的需要,基于低端服务器的集群远比基于高端服务器的集群优越,所以基于低端服务器实现都会使用MapReduce并行计算集群。
2)失效与常态。相对低端的服务器适用于MapReduce集群,无论哪个节点失效,其他的节点要无缝接管着失效节点的计算任务;当该节点恢复以后将不需要人工配置而是能自动无缝加入集群。
3)处理向数据迁移。MapReduce采取数据与代码互定位的技术时,计算节点首先计算其本地存储的数据并对其负责使数据发挥本地化的特点。
三、对MapReduce改进
(一)预处理算法
大量事实证明,在数据挖掘中整个工作量的60%到80%都是数据预处理[3]。通过数据预处理工作可以使残缺的数据变得完整,能达到数据类型相同化、数据格式的一致化、数据存储集中化和数据信息精练化[4]。采用Hash算法,间接取余法。公式:f(x):= x mod maxM ; maxM一般是不太接近 2^t 的一个质数。得余数x,根据x对源数据进行预处理分配,采用Hash取模进行等价映射。
(二)分布缓存
对由N台缓存服务器组成的集群缓存把集群依次编号为0 - (N-1)。
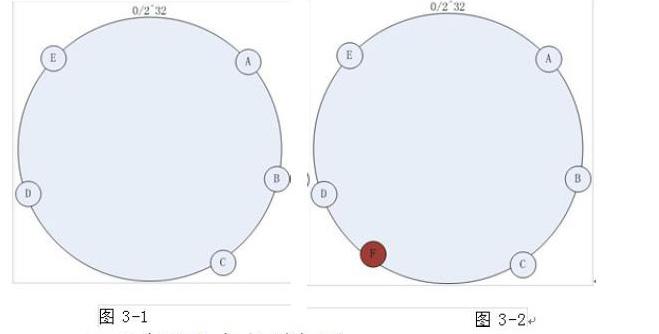
1)hash机器节点。首先求出机器节点处的hash值,然后把它分布到0~2^32的一个圆环上(顺时针分布)。如图3-1,集群中有ABCDE五台机器,通过hash算法把它们分布到如图3-1所示的环上。
2)访问方式。写入缓存的请求,Key值为K计算器hash值为hash(K),Hash(K)对应着图3-1环中的某一个点。若该点没有对应映射到具体的某个机器节点上,就进行顺时针查找直到找到确定的目标节点,也就是首次有映射机器的节点。Hash(K)的值介于A~B之间时,那么它命中的机器节点应当就是图3-1中的B节点。
3)增加节点的处理。如图3-1中如果在原有集群的基础上想再增加一台机器F,过程如下,首先要计算机器节点的Hash值,找到环中的一个节点,把机器映射上,如图3-2所示。在增加机器节点F以后访问策略不发生改变,按2)中的方式继续访问,那么此时仍然是不可避免的是缓存不命中的情况,hash(K)在增加节点之前不能命中的数据是落在C~F之间的数据。hash它使用了虚拟节点的思想,在圆上分配了100~200个点为其中的每一个物理节点,这样就能较好的抑制了分布的不均匀的情况,还能最大限度减小当服务器增减时缓存的重新分布。
{三}复用中间结果
在对海量数据进行了预处理和分布式缓存之后,采用简单随机取样[5]的方法对缓存好的数据进行随机取样具体实现该方法。
四、实验
本论文的实验可以对是某地区房价数据进行处理,简要的过程如下:
第一数据预处理阶段,首先让每一组数据分别自动编号,然后采用取余的方法。第二根据分组情况,分别把各组数据放置到不同的服务器上。第三采用简单随机取样的方法对缓存好的数据进行随机取样,选择出最适合的房产。
五、结束语
本文在算法方面也还有一些不足之处,有待深入的分析。目前海量数据的处理还有很多值得深入研究和挖掘的地方,还将会是热门的话题以及更多专家学者热衷研究的方向。
【参考文献】
[1] John Gantz, David Reinsel .The 2011 Digital Universe study: Extracting Value from Chaos [J]. International Data Corporation (IDC), 2011
[2]陈康,郑纬民.云计算:系统实例与研究现状[J].软件学报,2009,20(5) :1337 -1348.
[3]D. Romano, Data Mining Leading Edge: Insurance&Banking, InProceedings of Knowledge Discovery and Data Mining, Unicorn, BrunelUniversity, 1997.
[4]刘军强,高建民,李言等.基于逆向工程的点云数据预处理技术研究.现代制造工程.2005.7: 73-75.
[5]Jiawei Han, Micheline Kambe;著,范明,孟小峰,数据挖掘概念与技术机械工业出版社,2001.
