自动混音技术探索(下)
2016-05-14江博文
江博文
在上一期的《自动混音技术探索(上)》一文中我们探讨了使用自动混音技术的必要性,并详细分析了“自动混音技术分类”中的其中一种——“Gating”算法。
本期我们继续讨论“自动混音技术分类”中的另一种——“Gainsharing”算法,以及“自动混音器的选择与设计注意事项” 和“自动混音技术的应用和发展展望”。
自动混音技术分类
Gating
(详细内容见《InfoAV China》6月刊,或关注“依马狮视听传媒”微信公众号查找对应内容)
Gainsharing
前文所说Gating+Noma的自动混音技术是一种正向思维的解决办法,归结起来三步走:1.话筒什么情况下开和关;2.话筒如何开和关;3.话筒开了如何平衡增益。而Gainsharing的技术则是一种逆向思维的解决办法。
Gainsharing其实本质上是一套算法,可以简单的用下面这句话来描述,“每一路输入进行一定量的衰减,衰减量等于该路电平与所有通路电平总和之差,以dB加减。”这一套简单有效的算法由美国音频技术大拿于上世纪70年代提出,并在1976年取得专利。在专利保护的20年内只有几家授权厂商在生产基于Gainsharing的自动混音器。直到专利保护期过后才在市场上逐渐出现相关的自动混音器,Gainsharing的技术也由此广为人知。专利这把双刃剑,此处就不多谈了。我们来看看具体的实现方法。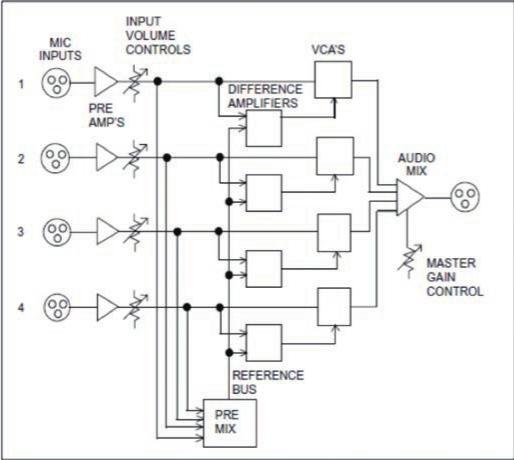
通过上图我们可以知道,通过预先混合得到总电平,然后在通过一个比较器得出每一路电平与总电平的差值,最后调整相应通道的VCA来实现增益的共享。具体公式如下:
Ln=Ln-[Sum(Ln )-Ln ]
Ln:通道衰减前的电平即原电平
Ln:通道衰减后的实际电平
Sum(Ln ):每个通道(衰减前)的总和电平
所有加减基于dB
可能从上面的公式来看还较难理解Gainsharing。换一种较为容易理解:当所有话筒都没有人说话时,此时所有话筒拾取的都是几乎等量的环境噪音,则每个话筒都分得几乎相同的增益;当其中一个话筒说话时,此时该话筒将得到几乎100%的增益,而其他未说话的话筒分享剩下的增益;当有2个话筒说话时,电平越大的得到的增益越多,电平越小的得到的增益越少,另一种情况就是假设两者的电平一致,则两者均分几乎100%的增益,其他情况以此类推。从中我们可以看出Gainsharing永远不会有多余的增益溢出,而是不断在分配可用增益的过程。所以从理论上可以看出,Gainsharing自动混音可以很好地辨别出相干与非相干信号,对余量的需求将会比Gating的小。那带给音频工程师的益处就是减少一定的调试工作。
Gainsharing自动混音技术面临一个问题是当话筒数量多的时候,没有说话的话筒总和电平将足够大,这样有可能导致实际需要扩声的话筒被减去过多的增益。所以对于一般的增益共享自动混音器建议通道数少于16只。当然也有厂商意识到了这些问题会提供相关的参数设置给工程师配置,主要通过更改分配比例来实现。
自动混音器的选择与设计注意事项
通过上面的介绍我们了解两种自动混音器的基本原理及各自的技术特点。那在实际的项目中我们该如何选择自动混音器?这里给出的建议是:
首先尽可能测试即将使用的自动混音器或技术是否能完成我们的工作,如Gating是否吃字,Gainsharing是否有更多话筒处理的能力等等。
根据自身技术能力选择。如Gating涉及门限,门限里面包含如何设置,启动时间,释放时间等等诸多的参数设置,则对此时需要充分了解每个设置的具体作用,那对技术人员的要求相对较高;而Gainsharing是一套自成体系的算法,几乎没有需要你自己设置的参数,相对来说对自动混音内的技术本身了解的要求则大大降低。
现场系统余量的许可。当现场余量足够时则建议使用Gating自动混音技术;当现场余量不足时则可使用Gainsharing确保任何时候的系统安全。
积极参加各厂家的相关的培训,充分了解各参数对应到的相关技术及解决的问题。
在自动混音器系统内实际要注意的除了对自动混音技术的了解以外,同时需要确保系统在正确的增益结构链路下。由于自动混音技术是根据实时电平大小来决定话筒开关或增益量的,所以如果增益结构不对很可能导致最终得到理想结果。
自动混音技术的应用和发展展望
自动混音的应用在诞生之初是为了解决演播厅等的多话筒管理问题,由于AV工程商的介入才发展到会议室内使用。从而构建一个自由无拘束的会议环境,并且大大减少会议的管理工作。但是由于中国技术的引进以及早期的自动混音器工作效果并不够好,所以几乎在广播市场很少使用,很少有人知道会议室需要用自动混音器。但随着越来越多国外高端厂商性能及效果良好的自动混音器引进,现在越来越多的会议室正在使用自动混音器或带自动混音的DSP处理器。
实际我对自动混音技术的理解是:多话筒的自动化或智能化管理。所以任何需要用到多话筒的场合都可以使用自动混音技术。这里举两个例子供大家参考:
近几年很流行的大型多人社交语言类节目,现场几十只话筒的管理问题让调音师绞尽脑汁。所以这种场合就需要使用自动混音技术来减少调音师的负担。如上图的爱情学院最终就选择了基于DSP的自动混音技术结合相关DSP内置功能很好地解决了节目话筒管理的问题。
多功能剧场剧院也是需要自动混音技术的场合。这种类型的剧场剧院主要为开会服务,一年演出机会实际很少。然而现在的项目一般会按照标准剧院的模式去设计。往往造成开会时管理复杂,或总是需要专人管理。实际我们可以将此类场所看做一个大型的会议室。那会议室我们现在往往会使用DSP和DSP内部的自动混音来完成话筒管理,多功能的礼堂剧院同样可以采用这样的模式,通过合理的系统搭建实现无人值守的会议。
其他更多的应用这里不做一一列举,记住自动混音帮助我们管理话筒,在任何的多话筒项目中你都可以考虑。
目前自动混音技术基本都市融合到各家的DSP内作为一个功能,所以在谈发展时我们应当站在DSP的角度去考虑技术的发展。所以以下几点是我认为可能的方向:
1.基于语音识别的自动混音技术。就目前所能见到的自动混音技术都是纯粹基于电平来进行管理的,这样或多或少会出现误判。而当有语音识别的自动混音技术出现时,则可以很精准地启动和关闭话筒。当然我这里说的语音识别并不是大家所熟悉的Siri或科大讯飞这些,这一类是非实时的处理且允许较长的响应时间,而在DSP内所谈的语音识别技术是在毫秒级的快速判断,且准确度必须很高,否则带来的就是糟糕的会议体验。目前已有顶尖的DSP厂商能实现这种类型的语音识别,未来可期。
2.加入会议管理的自动混音技术。目前而言自动混音技术主要场合是自由发言会议的场合。根据国内的实际情况,对会议管理要求更多的功能,则此时能通过开放式DSP内部编程来实现部分如优先等功能,但更为复杂的实现仍需要借助第三方。所以加入会议管理的自动混音也可能是一个课题。
总结
正如自动混音技术是为广播事业而诞生最终被AV集成商青睐,当技术发展到足够成熟能够很好地完成它本应解决的问题,技术的应用则又会有新的发展。我们通过很好地理解技术的本源来更好地理解我们的产品以及为客户提供更优质的沟通环境。
参考文献
Dan Dugan (October 1989). "Application of Automatic Mixing Techniques to Audio Consoles
Tom Stuckman and Steve Marks “AUTOMATIC MIXERS”
Biamp Technical Newsletter”Automixer”
Wikipedia “Automixer”
