《现6》《牛8》多义词义项数目异同研究
2016-05-13李仕春史梁樱
李仕春,史梁樱
(1.西南大学 文学院,重庆400715;2.广西大学 文学院,广西 南宁530004)
《现6》《牛8》多义词义项数目异同研究
李仕春1,史梁樱2
(1.西南大学 文学院,重庆400715;2.广西大学 文学院,广西 南宁530004)
摘要:《现6》、《牛8》多义词义项数目的差别,反映了以《现汉》为代表的汉语类中型语文性词典在常用词义项方面的编纂水准落后于以《牛8》为代表的同类别英语类词典,主要表现在《现6》的编纂者忽略了用语料库技术丰富并补充现代汉语常用词义项分布情况的研究。运用语料库技术的方法,研究现代汉语中常用词的义项分布情况,是一项刻不容缓的任务。
关键词:《现6》;《牛8》;多义词
一、引言
李仕春指出《现代汉语词典》(本文简称《现汉》)、《现代汉语学习词典》、《现代汉语规范词典》等汉语类词典和《牛津高阶英语词典》(本文简称《牛津》)、《牛津简明英语词典》、《韦氏高阶英语词典》、《郎文高阶英语词典》等英语类词典都是中型语文性词典,并统计出:以《牛津》为代表的英语类词典100核心词的平均义项比以《现汉》为代表的汉语类词典要多出5-7个义项,据此认为:长期以来中国词典的编纂者乃至研究现代汉语词汇的学者忽视了现代汉语100核心词义项分布的研究[1]。
本文用穷尽性的方法统计了《现6》、《牛8》*之所以选取这两部词典,是因为《现代汉语词典》(第6版)(本文简称《现6》)是汉语词典中最有代表性的中型语文性词典,《牛津高阶英语词典》(第8版)(本文简称《牛8》)是英语词典中最有代表性的中型语文性词典,并且两部词典的编纂体例相差较小。中多义词义项数目,发现两部词典中多义词义项数目差别很大,这种差别不但印证了上文观点,而且说明中国学者忽略了用语料库技术丰富并补充现代汉语更多常用词义项分布情况的研究。
二、《现6》《牛8》多义词义项数目对比与分析
据苏新春(2002)统计,《现汉》(第3版)有12501个多义词[2]。我们统计《现6》共有13849个多义词,排除199个表示“姓”的义项后,《现6》共有13650个多义词(《现6》中一些词含有两个义项,一个是该词的本义另一个表示“姓”,这两个义项之间没有引申关系,我们在统计的时候不把这样的词看作多义词,如:“鲍:名。①软体动物,贝壳椭圆形,生活在海中。贝壳可入药,称石决明。②(Bào)姓。”“鲍”的义项①和②之间没有引申关系,我们把它看作单义词)。两者的统计说明《现汉》多义词义项数目基本稳定。
国内少有人运用穷尽性统计的方法统计英语类词典中多义词义项数目,我们统计出《牛8》共有10027个多义词。《现6》和《牛8》多义词义项数目具体分布如下表:
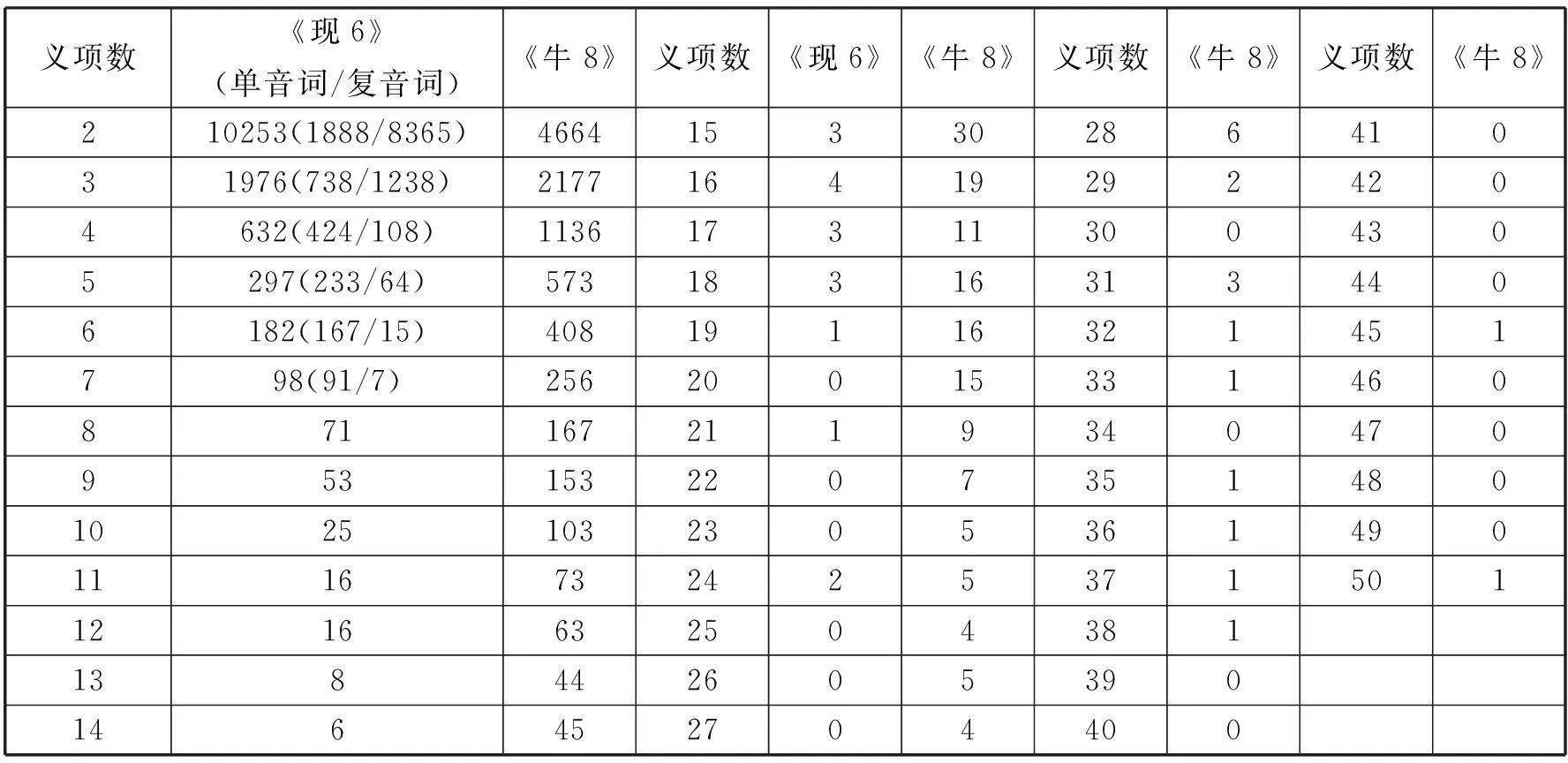
《现6》《牛8》多义词义项数目对比表*表中《现6》的多义词区分为单音多义词(简称单音词)和复音多义词(简称复音词),其中复音多义词义项数目最多有7个,单音多义词义项数目最多有24个,是“点”和“打”。《牛8》中多义词义项数目最多的词是“run”,有50个。
上表显示,《现6》、《牛8》中多义词义项数目具体差别如下:
(一)2个义项的多义词:《现6》有10253个,占《现6》多义词总数的74.08%,其中单音词1888个,复音词8365个;《牛8》有4664个,占《牛8》多义词总数的46.51%。
(二)3个义项的多义词:《现6》有1976个,占多义词总数的14.48%,其中单音词738条,复音词1238条;《牛8》有2177个,占多义词总数的21.71%。
(三)4个义项的多义词:《现6》有632个,占多义词总数的4.63%,其中单音词424条,复音词108条;《牛8》有1136个,占多义词总数的11.33%。
(四)5个义项的多义词:《现6》有297个,占多义词总数的2.18%,其中单音词233条,复音词64条;《牛8》有573个,占多义词总数的5.71%。
(五)6个义项的多义词:《现6》有182个,占多义词总数的1.33%,其中单音词167条,复音词15条;《牛8》有573个,占多义词总数的4.07%。
(六)7个义项的多义词:《现6》有98个,占多义词总数的0.72%,其中单音词91条,复音词7条;《牛8》有256个,占多义词总数的2.55%。
(七)8个及8个以上义项的多义词:《现6》有216个,占多义词总数的1.58%,这些多义词全部是单音词;《牛8》有815个占多义词总数的8.13%。
由上可见,《现6》共有13650个多义词,《牛8》共有10027个,《现6》多义词条目比《牛8》多3623个,但多出的部分主要是2个义项的多义词,且绝大多数是复音词*《现6》中有两个义项的多义词的数目是10253个,《牛8》中有两个义项的多义词数目是4664,前者比后者多5589个。。除此之外,《现6》多义词义项数目都比《牛8》少:含有3个义项的多义词,《现6》比《牛8》少201个;含有4个义项的多义词,《现6》比《牛8》少504个;含有5个义项的多义词,《现6》比《牛8》少276个;含有6个义项的多义词,《现6》比《牛8》少226个;含有7个义项的多义词,《现6》比《牛8》少391个;含有7个义项的多义词,《现6》比《牛8》少158个;8个及以上义项的多义词,《现6》比《牛8》少599个。
三、《现6》《牛8》多义词义项数目异同原因分析
尽管《现6》比《牛8》多出3623个多义词,但是除含有2个义项的多义词《现6》比《牛8》的数目多之外,其他都是《现6》义项数少于《牛8》。两部词典多义词义项数目的差别主要集中在4个义项到20个义项之间,《牛8》有4个及以上义项的多义词共有3128个,而《现6》仅有1418个。《现6》和《牛8》义项数目出现上述差别的主要原因在于《牛8》的编纂者在20世纪八九十年代就已经用语料库技术发现英语常用多义词的新义项了,而《现汉》的编纂者却没有。
张志毅指出:“语料库理念萌生于1959年伦敦大学语言学教授R. Quirk:几年间建起涵盖多种语体的上百万字的‘英语用法语料库’。1961年美国布朗大学建起第一个机读的逾百万字的‘布朗语料库’。从20世纪80年代起,柯林斯等出版社和伯明翰等大学合作,创建了‘CO-BUILD语料库’,由此开发了《柯林斯COBUILD英语词典》。《牛津高阶英语学习词典》、《朗文当代高级英语辞典》、《钱伯斯基础英语词典》等的最新版本,也都是以语料库为依托编写而成。”[3]世界语言学自20世纪五六十年代进入语料库时代,英语词典编纂者在20世纪八九十年代就把语料库技术广泛应用于英语词典的编纂与研究中了,他们非常重视用语料库技术发现英语多义词的新义项,我们的统计显示《牛津》1至8版中100核心词的平均义项分别是7.55个、7.91个、7.03个,8.25个、8.47个,10.2个、10.47、10.61。《牛津》(1至3版)分别出版于1948、1963、1974年,这三版中100核心词的平均义项数目基本稳定,这说明此段时间《牛津》词典编纂者还没有利用语料库技术把丰富补充常用词的义项作为重点修订对象;《牛津》(4至6版)分别出版于1989、1995、2000年,这三版中100核心词的平均义项数目有较大的变化,这说明这三版的词典编纂者已经利用语料库技术把丰富补充常用词的义项作为重点修订对象;《牛津》(6至8版)分别出版于2000、2005、2012年,这三版100核心词的平均义项数目基本稳定下来,并且从第6版开始《牛津高阶英语词典》常用词的编纂体例也发生了很大变化。
目前,占据英语辞书主要市场的牛津、韦氏、朗文与麦克米伦等英语词典,都是在语料库的基础上编成的。在最新出版的英语类中型语文性词典中,100核心词的平均义项分别是:《牛津高阶英语词典》 (第8版)10.61个,《牛津简明英语词典》(第10版)12.81个,《麦克米伦高阶英语词典》(第2版)11.68个,《韦氏高阶英语词典》(2009年)11.43个,《郎文当代英语词典》(第4版)10.35个。与传统凭借语感编纂的词典相比,建立在语料库技术基础上的英语类中型语文性词典在多义词义项划分方面更加细化、义项收录更加全面,在词典编纂史上实现了里程碑式的跨越发展。
章宜华早在2010年就指出:“词典语料库是西方上世纪70—80年代的产物,而我们直到90年代才有这方面的成果发表,而至今大多仍只限于纸上谈兵,没有投入商业运营的大型词典语料库;而在西方谈语料库的建设和重要性已经是个过时的话题。这些都值得学术界和出版界注意。”[4]确实,中国自20世纪90年代起就开始相继建设了一批汉语语料库,最有代表性的如北京大学中国语言学研究中心研制的“CCL语料库”,截止2015年9月18日现代汉语语料库规模已达5.81亿字,可以说,目前我国的语料库已经初步具备了词典编纂所需要的规模。尽管如此,在当今中国,用语料库技术发现汉语常用词新义项的方法还没有引起汉语词典编纂者的足够重视。例如:我们的统计显示《现汉》1至6版中100核心词的平均义项分别是4.85个、5.20个、5.18个、5.18个、5.20个、5.42个,这表明,《现汉》(1至6版)并没有把丰富补充常用词的义项作为重点修订对象,也就是说《现汉》(第6版)对100核心词义项的划分还和《现汉》(第1版)基本一致。与《现汉》同类别的其他汉语类词典:《现代汉语规范词典》(第2版)100个核心词的平均义项是5.68个,《现代汉语学习词典》(2010版)5.9个,《新华词典》(最新修订版)4.33个,这说明汉语类中型语文性词典中100核心词乃至更多常用词义项的划分并没有建立在大型语料库的基础上进行成规模地系统修订,也说明汉语类词典中常用多义词的义项至今依然处在20世纪五六十年代靠语感确定义项的编纂水准。因此汉语类词典中存在常用多义词义项收录不全的情况就在所难免了,从而导致汉语类中型语文性词典义项的划分比较粗疏、存在义项漏收的情况。
评价一部词典是否优劣的基本参数有两个:一是词典的编纂体例,二是词典中常用多义词的释义,而词典编纂体例是否完善也最终体现在常用多义词释义方面,也即常用多义词义项的精细度、常用多义词义项的释义用语、常用多义词义项的排列等方面。《现汉》从20世纪五六十年代开始编纂,1978年发行第1版, 2012年发行第6版,但是半个世纪以来,《现汉》(1-6版)无论在编纂体例方面还是常用词的释义方面基本没有变化,因此,按照上述标准评价以《现汉》为代表的汉语类词典,我们很容易就会得出《现6》常用词义项方面的编纂水准至今仍处在20世纪五六十年代的水平,落后于英美国家同类型的词典。
古今中外语文性词典的差别主要体现在常用词的释义方面,《现汉》与同类别的英语词典相比落后的主要原因在于《现汉》没有用语料库技术的方法丰富并补充常用词的义项。用语料库搜集语料与人工搜集语料相比具有许多优越性,最重要的优点就是用语料库搜集语料具有里程碑式的、划时代的方法论意义,以“黑”为例:用语料库检索的方法可以在16毫秒的时间内得出“黑”在CCL现代汉语语料库中有130831条。假设用人工阅读的方法查找1条含有“黑”字的语句需要用1个小时(实际上有时候不止1个小时),那么要找130831条“黑”字语料则要用130831小时。经过计算可以知道查找同样多的语料的速度,用语料库技术的方法约是人工阅读的290多亿倍,简直是神速。
我们可以根据有关字频、词频的统计材料,确定3000个构词能力强、使用频率高的常用词作为主要研究对象,在语料库基础上以个案研究和系统研究相结合的形式着重探讨现代汉语中3000常用词的义项分布:一方面可以详细描写出每个常用词在现代汉语中的义项分布情况,另一方面也可以归纳出同类词在现代汉语中的义项分布规律。
如果说李仕春通过统计100核心词的数据说明“长期以来中国词典的编纂者乃至研究现代汉语词汇的学者忽视了现代汉语100核心词乃至更多常用词义项的研究”[1],那么本文则进一步印证了这一观点——《现6》的编纂者确实忽略了用语料库技术丰富并补充现代汉语常用词义项分布情况的研究。
四、结语
《现代汉语词典》自问世以来,发行量大、应用面广,世所罕见,特别是进入新世纪以来《现汉》每年的发行量大概在300万至500万册之间,销售额度在2—4亿,可见其在国民学习生活中的重要作用,堪称国典,然而却还存在着落后的一面。李仕春《语料库视野下的现代汉语“绿”字义项分布研究》[5]、《语料库视野下的现代汉语“狗”字义项分布研究》[6]等系列文章,就以理论和实践的形式说明汉语中常用词的义项数目一点也不比英语中常用词的义项数目少。因此,在汉英词典的视角下,在已有汉语类词典释义的基础上,运用语料库技术的方法,描写出现代汉语中常用词的义项分布情况,是一项刻不容缓的任务。这样的研究成果有利于《现汉》的编纂水准达到国际先进的水平,是功在当代利在千秋的利国利民的大好事。
[参考文献]
[1]李仕春.汉英词典100核心词释义对比研究[J].中南大学学报:社会科学版,2013,(6):252-258.
[2]苏新春.汉语释义元语言研究[M].上海:上海教育出版社,2005:51.
[3]张志毅.辞书强国——辞书人任重道远的追求[J].辞书研究,2012,(1):1-9.
[4]章宜华.《辞书研究》与新时期词典学理论和编纂方法的创新[J].辞书研究,2010,(1):57-69.
[5]李仕春.语料库视野下的现代汉语“绿”字义项分布研究[J].山西大同大学学报:社会科学版,2013,(5):62-66.
[6]李仕春,李蓓.语料库视野下的现代汉语“狗”字义项分布研究[J].北华大学学报:社会科学版,2013,(5):9-11.
[责任编辑:康邦显]
中图分类号:H06
文献标识码:A
文章编号:1001-0238(2016)01-0109-04
[作者简介]李仕春(1973—),男,山东莒县人,西南大学文学院教授,主要从事词汇学、词典学研究。
[基金项目]国家社会科学基金重点项目“语料库视野下的现代汉语单音多义词义项分布研究”(14AYY018);教育部规划基金项目“山东方言表体范畴的语法化音变研究”(11YJA740048);西南大学科研基金资助项目“语料库视野下的现代汉语单音多义词义项分布研究”(SWU1509502)。
[收稿日期]2015-11-25
