镨/钕萃取过程组分含量多RBF模型预测
2016-05-11陆荣秀叶兆斌杨辉何峰华东交通大学电气与电子工程学院江西南昌330013江西省先进控制与优化重点实验室江西南昌330013
陆荣秀,叶兆斌,杨辉,何峰(华东交通大学电气与电子工程学院,江西 南昌 330013;江西省先进控制与优化重点实验室, 江西 南昌 330013)
镨/钕萃取过程组分含量多RBF模型预测
陆荣秀,叶兆斌,杨辉,何峰
(华东交通大学电气与电子工程学院,江西 南昌 330013;江西省先进控制与优化重点实验室, 江西 南昌 330013)
摘要:针对具有特征颜色的镨/钕(Pr/Nd)萃取过程中元素组分含量难以快速准确检测的问题,提出了一种基于多RBF神经网络模型的组分含量建模及其自适应校正方法。通过选择Pr/Nd溶液图像特征H、S分量一阶矩为模型的输入变量,采用减法聚类对样本数据进行分类并建立相应的子模型;当萃取运行环境或对象特性发生变化导致模型精度不够时,根据模型参数调整策略自动调整各子模型的网络结构和参数,实现元素组分含量的准确预测。针对某Pr/Nd生产过程实际数据实验对比,结果表明本文方法能够满足稀土萃取过程元素组分含量检测的高准确度和快速性要求。
关键词:萃取过程;组分含量;神经网络;多模型;自适应;预测
2015-12-22收到初稿,2015-12-29收到修改稿。
联系人:杨辉。第一作者:陆荣秀(1976—),女,博士,副教授。
Received date: 2015-12-22.
Foundation item: supported by the National Natural Science Foundation of China (61364013, 51174091, 61563015) and the Earlier Research Project of the National Basic Research and Development Program of China (2014CB360502).
引 言
稀土元素组分含量的快速准确检测是实现稀土萃取过程各控制流量调节的关键环节之一。目前对稀土萃取过程组分含量快速检测的方法主要有两种,一种是运用在线检测仪器进行检测,但这些仪器普遍存在投资大、结构复杂、系统连续运行可靠性差等缺点[1-3],因而未能在稀土分离企业推广使用;另一种是软测量技术,由于其具有精确、可靠、经济、和动态响应快等特点,而成为解决这一问题的新方法[4-6]。而基于历史生产数据样本的组分含量软测量模型,其预测精度及泛化能力与萃取过程采集的历史生产数据密切相关,在长期连续监测时无法反映稀土萃取过程的动态信息[7],影响其实际应用。
针对具有离子特征颜色的稀土萃取分离体系,将机器视觉技术应用于萃取过程元素组分含量检测,为解决具有离子特征颜色的稀土萃取过程元素组分含量快速检测提供了新的思路。文献[8]在HSI颜色空间下分析镨/钕(Pr/Nd)混合溶液图像H特征分量与元素组分含量之间关系的基础上,利用最小二乘方法建立了色度(H)分量一阶矩与元素组分含量的关系模型,但该模型仅适用于单一元素组分含量占主导的情况。在此基础上,文献[9]以Pr/Nd混合溶液图像中与元素组分含量关联度强的H和饱和度(S)分量为输入,采用最小二乘支持向量机算法(LSSVM)建立了元素组分含量的预测模型,实现稀土元素组分含量快速检测。但以上模型均建立在历史数据样本的基础上,在稀土萃取运行环境和对象特性发生变化时,容易导致模型预测精度变差。
文献[10]指出稀土萃取过程是一类运行工况复杂的工业过程,萃取槽中元素的组分含量分布往往存在大范围的波动。采用单一模型建模需要大量的数据,且模型具有学习时间过长、过程匹配不佳、精度和外推能力差等缺陷[11-12]。而具有自校正能力的多模型建模方法能在一定程度上克服上述不足。文献[13]提出在采用支持向量机算法建立的拟稳态过程软测量模型中,将建立的两个模型结果进行线性融合获得了比较理想的预测精度。文献[14]提出一种基于在线减法聚类的RBF神经网络结构优化设计方法,使RBF神经网络具有良好的自适应能力。
本文以Pr/Nd混合溶液图像的颜色特征H、S分量一阶矩为输入变量[15],采用减法聚类对样本数据进行分类并对每一类数据建立基于RBF神经网络的子模型,然后按照一定的规则将子模型进行组合得到元素组分含量预测模型;当萃取环境或者对象特性发生改变时,根据模型参数校正策略,实现元素组分含量模型的自适应校正。经过Pr/Nd萃取现场数据测试实验,结果表明本文方法有较好的自适应能力,适用于稀土萃取过程组分含量的准确快速预测。
1 多模型建模策略
鉴于Pr/Nd萃取过程流程长、影响因素多,元素组分含量难以快速、准确检测,采用多RBF建模方法建立元素组分含量预测模型,其结构框图如图1所示。多模型的结构可以分为输入聚类层、子模型层和输出层。
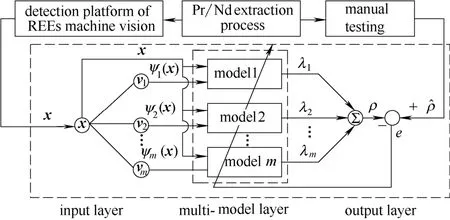
图1 元素组分含量多模型结构框图Fig.1 Multi-model block diagram of element component content
(1)输入聚类层
以稀土混合溶液图像在HSI色彩空间中的H和S分量一阶矩作为模型的输入,则样本的输入量表示为:表示样本数;图1中的ψi(x )( i= 1,2,… ,m )为开关函数,m为聚类数,即式中,vi表示第i个聚类中心;δ表示激活阈值。当ψi(x)为1时,则表示对应的model i子模型被激活,反之则没有被激活。
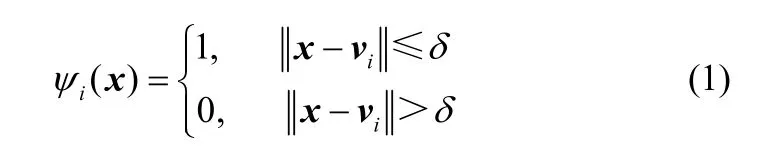
由式(1)可知,改变距离阈值δ的大小可以改变输入样本激活子模型的个数。
(2)多模型层
采用RBF神经网络作为子模型,即每一个子模型均表示一个RBF神经网络。
(3)输出层
以元素组分含量作为模型的输出变量。由图1可知,元素组分含量的模型输出值ρ为
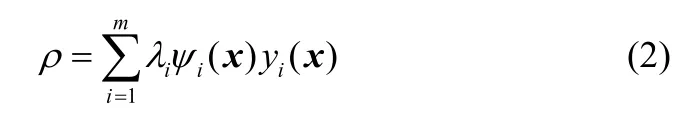
式中,λi为第个子模型的输出权值,与样本x到聚类中心的距离有关;yi(x)为第i个子模型的输出值。
要得到式(2)的元素组分含量模型输出值,必须确定:①聚类个数m及其聚类中心vi和距离阈值δ;②子模型的网络结构及参数;③输出层中各子模型的合成权重。
1.1 聚类个数及其参数确定
确定输入聚类数m及其参数vi、δ的方法很多,鉴于减法聚类与其他聚类方法相比,具有仅根据样本数据密度即可快速确定聚类中心的位置和聚类数的优点;且它把每一个数据点作为一个潜在的聚类中心,可以克服山峰聚类法计算量随着问题的按指数增长的不足,使得聚类的结果与问题的维数无关[16-17],故本文选用减法聚类算法。
对于n个稀土混合溶液样品,即n个样本数据点,采用减法聚类确定聚类数时,每一个样本点的输入量均可作为一个聚类中心的候选者。当第k个数据点的输入量为作为聚类中心的候选者时,密度函数Dk定义为
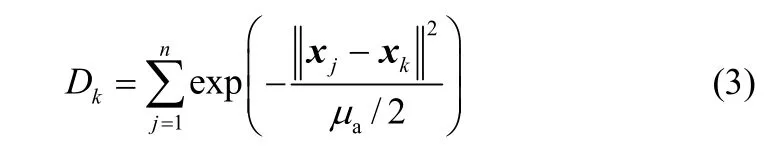
式中,μa半径是一个正数。一般按式(4)设定μa
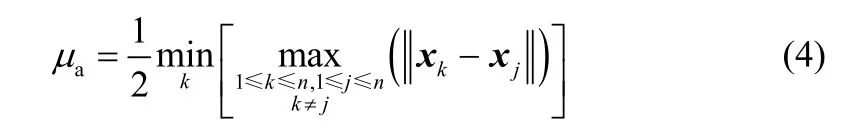
μa定义了该点的影响邻域,半径以外的数据点对该点的密度指标贡献非常小,一般忽略不计。
计算每一个数据点的密度值,选择具有最高密度指标Dc1的数据点作为第一个聚类中心v1;然后按式(5)修正密度值,消除前面已有聚类中心的影响。
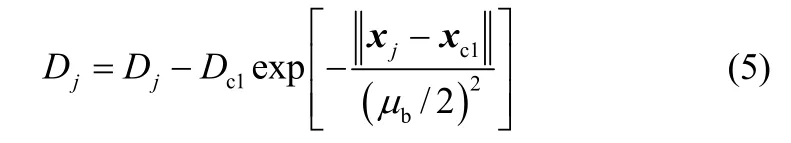
式中,Dc1为初始聚类中心对应的最高密度值;xc1为Dc1对应的样本点,修正半径μb的设定是为了避免第2个聚类中心点离前一个中心点太近,一般设定为μb=ημa,1.25≤η≤1.5。
当修正后的数据点最大密度指标D'与初始最高密度值Dc1满足式(6)时,该密度指标D'对应的聚类中心即为新的聚类中心v2。

式中,γ为根据实际情况提前设定的阈值。
不断重复上述这个过程,直到新的密度指标D′与Dc1不满足式(6)时,聚类算法终止,同时得到聚类个数m及其聚类中心。距离阈值δ可由式(7)确定
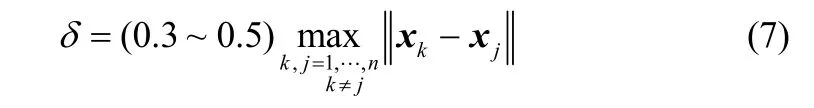
通过上述计算,将n个稀土溶液样品分成了m类,第i类的样本数据表示为,,,ni是第i个子模型的数据样本个数。
1.2 多模型的结构
RBF神经网络具有学习速度快、局部响应等优点,适合于自适应学习[18-20],故本文采用RBF网络自适应建模方法对各个子模型进行建模。鉴于各子模型的输入变量个数为2,模型的输出变量个数为1,故采用2−h 1−结构(h为隐节点数)的RBF网络实现以下映射
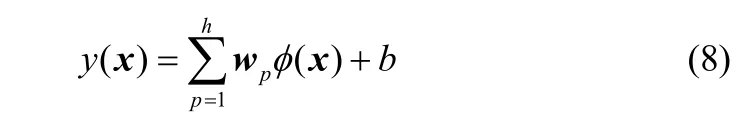
1.3 元素组分含量预测输出
权值iλ决定了各子模型输出值在元素组分含量多模型输出中的大小。其值由式(9)确定

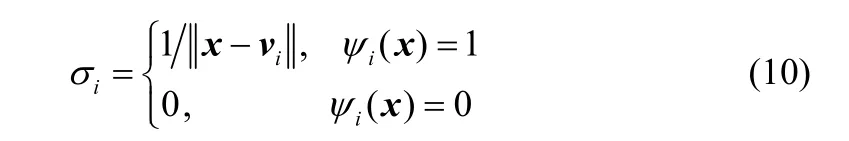
将iλ代入式(2),则得到元素组分含量多模型输出值。
由上述建立元素组分含量多模型的过程可知,当数据样本的聚类个数确定后,各RBF网络子模型的隐层节点数h和网络参数cp、rp和wp对元素组分含量模型的输出值有很大的影响,当萃取环境或对象特性发生改变时,为了保证高精度的组分含量预测模型,应采取适当的调整策略对模型进行适时调整。
2 多RBF模型结构及参数的调整策略
元素组分含量多RBF模型的调整通过各子模型的网络结构及权值进行实时调整来实现。
当有测试样本xk时,子模型的输出误差ek

样本xk到第i个聚类中心vi的距离dki

根据输出误差ek和最短距离dki调整网络参数。由于不同的子模型的样本数据特性不同,对每个子模型分别设置两个误差阈值1ε、εmin,令0<ε1<εmin,一个距离阈值ζmin,则子模型的网络结构及参数的调整策略如下:
①如果|ek|≤ε1,则保持网络结构及参数不变;
②如果|ek|≥εmin且di≥ζmin,则在线增加隐节点以快速消除误差,并调整网络参数;
③如果ε1≤|ek|≤εmin,则保持网络结构不变,仅调整网络参数数据中心cp、扩展常数rp和输出权值wp;
④当两个隐节点的数据中心cp和扩展常数rp之间的距离分别小于合并阈值Δcmin、Δrmin时,则进行隐节点的合并操作。
2.1 网络结构调整方法
根据上述调整策略,网络结构的调整主要包括隐节点的增加和合并或删减两个操作。
(1)增加隐节点的操作
新输入一个样本(x', ρ'),如果当前激活子模型对该样本的偏差过大,且样本输入距离当前所有子模型的数据中心都较远,那么认为当前网络无法准确预测样本(x', ρ'),即认为该样本是“新”的,此时需采用网络调整策略中的方案(2),即增加新的隐节点以快速消除偏差,且该新隐节点的数据中心ch+1、扩展常数rh+1和输出权值wh+1分别为

式中,κ称为重叠因子。
(2)隐节点合并或删除
①隐节点合并。假定p、t是两个隐节点,由于它们的数据中心cp、ct会不断调节,最终cp、ct可能比较接近,若有



表明出现了冗余隐节点,则需要将这两个隐节点进行合并操作。合并后的隐节点的数据中心cp、拓展常数rp和输出权值wp分别为
式中,Δcmin、Δrmin是合并阈值。于是对任意输入x,隐节点p、t的输出满足
②隐节点删除。网络在线调整的过程中,如果有某个隐节点长时间没有被任何输入数据激活,则表明该隐节点已经不能跟踪实时工况。为了使RBF网络维持紧凑的结构,这些隐节点应该被删除。
2.2 网络参数调整方法
通过最小化目标函数实现对子模型隐节点的数据中心cp、扩展常数rp和输出权值wp的调整。
设神经网络学习的目标函数为

式中,β= 1/N,第k个样本的训练误差ek由式(11)获得。
神经网络函数y(x)对数据中心cp、扩展常数rp和输出权值wp的梯度分别为
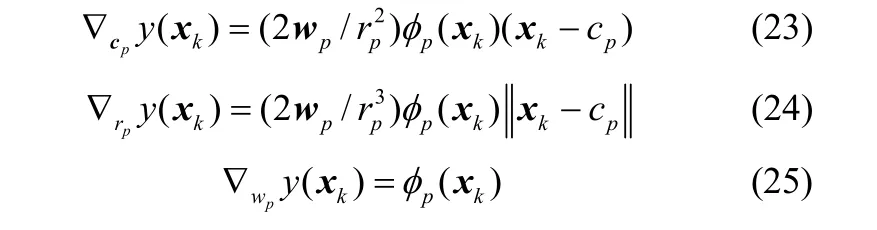
考虑所有训练样本的影响,cp、rp和wp的调节量Δcp、Δrp和Δwp分别为

式中,ϕp(xk)为第p个隐节点对xk的输出;wp为该隐节点输出权值;η为学习率。
为了加快学习,采用带有动量项的梯度调节算法
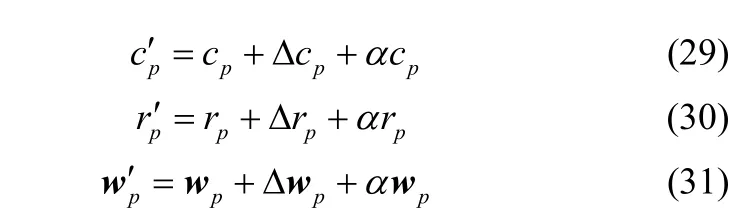
当达到给定训练次数,或样本的误差满足以下指标时停止训练

为了加快收敛,当两次梯度修正之间误差不再下降时停止学习,即

Δχmin一般应小于0.0001。
2.3 元素组分含量多模型自适应校正步骤
以Pr/Nd萃取过程溶液图像H、S分量一阶矩为输入变量,采用多RBF神经网络建立组分含量自适应模型的具体步骤如下。
(1)采用减法聚类算法对样本数据聚类分析,得到模型数m,聚类中心及相应数据集。
(2)利用RBF神经网络分别对各数据集建立相应的子模型。初始化子模型时,令偏移为激活该子模型的第一个样本的输出,即b= y0;初始隐节点的数据中心cp= [x0];扩展常数rp= [0.5];权值wp= [0],并设定各阈值,包括:距离阈值δ,误差阈值ε1、εmin。
(3)由式(1)确定被激活的子模型,由式(9)计算出各子模型权值λi,最后根据式(2)得出元素组分含量多模型预测输出ρ,即建立了基本的元素组分含量多模型。
(4) 当采集到新样本数据x'时,采用上述模型进行预测,并根据模型的输出误差,对被激活的子模型进行如下操作:
① 通过式(12)计算子模型对应的聚类中心vi到样本xk的距离dki;
② 若|ek|≤ε1,则保持网络参数保持不变;
③ 若|ek|≥εmin且dki≥ζmin,则通过式(13)~式(15)在线增加隐节点数以快速消除误差;
④ 若ε1≤|ek|≤εmin,则通过式(29)~式(31)采用梯度下降法调整网络参数数据中心cp′、扩展常数和输出权值;
⑤ 根据式(16)和式(17)判断是否进行隐节点合并操作,若满足条件则通过式(19)~式(21)进行隐节点的合并操作。若隐节点长期未被激活,则进行隐节点的删除操作,并保持其他隐节点及其网络参数不变。
(5)当采集到新的稀土溶液数据样本时,转步骤(4);反之,结束。
3 仿真实验
为检验本文方法在稀土萃取过程组分含量建模中的有效性和可行性,以某公司Pr/Nd萃取分离生产过程为对象,在Pr/Nd萃取生产现场采集100份混合溶液样品,其中Nd元素组分含量分布在0.88%~99.25%,提取出混合溶液图像的H、S颜色特征分量一阶矩作为模型的输入变量,Nd元素组分含量作为模型的输出变量。为了消除变量间由于数量级差异带来的影响,将输入/输出样本组成的数据集进行归一化处理,并将处理后的数据集表示为:,。然后随机选取70组数据作为多RBF模型建模的训练样本,剩余的30组数据用来测试模型的有效性。
通过调整模型参数,对比输出结果,设置多模型的结构和优化参数为:聚类参数γ=1.5,,得到的聚类数为3个。设置相应的3个子模型参数如下:步长Nmax= [50, 400, 200],重叠因子κ=0.5,动量系数α= [0.3, 0.1, 0.2],距离阈值ζmin= [0.2, 0.2, 0.2],χ= 0.01,Δχmin= 0.0001,两个误差阈值为εmin= [0.06, 0.02, 0.04]、ε1= [0.005, 0.001, 0.001],数据中心c的学习率ηc= [0.11, 0.25, 0.85],扩展常数r的学习率ηr= [0.09, 0.2, 07],隐节点输出权值w的学习率ηw= [0.12, 0.2, 0.1],合并阈值Δcmin= 0.012,Δrmin= 0.01。建立的3个RBF子模型的隐含层节点数分别为:11、6和3,即子模型的网络结构分别为:2-11-1,2-6-1和2-3-1。基于多RBF模型的镨/钕萃取过程元素组分含量预测输出值和实测值的对比效果如图2所示,由图中可以看出,模型预测结果能较好地反映Pr/Nd萃取过程现场溶液中的元素组分含量值。由两者比较结果的相对误差图(图3)可知,所得相对误差均小于4%,满足Pr/Nd萃取生产过程工艺控制对于元素组分含量的精度要求。
为了直观展示建模过程中多模型隐节点的自适应变化,在建模过程中,采取了将每一组样本数据依次输入的形式,即以第1组样本数据按2.3节的步骤(1)~步骤(3)建立一个预测模型,以后每增加一组样本数据,均执行步骤(4)~步骤(5),当70组训练样本数据依次输入完毕,模型的训练过程结束。图4以子模型1为例展示了其隐节点在训练过程中的变化情况。
由图4可知,子模型1无论是在模型训练(前30次)还是在模型测试时(后18次),隐节点数均能依据模型校正测量进行自适应调整。

图2 元素组分含量多RBF模型输出结果Fig.2 Output results of element component content based RBF-models
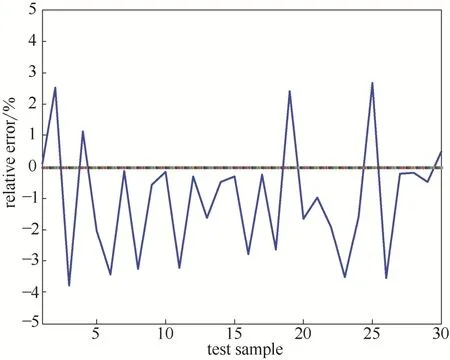
图3 元素组分含量多RBF模型输出误差Fig.3 Output errors of element composition based RBF-models
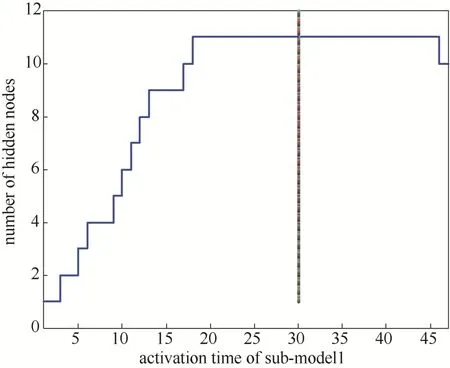
图4 子模型1中隐节点的变化情况Fig.4 Change of hidden nodes in sub-model 1
为了检验多模型参数自适应校正在组分含量预测时的优越性,采用相同数据对以下3种方法建立的组分含量模型进行仿真对比:方法1与方法2在建立模型时的过程相同,但在进行模型测试时,方法1的隐节点及参数能自适应校正,即本文所提方法的模型;方法2则保持模型中各参数均不改变;方法3是基于文献[18]中的单一RBF网络自适应调整参数方法建立的稀土萃取过程元素组分含量预测模型。以式(34)、式(35)的平均相对误差(MRE)和均方根误差(RMSE)两个指标衡量建模测试结果的优劣,并将30组数据的测试性能指标值列出(表1)。

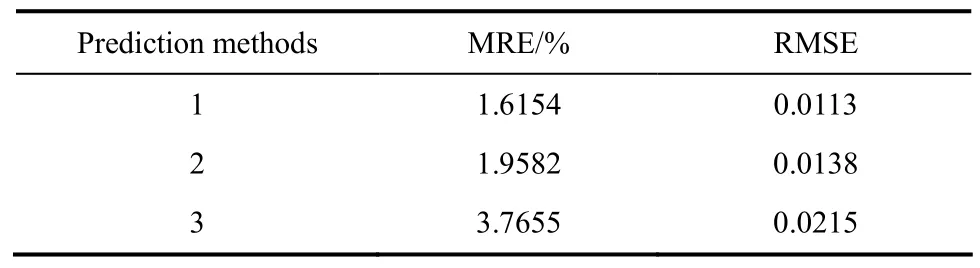
表1 3种方法的测试性能结果比较Table 1 Comparison of testing performance
由表1可知,方法1相比于模型参数固定的方法2而言,其模型的平均相对误差和均方根误差均减小,说明自适应调整网络结构参数能提高模型的预测精度。对比方法1与方法3可知,本文提出的多模型自适应校正模型的泛化能力优于单一模型自适应校正的方法3,这是因为组分含量在不同区域对象特性也不相同,从而造成方法3的过程匹配不佳。
4 结 论
针对具有离子特征颜色的稀土萃取过程元素组分含量存在难以准确快速检测的问题,应用模型结构和参数均能进行自适应校正的多RBF模型方法建立了基于Pr/Nd溶液图像颜色特征的元素组分含量预测模型。采集萃取现场数据进行实验比对,表明本文方法具有较高的预测精度和较好的泛化能力,适用于具有离子特征颜色的稀土萃取分离过程组分含量快速准确检测,为稀土工业可持续发展提供技术支撑。
符 号 说 明
b——输出偏移
cp,——分别为第p个隐节点梯度调节前、后的数据中心
Dk——第k个数据点的聚类密度
dki——样本到第i个聚类中心的距离
ek——子模型的输出误差
H ——HSI颜色空间的色相
h ——子模型隐层节点数量
m ——聚类数
model i ——第i个子模型
n ——样本数
rp——第p个隐节点的拓展常数
Δrmin——拓展常数rp的合并阈值
Δrp——梯度下降法中rp的调节量
S ——HSI颜色空间的饱和度
vi——第i个聚类中心
wp、——第p个隐节点梯度调节前、后的输出权值
Δwp——梯度下降法中wp的调节量
x ——样本输入量
xHj, xSj——分别为第j个输入样本中的H分量和S
分量一阶矩
yi(x) ——第i个子模型的输出值
α ——动量因子
β ——为1/n,即样本总数的倒数
δ ——激活阈值
ε1, εmin——误差阈值
ζmin——距离阈值
η ——学习率
к ——重叠因子
λi——第i个子模型的输出权值
μa, μb——聚类半径
ρ ——模型输出值
References
[1] 杨辉, 柴天佑. 稀土分离过程综合自动化系统研究 [J]. 稀有金属, 2004, 28 (6): 1071-1075. DOI: 10.3969/j.issn. 0258-7076.2004.06.024.
YANG H, CHAI T Y. Integrated automation system for rare earths countercurrent extraction process [J]. Chinese Journal of Rare Mentals, 2004, 28 (6): 1071-1075. DOI: 10.3969/j.issn.0258-7076.2004.06.024. [2] 许勇刚, 杨辉. 基于RBF网络的稀土萃取过程组分含量软测量 [J].稀土, 2007, 28 (5): 19-22. DOI: 10.3969/j.issn.1004-0277.2007.05.005.
XU Y G, YANG H. Component content soft-senor based on RBF neural network in rare earth countercurrent extraction process [J]. Chinese Rare Earths, 2007, 28 (5): 19-22. DOI: 10.3969/j.issn.1004-0277.2007.05.005.
[3] 田海, 郭智恒, 李兰云. 稀土萃取分离过程软测量方法的研究 [J].中国稀土学报, 2015, 33 (2): 201-205. DOI: 10.11785/S1000-4343. 20150209.
TIAN H, GUO Z H, LI L Y. Soft-sensing in rare earth extraction [J]. Journal of the Chinese Rare Earth Society, 2015, 33 (2): 201-205. DOI: 10.11785/S1000-4343. 20150209.
[4] 向峥嵘, 刘松青. 基于LS-SVM的稀土萃取组分含量软测量 [J].中国稀土学报, 2009, 27 (1): 132-136. DOI: 10.3321/j.issn.1000-4343.2009.01.024.
XIANG Z R, LIU S Q. Component content soft-sensor in rare earth extraction based on LS-SVM [J]. Journal of the Chinese Rare Earth Society, 2009, 27 (1): 132-136. DOI: 10.3321/j.issn.1000-4343.2009. 01.024.
[5] 贾文君, 柴天佑. 稀土串级萃取分离过程元素组分含量的多模型软测量 [J]. 控制理论与应用, 2007, 24 (4): 569-573. DOI: 10.3969/j.issn.1000-8152.2007.04.011.
JIA W J , CHAI T Y. Soft-sensor of element component content based on multiple models for the rare earth cascade extraction process [J]. Control Theory & Applications, 2007, 24 (4):569-573. DOI: 10.3969/ j.issn.1000-8152.2007.04.011.
[6] 李修亮, 苏宏业, 褚健. 基于在线聚类的多模型软测量建模方法[J]. 化工学报, 2007, 58 (11): 2834-2839. DOI: 10.3321/j.issn:0438-1157.2007.11.025.
LI X L, SU H Y, CHU J. Multiple models soft-sensing technique based on online clustering arithmetic [J]. Journal of Chemical Industry and Engineering (China), 2007, 58 (11): 2834-2839. DOI: 10.3321/j.issn. 0438-1157.2007.11.025.
[7] 杜文莉, 官振强, 钱锋. 一种基于时序误差补偿的动态软测量建模方法 [J]. 化工学报, 2010, 61 (2): 439-443.
DU W L, GUAN Z Q, QIAN F. Dynamic soft sensor modeling based on time series error compensation [J]. CIESC Journal, 2010, 61 (2): 439-443.
[8] 杨辉, 高子洁, 陆荣秀. 基于稀土离子颜色特征识别的组分含量检测方法 [J]. 中国稀土学报, 2012, 30 (1): 108- 112.
YANG H, GAO Z J, Lu R X. Detection method of component content based on rare earth ions color characteristics identification [J]. Journal of the Chinese Rare Earth Society, 2012, 30 (1): 108-112.
[9] 陆荣秀, 杨辉, 欧阳超明, 等. 基于PCA-LS_SVM的镨/钕萃取过程元素组分含量预测 [J]. 南昌大学学报 (理科版), 2013, 37 (6): 589-593. DOI: 10.3969/j.issn.1006- 0464. 2013.06.018.
LU R X, YANG H, OUYANG C M, et al. Forecast of element component content in Pr/Nd extraction process based on PCA-LS_SVM [J]. Journal of Nanchang University (Natural Science), 2013, 37 (6): 589-593. DOI: 10.3969/j.issn.1006- 0464. 2013.06.018.
[10] 柴天佑, 杨辉.稀土萃取分离过程自动控制研究现状及发展趋势[J].中国稀土学报, 2004, 22 (4): 427-433. DOI: 10.3321/j.issn:1000-4343.2004.04.001.
CHAI T Y, YANG H. Situation and developing trend of rare-earth countercurrent extraction processes control [J]. Journal of the Chinese Rare Earth Society, 2004, 22 (4): 427-433. DOI: 10.3321/j.issn:1000-4343.2004.04.001.
[11] HUANG M Z, WAN J Q, MA Y W, et al. A fast predicting neural fuzzy model for online estimation of nutrient dynamics in ananoxie/oxic process [J]. Bioresource Technology, 2010, 101 (6): 1642-1651.
[12] ALTUNAY P, SEVER A, SERDAR S G, et al. Prediction of effluent quality of an anaerobic treatment plant under unsteady state through ANFIS modeling with online input variables [J]. Chemical Engineering Journal, 2008, 145 (1): 78-85.
[13] 唐志杰, 唐朝晖, 朱红求. 一种基于多模型融合软测量建模方法[J]. 化工学报, 2011, 62 (8): 2248-2252. DOI: 10.3969/j.issn.0438-1157.2011.08.028.
TANG Z J, TANG Z H, ZHU H Q. A multi-model fusion soft sensor modeling method [J]. CIESC Journal, 2011, 62 (8): 2248-2252. DOI: 10.3969/ j.issn.0438-1157.2011.08.028.
[14] 张昭昭, 乔俊飞. 基于在线减法聚类的RBF神经网络结构设计[J]. 控制与决策, 2012, 27 (7): 997-1002.
ZHANG Z Z, QIAO J F. Design RBF neural network architecture based on online subtractive clustering [J]. Control and Decision, 2012, 27 (7): 997-1002.
[15] 陆荣秀, 欧阳超明, 杨辉, 等. HSI颜色模型在镨钕组分含量检测中的应用 [J]. 计算机与应用化学, 2013, 30 (10): 1157-1161. DOI: 10.3969/j.issn.1001-4160.2013. 10.016.
LU R X, OUYANG C M, YANG H, et al. Pr/Nd component content detection using a HSI color model [J]. Computers and Applied Chemistry, 2013, 30 (10): 1157-1161. DOI: 10.3969/j.issn.1001-4160.2013. 10.016.
[16] XIONG S W, NIU X X, LIU H B. Support vector machines based on subtractive clustering [C]//Proceeding of the Fourth International Conference on Machine Learning and Cybernetics, 2005: 43-45.
[17] 潘天红, 薛振框, 李少远. 基于减法聚类的多模型在线辨识算法[J]. 自动化学报, 2009, 35 (2): 220-224. DOI: 10.3724/SP.J.1004. 2009.00220.
PAN T H, XUE Z K, LI S Y. An online multi-model identification algorithm based on subtractive clustering [J]. Acta Automatica Sinica, 2009, 35 (2): 220-224. DOI: 10.3724/SP.J.1004.2009.00220.
[18] 魏海坤, 宋文忠, 李奇. 基于RBF网络的火电机组实时成本在线建模方法 [J]. 中国电机工程学报, 2004, 24 (7): 250-256. DOI: 10.3321/j.issn:0258-8013.2004.07. 047.
WEI H K, SONG W Z, LI Q. A RBF network based online modeling method for realtime cost model in power plant [J]. Proceedings of the CSEE, 2004, 24 (7): 250-256. DOI: 10.3321/j.issn:0258-8013.2004.07. 047.
[19] 乔俊飞, 韩红桂. RBF神经网络的结构动态优化设计 [J]. 自动化学报, 2010, 36 (6): 865-872. DOI: 10.3724/SP.J. 1004.2010.00865.
QIAO J F, HAN H G. Optimal structure design for RBFNN structure [J]. Acta Automatica Sinica, 2010, 36 (6): 865-872. DOI: 10.3724/ SP.J.1004.2010.00865.
[20] HAO C, YU G, XIA H. Online modeling with tunable RBF network [J]. IEEE Transactions on Cybernetics, 2013, 43 (3): 935-947.
研究论文
Multi-RBF models based prediction of component content for Pr/Nd extraction process
LU Rongxiu, YE Zhaobin, YANG Hui, HE Feng
(School of Electrical and Electronic Engineering, East China Jiaotong University, Nanchang 330013, Jiangxi, China; Key Laboratory of Advanced Control & Optimization of Jiangxi Province, Nanchang 330013, Jiangxi, China)
Abstract:It is difficult to rapidly and accurately detect the component content in the praseodymium/neodymium (Pr/Nd) extraction process. This paper proposes a multi-RBF model and its adaptive correction method of component content. Extracting the HSI image features of Pr/Nd mixed solution, the first moments of H and S components are selected as input variables. Using the subtractive clustering algorithm, the sample data are divided into several categories and the corresponding sub-models are obtained based on RBF neural network. To further realize the high-accuracy prediction of the element component content, a parameters adjustment strategy is designed to automatically adjust the network structure and parameters of sub-models when the change of operating environment or the object characteristics results in the accuracy of the prediction model doesn’t meet control requirements. The comparison experiments on actual production data from Pr/Nd extraction process show that the proposed method can meet the high-accuracy and rapid requirements of element component content detection in rare earth extraction process.
Key words:extraction process; component content; neural network; multi-models; adaptive; prediction
DOI:10.11949/j.issn.0438-1157.20151950
中图分类号:TP 273
文献标志码:A
文章编号:0438—1157(2016)03—0974—08
基金项目:国家自然科学基金项目(61364013,51174091,61563015);国家重点基础研究发展计划项目前期研究专项(2014CB360502)。
Corresponding author:Prof. YANG Hui, yhshuo@263.net
