面向语言信息处理的汉日同义句式研究策略
2016-05-06李哲常州工学院江苏常州213002
李哲(常州工学院 江苏 常州 213002)
面向语言信息处理的汉日同义句式研究策略
李哲
(常州工学院 江苏 常州 213002)
面向语言信息处理,对汉日同义句式的句法结构和语义特征进行详细系统的分析考察,利用语料库抽取实例进行语义分类并提出相应的机器翻译规则,生成计算机识别流程图。该研究策略的有效性需通过海量真实语料进行验证,将信息处理的结果与人工翻译和现有的在线机器翻译对比,从而验证生成的同义句式识别流程图的效度。
语言信息处理;汉日同义句式;句法结构;语义特征
语言信息处理是将计算机科学应用在语言学领域,两门学科交叉形成的新型学科,是应用语言学的重要组成部分。随着网络的普及和全球化趋势的发展,语言信息处理领域的应用范围大大延伸,特别是机器翻译的应用形式更加多样化,云计算和移动终端的普及等使机器翻译、口语翻译、文字扫描翻译、照相翻译等都开始实际应用。然而语言信息处理过程中,不同种类的语言之间的句处理问题越来越突出。
1.问题提起
1.1 先行研究
为解决计算机的句处理问题而进行的语言信息处理及机器翻译研究不论在国内还是国际上都是竞争激烈的研究领域之一,也是人工智能和信息处理领域中的实用技术之一。国内汉日语言学界关于汉日同义句式对比的语言学基础研究较常见,如李金莲(2010)《基于平行语料库的中日被动句对比研究》、付佳(2012)《汉日祈使句对比研究》以及张北林等(2013)《WH疑问词转折句式汉日对比研究》等。这些研究尽管角度不一,有的从类型学模式切入,有的在认知模式下进行,但实质上都属于语言学的本体研究,面向语言信息处理的语言学应用研究非常少见。目前我国汉日语言信息处理的研究主要集中在自然科学领域的研究者身上,如南京大学计算机软件国家新技术重点实验室的张鹏等(2002)在《从日语格语法表示生成汉语的难点分析》一文分析了基于转换规则的日汉机器翻译中的汉语生成方法,重点分析了基于日语格语法表示的汉语生成所面临的难点,同时,还对句子的语气、时体态、标点符号和关联词的表层处理等进行了讨论。戴新宇等(2003)在《从汉语格关系表示生成日语》一文中描述了一种基于格关系的汉语依存分析树,给出基于规则的日语生成系统的组织结构。清华大学的杜伟、陈秀群等(2008)在《多策略汉日机器翻译系统中的核心技术研究》中通过生成各翻译核心子系统所使用的核心技术和算法,构建了一个多策略的汉日机器翻译系统。另外还有黄金柱等(2012)在《依存语法在日汉自动句法转换中的应用》中分析了根据日汉语言的特点及差别,利用依存语法来处理在日汉机器翻译中遇到的一些问题。刘颖(2014)在《计算语言学》一书中提到了目前日本主流的开源自动词性赋码器,详细介绍了日语的分词、分词歧义、分词算法等。
在日本,汉日语言信息处理的研究主要启动与2006年。日本筑波大学石原彻也以及岐阜大学的池田研究室都对汉日机器翻译有较深入的研究,并开发出了跨语言信息检索和中日机器翻译系统等。另外,日本的企业研究所在这方面实力也非常强,如东芝致力于解决汉日机器翻译时的歧义问题,开发了“基于统计的中文解析技术”。面向中日语言信息处理的日语生成在日本起步较早,已有一些研究,IBM日本研究院Taijiro等(1986)曾经对一些技术手册进行机器翻译,日语生成采用的是基于转换方法。Sumumu(1994)等则提出了实例转换和规则相结合的日语生成方法。日本京都大学长尾真和佐藤的MTBI和MTB2系统是比较有名的基于实例的机器翻译系统。
综上,在语言学领域,面向语言信息处理的汉日同义句式研究方面,汉日句式对比的语言学本体研究较多,应用研究较少,将语言学与计算机科学相结合的更是少之又少。在自然科学领域的日汉机器翻译研究相对丰富,但是,几乎所有此方面的研究人员都提出,高质量的中日翻译系统开发,需要精通中日两种语言的语言学研究人员参与进来,以完善翻译系统的精度,解决其中汉日语言结构不同所带来的诸多问题。
1.2 研究价值
语言信息处理特别是机器翻译中,最大的难题是句处理问题。面向语言信息处理中的难题,选取最为经典和常用的汉日同义句式进行句法结构和语义特征分析,对比中日同义句式在结构上的异同,然后将其改写为计算机识别流程图。在理论上可以扩展汉日语言对比的研究视角,将普通的语言学本体研究与自然科学研究相结合,丰富语言学理论的使用范围和研究功能。
从应用价值看,对汉日同义句式进行结构分析和深层语义解析,并由此生成计算机识别流程图,可为自然科学领域的汉日机器翻译系统的进一步研发提供线索和指导,以达到开发出精度更高的汉日语言识别系统或机器翻译软件的成效。面向语言信息处理的语言对比研究可以促进机器翻译的发展,与此同时机器翻译的研究也可以促进语言研究的发展。基于以上方面,面向语言信息处理的汉日同义句式对比研究极具学术和实际应用价值。
2.语言信息处理中的汉日同义句式研究
2.1 汉日翻译软件中的语言信息处理问题
目前市场上比较成熟的在线翻译软件网易有道在线翻译、百度在线翻译、Goole在线翻译等。面向语言信息处理的汉日同义句式对比研究,首先要从汉日机器翻译着手,找到汉日同义句式在语言信息处理流程中亟待解决的主要问题,即提出计算机要处理的语言学问题。以汉日比较句式“X比Y+形容词”句式为例解析:
句式:“X比Y+形容词”
例句(1)我比他高
使用目前市场上主要汉日机器翻译软件生成的句式:
有道在线翻译:私はボーグスよりもっと高い
百度在线翻译:私は彼より高い
Google在线翻译:私は彼より背が高いんだ
例句(2)今天下雨,比昨天冷多了
有道在线翻译:今日は雨が降っても、は昨日より寒いですがありました
百度在线翻译:今日も雨、昨日より寒い
Google在线翻译:昨日より今日、雨、寒さかなり良く
以上译文中标记下划线的部分为各软件翻译不当之处。从翻译结果来看,三个翻译软件的日文生成各有正误。例句(1)结构简单,三个软件均表现出了较高的准确率,语言信息处理的词对词翻译显示出了较大的成熟度。对例句(2)的翻译识别三种软件均有不同程度的失误,究其原因在于目前的翻译软件难以准确完成高质量的句法结构处理和语义特征识别。
2.2 句法结构描述和语义特征分析
针对上一步的发现的具体问题,对汉日比较句式进行详细的句法结构和语义特征分析。从信息处理的角度重新观察语言学,将汉日同义句式的句法和语义问题形式化,使之能严谨规范并能对应于计算机信息处理的规则方法。比如“X比Y+形容词”可拟做以下分析:
句式特点:汉日比较句式是两种语言中的经典句式,表示两种事物(包括人在内)之间在某种性质上的程度差别。这里的X、Y代表两种事物,形容词表示程度差别。X是比较主体,Y是比较客体,由介词或助词引导。而日语比较句式一般格式为“AはBより+形容词”。日语中的A和B分别对应了汉语中X和Y的主体和客体功能,但是,从句法结构上来描述,日语助词“は”的添加和比较助词“より”的位置是此类句式分析的要点。
语义特征及条件:X、Y往往是同类事物,形容词一般是表示性质的形容词,如:冷、高、聪明、能干、繁华、穷,等等。X、Y主要由名词或体词性短语充当,也可由动词、形容词或非体词性短语充当。日语中的A 和B在语义范畴上大致等同于汉语比较句的X和Y,但是又存在细微差别。汉日比较句式的分析,要考虑到具体的语义范畴、句法形式甚至语用功能。
2.3 汉日同义句式计算机识别流程图生成及有效性验证
基于1、2两个步骤的分析,设计计算机算法,生成汉日比较句式计算机识别流程图。按照共性规则穷尽式描述汉日语中比较句的句法构成。把具有相同语言现象的知识放入同一个流程步骤。比如格助词识别流程、用言识别流程、时体态识别流程等规则。特别注意对其中的一些特殊用法、特殊的语言现象进行识别流程描述。建立严谨的可计算的形式化模型或可统计的概率模型。
以比较句式为例,识别流程如下图:
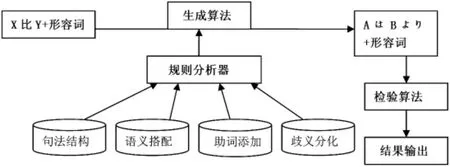
以上流程图变为翻译程序,用海量真实语料进行验证,与人工翻译和现有的在线机器翻译对比,验证同义句式识别流程图的效度。
3.研究策略及重点难点
3.1 研究思路和研究方法
传统的日汉语言学研究主要专注于个别问题或语言中的某个特殊现象的研究,面向语言信息处理的汉日同义句式对比研究应从计算语言学的角度出发,研究语言处理的普遍性和总体性的一般问题。将汉日同义句式的句法结构和语义特征形式化,使其具有可操作性。
作为该问题的研究方法,应采用从计算语言学、生成语法和语义学的角度,利用定量和定性的方法来分析代表性汉日同义句式的句法结构和语义特征。认知语言学中的构式语法理论以及配价语法理论和语义指向分析是也是可借鉴的主要方法。从实证分析的角度来看,研究策略可基于平行语料库,从《现代日语书面语均衡语料库》中抽出实例检验、评价检测计算机识别流程图的有效性并对存在的问题进行分析。
3.2 重点和难点
作为一种新视角的语言研究,面向语言信息处理的汉日同义句式对比研究应着力于以下几个方面:①计算机可识别的汉日同义句式的句法结构描述。在句法结构描述过程中,确定句子中每个词的词性,确定成分与成分之间的关系以便构成计算机能够识别的表示形式,即汉日同义句式句法结构形式化。②计算机可识别的汉日同义句式的语义特征分析。语义分析涉及的面较多,既缺乏统一的表示,也缺乏有效的处理机制。目前语义分析比较困难,有一些系统语义分析和句法分析同时进行,互相连接在一起。面向语言信息处理,将复杂的语义信息形式化成计算机能识别的语言。③汉日同义句式计算机识别流程图的生成。特别是流程图生成过程中,汉日两种语言的歧义消除问题更加复杂。面向基于句法的分析方式展开,辅以基于转换的分析方式生成汉日同义句式的计算机识别流程图。
4.结语
以汉日语言信息处理特别是汉日机器翻译中遇到的实际问题和需求为前提,深层对比汉日同义句式,对汉日同义句式的句法结构和语义特征分析,最终目标是生成行之有效的汉日常用
句式的计算机识别流程图。基于以上策略的研究既能为汉日语言信息处理特别是机器翻译提供高质量的语言学参考,又能解决部分汉日语言信息处理中的同义句句处理问题。
[1]张鹏等.从日语格语法表示生成汉语的难点分析,计算机应用研究,2002
(12):10.
[2]戴新宇等.从汉语格关系表示生成日语,中文信息处理,2003(6):17.
[3]杜伟,陈群秀.多策略汉日机器翻译系统中的核心技术研究,中文信息学报,2008(5):60.
[4]刘颖.计算语言学,清华大学出版社,2014,9:67-71.
[5]冯志伟.计算语言学基础,商务印书馆,2008,1:29.
H36
A
2095-7327(2016)-04-0163-02
课题项目:课题来源于常州工学院科研基金资助项目《面向语言信息处理的汉日同义句式对比研究》(项目编号YN1441)。
李哲(1981.11—),女,山东淄博人,讲师,硕士,研究方向为语言学及应用语言学。
