基于用户偏好与语言模型的个性化引文推荐
2016-05-04刘亚宁闫宏飞
刘亚宁,严 睿,闫宏飞
(北京大学 网络与信息系统研究所,北京 100871)
基于用户偏好与语言模型的个性化引文推荐
刘亚宁,严 睿,闫宏飞
(北京大学 网络与信息系统研究所,北京 100871)
根据引文上下文,自动为科研人员推荐备引用的论文列表具有很大的实用价值和研究意义。在科研人员写作时,一个为引用符自动推荐引文的系统,会为科研人员节省大量的时间。对于引文推荐问题,过去的工作均主要把注意力集中到基于内容的研究上。该文认为引文推荐,不能只根据内容进行通用推荐,还需要根据不同研究者的偏好进行个性化推荐。该文利用用户的发表及引用历史,结合语言模型,构建出一个个性化引文推荐模型——PCR模型。在结合用户引用倾向性与内容相关性后,与传统的基于内容的语言模型相比,PCR模型在recall@10上获得了71.01%的性能提升,在MAP上获得了70.23%的性能提升。
引文推荐;个性化
1 引言
我们将某个特定引用符附近,对所引文章进行描述的句子称为引文上下文。图1为引文上下文的一个示例。科研工作者都有花费大量时间找类似图中“[10,6]”具体指向哪篇论文的经历。找到需要被引用的文章经常需要花费大量的时间。其中非常矛盾的一点是,一个作者知道的论文越多,找到一种想法的来源就越显困难。论文的总量非常庞大,而且仍以极快的速度逐年递增。我们以计算机领域的论文为例,近年来,每年大约有16 000篇新的论文问世,而且在可预料的将来,论文数量仍然会以很快的速度持续增长。论文总量增大是必然的,论文增加的速度也在不断提高。例如2009年,计算机领域新产生的论文总量几乎是十年前的三倍[1]。论文领域的信息过载使得引文推荐工作不仅非常必要,而且很有挑战性。找到某个用户可能会引用的论文,会遇到很多问题,具有一定的难度。

图1 一个引文上下文示例
如果存在一个系统,可以针对每个引文符号推荐一个备引用的论文列表给科研人员,那么科研人员进行论文写作时将会省时省力:科研人员只需关心所要写作的内容,而寻找引用相关的事宜可以交给系统去做。有些计算机领域的研究人员已经意识到引文推荐的重要意义,并进行了一定量的研究,提出了解决引文推荐问题的若干算法。例如,将引文推荐问题看作信息检索问题,把引文上下文看作查询串,然后系统根据引文上下文这个“查询串”来搜索相应的论文并返回。这个过程和标准的搜索引擎进行检索的步骤是很类似的。在这个框架下,可以用很多方法来衡量一个引文上下文和一篇论文的相关性,例如语言模型[2]和翻译模型[3]。引文上下文也可以被用作锚文本,引文推荐系统通过对比当前的引文上下文和其他已知指向的引文上下文,来决定该引文上下文的指向。
总之,所有之前的方法都只对论文及引文上下文的内容进行分析。这些方法共同的缺点是,都没有考虑用户的引用偏好性。在现实中,不同的用户具有不同的阅读范围和不同的引用习惯,这导致对于相同的论文和引文上下文,不同的用户具有不同的引用倾向性。因此,引用推荐应该考虑到用户的偏好,进行个性化的推荐。在本文中,我们进行引文推荐时,不仅考虑了内容,还考虑了用户的偏好。我们将这种同时考虑了内容和用户偏好的引文推荐方法称为“个性化引文推荐”。
个性化引文推荐是个新工作,因此会存在很多挑战:
• 如何得到用户资料,并构建用户信息。
• 如何对用户信息进行建模。
• 如何将用户信息结合到已有的基于内容的方法中。
据我们了解,本文是第一篇提出用个性化的方法来解决引文推荐问题的论文。由于之前工作存在没有考虑用户倾向性这一统一问题,我们的工作可以结合到之前所有基于内容的工作中,并提高它们的效果。在本文中,我们将语言模型[2]结合进个性化引文推荐模型中,并使得推荐效果取得了显著提高。
2 相关工作
2.1 论文推荐
引文推荐首先是个论文推荐的任务,在论文推荐这个大方向上,已经有了不少的研究工作。D Blei等人[4]对网络上的信息进行分析,得到审稿人信息,为审稿人推荐合适的论文。K Chandrasekaran等人[5]利用用户在CiteSeer中的信息,为用户推荐论文进行阅读,他们将用户以及文档信息,用层次树结构进行表述,并用编辑距离描述用户和文档之间的相似度。B Shaparenko等人[6]利用语言模型和凸规划来进行论文推荐,他们利用余弦相似度对全文进行计算,从而推荐最相似的前k篇论文。S McNee等人[7]利用已经存在的研究者之间的引用关系、论文之间的引用关系等多种互联信息为用户推荐论文。K Sugiyamad等人[8]根据用户最近的研究兴趣,为用户推荐其可能感兴趣的论文,他们利用用户自己论文的信息以及其引用信息,构建用户的个人信息,并通过用户个人信息和其他文档信息之间的相似度,作为推荐的主要依据。D Zhou等人[9],利用作者、文献之间已有的多种关系,构建成图,以此为依据来为用户推荐论文。T Tang等人[10]在一个在线学习系统中,针对了不同用户的不同兴趣和不同知识水平,为用户推荐论文,并在用户学习之后,相应地更新了用户的知识水平信息。
2.2 引文推荐
引文推荐是近几年才兴起的研究热点。在引文推荐这个细化的方向上,目前的工作还不是很多,但是近几年,大家也逐渐注意到引文推荐的意义。Trevor Strohman等人[11]首次将整篇手稿作为系统输入,为整篇手稿推荐一个引文的列表。他们利用发表时间、整篇文档相似度、共同引用、共同作者等若干简单特征,将这些特征进行简单整合,得到一份手稿的推荐文献的列表。J Tang等人[12]利用Topic Model对引文上下文和其他文献间的相似度进行描述,进而进行相似论文推荐。Y Lu等人[3]利用翻译模型得到某个引文上下文“翻译”到某论文的概率,并根据这个概率值进行引文推荐。Q He等人[13],利用引用符号附近的引文上下文,作为所引文献的描述,以此描述作为推荐引文的主要依据。随后,Q He等人又对文献[13]中的工作进行了进一步扩展[14],他们不再需要引用符的位置信息,先进行引用位置预测,再进行引文预测。
3 问题定义
本文需要以下信息作为系统输入,并得到如下输出:
输入:1) 论文的元数据集合P,元数据需要包含论文的内容信息、作者信息、会议信息及引用信息; 2) 一些没有引用指向的引文上下文,及这些引文上下文的作者。
输出:根据输入,为每个引文上下文得到一个按照被引用概率排好序的论文列表。
为了方便起见,我们在此介绍后文中使用到的一些术语。
内容相关度(Content Relevance Degree,CRD),用来衡量一个引文上下文和一篇文章之间只考虑内容的相关程度。这个值可以通过前人提出的任意一种基于内容的模型计算得来,例如,常用的语言模型。
用户倾向度(User Tendency Degree,UTD),用来衡量一个用户引用一篇文章的倾向性,是本文介绍的重点。
引用可能度(Cite Possibility Degree,CPD),用来衡量一个引文上下文引用一篇论文的可能性,即进行推荐的最终衡量标准。
总之,引文推荐要解决的问题是,输入一个特定的引文上下文,输出一个根据计算得到的CPD排序的论文列表。
4 PCR模型
我们将本文的模型称为PCR(Personalized Citation Recommendation)模型。这个章节将对PCR模型进行详细的介绍。
首先,我们设想一个用户u引用一篇论文t的全过程。首先u必须知道t的存在,并对t感兴趣,然后阅读了它;之后,当u写作一篇论文p的时候,回忆到t是相关的;这时,用户u可能会写一段关于t的描述d并最终引用t。在写p之前,与其他没有被u阅读过的论文相比,实际上t已经有了一个更高的被引用的概率。
衡量d和t之间的值便是CRD,衡量u和t之间的值是UTD。在之前的工作中,往往CRD被用来当作CPD,而UTD却被忽视了,这很大程度上限制了推荐效果的进一步提升。实际上,用户首先对不同的论文具有不同UTD,然后根据这些UTD产生一个个性化的引文行为。换句话来说,在引文推荐工作中,UTD实际上可以被认为是CPD的先验。我们可以用式(1)来描述他们之间的关系。

(1)
4.1 UTD(用户倾向度 User Tendency Degree)
正如前文所述,对于每一个“论文-用户”对,我们需要计算UTD的值。首先,我们进行用户信息的构建。对于刚开始科研的初级研究人员,构建他们的用户信息是困难的,没有用户数据的有效支持,无法实现个性化,但是我们可以延用基于内容的模型进行引文推荐。对于从事科研工作多年的高级研究人员,由于他们已经发表过一些论文,这些已经发表的论文便是建立他们用户信息的关键,这正是PCR模型的着眼点。对于大部分从事研究工作若干年的研究人员来说,我们可以从他们的发表历史中得到一切我们希望得到的信息:
1) 所有用户发表的论文构成的集合;
2) 所有曾经同用户合作过的作者构成的集合;
3) 所有用户曾经引用过的作者构成的集合。
在拥有以上这些用户信息后,给定一个用户u和一篇目标论文t,我们如何衡量u和t之间的UTD?本文认为,造成用户对不同论文产生不同UTD的原因是,某些“推荐”和“扩展”关系。推荐来自三个级别的人:用户自己、用户的合作者和用户引用过的作者。这三个级别的人会用写作和引用两种方式为用户推荐论文,本文将这两种方式都认为成推荐行为。例如,合作者写作论文p或引用论文p一次,都认为成推荐论文p一次。在接受到三个级别人的推荐后,用户会对这些推荐进行扩展,除了会注意到论文本身,用户还会注意到论文的作者以及论文所发表的会议。根据三个级别人的推荐和三种扩展方式,我们可以得到3×3=9种可以用作UTD的先验特征(表1)。

表1 不同级别的推荐和不同方式的扩展
接下来对每个UTD进行详细的介绍,并列出每个UTD的计算公式。在后面的计算公式中,count(x,y)意为x推荐y的次数。其中x为某用户,y可能为论文、作者或是会议。count(x) 意为用户x推荐论文的总次数。count’(x) 意为用户x推荐作者的总次数。例如,如果x只推荐过一篇论文,这篇论文有三个作者,那么count(x)就是1,count’(x)就是3。变量u代表当前用户,t代表目标论文。A代表目标论文的作者集合,v代表t所发表在的会议或是期刊。Aco代表u合作过的人构成的集合,Aci代表u引用过的人构成的集合。
首先是用户自己的推荐行为,用户明显对自己的论文或是曾经引用过的论文更加熟悉,具有更强的引用倾向性。高倾向性不仅会影响用户对论文本身的引用行为,还会扩展到论文的作者和会议。由此可以得到UTD1_1到UTD1_3。
1)UTD1_1:用户自己推荐论文t的次数占用户总推荐次数的比例。这个特征考虑到两种用户行为:引用自己发表的论文、再次引用自己引用过的论文。首先,对于每位研究人员,其研究领域相对集中,即研究人员当前的工作同过去的工作往往具有较大的关联。因此,之前发表的论文或引用过的论文无疑有更大的概率与当前的作品相关;另一方面,用户对自己的工作或曾经引用的工作往往更加熟悉,这两点因素,带来了更高的引用倾向性。因此,给定一篇论文,用户本身的推荐行为是首先要考虑的特征。计算公式如式(2)所示。
(2)
2)UTD1_2:用户自己推荐论文t的作者集合A的次数占用户总推荐作者次数的比例。这个特征考虑到这样一种用户行为:引用自己引用过作者的论文。用户曾经引用过某个作者多次,则说明用户对该作者的工作较为熟悉和认可。那么用户会有很大的概率熟悉该作者的大部分甚至是全部的论文。这个特征将注意力扩展到目标论文的作者上,其公式如式(3)所示。
(3)
3)UTD1_3:用户自己推荐论文t的会议v的次数占用户总推荐次数的比例。这个特征考虑到一种用户习惯:阅读、引用自己熟悉会议的论文。用户引用某个会议的论文的次数越多或用户在某个会议发表的次数越多,则说明用户越熟悉这个会议。那么,这个会议的论文就越有可能被用户引用。该特征在会议的方向上进行扩展,计算公式如式(4)所示。
(4)
以上三个公式均考虑用户自身的行为,除了用户自身外,用户的合作者同样具有“推荐”力,并会对用户未来的引用行为产生影响。因此用户合作者发表或者引用的论文同样在我们的模型中起到了作用。以下三个先验特征均考虑用户合作者的推荐行为。
4)UTD2_1:用户的合作者集合Aco推荐论文t的次数占Aco总推荐次数的比例。这个特征考虑到这样的用户行为:熟悉合作者的工作、阅读合作者的论文。用户往往同合作者具有紧密的联系,这导致用户有很大的概率熟悉合作者的工作,并阅读其论文。因此,合作者推荐的论文,会对用户具有一定的影响力,UTD2_1用来衡量这个影响,公式如式(5)所示。
(5)
5)UTD2_2:用户的合作者集合Aco推荐论文t的作者A的次数占Aco总推荐作者次数的比例。在Aco对论文的推荐行为对用户产生影响之后,用户可能会将这影响进一步扩展到这些推荐论文的作者上。因此用户的合作者同样对论文作者具有推荐作用,公式如式(6)所示。
(6)
6)UTD2_3,用户的合作者集合Aco推荐论文t的会议v的次数占Aco推荐总次数的比例。类似UTD1_3,从用户的合作者的角度来看,同样可以进行会议维度的扩展。这个特征可以用式(7)进行描述。
(7)
除了用户本身和用户的合作者,用户的引用者同样具有向用户推荐的能力。如果一篇文章、某作者或某个会议被用户的引用者推荐多次,那么用户就会有较高的概率对其进行引用,接下来的三个先验特征从三种扩展方式(论文本身、论文的作者、论文所发表的会议),考虑用户引用过作者的行为,这些特征与UTD2_1到UTD2_3的计算方式是类似的。
7)UTD3_1,用户引用过的作者集合Aci推荐论文t的次数占其总推荐次数的比例。此特征仅考虑目标论文本身,计算方法如式(8)所示。
(8)
8)UTD3_2,用户引用过的作者集合Aci推荐论文t的作者集合A的次数占Aci推荐作者总次数的比例。此特征扩展到了作者维度,如式(9)所示。
(9)
9)UTD3_3,用户引用过的作者集合Aci推荐论文t所发表的会议v的次数占Aci总推荐次数的比例。此特征在会议维度进行扩展,如式(10)所示。
(10)
这九个特征实际上是CPD在九个维度上的先验,然后我们可以将这九个先验同前人提出模型所计算出来的CRD相乘,得到九个不同的CPD。将这九个CPD结合,便可以得到最终用来在给定引文上下文的情况下对候选论文集进行排序的标准。
4.2 将多个UTD与单个CRD结合
在本论文中,我们将语言模型用作CRD,并用作对比算法。本章节介绍如何将4.1得到的九个UTD先验与语言模型结合,得到最终结果。结合过程被分成以下两个步骤,用来解决结合过程中存在的三个问题。
4.2.1 填平取值鸿沟
在式(1)中,我们需要将UTD和CRD相乘。但是相乘过程有一个问题,UTD和CRD之间有一个取值的鸿沟,不同点之间UTD的差别和CRD的差别不在一个数量级上。所以如果将两个值直接相乘,其中某个值的影响会小到可以忽略。UTD的取值数量级主要取决于数据集的大小,CRD的取值数量级主要取决于引文上下文的长度。为了解决这个问题,我们引入一个收缩变量α,这样式(1)最终的表示更新为式(11)。
(11)
4.2.2 结合多个分数
在本文的模型中,有九个不同的先验,与CRD相乘之后,会有九个不同的分数。为了得到一个用来排序的最终分数,我们需要将这九个分数进行结合。
引用推荐实际上是引用预测问题, 我们可以将其看成一个分类问题。对于每一个引文上下文和论文对c,实际上只有两种关系:引用或没有引用。我们可以用九个不同的分数来代表c。所以,每个引文上下文和论文对实际上是一个九维的点。所有这些点中,有些是正例(引文上下文引用了这篇论文),有些是反例。这正是一个SVM分类器解决的标准问题。给定一个引文上下文,将其与所有候选论文进行组合,得到多个分类点,对这些点进行分类后,我们可以根据SVM得出的分为正例的置信度对这些论文进行排序。
在SVM的训练过程中,会遇到正例点和负例点数量不均衡的问题。一个引文上下文只引用一篇论文,其他所有论文与该引文上下文结合后都会构成负例点。所以训练过程中,负例点占了绝大多数,这非常影响SVM的性能。我们用以下方法解决了该问题:
1) 将所有正例点加入到训练集中,随机选取等量的负例点,加入到训练集中;
2) 训练一个SVM模型。这里我们利用C-Support向量分类器、径向基核函数;
3) 根据2) 中的模型得到一个结果;
4) 重复1)-3) 中的步骤n次,得到n个结果,然后计算平均结果作为最终分数。因为n为5时结果已稳定,再增大n对结果基本无影响,所以此处我们将n设定为5。
这样,考虑一个引文上下文和论文对时,对于这个引文上下文的每个作者,我们都可以得到一个分数。很多论文往往由多名作者合作而成,因此很多引文上下文有多个作者。对于有多个作者的引文上下文,相比于最大值或最小值,多个作者的平均值具有最好的效果。因此,我们取多个作者的平均值作为该引文上下文、论文对的最终分数。
到达这个步骤,对于每个引文上下文和论文对,我们都可以得到一个唯一的分数。这样,对于某个引文上下文,我们可以根据该分数对候选论文进行排序,然后输出,即为引文推荐问题的最终输出。
5 实验与结果
5.1 数据集
我们数据主要来自三个源:MAS(微软学术搜索引擎 Microsoft Academic Search) API、 MAS网站*http://academic.research.microsoft.com/、互联网中开放存取的论文资源。数据通过以下步骤获取:
1) 挑选出十个种子会议:ACL、CIKM、EMNLP、ICDE、ICDM、KDD、SIGIR、VLDB、WSDM、WWW。
2) 从MAS API中获得这十个会议从2000年至2012年的所有论文的元数据,元数据包括以下信息:论文在MAS中的ID,标题、摘要、发表时间、所发表的会议、作者、所引用论文的ID列表、可以获取论文的URL。最终,我们得到9 492篇论文的元数据。
3) 得到所有在2) 中获取的论文的所有引用论文元数据,最终我们得到55 823篇论文的元数据。
4) 根据所有的可获取论文的URL,我们共下载到20 171篇pdf格式的论文,其中共有4 537篇来自选中的十个种子会议。
5) 我们获取所有发出引用的源论文和目标论文都在数据集中的引用关系,并从中挑选出可以从MAS网站中得到引用上下文的引用关系。最终,我们得到来自4) 中4 537篇文章的73 236个引用关系。由于一篇文章会在多处引用另一篇文章,因此,一篇文章与另一篇文章的引用关系会出现多次。
我们挑选出个人信息相对完整的1 000个作者,对于每个作者,我们取出该作者的最后一篇论文,并从这篇论文中随机挑选出一个引文上下文,放入测试集。所有测试集中的引文上下文所指向的论文构成了推荐时的候选集。在完成这些步骤后,我们将剩下的所有数据作为特征提取和模型训练的数据集。
5.2 评分机制
对于每一个引文上下文,每个模型都可以得到一个排好序的论文列表。我们将这个引文上下文实际引用的论文作为唯一正确答案。那么以下标准可被用来衡量各个模型的优劣。
召回率(recall):由于对于每个引文上下文,只有一个正确答案。因此,此处召回率意为在前k个结果中将唯一的正确答案返回的引文上下文的比例,由于排序靠后的结果会被用户忽略,参考价值较小,因此,我们只需要关注k的值到10。
平均准确率(Mean Average Precision,MAP)如式(12)所示。
(12)
此处,R(di)是一个表明引文上下文是否引用di的布尔函数。
5.3 实验结果
我们用随机算法和一元语言模型作为对比方法,与结合一元语言模型的PCR模型作对比,表2为实验的最终结果,图1为前十项召回率的变化。

表2 不同模型的效果对比
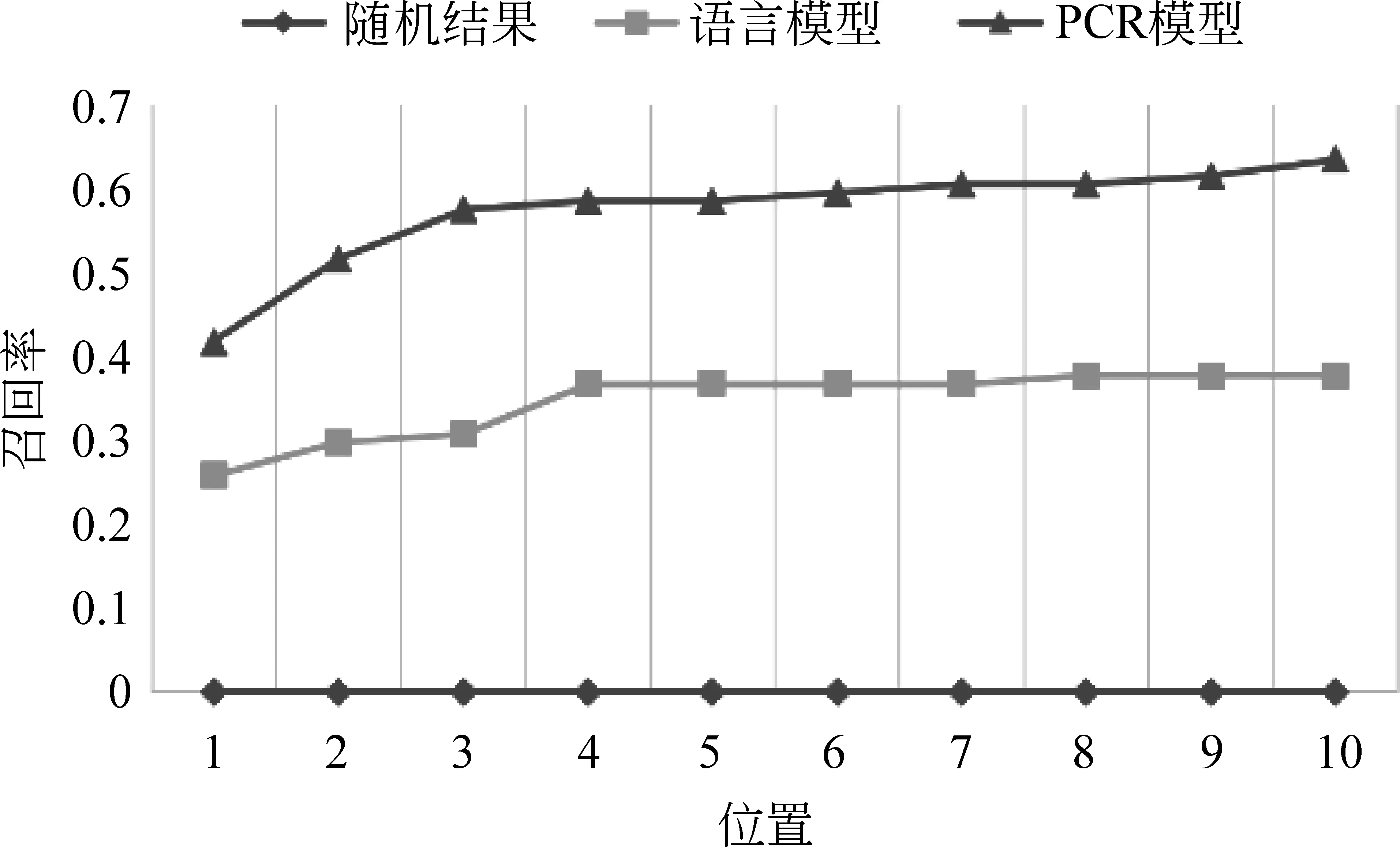
图1 前10个位置的召回率
从上面的结果我们可以看到,在加入用户的引用倾向性后,传统语言模型的效果在recall@10上获得了71.01%的性能提升,在MAP上获得了70.23%的性能提升。这是由于PCR模型不仅可以利用内容上的相关性,还可以利用用户的倾向性。一方面,PCR模型可以维持只利用内容信息就可以取得较好效果的引文上下文;另一方面,PCR模型可以改进仅仅利用内容信息不能得到较好效果的引文上下文。因此,PCR模型是有效的,可以大幅度地提高传统引文推荐模型的效果。
5.4 参数调优
在这个章节,我们对4.2.1中提到的参数α进行调优。数据规模为5.1中所描述,我们的引文上下文从MAS网站得到,删除掉停用词之后,平均的引文上下文的长度为13.4个单词。图2显示了参数α的值从0.1至0.9变化的过程中,PCR模型效果 的 变化。我们可以看到, 将α设为0.8可以取得最好的效果。

图2 对参数α进行调优
5.5 特征分析
在我们的模型中,共有3×3=9个特征,图3显示了依次去掉其中某个特征后模型的效果。图3中横坐标为x_y的项意为去掉UTDx_y后的效果。最后一项“无”意为所有特征均不去掉,即模型的最终结果。通过图3我们可以看到,当去掉UTD1_1时,效果的损失最大,表明用户针对目标论文本身的行为对模型具有最大的影响。

图3 对各个特征的分析
6 结论
我们提出了一种个性化的引文推荐模型——PCR模型。不同的用户对同样的论文具有不同的引用倾向性,我们的模型对此倾向性进行了量化,并与语言模型结合,取得了较大的效果提升。将来,我们会将协同过滤、图模型等其他方法应用到UTD(用户倾向性)中。并将考虑引用推荐问题中的其他因素,例如,论文的权威性及流行性。我们相信,随着工作的深入,引文推荐的效果可以被进一步提升。
[1]RYan,JTang,XLiu,etal.Citationcountprediction:Learningtoestimatefuturecitationsforliterature[C]//Proceedingsofthe20thACMinternationalconferenceoninformationandknowledgemanagement,ACM, 2011:1247-1252.
[2]CDManning,PRaghavan,HSchütze.Introductiontoinformationretrieval[M].CambridgeUniversityPressCambridge, 2008.
[3]YLu,JHe,DShan,etal.Recommendingcitationswithtranslationmodel[C]//Proceedingsofthe20thACMinternationalconferenceoninformationandknowledgemanagement,ACM, 2011:2017-2020.
[4]DMBlei,AYNg,MIJordan.Latentdirichletallocation[J].theJournalofMachineLearningResearch, 2003,3:993-1022.
[5]KChandrasekaran,SGauch,PLakkaraju,etal.Concept-baseddocumentrecommendationsforciteseerauthors[C]//ProceedingsoftheAdaptiveHypermediaandAdaptiveWeb-BasedSystems,Springer, 2008:83-92.
[6]BShaparenko,TJoachims.Identifyingtheoriginalcontributionofadocumentvialanguagemodeling[C]//ProceedingsoftheMachineLearningandKnowledgeDiscoveryinDatabases,Springer, 2009:350-365.
[7]SMMcNee,IAlbert,DCosley,etal.Ontherecommendingofcitationsforresearchpapers[C]//Proceedingsofthe2002ACMconferenceoncomputersupportedcooperativework,ACM, 2002: 116-125.
[8]KSugiyama,MYKan.Scholarlypaperrecommendationviauser’srecentresearchinterests[C]//Proceedingsofthe10thannualjointconferenceondigitallibraries,ACM, 2010:29-38.
[9]DZhou,SZhu,KYu,etal.Learningmultiplegraphsfordocumentrecommendations[C]//Proceedingsofthe19thinternationalconferenceonWorldWideWeb,ACM, 2008:141-150.
[10]TTang,GMcCalla.Beyondlearner’sinterest:personalizedpaperrecommendationbasedontheirpedagogicalfeaturesforane-learningsystem[C]//ProceedingsofthePRICAI2004:TrendsinArtificialIntelligence,Springer, 2004:301-310.
[11]TStrohman,WBCroft,DJensen.Recommendingcitationsforacademicpapers[C]//Proceedingsofthe30thannualinternationalACMSIGIRconferenceonresearchanddevelopmentininformationretrieval,ACM, 2007: 705-706.
[12]JTang,JZhang.Adiscriminativeapproachtotopic-basedcitationrecommendation[C]//ProceedingsoftheAdvancesinKnowledgeDiscoveryandDataMining,Springer, 2009: 572-579.
[13]QHe,JPei,DKifer,etal.Context-awarecitationrecommendation[C]//Proceedingsofthe19thinternationalconferenceonWorldWideWeb,ACM, 2010:421-430.
[14]QHe,DKifer,JPei,etal.Citationrecommendationwithoutauthorsupervision[C]//ProceedingsofthefourthACMinternationalconferenceonWebsearchanddatamining,ACM, 2011:755-764.
Personalized Citation Recommendation Based on User’s Preference and Language Model
LIU Ya’ning, YAN Rui, YAN Hongfei
(Institute of Network Computing and Information Systems, Peking University, Beijing 100871, China)
Automatic citation recommendation based on citation context is a highly valued research topic. The existing works all focus on the content based methods only. In this paper, we consider the citation recommendation as a content based analysis combined with personalization. Using users’ publication and citation history as the users’ profile and the language model, we propose a PCR (personalized citation recommendation) model. Experiment indicates 71.01% improvement of the performance in terms of recall@10 and 70.23% improvement in MAP compared with the traditional language model.
citation recommendation; personalization

刘亚宁(1988—),硕士,主要研究领域为搜索引擎与互联网信息挖掘。E⁃mail:lyn@net.pku.edu.cn严睿(1985—),博士,百度研究院资深研究员,主要研究领域为自然语言处理,数据挖掘,信息检索,与人工智能与社交网络。E⁃mail:yanrui02@baidu.com闫宏飞(1973—),副教授,博士,访问学者,主要研究领域为信息检索。E⁃mail:yhf1029@gmail.com
1003-0077(2016)02-0128-08
2013-09-15 定稿日期: 2014-01-20
教育部科技发展中心网络时代的科技论文快速共享专项研究资助课题(FSSP 2012 Grant 2012115);国家自然科学基金(61272340, 61073082)
TP
A
