一种融合地理位置信息的协同过滤推荐算法
2016-05-04王书鑫
鲁 骁 ,王书鑫 ,王 斌 ,鲁 凯
(1. 国家计算机网络与信息安全管理中心,北京 100029;2. 中国科学院大学,北京 100049;3. 中国科学院 信息工程研究所,北京 100093;4. University of California,Santa Cruz,USA)
一种融合地理位置信息的协同过滤推荐算法
鲁 骁1,王书鑫2,王 斌3,鲁 凯4
(1. 国家计算机网络与信息安全管理中心,北京 100029;2. 中国科学院大学,北京 100049;3. 中国科学院 信息工程研究所,北京 100093;4. University of California,Santa Cruz,USA)
目前,基于用户消费数据构建的推荐系统在电子商务领域发挥着越来越大的作用,而在这些数据中,商家本身具有的地理位置信息忠实地记录了用户的消费痕迹,能够有效反映出用户在地理位置维度上的个人偏好信息,从而对推荐系统具有非常重要的意义。现有工作一般只利用了用户对地点的评价以及地点之间的距离,无法反映出不同地点之间的关联关系,以及用户在不同地点中的偏好权重问题。该文从地理区域划分的角度出发,研究了用户在区域范围内的消费兴趣偏好,以及不同粒度级别的区域划分方法对推荐模型的影响,探索了在推荐过程中有效融合地域信息的方法,考虑了包括地区的全局性影响、用户对地区的偏好等,结合这些因素提出了融合地理位置信息的推荐模型LGE、LGN及LRSVD。通过在Yelp数据集上的实验表明,这些模型相比于传统的推荐算法能够有效提高预测效果。
推荐系统;协同过滤;地理位置信息;邻居模型;隐参数模型
1 引言
随着互联网和电子商务的发展,越来越多的商家开始在网上推广商品及服务,并涌现出了各种提供在线展示、预约、购买、团购等服务的网站,国内规模较大的如大众点评和口碑网,国外较有名的如Yelp等,这些网站在提供商家展示信息的同时,也为用户提供了信息反馈的渠道,从而产生了大量的用户对商家的消费数据,包括消费记录、评价打分、评论内容等信息,根据Yelp发布的2013年第二季度财报显示,截至2013年7月30日,Yelp网站中累积用户点评数量超过4 250万条,月独立用户达到1.08亿。如何有效利用这些数据来更好地为用户推荐商家,对工业界和学术界来说都是一个挑战。
在学术界,目前大量的研究集中在根据用户反馈进行推荐。具体到生活服务的推荐,情况又有所不同,由于商家都是线下实体店,真正的消费是在实体店完成的,其中有一个很重要的因素就是地理位置,在现实生活中,不同地区的商家,服务质量与其所在的位置有着很大的关系,而用户本身也有着地理位置属性,其消费活动一般会局限在部分地区范围,所以在根据线上用户的评论数据进行个性化推荐的同时,必须对地理位置进行着重考虑。以此为出发点,本文提出融合了地理位置信息的推荐模型,并在Recsys 2013公布的Yelp数据集上进行了实验,验证了该方法的有效性。
本文后续内容安排如下:第二节主要介绍常用的推荐算法;第三节阐述融合地理位置信息的推荐模型,主要包括考虑地区偏置的全局影响模型LGE,以地理位置信息来改进相似度计算的全局邻居模型LGN,以及融合了前述工作的隐参数模型LRSVD;第四节展示在Yelp数据集中的实验结果,并对结果进行分析;第五节是结论及未来工作。
2 相关工作
自从Tapestry系统[1]最早提出协同过滤的概念之后,协同过滤方法越来越受到研究者和商业系统的重视,较有名的推荐系统应用包括GroupLens、MovieLens、Netflix等,从2007年开始,ACM Recsys会议每年都会组织一次关于推荐算法的讨论,以促进推荐算法的发展。
经典的协同过滤推荐算法可以分为基于记忆的方法和基于模型的方法。基于记忆的方法[2-4],是利用用户对物品的打分来计算用户或物品之间的相似度,并根据相似的用户或物品来进行推荐,其中经典的方法如user-based KNN[2], item-based KNN[3-4]等,这类方法实现起来比较简单,但也有许多限制,受数据稀疏性影响较大[5]。为了克服这个问题,研究者提出了基于模型的方法,通过机器学习来训练模型中的参数,发掘数据之间的关联关系,常见的包括邻居模型[6-7]、贝叶斯网络[8-9]、聚类模型[10-11]、因子分解模型[12]等,基于用户和物品偏好的RSVD模型[13]得到了普遍应用。与此同时,融合上下文的推荐方法[14-18]也越来越受到重视,推荐系统中的上下文信息包括了时间因素、人口特征、社会特征、环境因素、地理位置、物品类别等,利用这些属性能够挖掘出更多的有用信息,改善数据稀疏性的问题。Li[14]将上下文信息作为用户特征,Oku[15]通过SVM模型来做上下文敏感的预测。
另外,在特定的应用场景中,尤其是在线下生活服务推荐中[19-25],地理位置作为一种重要的上下文信息,受到了很多研究者的重视。Zheng[19]提出了LBSN (Location-Based Social Network)的概念,用于表示人们基于真实地理位置而发展出来的一种新型社交关系结构。目前推荐系统对地理位置信息的利用,主要体现在两个方面。
一种是基于共同地点,以用户的消费地点为对象,通过统计不同用户之间的共同消费地点来计算用户之间的相似度,如Mao[20]设计了基于用户共同活动地点的好友相似度评估方法,并提出了基于好友的协同过滤模型,以用户消费的地点为对象,来衡量用户之间的相似度,在此工作基础上,进一步提出融合了用户喜好、社交影响力以及地域影响力等因素的模型[21],实现了基于概率的用户兴趣地点推荐。Sabar[22]根据用户的实时上下文信息,包括用户过去常去的地点以及当前的活动地点为用户提供更贴近生活的推荐服务。这种方法是以用户-地点为数据对进行推荐,其缺点在于没有考虑地点之间的关联关系。
另一种是基于距离,根据地理位置来计算用户消费地点之间的距离,并将其加入到模型因子中来调整推荐模型,如Park[23]基于用户使用的移动设备中的信息,包括上下文信息、时间、天气、GPS数据等,对待推荐项的地理位置按照相对距离的远近划分为Near、Mid、Far三类,利用贝叶斯网络构建了用户的个人偏好模型,从而为用户推荐感兴趣的餐厅。Cao[24]通过分析用户的GPS数据,构建用户-地点的双层网络,并利用随机游走算法来为地点进行排序,从而抽取出有显著意义的地点。Kuo[25]将商户的地理位置作为排序因子之一,通过让用户选择相对距离的重要性,并结合用户的长期兴趣和短期兴趣,构建了用户的周边服务推荐系统。
以距离作为因素来构建推荐模型,能够有效地将用户在不同地点的消费偏好关联起来,但其计算方法主要根据GPS数据中的绝对距离,而忽略了地理位置天然具有区域概念的事实。而且这两种方法都只基于用户在地点中的消费打分,而由于单点的消费记录无法反映出用户对地点的消费次数,从而忽略了用户在不同地点中由于消费次数的不同应当具有不同的偏好权重。只有以区域为单位进行消费次数的统计,才能有效利用权重这个因素。
根据上述不足,本文主要从地理位置的区域性出发,首先考虑区域性偏好对用户潜在喜好的影响,在此基础上,提出了以地理区域为单位的全局邻居模型,在这个过程中提出了带权重的基于地理位置的用户相似度计算方法,并解决了整合不同层次区域划分方法的问题,最后,本文还将地域因素加入到隐参数模型中,并融合了前两步的工作以进一步提供算法的推荐效果。
3 本文工作
本文研究发现,在消费者对商家反馈信息中,有着显著的地域效应,主要体现在以下三个方面。
1) 不同的地域之间消费情况有明显区别,会对其范围内的商家产生全局性的影响,甚至同一品牌的商家在不同地区的分店可能会有不同的平均得分,这些地区之间的区别具有现实原因,例如经济情况、交通情况等;
2) 用户的消费行为一般会呈现出地域较为集中的趋势,说明用户在选择商家进行消费时,地域也是一个潜在的偏好因素;
3) 对于地理位置信息本身,按照其范围大小有粒度上的区别,如省、市、街区等,不同粒度的地理信息将对推荐产生不同的影响,应当分层考虑。
3.1 地理位置的全局性影响
数据集中商家的数量、商家的平均消费数量以及用户的评分反馈都能从特定方面反映出当前地区的消费情况,而不同地域之间的消费情况具有很大的差异,如图1展示了Yelp数据集中各城市的消费数量以及平均得分情况。

图1 Yelp数据集中各城市的消费数量及平均得分差异
图中横坐标表示消费数量由高到低的各个城市,左侧纵坐标表示在每个城市中的消费数量,右侧纵坐标表示在各城市中所有消费评价的平均分,柱状图由高到低展示了各城市之间消费数量的差异,可以看出大部分消费集中在少量几个城市中。折线图显示了各城市的平均得分,可以看出根据地区的不同,其总体平均分是有明显区别的。
本文在后续工作中用b这一项来代表全局范围内的地区偏置,其中表示商家i所在的地区,对于每个商家i而言,其所在地区是固定的,即商家与地区是1∶1的映射关系,所以对于每一个商家,都有唯一的地区偏置项。
3.2 用户对地理位置的偏好
本文从用户的评价信息与商家信息中统计了用户消费的覆盖范围,根据商家所在的城市,统计出用户消费的城市分布,可以看出每个用户都有较为常去的城市,说明用户对城市本身具有一种偏好。接下来,本文对商家的详细地址进行了分析,抽取出其所在的街区邮编号码,由于城市内部都以街区进行区域划分,所以能够用邮编号码来表示商家的街区分布,从而能够统计出用户消费的街区分布。 图2、图3所示是分别从城市和街区两个粒度上统计的Yelp用户消费记录分布。

图2 用户消费城市分布统计图

图3 用户消费街区分布统计图
图2和图3的横坐标表示各个用户曾经去消费过的地区数量,纵坐标表示各个用户的消费数量,图中的箱线图直观地展现了用户消费地区数量的分布情况,从图2中可以看出,用户的消费地点都比较集中,大多数用户的消费都集中分布在几个城市中。将位置信息的精度放缩到街区范围内,从图3中也可以看到类似的情况,用户消费的街区分布也较为集中,大多数用户的消费覆盖街区不超过十个,从而呈现出用户对地点的一种偏好,这个现象比较符合真实情况,日常生活中,用户的消费地点和其所在的地理位置息息相关,比如用户倾向于在家庭居住地或工作地点附近进行消费。
对于用户,每个用户在不同的地区会有不同的消费记录,从而形成了他们在这些地区中的个性化偏好,本文从这点出发,考虑用户消费习惯在地区上的体现,提出用户对每个地域都有偏置,通过与全局偏好组合,可以将用户的偏置用式(1)进行表示。
(1)
其中,bu表示用户u的基本偏置,表示商家i所在的地区,bu()表示用户对地区的偏置,具体计算方法如式(2)所示。
(2)
其中,αu,表示用户对地区的偏好,ωu,用来调节其权重大小。
由于用户在不同城市中的消费记录并不均衡,用户的大部分消费都分布在几个城市中,较为集中,所以本文在处理用户的地理位置偏好时,将根据其在每个地区的消费频次,进行权重调节,消费次数较少的城市,用户对该城市偏好的权重相对较小,权重的计算如式(3)所示。
(3)
其中,Cu,表示用户在地区的消费次数,Su表示用户的全部消费次数。
根据以上推导,从而得到用户的地理位置偏好表示如式(4)所示。
(4)
该公式意味着,用户消费较少的城市,其个性化偏好较弱,而在消费较多的城市,其权重较大,具有更明显的个性化偏好。一个极端的例子就是,用户在某个城市没有打分记录,则根据上述公式可计算出用户对该城市的偏好为0,从而只有全局偏好,而没有地理位置偏好。
3.3 基于地理位置信息的全局影响模型
在前面两小节的工作基础上,考虑到商家的地区偏置项以及用户对地理位置的偏好,本文以全局影响模型[24]为原型,提出了基于地理位置的全局影响模型(Location-basedGlobalEffects),以下简称为LGE,模型的具体计算方法如式(5)所示。

(5)

3.4 基于地理位置信息的全局邻居模型
本文考虑根据用户的消费地区信息来计算用户之间的相似度,并将前文中的地区全局影响、用户对地理位置的偏置融合到全局邻居模型[6-7,26]中,提出了基于地理位置的全局邻居模型(Location-based Global Neighborhood),简称为LGN模型,以解决两个问题:第一是对用户-地理位置建模,在地理区域的维度空间上来表示用户,而且需要考虑到用户在各地区上的偏好权重不同;其次,地理位置具有明显的层级特征,需要充分考虑不同级别的地区表示之间的融合问题。
3.4.1 带权重的地理位置特征表示方法
以地理位置为特征来表示用户,则用户地理位置特征向量可以表示为式(6)。
(6)

以此便可以将用户表示为地理区域上的向量。
随后,本文考虑了用户对区域的消费偏好,认为用户对其消费区域的偏好将通过其消费记录反映出来,所以在表示用户的地理位置特征向量时,为每一维特征加上不同的权重wi,以表示其对不同区域的偏好,如式(7)所示。
(7)
其中,权重wu,i的计算方法参考文档的tf-idf计算方法,此处假设以地理区域为词项,每个用户为文档,则可以将用户-地理区域模型转换为文档的词袋模型来进行表示,词频tf代表用户在区域i的消费次数,文档频率df代表所有在区域i消费过的用户数量,从而可以根据tf-idf的公式得到用户的地理区域权重计算公式,如式(8)所示。
(8)
其中,tfu,i表示用户u在区域i的消费次数,dfi表示所有在区域i消费过的用户数量,N表示用户总数。
3.4.2 考虑地理位置层级关系的相似度计算方法
在将用户表示为地理区域的向量空间后,可以对用户进行相似度计算,从而完成相似用户的选择。本文选用余弦相似度来进行计算,如式(9)所示。
(9)
在这个过程中,本文发现地理区域的选择面临很强的粒度选择问题。具体而言,地理位置具有明确的级别划分的概念,不同级别能够代表不同范围的地区,如中国的地区行政级别划分方法为:省/市/区/县,而美国地区行政级别划分方法为:州/市/区,不同粒度的划分方法将对区域的用户消费统计产生不同的影响。
从这点出发,本文在研究地理位置对推荐算法的影响时,也对其粒度级别进行了考虑,将不同的地区粒度融合在一起进行计算。参考上一小节,在每一个区域级别上建立独立的用户-区域向量模型,向量空间的维度为该层级别上地理区域的划分集合,例如在省级粒度上,就以省作为维度,这样对于有K层级别的地理位置而言,就相应建立了K个用户-地理区域的向量空间,每个向量空间进行独立的向量相似度计算,之后通过线性插值的方法进行不同级别的相似度计算结果融合。
本文采用双层级别划分的地理位置表示方法,考虑城市和街区两个粒度级别,融合方法如式(10)所示。
(10)
其中,每一层级别Li上的相似度表示为simLi,η作为调节系数来管理各个层次之间的权重比例。在计算出相似度之后,对于用户u,将和其关联的用户的相似度按照降序进行排列,取出前K个用户作为邻居用户集合NK(u)。
3.4.3 LGN模型
基于上述工作,本文提出基于地理位置的全局邻居模型,如式(11)所示。
(11)
其中,PK(i)=P(i)∩NK(u)表示从训练集中对商家i评分的用户集合中,选出与用户u相似的Top-K邻居用户集合,AK(i)=A(i)∩NK(u)表示从全部数据集中对商家i评分的用户集合中,选出与用户u相似的Top-K邻居用户集合,bv,i为用户v对商家i的基准预测评分,这里采用本文提出的LGE模型来进行计算[参见式(5)],ωuv为偏移量,表示v对u的可预测程度,Cuo为模型参数。
3.5 基于地理位置信息的隐参数模型
在前面两节中,本文分别提出了对地理位置敏感的LGE和LGN模型,在此工作基础上,本文改进了隐参数模型RSVD[13], 加入了地理偏置、用户对地理位置的偏置以及改进的最近邻计算方法,并融合了隐参数模型,提出了LRSVD模型,从而缓解数据稀疏带来的影响。
(12)

4 实验和结论
4.1 实验数据
本文使用Recsys 2013提供的Yelp消费评论数据,该数据集收集了Yelp网站中位于美国亚利桑那州各个城市的商家信息以及消费者打分记录。数据集主要包括两个部分:训练集、测试集。数据详细信息如表1所示。

表1 Yelp商家评分数据集
其中,用户对商家的评分值范围为1~5。通过表1可以看出,整个数据集包含了超过20万条用户评分数据,训练集中只有一条评分数据的用户数量为22 829,接近总用户数的一半,通过计算得到训练集的稀疏度约为99.96%,而测试集中新出现的用户数为5 315,占测试集用户数的44.5%左右,新出现的商家数为1 205,约占测试集商家数的21.6%。
本文使用的地理位置信息包括城市名称、邮编号两种,邮编号用来代表街区的信息,具有唯一性。另外,由于数据集中商家的地理位置信息存在一些噪音,例如单词拼写错误、城市中带有其他位置信息,导致数据格式不一致,所以在从地址中抽取出城市信息时,采用了编辑距离算法[27]来修正错误的城市名称拼写。
另外,为了便于对模型参数进行拟合训练,本文依据训练集和测试集中用户数与商家数的比例,对原始训练集数据进行了切分,得到五份新的训练集和验证集,表2所示是各个子数据集中用户和商家的数据统计。

表2 新的训练集与验证集
在切分数据集的过程中,本文不仅保持训练集与验证集中用户-项的比例,而且尽量维持验证集中冷启动用户的比例,以便与原始数据集保持一致。
4.2 评价指标
本文采用RMSE(均方误差)作为实验的评价指标,计算公式如式(13)所示。
(13)
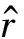
RMSE放大了预测值与真实值之间的绝对误差,从而加大了对预测不准的评分数据的惩罚,因而对系统的评测更为苛刻一些。
4.3 模型参数训练
本文通过平方损失函数来评估算法的误差,计算方法如式(14)所示。
(14)
对以上损失函数,可以采用最小二乘法或梯度下降来求解参数,以LRSVD为例,优化目标函数的计算公式为式(15)。
(15)
其中,公式中第二项用来防止过拟合。
本文通过NelderMead方法[28]来训练步长参数和正则化参数λ,实验过程中设定NelderMead的迭代次数为50次,可以得到各个模型的最优RMSE值。
4.4 实验结果及分析
本文对前面章节中提出的LGE、LGN和LRSVD三个模型进行了实验,为了便于比较模型之间的效果差异,本文主要选择了以下几个模型做对比:
•GE:全局影响模型(GlobalEffects)
•GN:全局邻居模型(GlobalNeighborhood)
•RSVD:正则化奇异值分解模型(RegularizedSingularValueDecomposition)
•FCF[3]:基于好友地理位置的协同过滤(Friend-basedCollaborativeFiltering)
其中,前三个模型是基本对照组,不具有地理位置因素,FCF是在经典KNN推荐模型的基础上加入地理位置的改进模型。
首先,本文比较了GN与LGN在取不同K值情况下的表现,GE和LGE与K值无关,作为基本对照,各模型的表现如图4所示。

图4 改进的KNN模型随着K取值变化的效果比较
图4中横坐标表示选取的相似邻居好友的个数,纵坐标表示各个模型的RMSE值,从图4可以看出,LGE模型比GE模型有较大的效果提升,说明将地区偏置和用户偏置融入到模型中确实能够提高模型的效果。随着K取值的不断增加,三个KNN模型的效果都越来越好,其中FCF和LGN表现都优于GN,从而证明在模型中融入地理位置因素后能够有效降低模型的RMSE值,而将地理位置及权重融入到最近邻计算中的LGN模型,相对于GN和FCF能够更加显著地降低预测误差。另外,在本文实验过程中发现,由于Yelp数据集比较稀疏,当K值超过50之后,效果提升不再明显。
随后,本文取K=50,对LRSVD进行了效果分析,图5所示是LRSVD与RSVD两个模型的实验结果。

图5 隐参数模型随着隐变量数量变化的效果比较
图5中横坐标表示隐参数的数量,纵坐标表示各个模型的RMSE值,其中GE模型仅提供基础预测误差作为参考,可以看出由于数据稀疏导致原始RSVD的效果并不理想,甚至比基本的全局影响模型还要差,而LRSVD由于综合了地区偏差、用户的地区偏差,以及基于地域的最近邻等因素,大幅度降低了预测误差,达到了很好的效果。而且随着隐变量数量(factorsize)的增加,两个模型的RMSE值都逐渐减小,而相比于传统的RSVD模型,考虑了地理位置因素的LRSVD的效果有更明显的提升。最后,本文取K=50,f=100,并与GE、GN、RSVD、FCF等模型进行效果对比,并以FCF为参考做了威斯康辛显著性检验,结果如表3所示。
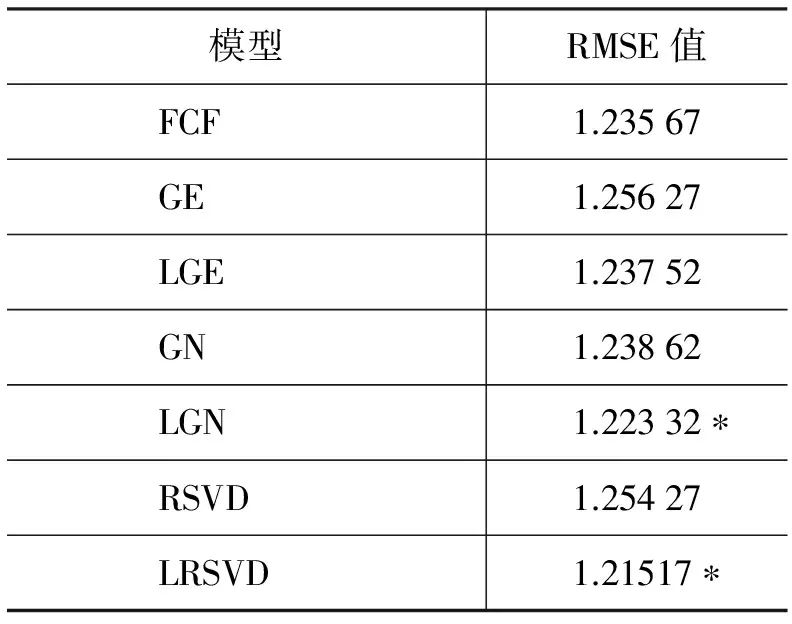
表3 与其他模型的效果比较
从表3可以看出,本文提出的LGE、LGN和LRSVD相对于原始的GE、GN和RSVD模型都有明显的效果提升,而且与经典的基于好友地理位置的FCF模型相比而言,LGN和LRSVD的效果也有显著的提升,由此可以充分说明本文提出的融合地理位置信息的方法能够有效利用地理位置因素来提高算法的推荐效果。
另外,本文还与Recsys Challenge 2013公布的其他队伍的结果进行了对比,如表4所示。

表4 与Recsys Challenge 2013其他队伍的效果比较
Recsys Challenge 2013在比赛中给出的benchmark是根据计算所有用户的平均打分值得到的,值为1.27,很容易被超越,最后各个比赛队伍公开的最好效果达到1.21,本文的单个模型最好效果能够达到1.215 17,与第二名的结果接近,另外,本文将LRSVD与LGE、LGN、RSVD和biasMF等其他几种模型的结果进行融合,最后效果能够达到1.037 23,充分说明了本文的模型不仅能够有效提升推荐效果,而且对其他模型的结果也具有补充增强作用。
5 总结和展望
本文主要介绍了一种基于地理位置信息进行协同过滤的推荐算法,该算法有效利用了物品的地理位置信息,并分析了位置信息对用户评价产生的影响,充分考虑了包括地区的全局性影响、用户对地区的偏好、通过用户消费的地点记录来改善最近邻计算方法,以及在隐参数模型中加入地区信息等各个方面,结合这些因素提出了融合地理位置信息的推荐模型。实验结果验证了模型的有效性。
未来工作主要包括以下几个方面:研究商家的行业类别信息与地理位置信息之间潜在的关联关系;考虑地理位置信息所携带的其他知识数据,将地理位置信息与其他的上下文信息进行有效结合,并用统一的模型来表示。
[1] Sarwar B, Karypis G, Konstan J, et al. Item-based collaborative filtering recommendation algorithms[C]//Proceedings of the 10th international conference on World Wide Web. ACM, 2001: 285-295.
[2] Resnick P, Iacovou N, Suchak M, et al. GroupLens: an open architecture for collaborative filtering of netnews[C]//Proceedings of the 1994 ACM conference on computer supported cooperative work. ACM, 1994: 175-186.
[3] Linden G, Smith B, York J. Amazon. com recommendations: Item-to-item collaborative filtering[J]. Internet Computing, IEEE, 2003, 7(1): 76-80.
[4] Linden G D, Jacobi J A, Benson E A. Collaborative recommendations using item-to-item similarity mappings: U.S. Patent 6,266,649[P]. 2001-7-24.
[5] Su X, Khoshgoftaar T M. A survey of collaborative filtering techniques[J]. Advances in artificial intelligence, 2009: 4.
[6] Koren Y. Factorization meets the neighborhood: a multifaceted collaborative filtering model[C]//Proceedings of the 14th ACM SIGKDD international conference on knowledge discovery and data mining. ACM, 2008: 426-434.
[7] Koren Y. Factor in the neighbors: Scalable and accurate collaborative filtering[J]. ACM Transactions on Knowledge Discovery from Data (TKDD), 2010, 4(1): 1.
[8] Miyahara K, Pazzani M J. Collaborative filtering with the simple Bayesian classifier[M].PRICAI 2000 Topics in Artificial Intelligence. Springer Berlin Heidelberg, 2000: 679-689.
[9] Su X, Khoshgoftaar T M. Collaborative filtering for multi-class data using belief nets algorithms[C]//Proceedings of the Tools with Artificial Intelligence, 2006. ICTAI’06. 18th IEEE International Conference on. IEEE, 2006: 497-504.
[10] Ungar L H, Foster D P. Clustering methods for collaborative filtering[C]//Proceedings of the AAAI Workshop on Recommendation Systems. 1998, 1:114-129.
[11] 王明文,陶红亮,熊小勇. 双向聚类迭代的协同过滤推荐算法[J]. 中文信息学报, 2008, 22(4):61-65.
[12] Hofmann T. Latent semantic models for collaborative filtering[J]. ACM Transactions on Information Systems (TOIS), 2004, 22(1): 89-115.
[13] Paterek A. Improving regularized singular value decomposition for collaborative filtering[C]//Proceedings of KDD cup and workshop. 2007: 5-8.
[14] Li Y, Nie J, Zhang Y, et al. Contextual recommendation based on text mining[C]//Proceedings of the 23rd International Conference on Computational Linguistics: Posters. Association for Computational Linguistics, 2010: 692-700.
[15] Oku K, Nakajima S, Miyazaki J, et al. Context-aware SVM for context-dependent information recommendation[C]//Proceedings of the Mobile Data Management, 2006. MDM 2006. 7th International Conference on. IEEE, 2006: 109-109.
[16] Rendle S, Gantner Z, Freudenthaler C, et al. Fast context-aware recommendations with factorization machines[C]//Proceedings of the 34th International ACM SIGIR conference on Research and Development in Information Retrieval. ACM, 2011: 635-644.
[17] Koren Y. Collaborative filtering with temporal dynamics[J]. Communications of the ACM, 2010, 53(4): 89-97.
[18] Panniello U, Tuzhilin A, Gorgoglione M, et al. Experimental comparison of pre-vs. post-filtering approaches in context-aware recommender systems[C]//Proceedings of the 3rd ACM Conference on Recommender Systems. ACM, 2009: 265-268.
[19] Y Zheng, X Zhou. Computing with spatial trajectories[M]. Springer Science & Business Media, 2011.
[20] Ye Mao, Peifeng Yin, Wang-Chien Lee. Location recommendation for location-based social networks[C]//Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems. ACM, 2010: 458-461.
[21] Ye M, Yin P, Lee W C, et al. Exploiting geographical influence for collaborative point-of-interest recommendation[C]//Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2011: 325-334.
[22] Ebrahimi S, Villegas N M, Müller H A, et al. SmarterDeals: a context-aware deal recommendation system based on the smartercontext engine[C]//Proceedings of the 2012 Conference of the Center for Advanced Studies on Collaborative Research. IBM Corp., 2012: 116-130.
[23] Park M H, Hong J H, Cho S B. Location-based recommendationsystem using bayesian user’s preference model in mobile devices[M]. Ubiquitous Intelligence and Computing. Springer Berlin Heidelberg, 2007.
[24] Cao X, Cong G, Jensen C S. Mining significant semantic locations from GPS data[C]//Proceedings of the VLDB Endowment, 2010, 3(1-2): 1009-1020.
[25] Kuo M H, Chen L C, Liang C W. Building and evaluating a location-based service recommendation system with a preference adjustment mechanism[J]. Expert Systems with Applications, 2009, 36(2): 3543-3554.
[26] Bell R M, Koren Y. Scalable collaborative filtering with jointly derived neighborhood interpolation weights[C]//Proceedings of the Data Mining, ICDM 2007. Seventh IEEE International Conference on. IEEE, 2007: 43-52.
[27] Christopher D. Manning,Prabhakar Raghavan,Hinrich Schutze,王斌(译). 信息检索导论[M]. 北京:人民邮电出版社,2010.
[28] Lagarias J C, Reeds J A, Wright M H, et al. Convergence properties of the Nelder—Mead simplex method in low dimensions[J]. SIAM Journal on Optimization, 1998, 9(1): 112-147.
A Collaborative Filtering Algorithm Combing Location Information
LU Xiao1,WANG Shuxin2,WANG Bin3,LU Kai4
(1. National Computer Network and Information Security Administration Center, Beijing 100029,China;2. University of Chinese Academy of Sciences,Beijing 100049,China;3. Institute of Information Engineering, Chinese Academy of Sciences,Beijing 100093, China; 4. University of California,Santa Cruz,USA)
Recommendation system based on users’ consumption data is playing an increasingly large application value in e-commerce, And in these data, businesses’ location information which can effectively reflect the user’s personal geographical preference, would make an important significance on recommender system. Existing work generally use only users’ review data as well as the distance between locations, which cannot reflect the relationships between different locations, not to mention that user preferences in different locations should has different weight. This paper proceed from the perspective of geographical area, and study the users’ preferences within the area, as well as the impact of different area partition methods on recommend models. Then we explore to incorporate recommender systems with geographical information effectively, including the location’s global effects and user’s regional preferences, proposing recommendation models, such as LGE, LGN and LRSVD. Experimental evaluation on Yelp dataset demonstrates that our models can effectively improve the prediction results comparing to the traditional methods.
recommender systems; collaborative filtering; location information; neighborhood model; latent factor model

鲁骁(1986—),博士,工程师,主要研究领域为社交网络、推荐系统、机器学习。E⁃mail:luxiao@cert.org.cn王书鑫(1985—),博士,主要研究领域为机器学习、数量化投资。E⁃mail:sxwang@szse.cn王斌(1972—),博士,研究员,主要研究领域为信息检索与自然语言处理。E⁃mail:wangbin@iie.ac.cn
1003-0077(2016)02-0064-10
2013-10-30 定稿日期: 2014-03-03
国家自然科学基金青年基金(61402466)
TP391
A
