基于释义扩展的术语归类研究
2016-05-03吕学强肖诗斌
贺 刚,吕学强,肖诗斌,王 凡
(1. 北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101; 2. 新华网络股份有限公司,北京 100101)
基于释义扩展的术语归类研究
贺 刚1,吕学强1,肖诗斌1,王 凡2
(1. 北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101; 2. 新华网络股份有限公司,北京 100101)
术语归类研究对领域本体构建与特定领域词表扩展有十分重要的意义。该文针对中国知网概念知识元库中存在的术语归类错误问题,研究如何提高术语归类正确率。经分析发现术语具有释义文本短、所包含的能够区分术语类别的特征词较少的特点。该文提出一种基于释义扩展的术语归类方法,该方法引入了释义扩展思想,以搜索引擎为工具,获取术语相关的互联网知识,抽取查询结果的锚文本和摘要文本等内容扩展术语释义文本;采用向量距离算法计算术语释义文本特征向量与类中心向量之间的距离,实现对术语的归类。实验得到的术语归类总体正确率为73.32%,与未经释义扩展得到的术语归类正确率相比,提高了近10%。实验结果表明,该方法对提高术语归类正确率是有效的。
术语归类;释义扩展;向量距离;类中心向量
1 引言
术语用来正确标记生产技术、科学、艺术、社会生活等各个专门领域中的事物、现象、特性、关系和过程。术语可以是词,也可以是词组。术语库是由术语及其相关属性构成的数据库,也称术语数据库。术语库可以是面向概念的、翻译的、特定领域的及面向其他特殊的用途。根据术语用途的不同,术语库中除术语词条、术语定义外,可以包含其他不同的属性,但是为了术语描述的层次性和整个术语库结构的清晰性,在设计术语库、收录术语词条之前一般要对所限定范围的术语作适当的分类[1-2]。术语归类研究对于构建本体和扩展特定领域词表和词典有非常重要的意义。
在对中国知网概念知识元数据库中的术语进行定义辨析时,发现有一部分术语存在归类错误的问题,比如术语“三教九流”被归到“军事”类。这对基于中国知网概念知识元数据库中的术语研究会造成严重影响,如术语抽取及本体构建等研究。
本文研究如何对该知识元库中的术语进行重新归类,以提高术语归类的正确率。着重探讨了互联网知识对术语释义文本扩展的有效性,以及向量距离分类算法在术语归类中的应用,并对分类结果进行了评价。
2 相关研究
术语归类是文本挖掘研究领域的一个重要任务。近年来,国内外研究人员对文本分类问题进行了深入的研究,并基于不同方法来构造文本分类器,例如,KNN、Naïve Bayes、Maximum Entropy、SVM、Decision Tree、NNet、LLSF等[3-7]。
Henri Avancini[8]等探讨了一种利用术语分类来自动扩充特定领域词典的方法,先人工标注一部分术语,用来训练分类器,然后利用迭代的方式对术语进行训练分类。这种分类方式的优点是只需要人工标注一小部分术语语料,构造小规模的训练集,但是每次迭代的结果都需要耗费人力去校对。昝红英[1]等对信息科学与技术领域的术语分类进行了研究,并结合现有的相关国际和国家标准,提出建立一种信息科学与技术领域的术语分类体系,此体系在术语库的构建中发挥了重要的规范作用。然而,这种术语分类体系的构建,更倾向于建立一种分类的规范,对术语自动归类研究较少。赖娟[9]提出了一种对中文词语进行自动分类的蚁群算法,该方法建立在大规模语料文本统计和计算的基础之上,得到词语的一元和二元信息,然后利用蚁群算法进行词语分类。这种分类方法是对一般词语进行分类,由于术语有较强的专业性,用在术语归类中未必适用。此外,该方法需要处理大规模背景语料,费时费力。
上述术语分类相关的研究取得了一定的效果,但是仍不能满足实际的需求。本文提出的术语归类方法将互联网作为术语释义扩展的来源知识库。互联网是一个不断更新的动态知识库,查询术语返回的结果可以有效扩展术语释义,克服术语释义不完整的不足。
3 术语特征表示
3.1 术语来源
本文要归类研究的术语来自中国知网概念知识元数据库(以下简称知识元库),知识元库是一个收录概念知识元并提供知识元检索服务的概念知识库。所谓知识元*http://www.baike.com/wiki/知识元&prd=button_doc_jinru.,是指不能再分割的具有完备知识表达的知识单位。从类型上分,包括概念知识元、事实知识元和数值型知识元等。
知识元库收录了多个学科的大量术语概念知识元,同时给出了解析术语概念知识元的文本,称作术语释义。一个术语知识元有一个或多个释义,这里把术语所有的释义统称为术语释义文本。知识元库对其收录的每个术语知识元都给定了类别标识,但是这些类别标识存在一定程度的归类错误,这将影响以知识元库为基础数据的学术研究。因此,提高术语归类的正确率,对于构建本体和扩展特定领域词表和词典有非常重要的意义。
通过对知识元库中术语概念知识元的观察,发现术语概念知识元主要有以下两个特点。
第一,术语有较强的专业性,是一些独立词,不能再分割。
第二,术语释义文本普遍较短,有些术语的释义在工具书及学术文献中均未给出。
图1为该知识元数据库中收录的术语“柳氏民居”,仅有两条释义且释义较短。

图1 术语“柳氏民居”的释义
3.2 术语释义扩展
知识元库中一些术语的释义文本较短,存在释义不完整的情况,在术语文本表示时容易造成数据稀疏问题。为了减少数据稀疏对术语归类造成的影响,以提高术语归类的正确率,需要对术语释义文本进行扩展,以丰富其信息表示。
互联网是一个完备的知识库,并且由于互联网的动态性,决定了其知识库是在不断地更新完善。因此,借助互联网知识扩展术语释义文本,可以很好地解决数据稀疏问题。比较直观的方法是把术语作为查询词串提交给搜索引擎,获取一些与查询词串相关的网页,如图2为借助GoogleTM查询术语“柳氏民居”返回的部分查询结果。从互联网中返回的网页信息能给术语提供较丰富的上下文信息。

图2 通过Google查询术语“柳氏民居”返回的部分结果
搜索引擎查询术语返回的检索结果是与术语最相关的信息,且按照某种策略进行了相关度排序。通常查询返回的结果列表中第一页信息与查询串更相关, 即排名靠前的结果项与搜索请求的匹配程度最高。搜索引擎提供的精确匹配查询功能可保证返回的信息与术语更相关,此功能提高了术语的查准率。因此,仅保留查询结果中排名top-K位的结果项对术语释义进行扩展更具有实际意义。
对于一个术语的查询结果,需要考虑从这些网页中抽取哪些内容来表示该术语。主要考虑了两类特征:锚文本和摘要文本。锚文本是对一个链接所指向的目标页面的文字描述,由于锚文本比较短,通常将其与摘要文本合并到一起。摘要文本是原始网页文本内容经过压缩之后的一段短文本,能正确表示原始网页内容的主题,并且摘要中术语出现的频次较高。摘要可以为术语提供相关的文本上下文信息。
对于知识元库中的任意术语T,都给出了其原始释义。术语T的原始释义可能有一个或多个,也可能未给出释义。将术语T的原始释义文本表示为集合ST,如式(1)所示。
(1)

为了扩展术语释义,把术语T作为查询词串提交给某一搜索引擎,从互联网这个知识库中查询与术语T相关的网页,抽取top-K查询结果中的锚文本与对应的摘要文本,得到锚文本集合Anchor={a1,a2,...,aK}与摘要文本集合Abstract={b1,b2,...,bK},将锚文本ai与对应的摘要文本bi(1≤i≤K)连接,得到术语的扩展释义集合SeT,即

(2)
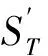
(3)
3.3 术语向量构建
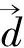
经上述释义扩展方法得到的术语释义文本在经过分词、去除停用词等预处理后,得到释义文本的特征集。该特征集中包含大量词汇,如果把这些词都作为特征,将造成一系列问题。首先是向量维数过大,会带来运算速度慢、运算开销过大等问题。其次有一部分词是对分类没有意义的,反而可能会对分类造成影响。为了确保不影响术语归类的精度,简化计算,提高程序运行速度,需要进行特征选择,以达到特征降维的目的,选取对释义文本区分度较大的词语,作为释义文本的特征项。词语权重计算采用TF-IDF算法,其计算公式如式(4)所示[11]。
(4)
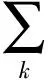
采用上述方法,计算出释义文本集中每一个词语的权重。这里认为特征词的权重大小能够反映其在术语释义文本中的重要性,把术语释义文本的所有候选特征词按权重降序排列,选取权重最大的M个特征词作为最终的特征项,构造术语释义文本的特征向量。
4 术语归类方法
4.1 归类方法及原理
中国知网概念知识元数据库中收录的术语是一些带类别标签的术语,只是术语的分类存在一定的误分。本文采用向量距离分类算法[12]对这些术语重新归类,基于知识元库中现有的术语类别,借助算术平均的思想,为每一类术语生成代表该类别的中心向量。任意术语的释义文本向量与各类中心向量进行距离相似度比对,将术语归类到相似度最大的那个类别中。算法描述如下:
(5)
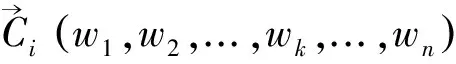
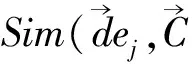
计算每类中心向量与新术语释义文本特征向量的相似度,将新术语释义文本d归类到相似度最大的类别中。
4.2 相似度计算
(6)

则任意一个术语所属的类别可由式(7)所示。
(7)
5 实验结果与分析
实验采用的术语语料来自中国知网(CNKI)概念知识元数据库,其中有25个不同类别共计56 600个术语及其相应的释义文本。为了对术语进行释义扩展,将术语名词作为一个查询词串提交到谷歌(GoogleTM)搜索引擎,获取搜索引擎精确匹配返回的检索结果中排名top-K位结果的锚文本与摘要文本,扩充该术语的释义信息。
实验中设置需要扩展的术语释义文本行数的阈值λ为5,特征词选择M值为候选特征词集合中权重最大的前70%,搜索引擎检索结果项K值取10。
5.1 评测指标
实验归类结果评测采用人工校对的方式,主要参考标准为现有的维基百科、互动百科和百度百科等权威中文百科网站对术语分类的情况。在评价术语归类结果时,主要采用正确率(Precision,P)、召回率(Recall,R)和F值(F-measure,F)等评价指标。
每类术语归类采用以下方法评价:
(8)
(9)
(10)
上述评价指标反映了分类器对某一类术语归类效果的判断,但是不能反映对整体样本的判定能力。因此,要对术语归类的总体正确率进行评价。
总体术语归类的正确率,则采用以下方法计算,如式(11)所示。
(11)
5.2 结果分析
本实验中文分词采用ICTCLAS[14],考虑到术语的专业性,在对术语释义文本分词时,术语可能会被分词器切分开,将所有待归类术语名词作为用户词典导入ICTCLAS。
实验过程中,为了验证本文术语释义扩展方法的有效性,与未经释义扩展而直接利用术语原始释义进行归类的方法进行了对比,实验结果如表1所示。把从知识元库中获取的25个类别的全部术语作为待归类对象,利用上述算法进行归类实验,然后采用抽样的方法从经过归类后的25个不同类别中随机抽出七类,并从这七类中随机抽取了3 700个术语进行评测。

表1 基于不同方法的术语归类的对比结果
从表1的实验结果可以看出,本文方法得到的每一类术语归类正确率明显要高于未经释义扩展得到的归类正确率。由本文方法得到的宗教类的正确率达到100%,通过分析发现,此类术语的类别特征比较明显,相较于其他类别更容易判定。
通过表2可以看出,本文基于术语进行释义扩展方法得到的术语归类总体正确率达到73.32%,比未经释义扩展得到的术语归类正确率提高近10个百分点。本文方法借助搜索引擎返回的互联网信息扩展术语的释义文本,有效丰富了术语的信息表示。因此,从归类效果可以看出,本文的方法对提高术语归类正确率是有效的。
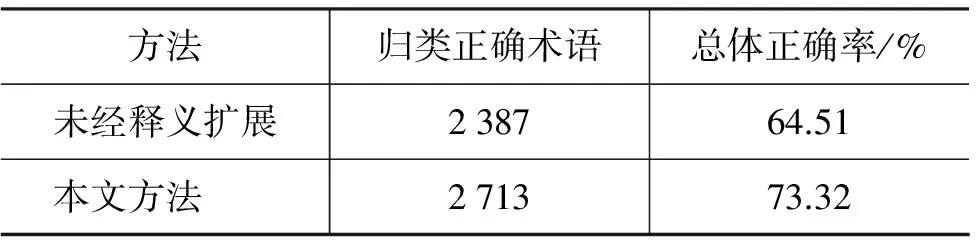
表2 总体术语归类的对比实验结果
6 结束语
本文阐述了中国知网概念知识元数据库中术语的特点,分析了术语释义文本较短给术语归类造成的影响。而后提出一种基于释义扩展的术语归类方法,引入了释义扩展思想,借助搜索引擎获取术语相关的互联网信息,对术语释义文本进行扩展,然后采用简单向量距离算法对术语进行归类实验。通过对知识元库中术语进行实验可以看出,本文方法提高了术语归类的正确率,为基于知识元库中术语的进一步研究奠定了基础;借助互联网知识对术语进行释义扩展的方法能丰富术语的语义信息,对加深理解术语有重要意义。本文方法仍有改进之处,错误归类的术语对中心向量的构建造成一定的影响,然而,从实验的效果来看目前采用的方法是有效果的。此外,本文待归类的术语必须带有预定义的类别标识,这是本文研究的重要前提。
下一步工作的重点是研究如何减小归类错误术语对术语中心向量构建的影响。此外,将进一步探讨搜索引擎top-K查询结果中K值的选取对实验结果的影响。
[1] 昝红英,胡俊峰,穗志方,等. 信息科学与技术领域中的术语分类研究[C]//亚太术语会议. 2002: 191-197.
[2] 张榕,宋柔. 术语定义提取研究[J]. 术语标准化与信息技术, 2006,(01): 29-32.
[3]JingnianChen,HoukuanHuang,ShengfengTian,etal.FeatureselectionfortextclassificationwithNaïveBayes[J].ExpertSystemswithApplications.2009,(36): 5432-5435.
[4]FabrizioSebastiani.MachineLearninginAutomatedTextCategorization[J].ACMComputingSurveys, 2002,34(1): 1-47.
[5] 王雅玡. 基于朴素贝叶斯和BP神经网络的中文文本分类问题研究[D]. 云南:云南师范大学硕士学位论文,2008.
[6] 郝秀兰. 文本分类技术与应用研究[D]. 上海:复旦大学博士学位论文,2008.
[7]YejunWu,DouglasW.Oard.Bilingualtopicaspectclassificationwithafewtrainingexamples[C]//Proceedingsofthe31stannualinternationalACMSIGIRconferenceonResearchanddevelopmentininformationretrieval,Singapore, 2008: 20-24.
[8]HAvancini,ALavelli,BMagnini,etal.Expandingdomain-specificlexiconsbytermcategorization[C]//ProceedingsofSAC-03, 18thACMSymposiumonAppliedComputing,Melbourne,US,ACMPress,NewYork,US. 2003: 793-797.
[9] 赖娟. 基于改进的蚁群算法中文词语自动分类技术研究[J]. 科技通报,2012,(2):152-154.
[10] 郭庆琳,李艳梅,唐琦. 基于VSM的文本相似度计算的研究[J]. 计算机应用研究,2008,(11):3256-3258.
[11] 施聪莺,徐朝军,杨晓江.TFIDF算法研究综述[J]. 计算机应用,2009,(B06): 167-170.
[12] 庞剑锋,卜东波,白硕. 基于向量空间模型的文本自动分类系统的研究与实现[J]. 计算机应用研究,2001,09: 23-26.
[13] 郭茂. 基于类中心向量的文本分类模型研究与实现[J]. 情报杂志,2010,7:44-49.
[14]Hua-PingZhang,Hong-KuiYu,De-YiXiong,etal.HHMM-basedChineselexicalanalyzerICTCLAS[C]//ProceedingsofthesecondSIGHANworkshoponChineselanguageprocessing,July11-12, 2003: 184-187.
Categorization of Terms Based on Paraphrase Expansion
HE Gang1, LV Xueqiang1, XIAO Shibin1, WANG Fan2
(1. Beijing Key Laboratory of Internet Culture and Digital Dissemination Research, Beijing Information Science and Technology University, Beijing 100101, China; 2. Xinhua Net Co.,Ltd, Beijing 100101, China)
Term categorization plays an important role in domain ontology construction and domain vocabulary collection. To deal with the misclassified terms in the conceptual knowledge element library of CNKI, this paper proposes a paraphrase-expanded method to categorize terms. This approach introduces the idea of paraphrase expansion as well as the term-related knowledge obtained via web search to reconstruct the term vectors. The final cauterization is decided by the vector distance between a term vector and the class central vectors. The overall precision reaches 73.32%, indicating nearly 10% relative improvement compared with the original method without expansion.
term categorization; paraphrase expansion; vector distance; class central vector

贺刚(1987—),硕士研究生,主要研究领域为自然语言处理。E⁃mail:hegang_126@126.com吕学强(1970—),博士,教授,主要研究领域为中文信息处理、多媒体信息处理。E⁃mail:lxq@bistu.edu.cn肖诗斌(1966—),硕士,高级工程师,主要研究领域为信息检索、文本挖掘。E⁃mail:Xiao.shibin@trs.com.cn
1003-0077(2016)01-0204-06
2013-07-03 定稿日期: 2014-03-20
国家自然科学基金(61171159,61271304);北京市教委科技发展计划重点项目暨北京市自然科学基金B类重点项目(KZ201311232037);国家科技支撑计划课题(2011BAH11B03)
TP391
A
