基于弱分类器调整的多分类Adaboost算法
2016-04-20杨新武北京工业大学计算机学院北京100124
杨新武 马 壮 袁 顺(北京工业大学计算机学院 北京 100124)
基于弱分类器调整的多分类Adaboost算法
杨新武*马壮袁顺
(北京工业大学计算机学院北京100124)
摘要:Adaboost.M1算法要求每个弱分类器的正确率大于1/2,但在多分类问题中寻找这样的弱分类器较为困难。有学者提出了多类指数损失函数的逐步添加模型(SAMME),把弱分类器的正确率要求降低到大于1/k(k为类别数),降低了寻找弱分类器的难度。由于SAMME算法无法保证弱分类器的有效性,从而并不能保证最终强分类器正确率的提升。为此,该文通过图示法及数学方法分析了多分类Adaboost算法的原理,进而提出一种新的既可以降低弱分类器的要求,又可以确保弱分类器有效性的多分类方法。在UCI数据集上的对比实验表明,该文提出的算法的结果要好于SAMME算法,并达到了不弱于Adaboost.M1算法的效果。
关键词:多类分类器;多类指数损失函数的逐步添加模型;Adaboost.M1
1 引言
Adaboost算法的思想起源于VALIANT提出的PAC(Probably Approximately Correct)学习模型[1]。SCHAPIRE提出了Boosting[2]算法,Boosting[3-5]算法是一种通过结合多个弱分类器提高最终分类准确率的方法。基于Boosting算法,1995年,FREUND提出的Boost-by-majority算法[3],在某种意义上说是最佳的Boosting算法,而1997年FREUND和SCHAPIRE提出的Adaboost算法[6]是更面向于实际应用的方法。Boosting方法一般只适用于二分类问题,在实际应用中,大多数的应用场景会多于两个类别,像检测[7],人脸识别,物体和动作检测[8]等。
简单地把Boosting算法从两类扩展到多类存在许多问题,比如在两类问题中,对弱分类器的要求只要比随机猜测好就能被接受,也就是正确率大于1/2。而在多分类问题中,尤其是在类别数较大的情况下,随机猜测正确率较低,很难满足正确率大于1/2的要求。像决策树这种简单的弱分类器就很不容易满足对弱分类器的要求。1996年FREUND和SCHAPIRE也通过结合这些弱分类器,提高了最终的分类准确率[9]。文献[10]是ALLWEIN等人在2000年提出的,其把多分类问题化简为多个二分类问题也是现在较为常见的思路[11]。
基于AdaBoost的多类别分类方法主要有AdaBoost.M1[9],AdaBoost.M2[9]和AdaBoost.MH[12]。1996年FREUND和SCHAPIRE提出了Adaboost.M1[9]算法,它比较直接地把Adaboost算法泛化到多类问题上,但其对弱分类器的要求较高,要求弱分类器正确率大于1/2[13]。但在多分类问题中,由于随机猜测的正确率只有1/k,与两类AdaBoost方法相比,多分类AdaBoost.M1算法难以找到正确率大于1/2的弱分类器,可能导致在实际应用中得到的弱分类器个数不足,无法保证得到足够好的强分类器。为此,学者针对这一问题提出了许多改进算法,通常把多类问题化简为多个二分类问题,再进行分类决策。AdaBoost.M2,AdaBoost.MH等算法多采用这种思想解决多类问题[13]。
AdaBoost.M2算法在AdaBoost.M1的基础上,采用伪损失代替弱分类器的正确率来衡量弱分类器。其对弱分类器的分类精度要求稍有降低,只要伪损失稍比随机猜测好就可以。并且,由于使用伪损失,使每一次迭代的弱分类器不仅注重错分样本,同时还关注到了难以辨别的标签类上。但是,伪损失函数要比错分率计算复杂得多,因此AdaBoost.M2算法比较复杂,计算成本和时间也相应增加[9]。
1999年SCHAPIRE和SINGER提出AdaBoost.MH[12]算法。AdaBoost.MH把每个样本的分类,转化为k个1和0的标签,是一种直接将k类问题转化为k个两类问题的算法。由于转化为两类问题,这样弱分类器的精度要求可以较容易地得到满足,多类分类效果改善明显[12]。但该算法的主要不足之处就是计算过程繁琐,计算量大,尤其在类别数k较大时[14]。
2009年ZHU等人[15]提出了一个新的从两类问题扩展到多类问题的方法SAMME(Stagewise Additive Modeling using a Multi-class Exponential loss function)。它将Adaboost算法直接扩展到了多类问题上。SAMME算法把弱分类器正确率的要求从1/2降低到1/k,也就是说在多分类问题中,弱分类器的性能只要比随机猜测好就可以被接受。因此,SAMME算法从概念上来说是简单的、容易实现的,且能找到足够多的弱分类器。但SAMME算法对于弱分类器的要求不足,导致算法并不能够保证弱分类器能增强最终强分类器的准确率。
我们在研究中也发现,在很多UCI数据库上的多分类问题中,SAMME算法的效果并不如Adaboost.M1算法好。究其原因,在于SAMME算法虽然通过放宽弱分类器错误率的限制,但其没有关注到弱分类器的质量,不能保证每次被弱分类器正确分类的训练样本权值一定大于其错分到其它任一类别的训练样本权值,从而不能确保最终强分类器正确率的提升。为此,我们分析了多分类Adaboost算法的原理。通过原理分析,使我们可以使用更简单的弱分类器达到比较好的效果。针对Adaboost.M1算法,弱分类器正确率要求过高的问题,SAMME算法并没有按照把多类问题化简为多个二分类问题的思路,而是直接对AdaBoost算法进行泛化,不将多类问题转化为多个两类问题,直接求解多类分类问题,可大大减小计算量。本文提出的SAMME.R(Stagewise Additive Modeling using a Multi-class Exponential loss function with Resample)算法是针对SAMME算法的不足,提出的改进算法。其解决多分类问题的思路与AdaBoost.M1算法,SAMME算法较为相似,与AdaBoost.M2算法及AdaBoost.MH等算法在解决多分类问题上的思路不同。在原理分析及实验时,本文也将针对AdaBoost.M1算法及SAMME算法进行分析。
本文中,我们首先分析了多分类Adaboost算法的原理,在SAMME算法的基础上提出了SAMME.R算法,该方法既可以把对弱分类器正确率的要求仅为1/k,从而保证更容易获得弱分类器,又通过重采样保证了弱分类器的质量,从而提高强分类器效果。本文对SAMME.R算法的有效性进行了证明。在基准UCI数据集[16]上的对比实验表明,本文提出的SAMME.R算法的结果要好于SAMME算法,并取得了不弱于Adaboost.M1算法的效果。
本文第2节首先对SAMME算法及其与Adaboost.M1算法的区别进行了简要介绍;在第3节中,分析了Adaboost.M1及SAMME算法的原理,并详细介绍了本文提出的SAMME.R算法;第4节中,利用数学对SAMME.R算法进行了有效性分析;对比实验的结果放在了第5节;最后一节是结论。
2 SAMME
对于多类问题,由于随机猜测的正确率只有1/k,所以通常难以找到错误率小于1/2的弱分类器,以致无法得到足够数量的弱分类器,从而不能集成得到足够好的强分类器。SAMME[15]算法针对此问题,对Adaboost算法的多类扩展做出了修改。SAMME算法通过改变权值分配策略at的计算方法,令,从而有别于Adab o ost.M1算法中的权值分配策略at=。SAMME算法与AdaBoost.M1算法看上去比较相似,其不同点在于at的计算公式中多加了ln(k -1)项。当k为2时(也就是两类问题),其权重分配策略与AdaBoost算法相同。在k(k>2)类别分类问题中,由于加上ln(k -1)项,SAMME算法中的弱分类器正确率不再要求大于1/2,而是大于1/k即可,这使得SAMME算法在解决多分类问题时的适用范围更广泛。
文献[15]在文献[17]中提出的统计学观点的基础上,从理论上对ln(k -1)添加项的合理性进行了统计分析证明。首先证明SAMME算法是符合向前梯度添加模型的,然后证明符合向前梯度添加模型的算法可以逼近最小化指数损失函数,而最小化指数损失函数可使分类决策函数满足贝叶斯分类规则,从而证明SAMME算法是满足贝叶斯分类规则的最优分类器。
但在我们的研究中发现,在很多基准UCI数据库上的多分类问题中,SAMME算法的效果并不如Adaboost.M1算法。在AdaBoost.M1算法中,要求弱分类器的正确率要大于1/2,也就是分类正确的样本的概率,大于分到其他各类样本的概率和,使得其分类正确的概率,一定大于分到其他各类的概率,根据大数定理,随着弱分类器个数的增多,最终强分类器的正确率趋近于1。而在SAMME算法中,把对弱分类器正确率的要求从大于1/2,降低到大于1/k,降低了寻找弱分类器的难度。但由于其弱分类器的正确率仅要求大于1/k,并不能保证每类训练样本分到本类的概率一定大于错分到其他各类的概率。若存在每类训练样本分到某一错误类的概率大于其分到本类的概率时,经过集成投票后,最终强分类器的对该类训练样本的分类会偏向于错分类别中概率较大的那一类,导致无法确保最终强分类器正确率的提升。
如果针对多分类问题,既可以把对弱分类器正确率的要求降低到大于1/k,又可以通过限制生成上述的低质弱分类器,就能确保得到足够强的强分类器。
3 SAMME.R
为了清楚地了解SAMME算法的不足,我们借助文献[18]的分析对此进行说明。
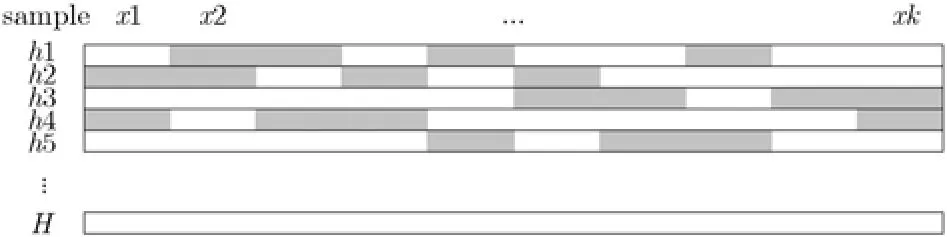
图1 Adaboost.M1分类图
在Adaboost.M1算法中,如图1所示,在弱分类器训练中,我们把分类正确的样本标注为白色,分类错误的样本标为灰色。则每行的白色部分表示该弱分类器本次迭代中正确分类的部分,当每行白色部分比例大于一半时,多次迭代训练得到多个弱分类器后,由于每次分类的正确率大于1/2,图中白色部分比灰色部分多,对于每个样本来说,必然会有很多样本白色部分所占比例大于一半。如果不同弱分类器正确分类的样本独立,且分布均匀,则随着迭代次数的增加,即训练样本中越来越多的样本被超过一半的弱分类器分类正确。无穷次迭代后,分类正确的标签一定比分到其他类的标签的数量多,保证最终的强分类器正确。
在SAMME算法中,只要求正确率大于1/k。如图2所示,同之前图示相同,每一行的白色部分代表弱分类器对训练集分类正确的样本。该弱分类器可以满足SAMME算法正确率大于1/k的条件,但对于某个属于n类的样本,弱分类器将其分至某一不为n类的概率大于其分到n类的概率的情况经常出现,无穷次迭代后,强分类器最终会导致分类结果错误。

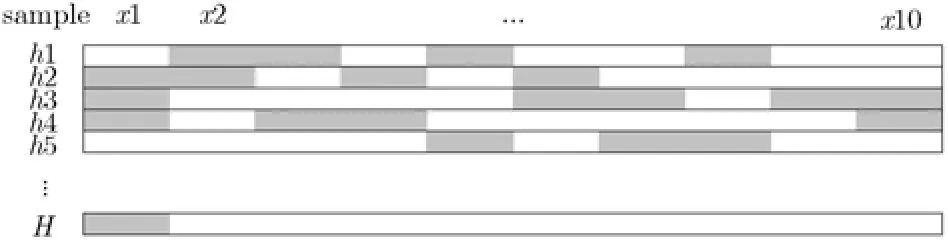
图2 SAMME分类图
与Adaboost.M1算法不同,SAMME算法中,由于每次分类的正确率为,而不是,T次训练得到T个弱分类器后,不能保证样本分类正确的标签的权值一定大于分到其他任意一类的标签的权值,以至于不能保证最终分类效果的提升。而在Adaboost.M1算法中,弱分类器的正确率为,则分到正确类的样本权值一定大于分到其他各类的样本的权值之和,从而其分类正确样本权值一定大于分到其他任意一类的权值,保证了当T趋近于无穷时,最终分类结果的正确率趋近于1。
要保证在最后的综合投票中分类正确的样本所占的数量是最多的,仅要求弱分类器的正确率大于1/k是不够的,需要添加一定的限制条件。为此,本文提出在训练弱分类器时,判断该弱分类器的结果,在所有同属一类的样本的分类中,正确分类的样本的权值和是否比分到其他任意一类的权值和大。如果满足该条件则继续进行权值调整和下一次迭代。如果不满足,则可能是由于训练出的弱分类器不够好,可以在权值不变的情况下重新训练弱分类器,然后再次判断新的弱分类器是否满足上边所说的条件,如果满足进入下一次调整,不满足则重新训练弱分类器。经过此条件的限制,当T趋近于无穷时,分类正确的标签一定比分到其他各类的标签的数量多,最终分类器的错误率趋近于0。
在此基础上,本文提出了SAMME.R算法,该算法流程如下:
(a)循环计算各类中,分到各类样本的权值和:
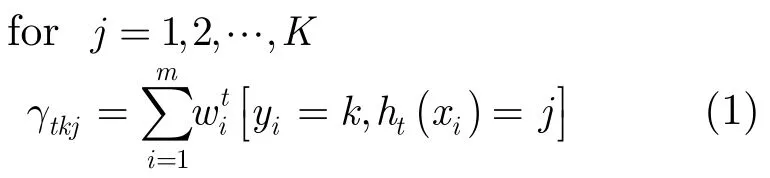
(b)判断各类中分类正确的样本权值和是否大于分到其他各类的样本的权值和。若满足,则进行下一次循环。若不满足,则返回步骤2重新开始计算。
(4)计算ht的伪错误率:
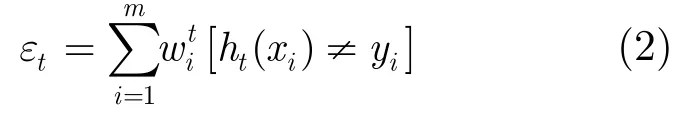
(5)置
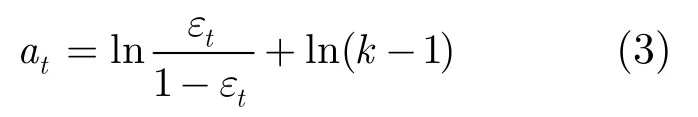
(6)计算新的权重向量:
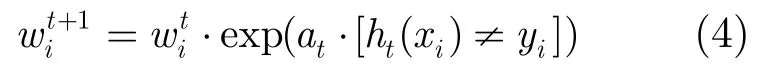
步骤3最终强分类器为
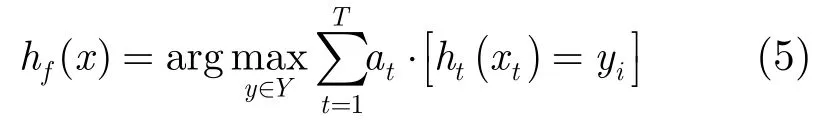
本文对SAMME算法的改进,并未影响其满足的向前梯度添加模型。因此,SAMME.R算法仍然满足贝叶斯最佳分类规则。
4 SAMME.R算法数学分析
上文中以一个简单的例子介绍了本文提出的SAMME.R算法,在本节中,将针对多分类问题,对Adaboost.M1,SAMME,SAMME.R算法的有效性进行数学分析。
Adaboost.M1算法中,在k分类问题中,若采用简单投票法构造强分类器,即H(x)=。则对任意训练集St,输出一个最大错误率为的分类器,相互独立选取不同的St得到不同的。定义随机变量序列Zt:
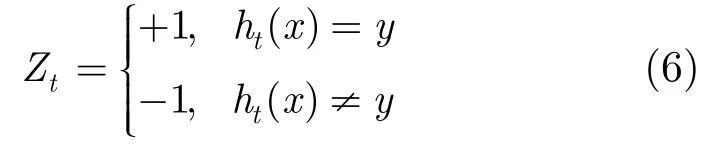
则Zt是一个均值为,方差为的随机变量。记

由于训练集相互间是独立的,因此可认为Zt是独立的,于是
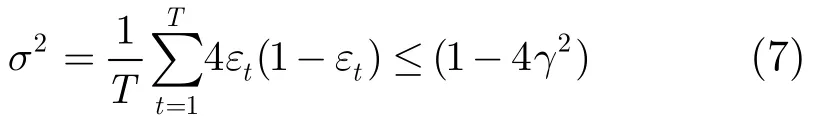
由大数定理,∀ε有
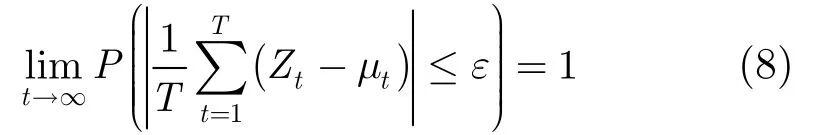

根据Zt的定义,当T→∞,对任意实例x,满足比的个数平均多μ个,采取简单投票法,,对x的分类错误率将趋于零。
SAMME算法中,在k分类问题中,若采用简单投票法构造强分类器,即H(x)=。则对任意训练集St,输出一个最大错误率为的分类器,,相互独立选取不同的St得到不同的。定义随机变量序列Zt,同式(6)。则Zt是一个均值为,方差为的随机变量。记

由于训练集相互间是独立的,因此可认为Zt是独立的,且,于是
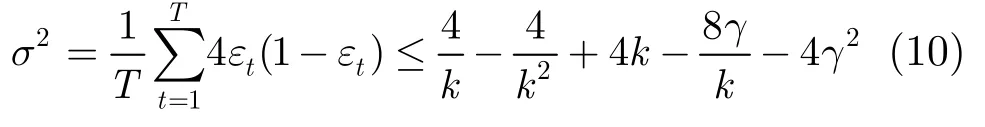
由大数定理,∀ε有
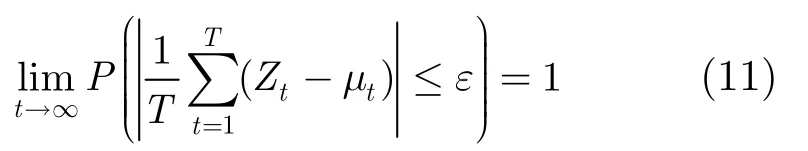

当k>2时,μ不一定大于0,根据Zt的定义,当T→∞,对任意实例x,满足的个数,不一定满足的个数多,采取简单投票法,,对x的分类错误率可能不会趋于零。
因此,本文提出了SAMME.R算法,在k分类问题中,若采用简单投票法构造强分类器,即。则对任意训练集St,输出一个最大错误率为的分类器,分类到k类的最小概率分别为,且。SAMME.R算法中要求,若,则。设m的概率为p,,则的概率为。
定义随机变量序列Zt:
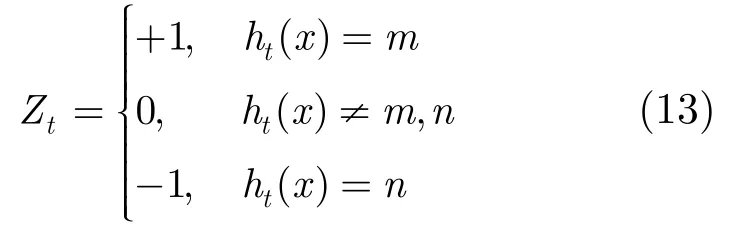
则Zt是一个均值为,方差为的随机变量。记μ=。由于训练集相互间是独立的,因此可认为Zt是独立的,于是

由大数定理,∀ε有

5 实验结果
在本节中,我们在基准UCI数据集上[16],对SAMME.R,SAMME以及AdaboostM1算法进行比较测试。我们在Segmentation,Vowel,Balance-scale,Ecoli,Wine,Yeast 6个数据集上进行了测试。其中,Segmentation数据集和Vowel数据集预先指定了训练集和测试集的内容。其他的数据集,我们随机挑选一半的样本作为训练集,其余部分作为测试集。
数据集的基本情况如表1所示。
本文用最近邻的方法作为弱分类器。在上述数据集上进行的实验中,实验数据为5次试验后的平均值。
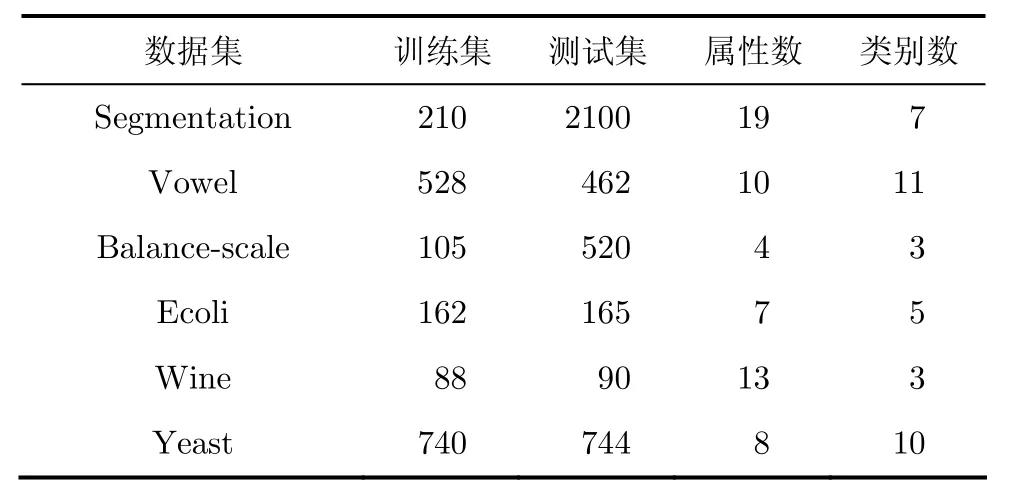
表1 测试数据集信息
分别计算了SAMME.R算法、SAMME算法以及Adaboost.M1算法,在200次迭代、400次迭代和600次迭代时的分类识别的错误率,实验结果如表2所示。
由表可以看出,在Segmentation,Balance-scale,Ecoli,Wine,Yeast数据库上,SAMME.R算法得出的结果都要优于SAMME算法和Adaboost.M1算法,只有在Vowel数据集上的表现不如Adaboost.M1算法,但SAMME.R的效果,仍然要比SAMME算法要好。
在实验结果中,我们发现Vowel数据集上SAMME.R算法的分类效果不如AdaBoost.M1算法。究其原因,由于SAMME算法和SAMME.R算法,为了能够更容易地找到弱分类器,降低了弱分类器对错误率的要求,权值调整at也因此加大。在下一次的迭代分类中,与AdaBoost.M1算法相比,SAMME算法与SAMME.R算法会更加偏向于本次分类错误的样本。导致下一次迭代中,弱分类器的分类正确率略有下降,造成弱分类器性能的下降。在弱学习算法中,弱分类器的质量会影响强分类器的分类效果,因此,SAMME.R算法对弱分类器性能弱化的要求,可使最终的强分类器性能提升,但个别情况下不如AdaBoost.M1算法的结果。Vowel数据集在所测试的所有数据集中,其类别数k最多,造成1/k较小,其对弱分类器正确率的要求也最低。而AdaBoost.M1算法,在任何数据集上都要求弱分类器正确率大于1/2。因此,在Vowel数据集上,SAMME.R算法的弱分类器性能有更大的可能性与AdaBoost.M1算法相差较大,造成SAMME.R算法对弱分类器性能弱化的要求,虽然保证了强分类器效果的提升,但最终的分类效果仍不如AdaBoost.M1算法好。
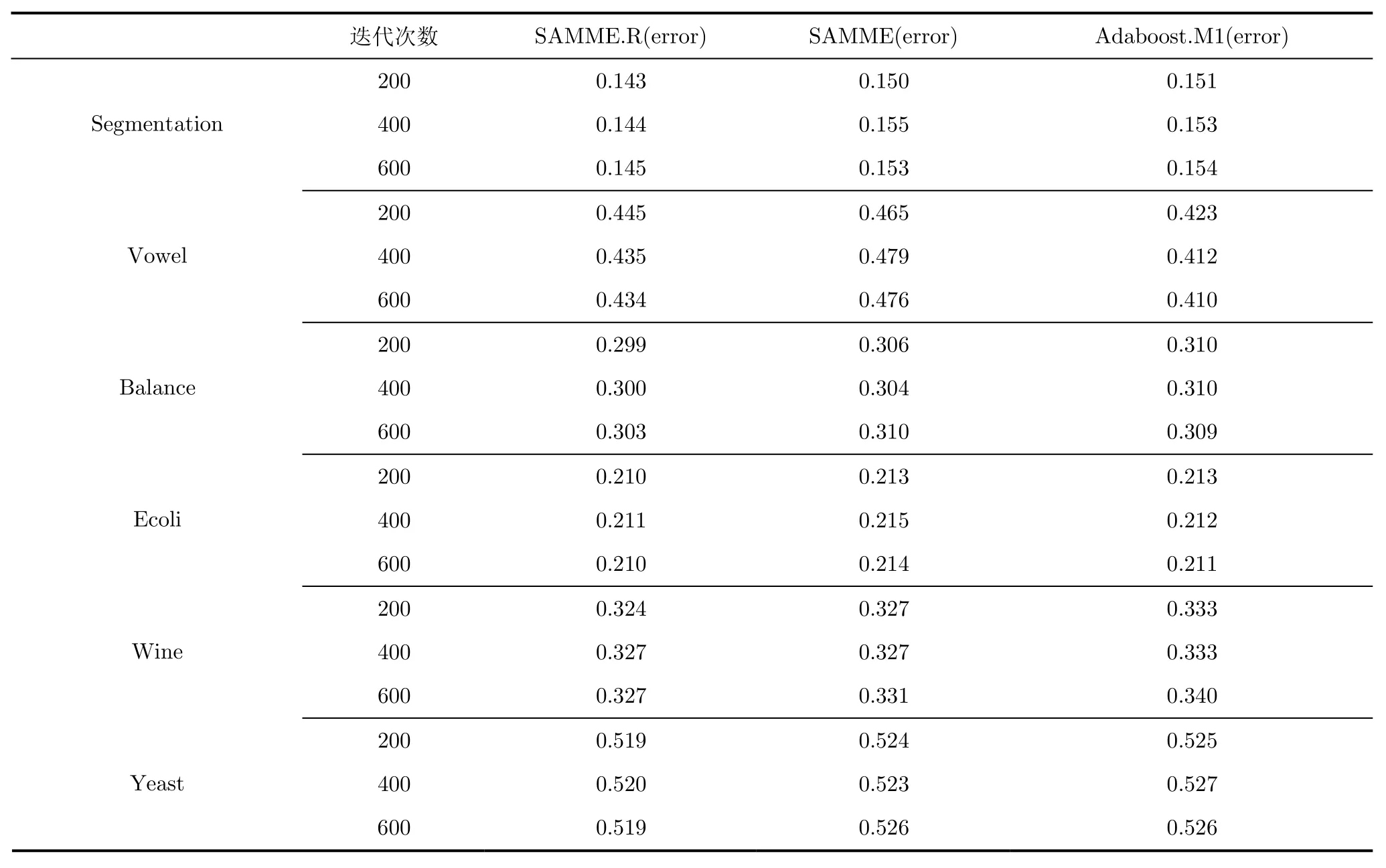
表2 测试错误率(%)
除在这些数据集上的测试外,我们还在Letter,Nursery,Pendigits,Satimage这几个数据集上进行了实验,由于实验过程中,未出现SAMME.R中需要重新训练弱分类器的情况,所以在这4个数据集上SAMME.R算法相当于SAMME算法。
对比实验表明,本文提出的SAMME.R算法的结果要好于SAMME算法,并达到了不弱于Adaboost.M1算法的效果。不但使其更容易应用到实际应用中,同时提高了其分类的准确性。通过实验发现在训练集较小的情况下,SAMME.R算法对SAMME算法有较明显的改进。
6 结束语
本文对多分类Adaboost算法的原理进行了分析,在此基础上针对SAMME算法的不足提出了改进的SAMME.R算法。SAMME.R算法要求弱分类器的性能只要比随机猜测好就可以被接受,降低了寻找弱分类器的难度。SAMME.R算法通过增加对弱分类器的限制,从而保证了弱分类器的有效性,确保强分类器的分类正确率得到提升。本文算法对弱分类器的要求,会比SAMME严格一点,但显然低于Adaboost.M1算法。与Adaboost.M1算法和SAMME算法相比,SAMME.R算法在绝大多数情况下有更好的分类效果。
本文只是从一个比较直观的角度分析了多分类Adaboost算法的原理。最近也有很多学者从不同的角度提出了新的多分类Boosting算法,有多分类DeepBoost[19],其从两类的DeepBoost[20]算法泛化而来的。DMCBoost[21]算法通过扩展两类的Direct Boost[22]算法而得出,也是一种直接的多类Boosting算法,其使用多类决策树作为基分类器[23]。PIboost[24]算法,把多分类问题转化为多个二分类问题,并且关注到了类的不对称分布的问题。
本文提出的算法也存在一定的不足,在SAMME.R算法重新训练弱分类器时,容易出现经过多次训练仍无法找到满足条件的弱分类器,实验中需要设置重新训练弱分类器的上限次数,使程序避免陷入死循环中无法跳出。在今后的工作中,需要找到一种更好的办法,来解决这个问题。
参考文献
[1]VALIANT L G.A theory of the learnable[J].Communications of the ACM,1984,27(11):1134-1142.doi:10.1145/800057.808710.
[2]SCHAPIRE R E.The strength of weak learnability[J].Machine Learning,1990,5(2):197-227.doi:10.1007/ BF00116037.
[3]FREUND Y.Boosting a weak learning algorithm by majority[J].Information and Computation,1995,121(2):256-285.doi:10.1006/inco.1995.1136.
[4]SCHAPIRE R E.A brief introduction to boosting[C].International Joint Conference on Artificial Intelligence,Sweden,1999:1401-1406.
[5]曹莹,苗启广,刘家辰,等.AdaBoost 算法研究进展与展望[J].自动化学报,2013,39(6):745-758.doi:10.3724/SP.J.1004.2013.00745.CAO Ying,MIAO Qiguang,LIU Jiachen,et al.Advance and prospects of AdaBoost algorithm[J].Acta Automatica Sinica,2013,39(6):745-758.doi:10.3724/SP.J.1004.2013.00745.
[6]FREUND Y and SCHAPIRE R E.A desicion-theoretic generalization of on-line learning and an application to boosting[J].Lecture Notes in Computer Science,1970,55(1):23-37.doi:10.1007/3-540-59119-2_166.
[7]NEGRI P,GOUSSIES N,and LOTITO P.Detecting pedestrians on a movement feature space[J].Pattern Recognition,2014,47(1):56-71.doi:10.1016/j.patcog.2013.05.020.
[8]LIU L,SHAO L,and ROCKETT P.Boosted key-frame selection and correlated pyramidal motion-feature representation for human action recognition[J].Pattern Recognition,2013,46(7):1810-1818.doi:10.1016/j.patcog.2012.10.004.
[9]FREUND Y and SCHAPIRE R E.Experiments with a new boosting algorithm[C].Proceedings of the Thirteenth International Conference on Machine Learning,Italy,1996:148-156.
[10]ALLWEIN E L,SCHAPIRE R E,and SINGER Y.Reducing multiclass to binary:a unifying approach for margin classifiers[J].The Journal of Machine Learning Research,2001,1(2):113-141.doi:10.1162/15324430152733133.
[11]MUKHERJEE I and SCHAPIRE R E.A theory of multiclass boosting[J].The Journal of Machine Learning Research,2013,14(1):437-497.
[12]SCHAPIRE R E and SINGER Y.Improved boosting algorithms using confidence-rated predictions[J].Machine Learning,1999,37(3):297-336.doi:10.1145/279943.279960.
[13]涂承胜,刁力力,鲁明羽,等.Boosting 家族 AdaBoost 系列代表算法[J].计算机科学,2003,30(3):30-34.TU Chengsheng,DIAO Lili,LU Mingyu,et al.The typical algorithm of AdaBoost series in Boosting family[J].Computer Science,2003,30(3):30-34.
[14]胡金海,骆广琦,李应红,等.一种基于指数损失函数的多类分类 AdaBoost 算法及其应用[J].航空学报,2008,29(4):811-816.HU Jinhai,LUO Guangqi,LI Yinghong,et al.An AdaBoost algorithm for multi-class classification based on exponential loss function and its application[J].Acta Aeronautica et Astronautica Sinica,2008,29(4):811-816.
[15]ZHU J,ZOU H,ROSSET S,et al.Multi-class adaboost[J].Statistics and Its Interface,2009,2(3):349-360.
[16]BLAKE C L and MERZ C J.UCI Repository of machine learning databases[OL].http://www.ics.uci.edu/.1998.
[17]FRIEDMAN J,HASTIE T,and TIBSHIRANI R.Additive logistic regression:a statistical view of boosting(with discussion and a rejoinder by the authors)[J].The Annals of Statistics,2000,28(2):337-407.doi:10.1214/aos/1016120463.
[18]付忠良.关于 AdaBoost 有效性的分析[J].计算机研究与发展,2008,45(10):1747-1755.FU Zhongliang.Effectiveness analysis of AdaBoost[J].Journal of Computer Research and Development,2008,45(10):1747-1755.
[19]KUZNETSOV V,MOHRI M,and SYED U.Multi-class deep boosting[C].Advances in Neural Information Processing Systems,Canada,2014:2501-2509.
[20]CORTES C,MOHRI M,and SYED U.Deep boosting[C].Proceedings of the 31st International Conference on Machine Learning(ICML-14),Beijing,2014:1179-1187.
[21]ZHAI S,XIA T,and WANG S.A multi-class boosting method with direct optimization[C].Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,New York,2014:273-282.
[22]ZHAI S,XIA T,TAN M,et al.Direct 0-1 loss minimization and margin maximization with boosting[C].Advances in Neural Information Processing Systems,Nevada,2013:872-880.
[23]DOLLAR P.Quickly boosting decision trees-pruning underachieving features early[C].JMLR Workshop &Conference Proceedings,2013,28:594-602.
[24]FERNANDEZ B A and BAUMELA L.Multi-class boosting with asymmetric binary weak-learners[J].Pattern Recognition,2014,47(5):2080-2090.doi:10.1016/j.patcog.2013.11.024.
杨新武:男,1971年生,副教授,研究方向为模式识别、遗传算法.
马壮:男,1990年生,硕士生,研究方向为模式识别.
袁顺:男,1989年生,硕士生,研究方向为模式识别.
Multi-class Adaboost Algorithm Based on the Adjusted Weak Classifier
YANG XinwuMA ZhuangYUAN Shun
(School of Computer Science,Beijing University of Technology,Beijing 100124,China)
Abstract:Adaboost.M1 requires each weak classifier's accuracy rate more than 1/2.But it is difficult to find a weak classifier which accuracy rate more than 1/2 in a multiple classification issues.Some scholars put forward the Stagewise Additive Modeling using a Multi-class Exponential loss function(SAMME)algorithm,it reduces the weak classifier accuracy requirements,from more than 1/2 to more than 1/k(k is the category number).SAMME algorithm reduces the difficulty to find weak classifier.But,due to the SAMME algorithm is no guarantee that the effectiveness of the weak classifier,which does not ensure that the final classifier improves classification accuracy.This paper analyzes the multi-class Adaboost algorithm by graphic method and math method,and then a new kind of multi-class classification method is proposed which not only reduces the weak classifier accuracy requirements,but also ensures the effectiveness of the weak classifier.In the benchmark experiments on UCI data sets show that the proposed algorithm are better than the SAMME,and achieves the effect of Adaboost.M1.
Key words:Multi-class classification; Stagewise Additive Modeling using a Multi-class Exponential loss function(SAMME); Adaboost.M1
*通信作者:杨新武yang_xinwu@bjut.edu.cn
收稿日期:2015-05-11;改回日期:2015-10-08;网络出版:2015-11-18
DOI:10.11999/JEIT150544
中图分类号:TP391.4
文献标识码:A
文章编号:1009-5896(2016)02-0373-08
