服务可用性监控系统的设计与实现
2016-04-08侯兴林王晓云
侯兴林++王晓云

摘要:随着互联网服务研究的不断深入,人们对网络服务的依赖程度也日渐增加。尤其在一些实时性要求较高的网络服务应用上,服务的后台核心系统是否具备高可用性,已经是影响该服务质量的关键因素。本文研究了针对服务可用性监控的服务可用性监控系统架构,提出了一个基于分层架构实现的多模块服务可用性监控系统,架构可以对接入的服务进行实时的监控,并展示该服务的实时可用性数据,从而可以在服务出现故障的时候快速的对其报警。
关键词:可用性;监控;报警
中图分类号:TP393.08
文献标识码:A
DOI:10.3969/j.issn.1003-6970.2016.02.018
引言
随着计算机技术与人们生活的紧密结合,在许多类似金融服务系统、飞行控制系统、医疗系统等应用领域,人们对这些系统的要求是不间断的提供有保障的服务,因为这些服务系统的故障会造成灾难性的后果。高可用性的服务解决方案就是为了解决这样的需求,高可用性系统相比普通的计算机系统来说,复杂性高了很多,其对应的研发成本也高了很多。
对于高可用性系统来说,该系统的用户会在系统设计之前,对系统的设计者提出一些量化标准,比如,要求该系统在一个时间范围内宕机的时间被控制在一定的范围内,高可用性系统由于其较高的设计难度,如果能在系统的运行期间引入量化分析的方法,就可以有效的对其可用性进行预测及报警,所以一个可用性监控系统对于一些大型系统的故障预测及报警有着非常重要的意义。
1 相关知识及研究
1.1 高可用性的定义
对于高可用性 的研究中,有三个相关的术语,分别是可用性 (Availability)、可靠性(Reliability)以及适用性(Serviceability)。其中可用性是指对于用户的使用来说,系统总的可用时间与总时间的百分比;可靠性是指系统在不出故障的情况下持续正常工作的时间;适用性是指对于系统维护、升级的难易程度。
在服务系统的运行周期中,系统的可靠性通过平均无故障时间(MTTF)来表示,平均无故障时间是指系统正常运行的平均时间;系统的适用性通过平均修复时间(MTTR)来表示,平均修复时间是指从系统发成故障到修复完成并重新恢复的平均时间。通过平均无故障时间和平均修复时间可以得到可用性的定义:
从可用性定义的公式可以得出两个影响系统可用性的因素,分别是:
(l)系统各组件的可靠性。这些组件包括服务器硬件、操作系统和服务系统本身,以及其他的支持组件如数据库系统、网络服务器等。
(2)当系统发生故障后,系统重新恢复所花费的时间。如果是服务系统本身的故障,则将该系统重新启动就可以恢复服务了;如果是硬件设施发生故障的话,则需要对定位发生故障的组件并对其进行修复或更换,然后重新启动操作系统和其他相关设备,最终启动服务系统。
一个高可用性系统对系统中所有的组件及子系统都要求其正常工作。在一个系统中,如果大部分组件都具备高可用性,但是另一些组件不具备高可用性,对于整个系统来说,系统也无法保证高可用性,这个特点是高可用性系统的木桶原理。
在一个高可用性系统中,还有两个相关的术语,即持续可用性(Continuous Availability)、容错(Fault Tolerance)。持续可用性是指系统无故障提供服务的理想状态,其也用来表示一个系统的可用性很高,故障时间较少;容错是指即使某些组件出现故障,整个系统依旧可以无故障的提供服务,一些高可用性的解决方案已经提供了一定的容错能力。
1.2 高可用性等级
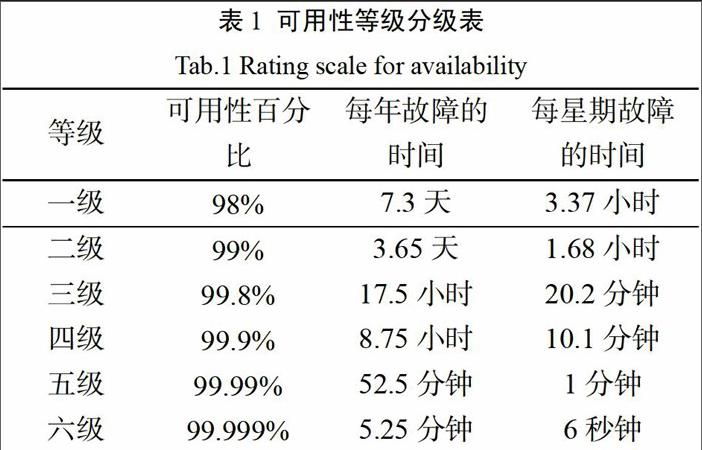
高可用性等级明的分级是以可用性百分比中数字“9”的个数来区分的,如果一个系统达到二级高可用,则说明该系统的可用性百分比为99%,一年中总的故障时间为3.65天;如果一个系统达到四级可用,则说明该系统的可用性百分比为99.99%,一年中总的故障时间为52.5分钟。可用性分级表如下表:
1.3 服务可用性监控系统相关研究
国内外已经有了许多关于服务可用性分析的研究与设计,例如一些成熟的商用服务可用性监控系统,如IBM Tivoli、HP Buiness Availability Center等,这些商业系统对服务可用性的分析基于强大的监控和数据分析能力,对部署于其上的服务进行实时的监控,并对不满足可用性的服务进行报警,但是这些服务可用性监控系统的购买费用较高,且需要大量监控日志数据的支持,对于国内的一些论文作者的。
我们的目标是建立一个可靠、灵活的服务可用性监控系统,通过在服务可用性监控系统中部署业务系统,可以通过系统直观的看出该业务系统在某段时间内的服务可用性。
2 服务可用性监控系统架构的分析与设计
本服务可用性监控系统提供了简单的域名监控接入方式,采用主动拉取数据的方式,无需用户参与,并提供了统一的可用性计算公式,以及丰富的图表及历史数据查询对比。
2.1 服务可用性监控系统的整体架构
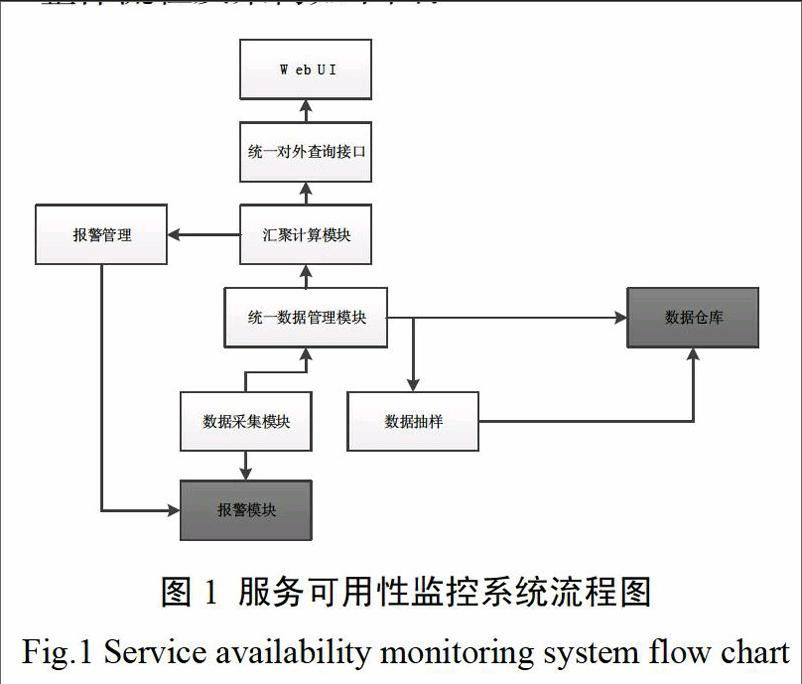
本服务可用性监控系统主要分为汇聚计算、统一数据管理、数据采集、数据抽样四个模块。
其中,汇聚计算模块是本服务可用性监控系统的入口,本模块负责接收用户的查询参数、获取统一数据数据管理模块传来的监控数据,并对监控数据进行汇聚计算,以得到可用性数据。如果最终计算的可用性数据低于用户配置的报警阀值时,对用户进行报警通知。
统一数据管理模块是本系统的中枢,本模块负责收集用户输入的监控配置项(包括被监控服务的域名、正常服务的关键字、可用性报警阀值等),将其保存到数据库中,并将监控配置项发送到数据采集模块;当用户点击其配置的监控配置项时,系统将会根据其配置从数据仓库中找到匹配的监控数据,并将监控数据发送至汇聚计算模块,最终展示给用户。
数据采集模块是本系统的核心,本模块首先取到监控配置项,然后根据监控配置项中的数据,调用监控集群中的多个监控机定时地对监控目标进行监控,得到监控的数据与用户配置的数据进行对比,如果数据不一致,则认为当前监控的服务是不可用的,将同一时间点多个监控机的数据累计计算出一个百分比,并将这个数据发送到统一数据管理模块。
数据抽样模块是一个辅助模块,主要是由于监控的数据量较大,当计算跨月或者季度的可用性时,由于数据量过大,会导致计算的时间过长,从而影响用户体验。因此,数据抽样模块将会按天为粒度将监控数据计算出来并保存到数据仓库中。
整体流程及架构如下图:
2.2 监控数据采集
监控数据的采集是由数据采集模块完成的,数据采集模块会根据用户配置的监控项调用监控集群中的多个监控机以10秒一次的频率对监控目标进行监控,将同一时间点多个监控机的数据累计计算出一个百分比,该百分比就是当前监控项当前时间点的监控数据。具体的监控数据采集流程如下:
(l)数据采集模块获取配置的监控项中被监控服务的域名、关键字等监控项。
(2)监控机发起对被监控服务域名的访问,获取其返回数据并将其返回数据与关键字对比,如果关键字符合则计数加一,不符合则不增加计数。
(3)最终将多个监控机计数除以监控机的总个数得到一个百分比,该百分比作为当前时间点的监控数据。
(4)将监控数据按照时间和监控项ID作为主键存人数据仓库的普通表。
2.3 监控数据抽样
由于监控机的监控周期为10秒,对于一个服务的监控数据量会非常庞大,当对该服务的可用性进行计算的时候会造成查询时间过长,影响用户体验。所以,数据抽样模块会以天为单位对服务的监控数据进行抽样计算,并将其存人数据仓库中。具体流程为,将前一天凌晨到当天凌晨的该被监控服务的监控数据计数并加和,将该计数和加和作为抽样数据存人数据仓库的抽样表。
2.4 可用性计算
被监控服务的可用性计算分为两种情况:
(l)用户查询时间区间在一天内。这种情况的可用性计算相对简单,即统一数据管理模块通过接口查询数据仓库,将该时间区间内所有该服务的监控数据取出,对其进行计数和加和,然后将该加和除以该计数就可以得到当前时间区间服务的可用性数值了。
(2)用户查询时间区间超过一天。在这种情况中,对总体可用性的计算由于需要的数据量过于庞大,需要使用抽样数据。首先将查询时间区间中整天的数据从数据仓库的抽样表中取出并累加到一起,最终得到一个计数count和一个加和sum,然后在数据仓库的普通表中取出查询时间区间的非整天数据,接着将查询时间区间中非整天的数据累加到sum上,并每次对count加一,最终得到整体计数和整体加和,然后用整体加和除以整体计数,得到当前时间区间服务的可用性数值。
服务可用性监控系统的数据流图如下:
3 结论
本文提出的服务可用性监控系统架构,包括了汇聚计算、统一数据管理、数据采集、数据抽样四个模块,一方面采用了分层的思想对业务逻辑进行分析,降低了模块与模块之间的耦合性,当逻辑需要发生变化的时候,只需要修改一个模块,不会影响到其他模块;另一方面在存储数据时,对原始数据存储时进行了一定的数据抽样,从而在大数据量查询时可以有效的降低查询时延,提升了用户体验。本文的下一步研究重点是完成对除web服务以外,其他类型服务监控的接入,希望最终实现一个可接人多类型服务的服务可用性监控系统。
