统一框架的混合依存句法分析
2016-04-05吴福祥周付根北京航空航天大学宇航学院北京海淀区100191
吴福祥,周付根(北京航空航天大学宇航学院 北京 海淀区 100191)
统一框架的混合依存句法分析
吴福祥,周付根
(北京航空航天大学宇航学院 北京 海淀区 100191)
【摘要】监督统计句法分析器的性能很大程度依赖于昂贵而有限的人工标注数据。为充分利用现有标注树库而不需额外设计句法分析器,该文提出了一种混合句法处理管线。该管线以基于最大生成树算法和线性链式条件随机场的句法分析器为基本框架,融合使用不同树库进行混合训练,综合利用不同树库对应的基线分析器解析的依存骨架,提取交叉信息,并在基本框架上构建了综合句法分析器。实验结果表明,该方法可以有效地提升单一树库的句法分析器的分析精度。
关 键 词条件随机场; 依存句法; 混合句法分析; 最大生成树
Unified Framework for Hybrid Dependency Parsin
WU Fu-xiang and ZHOU Fu-gen
(School of Astronautics, Beihang University Haidian Beijing 100191)
Abstract The mainstream dependency parser is a supervised statistical parser whose performance greatly relies on manually annotated dataset in recently. In order to use multi-treebank without building a new parser, a hybrid dependency processing pipeline is proposed. The pipeline is implemented through maximum spanning tree (MST) algorithm and linear chain conditional random fields (CRF) as base framework, and a hybrid dependency processing pipeline for training the parser by using multi-treebank is constructed, then a composite dependency parser is built from base framework to utilizes cross information of the multi-treebank with a set of hybrid feature templates. The result shows that the pipeline can improve the parsing precision of single-treebank parser without designing a new parser.
Key words CRF; dependency grammar; hybrid dependency parsing; MST
通过解析语句句法分析可以生成词间的内在结构信息,为信息获取、问答系统和机器翻译[1]等提供便利。句法分析可分为依存结构句法分析和短语结构句法分析,现主流方法是通过使用大规模人工标注语料库有监督学习的句法分析方法[2-4]。由于中文缺乏形态变化,并且有大量的兼类词,使之分析的精度没有达到英文句法分析的精度,现在仍是研究的热点[5]。
有监督的句法分析算法性能很大程度依赖于人工标注数据,该标注数据的质量和规模会严重影响算法的性能,而人工标注数据是一件非常繁重的工作,且需要专业的语言学知识,因此并不容易获取高质量的数据。现在常用的标注语料库主要有哈尔滨工业大学的Chinese dependency treebank(CDT)[6]和宾夕法尼亚大学的Chinese treebank(CTB)[7]等,其中CDT是依存结构句法语料库,而CTB是短语结构句法语料库。由于各个标注语料库标注规则并不相同,不能直接合并使用,因此如何有效地利用现有的标注数据扩大训练数据也是一个研究热点。
为了同时使用不同标注语料库来提高分析器的性能,本文提出一种融合多个语料库信息进行分析的处理管线。该管线统一使用基本解析算法进行前期处理和后期合并,该算法MST[8]的图算法实现,而训练算法是通过CRF[9]学习边权重。该处理管线不需要重新开发句法分析器,直接重用分析器即可融合多个语料库。
1 相关工作
近年来,有大量关于依存句法分析的研究。在依存句法分析中,根据所研究的句子依存结构中依存弧是否有交叉分为投影性(projective)和非投影性(non-projective),此外根据分析算法中使用的特征阶数分为一阶、二阶和高阶,由于本文主要研究融合使用多语料库带来的效果,因此只考虑投影依存句法分析,并使用一阶特征。
依存句法处理主要有文献[3-4]构建的基于转移的依存句法分析器MaltParser和文献[8]构建的基于最大生成树的依存分析器MSTParser。其中MaltParser是通过left-arc、right-arc、reduce和shift操作输入队列和相应的栈完成句子的依存结构构建,它的训练是通过支持向量机或线性分类器学习4种操作发生时的相应特征;而MSTParser则是通过最大生成树搜寻依存结构和使用在线学习margin infused relaxed algorithm(MIRA)算法完成,它们都获得了一流的分析结果。此外,混合转移、图算法的束(beam)搜寻算法[10-11]和融合了高阶特征[12]的分析算法都获得了分析性能的提升。
有监督学习的算法中,标注训练数据非常重要,同时使用多语料库进行融合学习的研究[13-15]也不少。其中文献[16]和本文方法比较类似,但该方法中的综合分析器需要进行子树提取和树结构比较以进行评分,是以类似于重估的方式进行合并处理,而本文则直接使用扩展了的基本分析器进行合并处理,统一了处理框架。
2 基本句法分析器
本文算法是基于CRF的MST句法分析器。CRF是一种无向图模型,它相对于最大熵算法,不会产生标注偏置问题,并且没有隐马尔科夫模型严格的独立性假设。对于一棵依存句法树,其概率为:
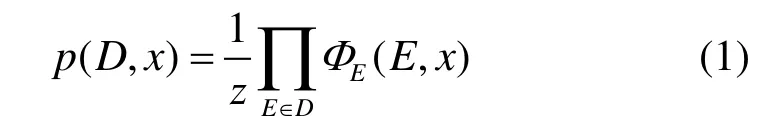
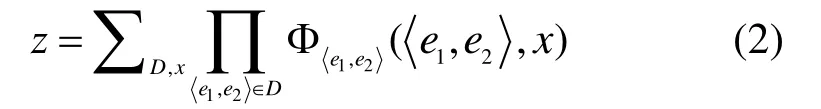
而势函数定义为:
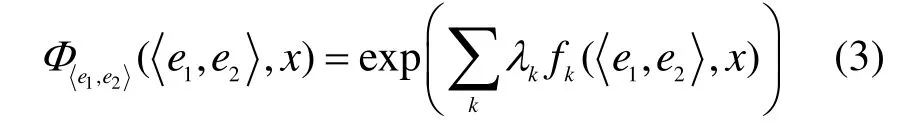

图1 基本分析器处理流程
在图1中,由于大规模语料库的特征规模往往非常巨大,会占用很多计算资源,此外也会带来数据稀疏等问题,因此需要对语料库进行裁剪,本文中将少于3的特征去除。即使如此在裁剪前也会产生内存不足的问题,因此要进行分割,每500句为一组生成特征映射子表,随后对逐个子表进行合并。此外由于CRF对正则化不太敏感并且训练比较耗时,使用如下规则进行训练:
1) 训练分析器并保存当前特征权重;
2) 训练次数是否是10的倍数,否则跳到步聚1);
3) 使用当前测试数据和特征权重计算解析精度,如果性能连续下降3次则训练完成;
4) 如果训练次数超过最大训练次数则退出。
3 混合句法分析
对于同种语言,不同标注树库之间信息是有交叉的,因此可以通过融合这些信息提升分析器的性能。虽然对于使用不同语料库训练完成的句法分析器的分析结果各有不同,但它们的依存关系骨架是有交叉的,如CTB中“外商投资企业成为中国外贸重要增长点”这句话,其依存骨架如图2所示。

图2 依存骨架
图2是通过CDT语料库训练的基本句法分析器解析生成的,虽然它和CTB中的关系标注各不相同,但可以看出和图2a的原始标注骨架基本相同,因此可以选择一个原始语料库合并另外语料库训练的分析器输出结果,并于训练时同时提取该结果的骨架特征和原始语料库的依存信息进一步分析,混合训练处理管线如图3所示。
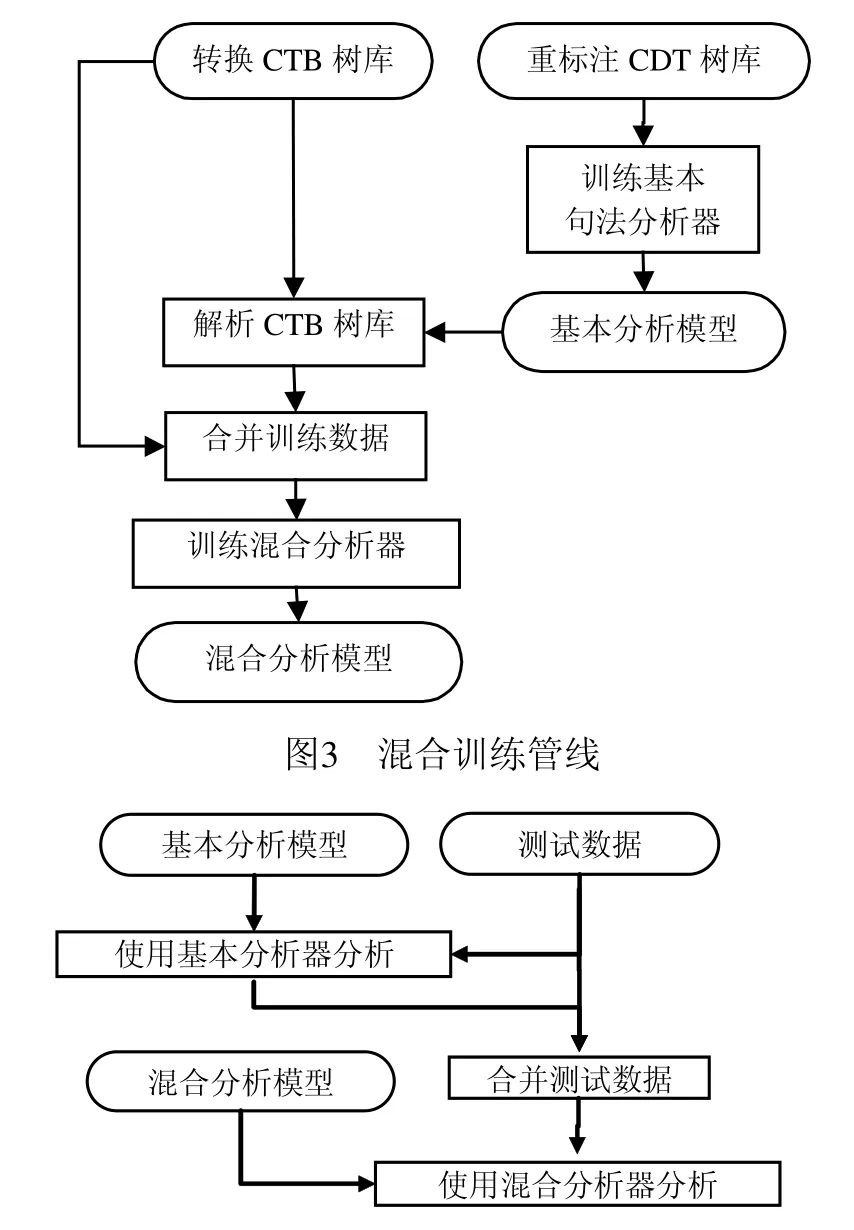
图4 解析管线
在图3中,由于CTB是结构句法语料库,需要转换为依存结构,这里使用Penn2Malt工具。此外,由于CDT词性使用的是国家863词性标注标准,和CTB不一致,需要进行统一,本文使用Stanford POS Tagger词性标注器进行重标注。数据准备完成后预训练基本句法分析器,得到基本分析模型,它包含特征表和权重数组,随后解析CTB语料,并将结果和CTB初始数据合并,最后使用该套数据训练综合分析器,得到混合分析模型。解析管线如图4所示。
在图4中,基本分析模型和混合分析模型是来自图3中的训练管线,并且这些模型格式都是对应于基本句法分析器的数据模型格式。
3.1 混合特征
混合特征提取除了包含基本句法分析器的特征模板外,还包括训练数据中的额外结果骨架(预先分析的结果)的特征提取,该特征提取函数如表1所示。
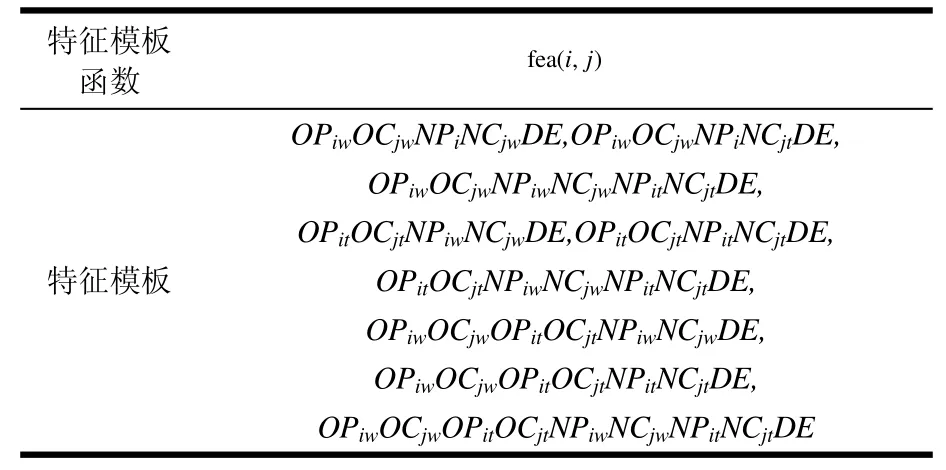
表1 骨架特征模板函数
表1中OP和OC分别对应于数据中CTB的原始依存弧中的父节点和子节点;而NP和NC则对应于通过基本句法分析器分析后合并到训练数据中的依存骨架父节点和子节点;D是指原始依存弧的方向;E特征为判断原始依存弧骨架和额外分析依存弧骨架是否一致;OPi和OCi分别指原始依存弧中的父节点和子节点的后i个节点,其余数值类推。
根据是否提取依存弧的端点,将领域特征分为3组特征模板集:
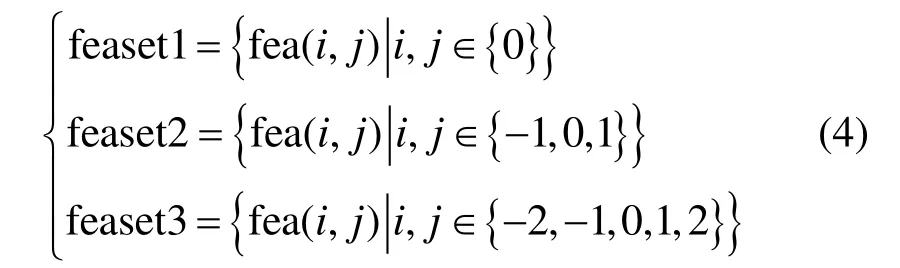
3.2 带有骨架特征的综合句法分析器
由于式(4)特征集中的骨架特征和其他基本句法分析器中的普通特征类似,可以直接融入基本句法分析器框架中,但是由于该特征数量巨大,需要提前对骨架建立连接信息结构,处理算法伪代码如下:
算法1:GenerateSkeletonFeature函数伪代码
输入变量:linkInfo, 骨架链接列表;mixtree, 合并后训练或测试数据;sentence, 原始句子;FeatureSet, 特征模板集合;
输出变量:fea_vec,特征集合; fea_vec_temp, 临时存储空间
for i in [1,n]:
CollectChildren(i, mixtree, linkInfo)
SortChildren(i, mixtree, linkInfo)
for temple in FeatureSet:
SplitTemple(temple, tem_list)
for item in tem_list:
GetFeaString(item, sentence, mixtree, linkInfo,
fea_vec_temp)
fea_str = BuildFullFeature(tem_list ,
fea_vec_temp)
addTo(fea_str, fea_vec)
通过算法1可以在训练或分析时提取骨架特征。其中,CollectChildren和SortChildren搜集骨架中某个节点的所有子节点(依存关系)并按照它们自然次序排序。由于式(4)特征集中各个特征模板的不少子元素是重复的,因此使用SplitTemple将特征集中的每个特征模板拆开,随后使用GetFeaString获取相应的特征值,最后使用BuildFullFeature重新合成完整特征,加快了特征提取过程。因此综合分析器的处理流程只需在图1中的分析器处理框架中进一步引入提取骨架特征算法,并通过图3和图4所示的流程将综合句法分析器和基本句法分析器结合起来构成整个训练及分析管线。
3.3 管线处理流程
混合管线包含底层的基本句法器和后面的混合分析器,训练流程如下:
1) 使用重标注的CDT树库训练基本句法分析器Pbase;
2) 使用Pbase预分析CTB树库中语句,生成预分析依存结果集Γ;
3) 使用CTB树库和结果集Γ训练混合分析器,通过混合特征模板提取特征并完成训练。
而测试流程为:
1) 使用Pbase预分析测试集中的语句,生成预分析结果集Π;
2) 使用测试集和结果集Π通过混合分析器进行分析,计算出解析结果。
4 数据及结果分析
4.1 训练及测试数据划分
由于CRF训练收敛比较慢,且特征空间比较大,因此选择CDT和CTB6树库的部分数据进行测试,数据划分如表2所示。
其中CTB训练数据的平均长度为24.2 331,测试数据的平均长度为28.568,而CDT训练数据的平均长度为24.2 331,测试数据的平均长度为17.859。

表2 数据划分
4.2 测试结果
本文使用MSTParser分析器和基本句法分析器作为基线测试,随后分别使用公式(4)中的3个模板特征集进行混合句法分析器的训练,这里的评测指标使用带标记依存正确率(LAS)和不带标记依存正确率(UAS)。其中基线测试结果如表3所示。
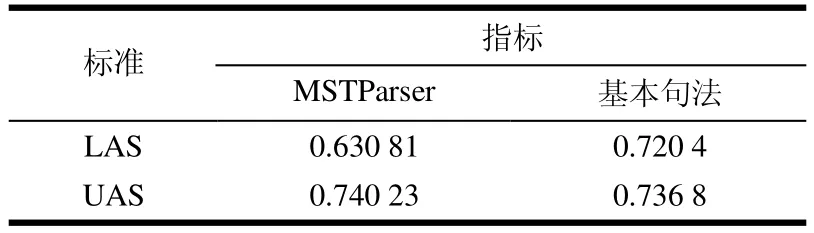
表3 基线测试结果
当使用式(4)的feaset1模板特征集时,测试结果如图5a所示,其中最高的LAS值为0.721 997。对比表3可看出,融合其他树库信息可以提高分析精度。由于feaset1特征模板集数量比较小,而feaset2是它的扩充。使用feaset2的混合句法分析器测试结果如图5b所示,其中最高的LAS值为0.722 557。相对于feaset1来说,扩充了特征集的feaset2可提取更多的有效特征,因此测试性能比feaset1提升了0.05%。而模板特征集feaset3包含feaset2,使用feaset3模板特征集的混合句法分析器测试结果如图5c所示,其中混合句法分器的最高LAS值为0.722 137。
4.3 结果分析
在表3中,基本句法分析器分析精度要比MSTParser高,这可能是由于它们的特征提取差别引起的,且没有对MSTParser进行进一步优化。从图5测试结果可以看出,通过使用额外的骨架特征,可以带来精度的提高,其中使用feaset1特征模板的混合分析器的LAS值最大提升0.1 997%;使用feaset2特征模板则提升0.2 557%;而使用feaset3特征模板提升0.2 137%。其中各组特征模板的特征数量如表4所示。

图5 混合句法分析器测试精度

表4 MSTParser特征数目
feaset1特征模板主要提取依存弧两端的节点信息,不包含它们周围信息,feaset2特征模板包含端点周围信息,比feaset1多4.25%,可以捕捉更多句法特征,而feaset3特征模板包含feaset2,但它会导致性能下降,这可能是由于feaset3比feaset2的特征数多所致,特征空间增大后带来数据稀疏引发的性能下降,这需要更加精细的特征模板设计。
5 结 束 语
在本文中,通过使用同一套基本句法分析器框架,构建了混合树库训练及分析管线,并通过添加额外的骨架特征提取实现了综合句法分析器,从而构建统一的混合句法分析管线。结果表明,通过使用同一框架混合句法分析器,融合两套树库进行训练,获得了比单一树库更高的分析准确率,它带来了0.255 7%的LAS提升。此外由于本文只是将CTB转换为依存句法结构并重标注CDT的词性,但它们的分词并没有进一步分析。未来计划进一步分析它们的分词等信息,使分析器更容易融合两树库的相关信息。
参 考 文 献
[1] ZHOU Guang-you, CAI Li, ZHAO Jun, et al. Phrase-based translation model for question retrieval in community question answer archives[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: Association for Computational Linguistics, 2011: 653-662.
[2] 宗成庆. 统计自然语言处理[M]. 北京: 清华大学出版社,2008. ZONG Cheng-qing. Statistical natural language processing[M]. Beijing: Tsinghua University press, 2008.
[3] NIVRE J, HALL J, NILSSON J. Memory-based dependency parsing[C]//Proceedings of the Eighth Conference on Computational Natural Language Learning (CoNLL). Boston, USA: Association for Computational Linguistics, 2004: 49-56.
[4] NIVRE J, HALL J, NILSSON J. MaltParser: a data-driven parser-generator for dependency parsing[C]//Proceedings of the 15th International Conference on Language Resources and Evaluation (LREC2006). Genoa, Italy: European Language Resources Association, 2006: 2216-2219.
[5] CHE Wan-xiang, SPITKOVSKY V L, LIU Ting. A comparison of Chinese parsers for stanford dependencies [C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (ACL 2012). Jeju Island, Korea: Association for Computational linguistics, 2012: 11-16.
[6] LIU Ting, MA Jin-shan, LI Sheng. Building a dependency treebank for improving Chinese parser[J]. Journal of Chinese Languages and Computing, 2006, 16(4): 207-224.
[7] XUE Nai-wen, XIA Fei, CHIOU Fu-dong, et al. The penn Chinese treebank: Phrase structure annotation of a large corpus[J]. Natural Language Engineering, 2005, 10(4): 1-30.
[8] MCDONALD R, CRAMMER K, PEREIRA F. Online large-margin training of dependency parsers[C]//Proceeding of the 43th Annual Meeting of the Association for Computational Linguistics. Ann Arbor, USA: Association for Computational Linguistics, 2005: 91-98.
[9] SHA F, PEREIRA F. Shallow parsing with conditional random fields[C]//Proceedings of the 2003 Human Language Technology Conference and North American Chapter of the Association for Computational Linguistics (HLT/NAACL-03). Edmonton, Canada: Association for Computational Linguistics, 2003: 134-141.
[10] NIVRE J, MCDONALD R. Integrating graph-based and transition-based dependency parsers[C]//Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Columbus, USA: Association for Computational Linguistics, 2008: 950-958.
[11] ZHANG Yue, CLARK S. A tale of two parsers: Investigating and combining graph-based and transitionbased dependency parsing using beam-search[C]// Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP '08). Stroudsburg, USA: Association for Computational Linguistics, 2008: 562-571.
[12] CARRERAS X. Experiments with a higher-order projective dependency parser[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing. Prague, The Czech Republic: Association for Computational Linguistics, 2007: 957-961.
[13] GREEN N. Hybrid combination of constituency and dependency trees into an ensemble dependency parser[C]// Proceedings of the Workshop on Innovative Hybrid Approaches to the Processing of Textual Data. Avignon, France: Association for Computational Linguistics, 2012: 19-26.
[14] LI Zheng-hua, LIU Ting, CHE Wan-xiang. Exploiting multiple treebanks for parsing with Quasi-synchronous grammars[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. Jeju Island, Korea: Association for Computational Linguistics, 2012: 675-684.
[15] NIU Zheng-yu, WANG Hai-feng, WU Hua. Exploiting heterogeneous treebanks for parsing[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP. Suntec, France: Association for Computational Linguistics, 2009: 46-54.
[16] ZHOU Guang-you, ZHAO Jun. Joint inference for heterogeneous dependency parsing[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. Sofia, The Republic of Bulgaria: Association for Computational Linguistics, 2013: 104-109.
编 辑 叶 芳
Application of CNTs Functional Layer in AC Plasma Display Panels
DENG Jiang1and WANG Xiao-ju2
(1. College of Optoelectronic Technology, Chengdu University of Information Technology Chengdu 610225; 2. School of Opto-Electronic Information, University of Electronic Science and Technology of China Chengdu 610054)
Abstract Carbon nanotubes (CNTs) are coated on conventional MgO protective film in an alternating current plasma display panel (AC PDP) as a functional layer by the spray coating method. The transmittance and the discharge characteristics of CNTs/MgO films are investigated. The results show that the visible light transmittance of the CNTs/MgO protective layer is 80% higher. The firing voltage and discharge delay time decrease with the addition of a CNTs functional layer. With 100 torr 10 % Xe-Ne pressure, the firing voltage and the discharge delay time of the AC PDP test cell with CNTs/MgO protective layer are 263.5 V and 270 ns, respectively, which are 15% and 26% lower than that of the conventional MgO protective layers. Thus, this CNTs/MgO layer could be considered as a potential protective layer for use in AC PDP.
Key words carbon nanotubes (CNTs); discharge delay time; firing voltages; protective layer; transmittance
作者简介:吴福祥(1984 − ),男,博士生,主要从事高性能计算、自然语言处理方面的研究.
收稿日期:2014 − 04 − 21;修回日期: 2015 − 09 − 25
中图分类号TN912
文献标志码A
doi:10.3969/j.issn.1001-0548.2016.01.017
