基于双聚类方法的乳腺癌相关酶研究前沿
2016-03-23,,
,,
乳腺癌是女性最常见的恶性肿瘤之一,在欧美国家多发,在我国,尤其是经济发达地区的发病率也呈明显上升趋势。经调研,发现大量研究表明乳腺癌的发生发展与各种蛋白酶密切相关。 Weqner MS等人证实,雌激素上调乳腺癌细胞神经酰胺合成酶的表达可能与乳腺癌细胞的增殖及肿瘤的发展有关[1];Laderoute KR等人证明,5'-AMP-activated蛋白酶通过调节乳腺癌肿瘤葡萄糖代谢的方式促进乳腺癌细胞的增殖生长[2]。本文的研究目的是为了帮助研究人员及时、准确地发现该领域研究前沿,制定未来发展策略。
国内外研究人员常使用共词分析方法探测研究前沿,如Ryosuke L.Ohniwa等选取增长率高的MESH术语,用共词的方法将它们分组,通过不同的时间窗比较探究生命科学领域的研究前沿[3];沈思等基于主题模型定义抽取表征主题不同发展阶段的特征词,利用特征词概率变化分析主题的冷热变化,证明该方法可提供较为准确的热点主题和发展趋势[4];齐凤青[5]等人利用WOS检索的文献进行共词分析,分析医学信息学研究现状。但以往的共词分析方法得到的主题往往语义不明确,含义模糊不清。基于双聚类的方法则可以实现对类团含义的揭示,清晰展示研究前沿。本文借助于双聚类算法对乳腺癌相关酶研究文献进行分析,实现行和列的同时聚类,从行和列两个维度共同分析,比较不同时间窗内聚类结果的变化,发现乳腺癌相关酶研究的前沿内容。
1 数据和方法
1.1 数据来源
在PubMed数据库中检索2009-2011年和2012-2014年乳腺癌相关酶研究的相关文献,构建检索表达式为“Breast Neoplasms/enzymology”[Mesh]AND (“2009/01/01”[PDAT]: “2011/12/31”[PDAT]) 及“Breast Neoplasms/enzymology”][Mesh]AND (“2012/01/01”[PDAT]: “2014/12/31”[PDAT]),检索结果分别为1 147篇和906篇,结果用MEDLINE格式保存,检索时间为2015年3月12日。
1.2 方法和工具
1.2.1 方法
双聚类方法是Hartigan[6]首先提出的。该方法可对数据矩阵中的样本和变量同时进行聚类,实现了在对象及其属性两个方向上的同时聚类,同时使用对象及其属性来提取它们的联合信息,发现潜在的局部信息。双聚类算法比其他单向传统聚类方法在应用上更具有优势,它可以同时探测两个维度的聚类成果,并在一定程度上实现了对聚类的自动标注。本文采用这种方法,“行”选取酶相关概念,“列”选取乳腺癌相关概念,两两统计概念的共现次数,组成共现矩阵,然后在行和列两个维度进行聚类分析,识别相关酶类团的同时得到与之对应的乳腺癌相关概念。
目前有许多不同的指标可用于识别和判别主题演化判断,如1986年Callon等提出的包容指数和邻近指数,1997 年Coulter 等提出的相似指数 (Similarity Index)。本文则采用冷伏海[7]等提出的指数P来判断不同时间段聚类结果形成的类团间的关联强度。P 指数即概率指数,主要反映两个聚类中有多少主题词以其对聚类的贡献度将这两个聚类相连接,同时有多少主题词以其对聚类贡献度将这两个聚类分割开,进而决定类团间是否具有演化关系。P指数计算公式为:Pij=Iij/(Ii+Ij-Iij),其中,Iij是两个主题聚类 Ci和 Cj中共有主题词集的信息量总和,Ii是聚类 Ci的所有主题词集信息量之和,Ij是聚类 Cj的所有主题词集信息量之和。本文对不同时间段聚类结果形成的类团进行分析,可以看到一定时间内类团的新生、演化、增长和消失,从而分析出科学研究兴趣的动态变化。
1.2.2 工具
利用Thomson Data Analyzer(TDA)[8]文本挖掘软件进行多角度的数据挖掘和可视化全景分析。
利用明尼苏达大学Matt Rasmussen等开发的gCLUTO软件形成共现矩阵或词篇矩阵,实现对矩阵的行和列同时聚类[9]。gCLUTO的聚类方法有Repeated Bisection(重复二分法)、Direct(直接聚类)、Agglomerative(凝聚聚类)和 Graph(图形聚类)4种,我们可以根据需要来选择最佳的聚类方案,并通过可视化矩阵和可视化山丘功能展示聚类效果。
2 共词聚类结果和分析
首先将下载的2009-2011年和2012-2014年文献记录分别导入到TDA中,选取MESH主题词字段进行分析,先对字段进行数据清洗,合并同义词处理,然后选择分析频次大于5的乳腺癌肿瘤相关概念和酶的相关概念,形成2009-2011年和2012-2014年以乳腺癌相关概念为列以酶相关概念为行的共现矩阵(见表1和表2)。

表1 2009-2011年乳腺癌相关概念为列和乳腺癌酶相关概念为行的共现矩阵

表2 2012-2014年乳腺癌相关概念为列和乳腺癌酶相关概念为行的共现矩阵
将两个矩阵分别导入gCLUTO软件进行双聚类分析,聚类方法选择重复二分法,最优化函数选择I2,相似系数选择余弦函数,聚类数反复调整,最终分别聚为6类(图1)和5类(图2)。类内相似度较大,类间相似度较小,聚类形成的可视化山丘显示效果较好。
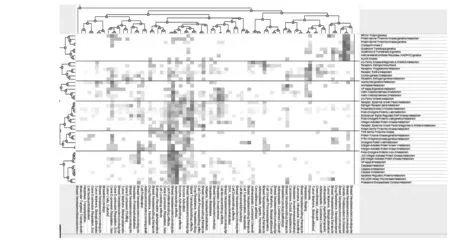
图1 双聚类可视化矩阵
2.1 2009-2011年乳腺癌相关文献的双聚类结果
图1聚类图形中,行聚类表示的是对乳腺癌相关酶研究的分类,并在图右侧对应列出酶相关概念;列聚类表示的是对乳腺癌相关概念的聚类,并在图下方对应列出所代表的乳腺癌相关概念。根据行和列的聚类结果,相关酶的研究被分为6类,并由对应的列得出研究前沿热点。
第1类主要与肿瘤的遗传学研究相关,主要包含BRCA1 Protein,Protein-Serine-Threonine Kinases、Checkpoint kinase 2、Glutathione Transferase、Glutathione S-Transferase pi、Methylenetetrahydrofolate Reductase (NADPH2)、Aurora Kinases等概念。
第2类主要与肿瘤的分期、预后和扩散的研究相关,主要包含src-Family Kinases、Receptors、 Estrogen、Receptor、ErbB-2、Cyclooxygenase 2等概念。
第3类主要与肿瘤细胞运动、信号转导、肿瘤侵袭性等肿瘤的病理过程相关,主要包含Isoenzymes、Aromatase、NF-kappa B、Matrix Metalloproteinase 9、Matrix Metalloproteinase 2等概念。
第4类主要与肿瘤相关的酶活性、细胞扩散、信号转导和细胞凋亡的研究相关,主要包含Receptor、 Epidermal Growth Factor、Estrogen Receptor alpha、Phosphatidylinositol 3-Kinases、Proto-Oncogene Proteins c-akt、Extracellular Signal-Regulated MAP Kinases、Mitogen-Activated Protein Kinases等概念。
第5类主要与肿瘤的药物抵抗、药物作用下的酶活性及药物作用下的细胞扩散的研究相关,主要包含TOR Serine-Threonine Kinases、Protein-Tyrosine Kinases、PTEN Phosphohydrolase、Oncogene Protein v-akt、Mitogen-Activated Protein Kinase 3、Mitogen-Activated Protein Kinase 1等概念。
第6类主要与肿瘤细胞药物作用下的细胞凋亡及药物作用下的细胞扩散研究相关,主要包含有Proto-Oncogene Proteins c-bcl-2、JNK Mitogen-Activated Protein Kinases、p38 Mitogen-Activated Protein Kinases、NF-kappa B、Caspases、Caspase 3、Caspase 8、Apoptosis Regulatory Proteins、Poly(ADP-ribose) Polymerases、Proteasome Endopeptidase Complex等概念。
3.2 2012-2014年乳腺癌相关文献的双聚类结果
根据横和列的聚类结果,相关酶的研究被分为5类,如图2所示,并由所对应的列得出研究的前沿热点。
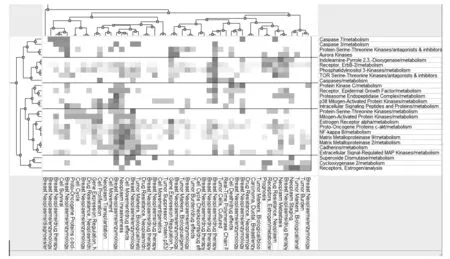
图2 双聚类可视化矩阵
第1类主要与肿瘤的药物疗法、药物作用下的细胞死亡、肿瘤细胞扩散和基因表达调节相关,主要包括Caspase 3、Caspase 7、Protein-Serine-Threonine Kinases、Aurora Kinases。
第2类主要与肿瘤的药物疗法、药物抵抗及肿瘤的代谢、分期和预后相关,主要包括Indoleamine-Pyrrole 2,3,-Dioxygenase、Receptor、ErbB-2、Phosphatidylinositol 3-Kinases、TOR Serine-Threonine Kinases、Caspases。
第3类主要与肿瘤的病理过程、肿瘤的侵袭性及肿瘤细胞死亡研究相关,主要包括Protein Kinase C、Receptor、 Epidermal Growth Factor、Proteasome Endopeptidase Complex、p38 Mitogen-Activated Protein Kinases、Intracellular Signaling Peptides and Proteins。
第4类主要与肿瘤标志物、肿瘤细胞扩散、肿瘤侵袭和细胞运动的研究相关,主要包括Mitogen-Activated Protein Kinases、Estrogen Receptor alpha、Proto-Oncogene Proteins c-akt、NF-kappa B、Matrix Metalloproteinase 9、Matrix Metalloproteinase 2、Cadherins、Extracellular Signal-Regulated MAP Kinases。
第5类主要与肿瘤标志物、肿瘤分期和预后的研究相关,主要包括Superoxide Dismutase、Cyclooxygenase 2、Receptors、Estrogen。
3 类团演变分析
通过双聚类算法对2009-2011年和2012-2014年乳腺癌相关酶研究相关文献的探索分析,可以发现乳腺癌相关酶的研究在前后两个时间段有细微的变化。计算不同时间段聚类结果形成的类团间的关联强度(P值)(表3)。将各类以类团的形式展现,按时间顺序排列并将明显相关的类团以线连接,线的粗细代表关系紧密程度(图3)。

表3 2009-2011年与2012-2014年各类团间的关联强度
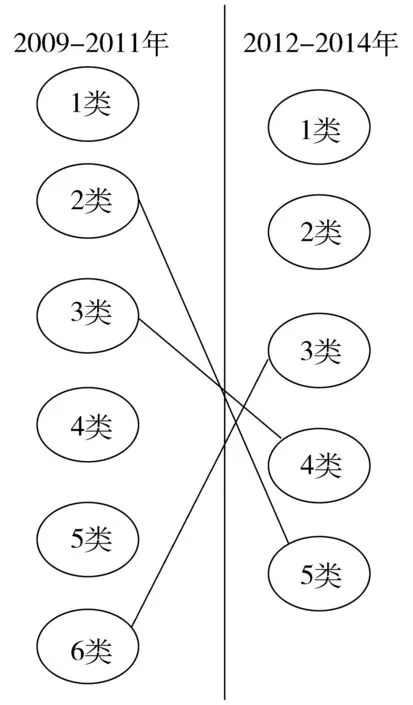
图3 类团变迁
当P在[0.3,0.5]时认为两个类团有演变关系。如图3中,第一阶段的2号类团与第二阶段的5号类团,主要与肿瘤的标志物和肿瘤的扩散相关,但是5号类团关于src-Family Kinases的研究相对减少而Superoxide Dismutase的研究增多;第一阶段的6号类团与第二阶段的3号类团,主要与肿瘤细胞的凋亡和细胞侵袭相关,但是6号类团更侧重药物作用下的相关研究,而3号类团关于Proto-Oncogene Proteins c-bcl-2,Caspase 8及JNK Mitogen-Activated Protein Kinases的研究减少而Protein Kinase C的研究增多。 当P在[0.5,1]时认为两个类团有持续发展的关系。如图3中第一阶段4类和第二阶段的第4类都与肿瘤细胞间的信号转导和细胞运动相关,表明相关研究一直是热点。其中第一阶段的3号和4号类团融合成了第二阶段的4号类团后,说明研究更侧重肿瘤细胞的侵袭运动;第一阶段的1号类团(肿瘤遗传学相关研究)和5号类团(药物作用下的酶活性研究)在第二阶段少有研究,第二阶段的1号类团和2号类团较为新生,说明肿瘤的药物疗法研究受到关注。
4 结论
本文基于双聚类方法,对PubMed数据库中近期乳腺癌相关酶的研究分阶段进行共词双聚类分析,并进行类团演化分析,得出乳腺癌相关酶研究的前沿热点。其中关于癌细胞间的信号转导、细胞运动的研究一直处于热点地位,肿瘤遗传学方面的研究则相对减少,肿瘤药物疗法的研究相对增多。关于酶的研究有些一直处于热点,有些较为前沿。如Protein-Serine-Threonine Kinases(蛋白质-丝氨酸-苏氨酸激酶)、Aurora Kinases(极光激酶)、Cyclooxygenase 2(环氧酶2)、Matrix Metalloproteinase 9(基质金属蛋白酶9)、Matrix Metalloproteinase 2(基质金属蛋白酶2)、Phosphatidylinositol 3-Kinases(磷脂酰肌醇3激酶)、Extracellular Signal-Regulated MAP Kinases(细胞外信号调节MAP激酶类)、Mitogen-Activated Protein Kinases(促分裂素原活化蛋白激酶)、TOR Serine-Threonine Kinases(TOR 丝氨酸-苏氨酸激酶)、Caspases(半胱天冬酶)等的研究一直较为热点,而且关于Superoxide Dismutase(超氧化物歧化酶)、Caspase 7(半胱天冬酶7)、Protein Kinase C(蛋白激酶C)的研究在第二阶段较多,皆为有发展潜力的前沿。
本文证实双聚类的方法可以用于探测前沿热点的研究,与传统的共词方法相比,能够对类团的语义内容进行一定程度的标注,为科研工作者提供有益的指导。不过还发现一些问题:一是高频次阈值的确定对结果有一定影响。低阈值不利于聚类,但利于一些隐含主题的出现;高阈值相反,聚类效果好,但会忽视隐含的知识。因此,阈值选择还是一个有待深入研究的课题。二是共词分析中使用的词是人工阅读后选取的主题词,选取乳腺癌相关概念和乳腺癌相关酶时,受人为因素的干扰,可能对结果有影响;共词分析选取的是MESH字段,没有利用现有的语义网络工具,不能从更深的粒度对文献进行分析。今后应该结合医学领域的本体,实现更深层次的语义标注。
