人脑分类机理的构造性学习方法
2016-03-18赵莎莎
李 萍, 赵莎莎
(阜阳师范学院 信息工程学院,安徽 阜阳 236041)
人脑分类机理的构造性学习方法
李萍, 赵莎莎
(阜阳师范学院 信息工程学院,安徽 阜阳 236041)
摘要:构造性学习(CML)算法训练分类器对有些样本会有“拒认状态”,构造性学习算法中对这一状况的处理使用就近原则,然而,这种方法无法体现数据之间的联系.为了能更好地体现数据间的联系,提出了人脑分类机理的构造性学习方法(HB-CML).在测试阶段,把测试样本、训练样本都考虑进来,利用人脑对数据的自动分类机理,对“拒认状态”样本进行分类标记.同时,选取UCI数据集进行实验.结果表明:与CML算法相比,该方法的分类更为有效.
关键词:构造性机器学习;人脑分类;覆盖算法
构造性机器学习通过在样本集C上寻找一组覆盖簇,使这些覆盖簇把不同类别的数据点分隔开来[1].这种方法比较容易构造网络且能高效地处理多分类问题[2].然而,在利用标记样本训练分类器时无法考虑到测试样本的数据特点及其与标记样本间的数据关系,从而导致在对测试样本进行标记时可能会出现“拒认状态”的样本.传统的覆盖算法在对拒认样本进行标记时是按照就近原则进行标记的,仍然是只考虑了已标记样本的数据特点,忽略了未标记样本的数据信息,从而影响其分类效率.
Zhu等人经过研究发现,人脑在对空间中的样本进行分类时,自觉地考虑了未标记样本的空间位置,可以说是一种半监督分类模式[3].考虑到未标记样本的数据信息,提出了人脑分类机理的构造性学习方法.该方法在应用已标记样本数据信息的同时,还考虑了未标记样本的数据信息,及已标记样本和未标记样本间的位置关系,从而提高机器学习的效率.
1覆盖算法
覆盖算法步骤:
输入:已标记样本C,即训练样本
输出:覆盖簇{F(i)}
(1)将C中的点投影到以原点为中心、以R′为半径的球面上,其中R′需要大于训练样本C中样本模的最大值;初始化i=1;k为不同类别数;
(2)构造第i个覆盖F(i);
1)若C(i)中点全部被覆盖住,转(3),否则,任取C(i)中还没有被覆盖的点ct;计算
作以ct为中心、b=d(t)为阈值的覆盖F(ct);C(i)表示第i类样本集.
2)把F(ct)所覆盖的所有点的重心计算出来,并将其也映射到以原点为中心、以R′为半径的球面上,设ct′为投影后落在球面上的点,用上述同样的方法求出ct′的球形领域F(ct′);
3)若F(ct′)覆盖的点数比F(ct)所覆盖的点数多,则令ct′→ct,b′→b,转2),否则,转1);
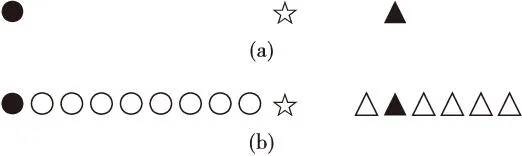
(3)若i 覆盖算法对测试样本标记时按照就近原则进行,对于“拒认状态”样本也是通过计算到各个覆盖领域的距离按照就近原则进行标记的,这种方法忽略了未标记样本的数据信息,这部分数据资源被浪费了,把大量无标记样本的数据信息特征加入到分类器的测试阶段可以优化分类效果. 2人脑分类机理的构造性学习方法 2.1人脑自觉分类机理 图1 二分类问题 Zhu等人经过研究发现,人脑在对空间中的样本进行分类的时候,自觉地考虑了未标记样本之间已经与已标记样本之间的空间位置关系,我们用图1简单说明人脑的这种分类机理,以二分类为例.图中“●”和“▲”分别表示两种不同类别的已标记样本,“○”和“△”分别表示相应类别的未标记样本,“☆”表示待测定的未标记样本,(a)中有两个标记样本和一个待测定样本,(b)中除了有两个已标记样本和一个待测定样本外,要有一些未标记样本.(a)和(b)中的待测定样本到两个标记样本的距离相同,但是通过观察人类大脑会把(a)中的“☆”归为“▲”类,而把(b)中的“☆”归为“●”类. 可见人脑在对待测定样本进行标记时,除了利用待测样本与各已标记样本的距离,还考虑了未标记样本的位置,这种测定更有说服力[4]. 2.2人脑分类机理的构造性学习方法 本文根据人脑自觉考虑未标记样本的分类机理,提出了人脑分类机理的构造性学习方法,其主要价值体现在分类器的测试阶段,在对“拒认状态”样本进行标记时,自觉地考虑了已标记样本、未标记样本的空间位置,及它们与“拒认状态”样本的位置关系,来确定其类别. 人脑分类机理的构造性学习算法流程: 输入:已标记样本集L,待测样本集U; 输出:待测样本集U的类别. (1)利用覆盖算法训练分类器,即覆盖簇; (2)对U中的各个待测样本,计算它们是否被覆盖住,若全部被覆盖住即没有“拒认状态”样本,那么按照覆盖簇的类别对这些待测样本进行分类,算法结束.否则,记“拒认状态”样本集为R,x为R中任一样本,记S为空集,转(3); (3)计算L、U两组数据集中距离x最近的样本y,若y∉R,将x及S中的样本标记成与y相同,将x及S移出R,令S为空集,转(4),否则将x移出U,令S=S∪{x},令x=y,转(3); (4)若R为空集,算法结束.否则,令x为R中任一样本,记S为空集,转(3). 3实验结果及分析 表1 5种数据集及正负样本比例 表2 两种算法分类正确率 从UCI中选了5种数据集作为实验对象,如表1所示,对于各个数据集,我们选出75%作为训练样本,剩下的25%作为测试样本. 采用本文提出的人脑分类机理的构造性学习算法(HB-CML)和采用CML得出的分类正确率结果如表2所示.从表中可以很容易地看出,应用人脑自觉分类策略后的覆盖算法相对于CML的分类效果得到了普遍提高.这说明本文提出的基于人脑分类机理的覆盖算法,能够利用已标记样本和待测试样本,以及它们之间的空间几何关系,对“拒认状态”样本进行合理标记,从而提高分类器的分类精度. 4结语 本文利用人脑自觉分类机理的思想,根据待测试样本与已标记样本之间的空间几何位置关系,给出了一种基于人脑分类机理的构造性学习方法,并以UIC数据为例,通过实验说明该方法能够有效提高分类率.但是,该算法还存在不足的地方,对某些数据集来说,分类正确率提高的并不显著.还需要继续对“拒认状态”样本进行研究,同时更深地研究人脑自觉分类机理,从而进一步提高该算法的性能. [参考文献] [1]张铃,张钹.多层前向网络的交叉覆盖算法[J].软件学报,1999,10(7):737-742. [2]王伦文,张铃.构造性神经网络综述[J].模式识别与人工智能,2008,21(1):49-55. [3]ZHU X J,TIMOTHY R,RUICHEN Q,et al.Humans perform semi- supervised classification too[C]∥ Proceedings of the 22nd National Conference on Artificial Intelligence.Menlo Park,Calif:AAAI Press,2007:864- 869. [4]李昆仑,曹铮,曹丽苹,等.半监督聚类的若干新进展[J].模式识别与人工智能,2009,22(5):735-742. [责任编辑马云彤] Constructive Learning Method Based onClassification Mechanism of Human Brain LI Ping, ZHAO Sha-sha ( School of Information Engineering, Fuyang Teachers College, Fuyang 236041, China ) Abstract:“Refusing to be classified” test examples will be produced using Constructive Machine Learning (CML) algorithm and the examples will be labeled according to principle of proximity, however the connections between data is ignored. So a constructive learning method based on human brain algorithm (HB-CML) is designed to reflect the connections between labeled and unlabeled samples. During the testing phase, the“refusing to be classified” test examples are labeled by automatic data classification mechanism of human brain using labeled and unlabeled samples. At the same time, experiment is conducted on UCI data set and results show that the algorithm is more effective than the CML algorithm. Key words:constructive machine learning; classification based on human brain; covering algorithm 中图分类号:TP18 文献标志码:A 作者简介:李萍(1985—),女,安徽阜南人,阜阳师范学院信息工程学院讲师,硕士,主要从事智能计算及其应用研究. 基金项目:阜阳师范学院校级项目(2015FSKJ13);阜阳师范学院信息工程学院院级项目(2015FXXZK01) 收稿日期:2015-07-12 文章编号:1008-5564(2016)01-0045-03