车载环境下语音增强的研究
2016-03-17景新幸
李 俊 周 萍 景新幸
1(桂林电子科技大学电子工程与自动化学院 广西 桂林 541004)
2(桂林电子科技大学信息与通信学院 广西 桂林 541004)
车载环境下语音增强的研究
李俊1周萍1景新幸2
1(桂林电子科技大学电子工程与自动化学院广西 桂林 541004)
2(桂林电子科技大学信息与通信学院广西 桂林 541004)
摘要针对车载环境下语音系统受到外界强噪声的干扰而导致识别精度降低以及通信质量受损的问题,提出一种自适应MMSE-LSA估计与TEO(Teager Energy Operator)能量端点检测相结合的语音增强算法。TEO端点检测可以将语音分为语音段和非语音段,从而在噪声估计时可以更好地跟踪噪声的变化,得到更加准确的先后验信噪比,使增强后的语音最大限度地接近纯净语音,而且对车载噪声的增强效果比其他噪声更好。在车载环境中进行实验,结果显示该方法与MMSE-LSA以及传统的谱减法相比,提高了输出信噪比,减弱了音乐噪声,在可懂度和清晰度方面均具有优势。
关键词车载噪声信噪比TEO端点检测语音增强
RESEARCH ON SPEECH ENHANCEMENT ALGORITHM UNDER ON-BOARD ENVIRONMENT
Li Jun1Zhou Ping1Jing Xinxing2
1(School of Electronic Engineering and Automation,Guilin University of Technology,Guilin 541004,Guangxi,China)2(School of Information and Communication,Guilin University of Technology,Guilin 541004,Guangxi,China)
AbstractVoice system could be disturbed by external strong noise under on-board environment, which will lead to decline in accuracy of recognition and damage of communication quality. In order to solve this problem, we proposed a speech enhancement algorithm combining adaptive MMSE-LSA estimation and TEO (Teager energy operator) endpoint detection. According to TEO endpoint detection method, speech can be divided into voice segment and non-voice segment so that in noise estimation the changes of noise can be better tracked and more accurate priori SNR and posterior SNR can be gained as well, this makes the enhanced speech sufficiently approach the original speech. In addition, TEO endpoint detection has a much better effect in enhancing vehicle noise than any other noises. Experiment was carried out under on-board environment, results showed that this method, compared with MMSE-LSA estimation and traditional spectral subtraction, improved the output SNR, reduced the music noise, and had the advantages in both intelligibility and clarity.
KeywordsOn-board noiseSignal-to-noise ratioTEOEndpoint detectionSpeech enhancement
0引言
在汽车内部由于动力系统的运行产生的齿轮啮合,高速行驶时车轮与地面和空气的摩擦以及其他振动源共同形成了车载噪声[3]。车载语音通信难免会受到噪声的干扰,带有很强的背景噪声的语音信号很难被车载语音系统识别,必须对车载语音进行增强处理,消除背景噪声,提高汽车中语音通信的质量和车载系统的识别率。
传统的谱减法、维纳滤波法、最小均方差估计法在去除背景噪声方面有很好的效果,但是有的时候会造成语音的失真或者产生强烈的音乐噪声[2,4]。通过研究发现自适应MMSE-LSA估计算法对背景噪声抑制度高,使语音失真度低。
自适应MMSE-LSA算法是利用先验信噪比计算增益函数,从而得出纯净语音的估计值。因此对噪声的准确估计显得尤为重要,文中提出一种基于TEO能量端点检测的方法与其结合,实验证明这种算法可以更好地抑制音乐噪声,适用于车载环境中,对volvo噪声的去除效果明显。
1自适应MMSE-LSA算法描述
人耳对语音的感知主要依赖语音信号的幅度,而对其相位不敏感[10]。大量的研究发现语音具有短时平稳性,即在30 ms以内通常可以认为语音是稳态分布的,所以短时分帧处理为研究语音信号提供了很大的方便。把每一帧信号都近似认为是平稳信号来处理,MMSE-LSA正是估计出纯净语音的短时对数谱幅度[1]。然后利用人耳对语音相位不敏感的特性,用FFT变换时得到的原始语音信号的短时谱相位和估计的短时对数谱谱幅度重构语音信号,把重构的信号作为纯净语音信号[7,8]。MMSE-LSA估计算法在对语音增强的过程中会涉及到先验信噪比和后验信噪比的估算。随着对噪声估计结果的变化,需要对信噪比进行及时更新,由于在先验信噪比的估算中引入了调节系数α,通常对其值设定一个范围,根据多次试验的结果确定一个经验值。但这种方法难免使其适应性减弱,可能不同的环境中,不同的信噪比时若继续使用相同的值就会造成语音失真或者产生过多的音乐噪声,需要对α 值及时更新。自适应MMSE-LSA则是采用先验信噪比的最小均方差,根据噪声的变化,得到α在不同噪声情况下的最优值即自适应效果。
用x(n),d(n)和y(n)分别表示纯净语音,噪声和带噪语音,文中研究的噪声是指语音中的加性噪声。则:
y(n)=x(n)+d(n)
(1)
式(1)经过FFT变换之后可得:
|Y(n,k)|2=|X(n,k)|2+|D(n,k)|2
(2)
其中,|Y(n,k)|2,|X(n,k)|2和|D(n,k)|2分别表示带噪语音,纯净语音和噪声的短时谱幅度则:
Y(n,k)=|Y(n,k)|∠θy
(3)
X(n,k)=|X(n,k)|∠θx
(4)


(5)
又由文献[1]知:
|X(n,k)|=G(n,k)|Y(n,k)|
(6)
其中:
(7)
其中,ξ(n,k)是语音信号的第n帧第k个频率点的先验信噪比,定义为:
(8)
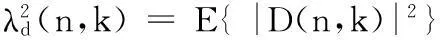
(9)
从式(7)得知要计算出增益函数就必须知道先验信噪比,从而才能估计出纯净语音,能否准确地估计出先验信噪比将关系感到语音增强的效果。传统MMSE-LSA估计对先验信噪比的估计采用直接判决法。
(10)
式中,α根据经验其取值范围为[0.8,1],ε是一个无限接近0的正实数,γ[n,k]是后验信噪比(SNRpost(n,k)),定义如下:
(11)
由文献[5]可知先验信噪比估计公式的另一种表示方式为:
(12)

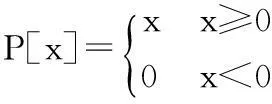
(13)
式(13)是一个半波整流函数。
(14)
由式(12)和式(14)可以得到下式:

(1-α(n,k))2·(ξ(n,k)+1)2
(15)
对M求导,并假设∂M/∂α[n,k]=0,则可以求出α的最优解:
(16)
2基于TEO的语音端点检测
语音信号由语音段和噪声段共同构成,用端点检测的方法将其区分出来再增强处理效果更明显[12]。谱减法以及基于谱减法的改进方法,在语音的增强过程中对噪声的估计都是选取带噪语音的开始几帧能量谱的平均值或者加权平均值,即一般情况下认为语音的开始部分只存在噪声不存在语音,但是这种假设对平稳噪声环境中具有一定的适用性。对车载环境中的语音增强需要考虑到汽车在行驶的过程中,产生的车载噪声随着汽车所处的外界环境不同,并不是固定不变,实际上是非平稳的。用端点检测的方法检测出噪声段和语音段对噪声进行实时更新,才能使增强后的语音更真实。因此探寻一种适合车载环境的端点检测方法也是很关键的。经过试验的验证比较发现基于TEO的语音端点检测更适用于车载环境。
很多研究中都默认声音的模型就是平面波沿着管轴传播。然而TEO理论则认为语音的产生是非线性的,语音是由声道中的涡流和平面共同作用产生的,而且这一结论被流体力学所支持[9]。在连续信号x(t)中,TEO定义为:
ψ[x(t)]=(x′(t))2-x(t)x″(t)
(17)
当x(t)为离散时间信号时,其TEO能量可以近似表示为:
ψ[x(t)]=x(n)2-x(n-1)x(n+1)
(18)
由式(18)可知,离散x(t)的TEO能量不仅与自身有关而且还和其前一时刻后一时刻的值密切联系。自适应MMSE-LSA算法的性能好坏依赖于噪声估计,噪声估计的准确性又依赖于端点检测。基于TEO的端点检测相比短时能量和短时过零率方法准确率有很大的提高,相比谱熵法复杂度以及计算量都有很可观的降低[2]。
基于TEO是端点检测首先根据信号是离散的还是连续的通过式(17)或者式(18)求出带噪语音的TEO能量。对原是语音信号进行分帧加窗处理,对每一帧信号进行计算,求其TEO能量Ei,和传统的短时双门限一样,在端点检测时我们设定一个TEO能量值,作为门限。经过对带噪语音的TEO能量曲线的研究,设置门限L=Emin+Emean×0.1,当Ei大于L时则认为是语音段,反之为噪声段,其中Emin表示整段语音TEO能量的最小值,Emean表示整段语音的TEO能量均值。
把纯净的语音分别加入white、babble、factory、volvo各种噪声,形成-5、0、5、15 dB不同的信噪比的带噪语音,比较TEO能量端点检测方法在不同的噪声中的检测率,结果如图1所示。

图1 TEO能量端点检测在四种不同噪声中的检测率
从图1可以看出基于TEO的端点检测在不同的噪声环境中效果不同,对车辆噪声的增强效果与信噪比近似成正比例关系,随着信噪比的逐渐增大识别率直线上升。不仅在高信噪比时有较高的检测率而且在0 dB以下相对于其用于其他噪声环境中的检测率最高,说明该方法适应范围比较广稳定性高,综合考虑得出一个结论:基于TEO的端点检测方法很适合在车载环境中应用。
3实验结果
为了验证文中方法的性能,分别在MATLAB仿真环境下进行试验和在实际车载环境中通过车载识别系统测试识别率。将文中的算法与传统谱减法,MMSE-LSA估计作比较。试验采用的纯净语音信号采样频率为8 KHz,采样精度为16 bit,对信号进行分帧帧长为256,帧移为128。并使用噪声语音库NOISEX-92中的volvo.wav车辆噪声加到纯净语音中构成不同的信噪比的带噪语音,比较算法的性能,如表1所示。

表1 三种算法输出信噪比对比
从表1中的数据可以得知用传统谱减法增强后的输出信噪比与输入信噪比相比较提升了很多。然而相比于文中的方法和MMSE-LSA估计传统谱减法效果还是有一定的差距。关键是传统谱减法会带来比较严重的音乐噪声。谱减法采用噪声的统计均值代替当前帧的噪声,要是噪声估计值的更新不及时,当估计噪声小于某帧中所含有的噪声分量,相减之后就会残留噪声。在频谱上形成离散的谱峰,在时域中就表现为类似正弦信号叠加产生的音乐一样的噪声,比较刺耳,影响听觉的可懂度和清晰度,还会使人听觉产生疲劳,被称为“音乐噪声”。文中方法相对于MMSE-LSA在信噪比提升方面大概提高0.5 dB。但是由于传统的谱减法和MMSE-LSA算法都会在增强后的语音中引入较强的音乐噪声,通过文中的算法增强之后的语音在听觉感受上有明显的改善,清晰度和可懂度也提高了。图2以信噪比为0 dB为例,更加直观地显示出增强效果的差异,MMSE-LSA增强后明显残留较多噪声。
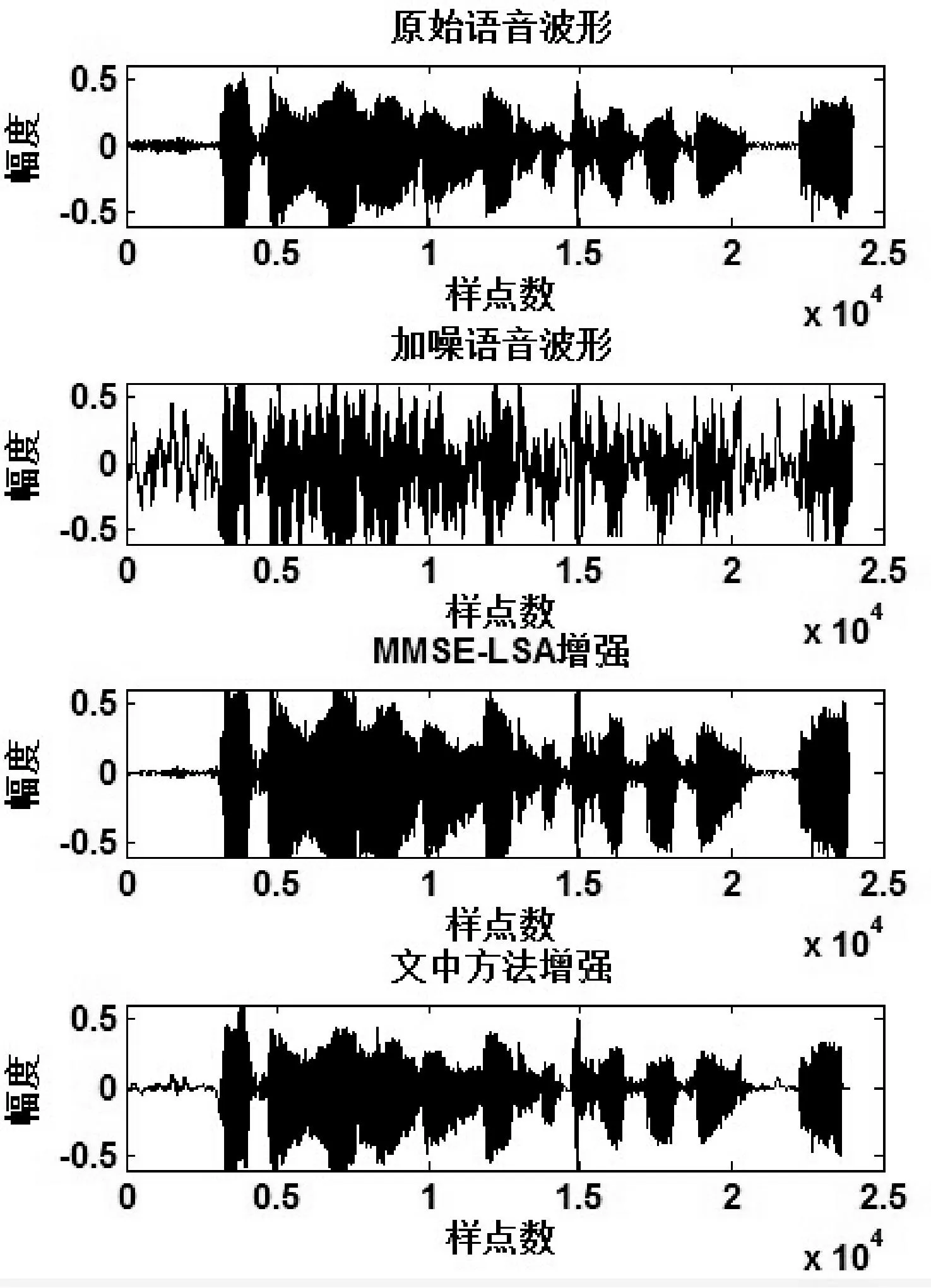
图2 文中方法与MMSE-LSA增强效果对比
研究增强算法的最终目的是为了提高车载语音识别系统的识别率,因此必须把文中的方法应用到实际的车载环境中检测其效果。测试的词语有录音、播放、停止、天窗、暂停、开门、关门、关窗、打开、关闭10个词。先让1名同学在实验室环境下进行训练作为参考模版,然后寻找10名同学作为测试对象,有男生也有女生,在真实的汽车环境中进行识别实验。每个同学以任意顺序说出上述10个词语并记录识别结果,重复上述操作10次,即每个词测试了100次。统计每个词的识别率,实验结果如表2所示。
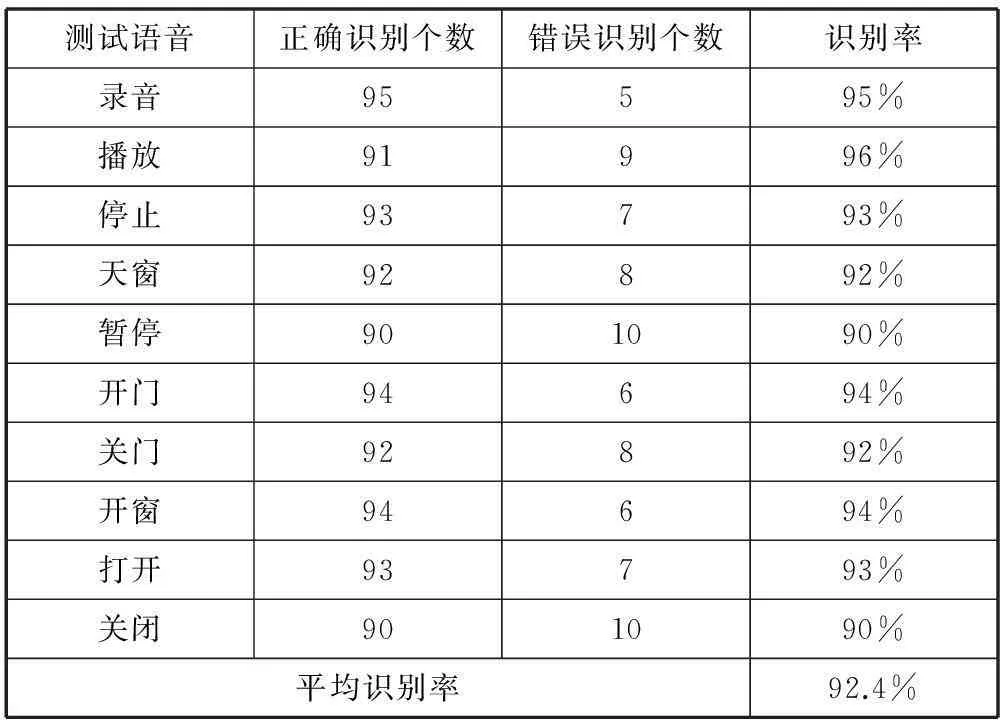
表2 各词语的识别率统计和比较
从表2中可以看出文中算法识别率达到92%已经很可观,通过上述实验文中方法不管是在仿真环境中,还是在实际车载环境中都取得不错的效果。
4结语
为了提高车载环境中语音通信的质量,本文提出自适应MMSE-LSA与TEO能量端点检测相结合的算法。通过在车载系统中的验证和与其他增强方法的比较表明本文方法对车载噪声有很好的增强效果。不仅提高了输出信号的信噪比和车载系统的成功识别率,而且增强后的语音在主观听觉感受上很好地抑制了音乐噪声。
参考文献
[1] 张鹏,张艳宁,付中华,等.基于MMSE-LSA语音增强算法在非平稳环境下的研究与实现[J].计算机工程与设计,2007,28(19):4695-4697.
[2] 赵欢,王纲金,胡炼,等.车载环境下基于样本熵的语音端点检测方法[J].计算机研究与发展,2011,48(3):144-147.
[3] 姚黎.车载语音识别系统的语音增强方法研究[D].武汉:武汉理工大学,2012.
[4] 姜占才,孙燕,王得芳.基于谱减和LMS的自适应语音增强[J].计算机工程与应用,2012,48(7):142-145.
[5] Ephraim Y,Malah D.Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator[J].Acoustics,Speech and Signal Processing,IEEE Transactions on,1984,32(6):1109-1121.
[6] Jia Hairong,Zhang Xueying,Jin Chengsheng.A speech enhancement method based on wavelet packet and hearing masking effect[C]//2010 2nd International Conference on Signal Processing Systems,2010:272-275.
[7] 徐耀华,郭英,范海宁.语音增强:使用burg谱先验信噪比估计消除“音乐噪声”[J].信号处理,2009,25(1):141-146.
[8] 李世绍,高勇.低信噪比下基于FastIca和MMSE-LSA的语音识别[J].电声技术,2014,38(1):62-65.
[9] Teager H M,Teager S M.Evidence for nonlinear sound production mechanisms in the vocal tract[M].Speech Production and Speech Modeling.Springer Netherlands,1990:241-261.
[10] 张雪英.数字语音处理及matlab仿真[M].电子工业出版社,2011.
[11] 朱兴宇,万洪杰.基于麦克风阵列的语音增强系统设计[J].计算机应用与软件,2013,30(3):240-243.
[12] 王劲松,李柏岩,宋辉.基于小波分解和信号相关函数的语音端点检测[J].计算机应用与软件,2011,28(7):103-104,124.
中图分类号TP391.42
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.02.031
收稿日期:2014-08-18。广西区自然科学基金项目(2012GXNS FAA053221)。李俊,硕士,主研领域:语音信号处理。周萍,教授。景新幸,教授。
