基于Lucene的Web服务查询系统设计与实现
2016-03-15叶骏宏,王勇,强保华
基于Lucene的Web服务查询系统设计与实现
引文格式: 叶骏宏,王勇,强保华.基于Lucene的Web服务查询系统设计与实现[J].桂林电子科技大学学报,2016,36(1):29-34.
叶骏宏,王勇,强保华
(桂林电子科技大学 计算机科学与工程学院,广西 桂林541004)
摘要:针对用户需求复杂多变,提出了用户反馈2阶段Web服务查询方法。该方法引入基于Lucene规范的Web服务搜索引擎系统,该系统由WSDL处理模块、向量化模块、相似度计算模块和QoS模块组成,分别支持WSDL解析功能、WSDL索引建立与查询功能、自定义权重计算功能和QoS功能。在解析加拿大Guelph大学的2507个真实WSDL文档集合基础上,筛选出符合Web服务功能标准的WSDL文档集,并对其进行服务索引建立和查询测试。实验结果表明,系统Web服务发现性能具有较高P@N值和NDCP值,验证了系统的可行性和有效性。
关键词:Web服务;用户反馈2阶段查询;WSDL;Lucene
随着以Web服务为基本单位的分布式计算模式SOC(service-oriented computing)产生和SOA(service-oriented architecture)技术的快速发展,互联网上的Web服务数量急剧增多,如何精准、高效地发现服务成为Web服务体系结构实现的一个重要任务,也是亟待解决的关键问题。目前,涌现出各式各样的Web服务发现技术。例如,针对服务中心单点故障和性能瓶颈,文献[1]提出了多中心对等架构Web服务注册系统;根据经典的向量空间模型,文献[2]提出了基于文本向量空间模型的Web服务搜索引擎系统;林文亮等[3]提出一种基于QoS感知的S-Skyline服务选择算法,对原子服务数量和组合服务搜索空间进行有效剪枝优化,使整个组合服务QoS达到或接近最优;郭得科等[4]基于宿主、服务和方法3个维度提出了三维QoS模型,该模型把QoS非功能指标作为维度并通过维度之间彼此正交且存在层次关系,完成Web服务的过滤和选择;李征等[5]把服务进行SVM分类,对分类后的领域服务集中进行面向主题聚类,该方法认为在一个主题相似的类簇中更容易发现兼容的服务以及可替代服务。
面对互联网上海量的Web服务描述文档(Web service description language,简称WSDL),用户无所适从。WSDL的价值不在于它本身,而在于是否满足用户需求。虽然用户的需求千变万化,但WSDL的功能操作始终是用户最直接的查询要求,即只有在满足用户业务逻辑功能需求的基础上,筛选出非功能质量高的Web服务才有意义。Lucene是一款高性能的可扩展的信息检索工具库,它能轻松地将搜索功能加入到任何系统框架[6]。为此,以用户的需求为主,提出一种基于用户反馈的2阶段Web服务发现方法,通过引入基于Lucene框架规范下的Web服务搜索引擎系统,支持WSDL的功能性和非功能性搜索,在满足用户查询业务功能需求条件下尽可能地满足非功能属性选择。该系统由WSDL处理模块、向量化模块、相似度计算模块和QoS模块组成,实现了WSDL索引简历和存储、QoS信息采集与计算、WSDL查询和匹配、WSDL解析与处理、WSDL文档相似度评分等功能。系统各个软件模块均使用开源软件实现,具有高可扩展性、开放性、可编程性和易维护性。
1用户反馈2阶段查询方法
1.1WSDL模型
现有的Web服务体系一般基于典型的3层模式:Soap消息传递机制(可跨平台);WSDL的服务描述标准(可对服务进行自描述);UDDI(universal description discovery and integration)对服务进行管理。现有的Web服务通常是一个WSDL文档,它是满足W3C系列规范的XML文档[8],用来描述和定位网络服务,其包含了Web服务的地址和描述、服务使用的数据类型和通信协议、服务提供的执行操作与操作参数等。而对于只关注服务功能的服务发现方法会更多关注WSDL与服务功能相关的部分,即描述信息、名称信息、操作信息和数据信息。
定义1单向量模型:Ms=〈N,D〉。其中:N为名称信息,包含服务名称、操作名称、消息名称和元素名称;D为描述信息,包含服务描述、操作描述、消息描述和元素描述。单向量模型对应自然语言查询,查询输入是纯文本信息,因此,需要把N和D的信息切成单个词放到同一向量,故名为单向量模型。
定义2多向量模型:Mm=〈F,I,O,Q〉。其中:F=〈Nf,Df〉,Nf为服务功能名称,由Service和Operation的名称组成,Df为服务功能描述,由Service和Operation描述组成;I=〈Ni,Ti〉,Ni为输入消息的名称,Ti为输入消息的类型;O为输出消息,定义与I相同;Q=〈Rq,Aq,Tq,Sq,Rq,Lq〉,分别代表响应时间、成功调用率、调用吞吐量、响应率、可靠度和处理时延6种非功能指标。多向量模型对应WSDL文档查询,查询输入是半结构化的WSDL文档信息。WSDL文档每个结构内容分布的特征不相同,因此,需要把F、I、O、Q四种结构切成的词放到不同向量进行计算,故名多向量模型。
1.2查询算法流程
基于WSDL模型,提出用户反馈2阶段服务查询方法,分别结合自然语言的非结构化查询和半结构化的WSDL查询,前者使用单向量模型表示,后者使用多向量模型表示。首先对用户的自然语言查询进行分词、过滤和变换等处理,以便于向量化模块建模和单向量服务库中服务的匹配,最终目的是为了返回相关度高的Web服务供用户选择。此时,用户可在候选服务列表中选取最满意的WSDL作为反馈信息进行第2阶段的查询,即半结构化的WSDL查询,通过与多向量服务库中服务的相似度计算,返回与此WSDL相似度高的Web服务集。图1为用户反馈2阶段Web服务查询流程。
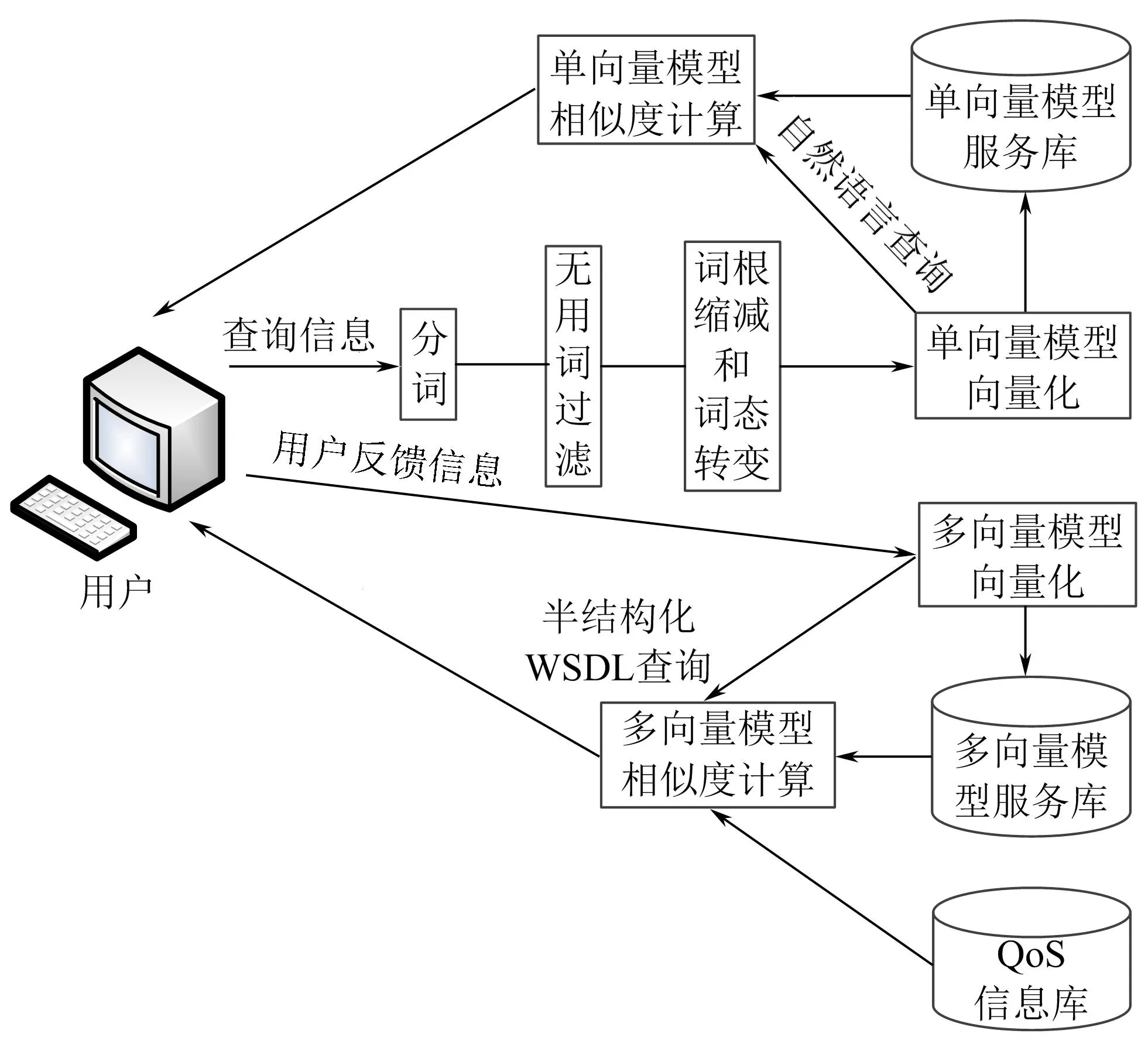
图1 用户反馈2阶段Web服务查询流程Fig.1 Flow chart of user feedback two-phaseWeb server discovery
2Web服务查询系统
2.1系统功能需求
基于用户反馈2阶段查询方法的Web服务查询系统满足的主要功能为:
1)从每一个注册的WSDL描述文档中抽取出服务功能描述信息,形成服务功能信息词集,并对其进行分词、过滤和变换,完成WSDL解析和处理。
2)为每个服务的功能信息词集建立单向量索引和多向量索引,并存储在数据库中,完成WSDL索引建立和存储。
3)定义多项非功能属性指标,为每一个注册入库的服务QoS进行采集和计算。
4)针对用户自然语言查询和WSDL半结构化查询,能够完成查询输入与单向量或多向量模型的匹配,最终返回用户满意度高的服务集。
5)灵活的相似度计算模块,自定义相似度计算方法完成服务文档的评分。
2.2系统模型
2.2.1系统网络模型
Web服务查询系统网络模型按照角色可分为Web服务使用方、Web服务提供方和Web服务中间方。Web服务提供方产生服务,通过开放对外接口提供给互联网用户有偿或无偿使用;Web服务使用方通过定位服务调用地址、使用服务;Web服务中间方是一个服务中心库,存储着大量Web服务描述和调用信息。中心库信息主要面向Web服务使用者,来源可通过互联网上采集或者服务提供方主动注册。图2为Web服务查询系统网络模型。
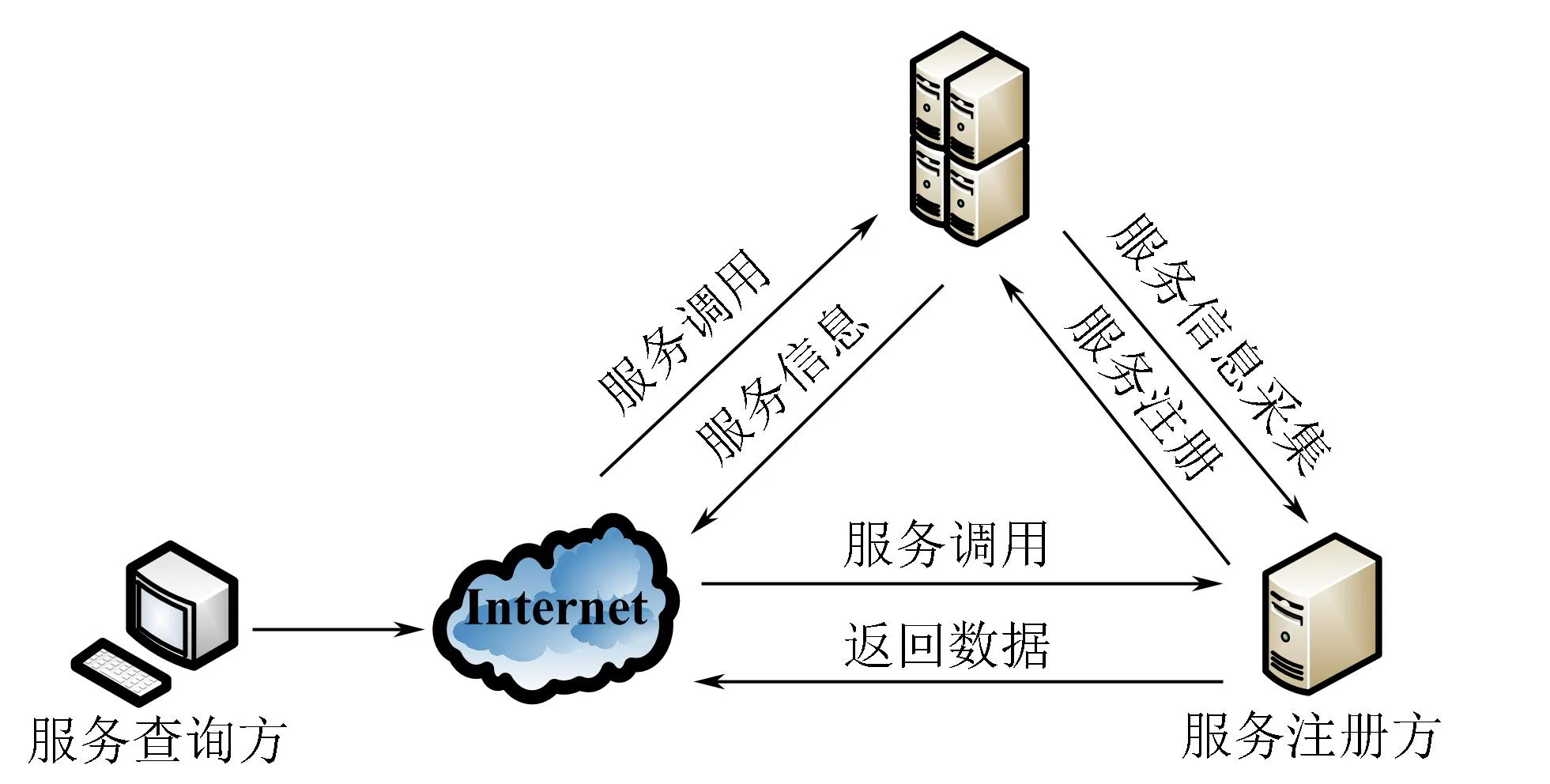
图2 Web服务查询系统网络模型Fig.2 Network model of Web service discovery system
2.2.2数据关系映射模型
Web服务查询系统是基于Lucene开源规范框架下开发的,系统主要功能包括WSDL服务信息的索引存储和索引查询。因此,需要了解WSDL结构和内容信息与Lucene标准索引数据格式之间的映射关系信息,以便于建立和查询索引接口程序的设计与开发。WSDL到Lucene数据关系单向量或多向量的映射分别如图3、4所示。
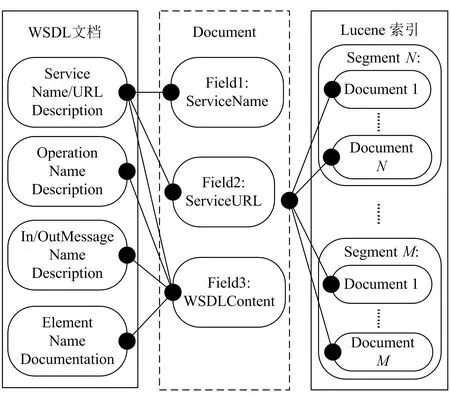
图3 单向量数据关系映射图Fig.3 Mapping of single vector data

图4 多向量数据关系映射图Fig.4 Mapping of multiple vector data
3Web服务查询系统框架
Web服务查询系统框架主要包括WSDL处理模块、向量化模块、相似度计算模块和QoS模块。系统面向服务查询者和服务注册者,提供不同的登录接口,不同的登录接口具有不同的操作权限。Web服务查询系统框架如图5所示。
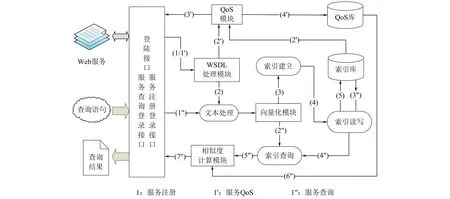
图5 Web服务查询系统框架Fig.5 Framework of Web service discovery system
3.1WSDL索引建立与存储
Web服务文档经过WSDL处理模块处理形成词集,然后向量化模块对词集进行索引建立后再存储。WSDL处理过程中的分词、变换和过滤可参照现有互联网上经典的算法,无法识别和滤除的需要加入人工标注。因此,为了得到具有代表性的Web服务词集,采用软件辅助工具和人工标注相结合的方法。伪代码描述如下。
Function:索引建立与存储
Input:WSDL文档集WSD
Output:Void(是否生成索引存入数据库)
1ArrayList〈wsdl〉WSD;
2IndexWriteriwriter;//存储索引类
3QoSWriterqwriter;//写QoS信息类
4QoSDataqdata;//QoS数据类
5FOREACHwsdliInWSD
6Definitiondefi=readWSDL(wsdli);
7qdata=collectQosData(defi.getAddress( ));
//QoS采集
8Documentdi;
9FOREACHattributejIndefi;
//抽取WSDL属性
10 di.add(Filedj(attributej));
11Fieldj=Analyzed(Filedj(attributej));//分词
12Fieldj=Stop_Filter(Filedj(attributej));//过滤
13Fieldj=Stem_Lemma(Filedj(attributej));
//变换
14CONTINUE
15qwriter.write(di.getID(),qdata);
16iwriter.addDocument(di);
17CONTINUE
18iwriter.commit();//写入索引
3.2WSDL服务索引查询
基于用户反馈2阶段查询分为自然语言查询和半结构化WSDL查询2个阶段。第1阶段是查询语句与文档的相似度匹配,目的是为了返回相关度高的文档集供用户选择,用户可选择一个满意的Web服务文档作为输入,进行第2阶段查询。伪代码描述如下。
Function:自然语言查询
Input:字符串Query
Output:评分从大到小的Document文档集
1StringQuery;
2Queryq=QueryParser.parse(Query);
//解析查询字符串,将查询q向量化成
//Document,Weight计算向量权重
3Documentdq=Scorer.Doc(Weight.creatweight(q));
4ArrayList〈IndexReader〉Simreader;
//单向量索引库
5ArrayList〈TopScorer〉tscorer;
//文档相似评分集,按分数从大到小排列
6FOREACHEsubReaderiInSimreader;
//读索引库
7Documentdi=subReader.getDocument(i);
8Scorersco=Similarity.score(dq,di);
//匹配评分
9tscorer.add(sco);
10CONTINUE
11RETURNtscorer.docs( );
第2阶段查询是文档与文档的相似度匹配,加入QoS属性满足用户非功能需求,最终目的是为了返回高质量的Web服务文档。伪代码描述如下。
Function:半结构化WSDL查询
Input:WSDL文档Documentd
Output:匹配度从大到小的Document文档集
1Documentdq;
2ArrayList〈IndexReader〉Mutil_reader;
//多向量索引库;
3QoSReaderqreader;//读QoS信息类
4Map〈DocumentScore,QosScore〉top_scorer;
//文档相似评分集,按分数从大到小排列;
5FOREACHEsubReaderiInMutilreader;
//读索引库
6Documentdi=subReader.getDocument(i);
7QosScoreqsco=qreader.getQosScore(di.getID( ));//获得该文档的QoS评分信息
8DocumentScorersco=Similarity.score(dq,di);
//文档相似度评分计算
9top_scorer.put(sco,qsco);
10CONTINUE
11RETURNtop_scorer.docs( );
4实验结果
4.1实验环境
Web服务查询系统部署在戴尔7910塔式工作站,该服务器拥有IntelXeonE5-2670 2.3GHz双处理器,32GB内存和1TB硬盘;系统在64位Windows7专业版操作系统上运行,采用JDK1.7+Eclipse4.3.2开发,MySQL5.0数据库,Tomcat7.0服务器,Lucene3.0.3开源项目,解析工具WSDL4J和软件架构SpringMVC。
数据集采用加拿大Guelph大学Ai-Masri等[9-10]收集的2507个真实WSDL文档集合,该集合每个服务都有相应的人工服务质量标注信息、具体调用地址和服务名称。系统通过WSDL4J解析该数据集,删除一些不符合算法要求的WSDL文档,例如,非英文描述的服务、信息不全的服务、无效服务等。然后,使用Lucene开源工具对每个服务信息块进行分词、词干提取和词态转变,再次剔除一些不符合功能信息描述的服务,如重复的服务、仅用于本地测试的服务、功能错综复杂的服务等,最后剩余1371个WSDL文档作为实验数据集。
4.2评价方法
针对系统2个阶段的服务查询有不同的评价标准。对于第1阶段的自然语言查询,使用搜索引擎的用户点击方式有其特殊性,一般用户更多关注返回的前N条服务。因此,对于此阶段实验采用P@N测试方法,用P表示。用Pm表示m个查询的平均P@N值,对特定的查询检测其前N条结果的准确率。
(1)
(2)
其中:m为查询数量;Ri为在第i个查询中返回的相关服务文档数量,0≤Ri≤N。
对于第2阶段的半结构化WSDL查询,可假设高相似的服务出现在结果列表越靠前就越有用,高相似的服务比低相似和不相似的服务有用。第2阶段实验采用NDCG(normalizeddiscountedcumulativegain)评价标准,衡量其DCG值与最佳DCG值接近程度来比较不同查询之间的效能。
实验为此阶段查询返回的服务制定5个相关性等级,分别为Perfect、Excellent、Good、Fair和Bad,对应5~1分,用r表示。
(3)
(4)
(5)
其中:p为返回的结果数量;ri为第i个结果的相关性等级;Npm为m个查询下的平均Np值;Dp、Np、Ip分别为返回p个结果下的DCG值、NDCG值、最佳DCG值。
4.3测试结果分析
系统2个阶段的测试都是基于平均查询值。自然语言查询进行15次,每次查询输入不同的查询主题,采用平均P@N值衡量系统的服务相关度。半结构化WSDL查询也进行15次,采用平均NDCG值反映服务匹配满意度。自然语言和半结构化WSDL查询性能如图6、7所示。
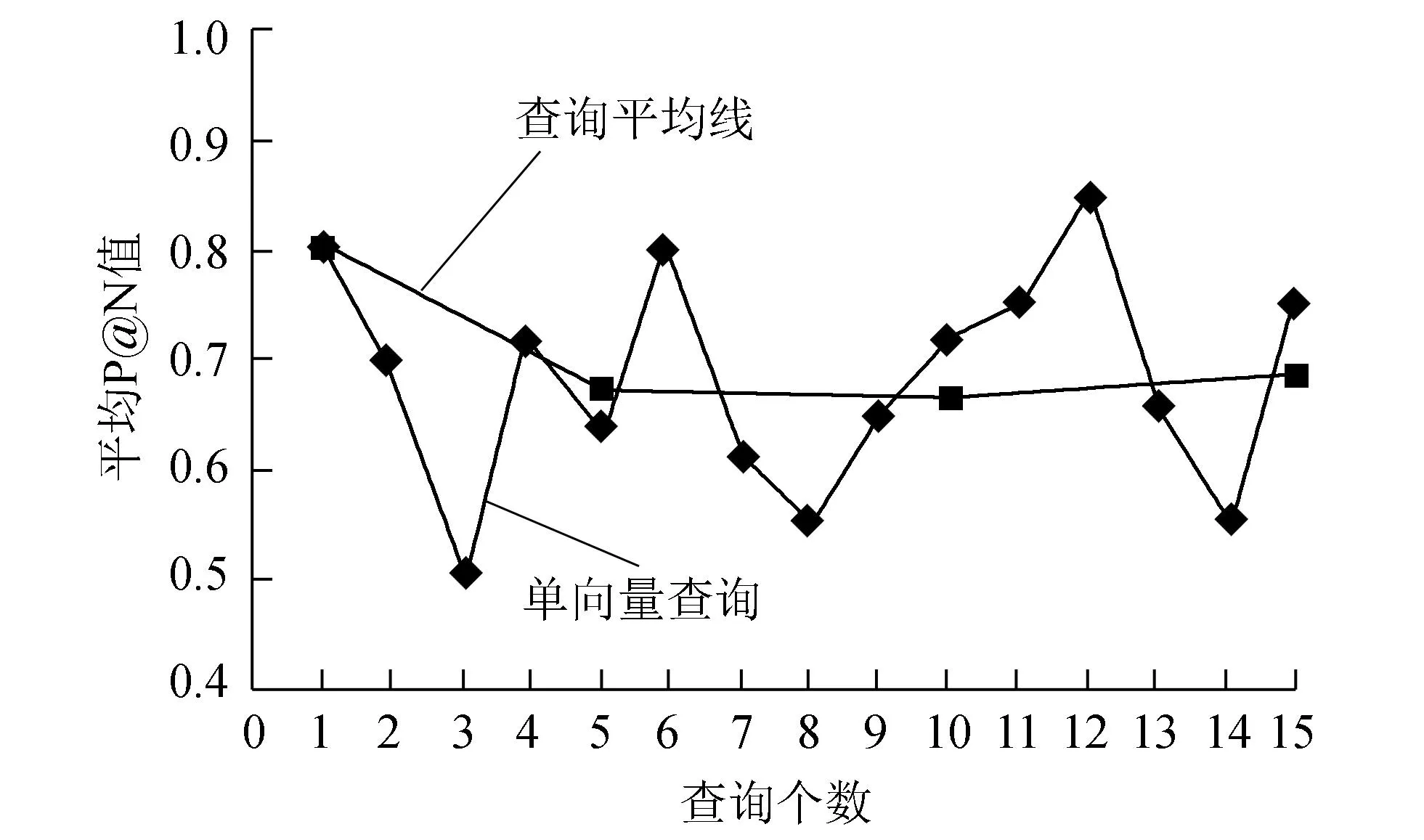
图6 自然语言查询性能Fig.6 Query performance of natural language
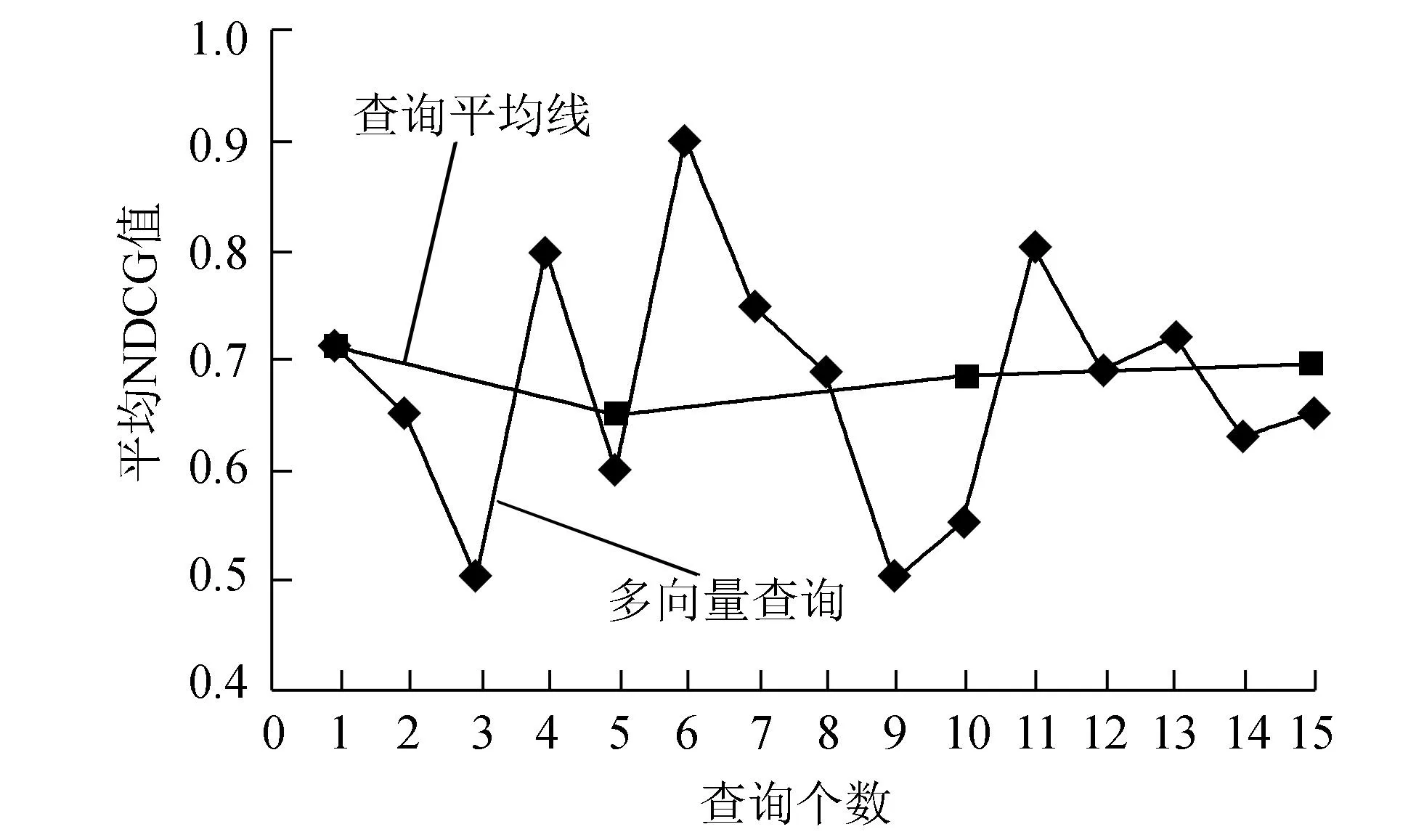
图7 半结构化WSDL查询性能Fig.7 Query performance of semi-structured WSDL
5结束语
针对Web服务发现性能问题,提出用户反馈2阶段查询方法,基于该方法引入基于Lucene的Web服务查询系统,通过实验分析和测试,系统的查询性能在用户需求多变情况下有一定的优势,下一步工作将建立面向海量服务的分布式架构。
参考文献:
[1]龙运坚,何倩,王勇,等.基于对等架构的Web服务注册系统[J].计算机应用,2014(7):1983-1987.
[2]PLATZERC,DUSTDARS.Avectorspacesearchengineforwebservices[C]//The3rdIEEEEuropeanConfonWebServices,2005:62-71.
[3]林文亮,王勇,何倩.基于QoS感知的S-Skyline服务选择算法[J].桂林电子科技大学学报,2014,34(6):464-468.
[4]郭得科,任彦,陈洪辉,等.一种QoS有保障的Web服务分布式发现模型[J].软件学报,2006,11:2324-2334.
[5]李征,王健,张能,等.一种面向主题的领域服务聚类方法[J].计算机研究与发展,2014(2):408-419.
[6]MICHAELM,ERIKH.Lucene实战[M].牛长流,肖宇,译.北京:人民邮电出版社,2011:4-5.
[7]BELLWOODT,CLEMENTL,EHNEBUSKED,etal.UDDIspectechnicalcommitteespecification[EB/OL].(2002-07-19)[2014-03-15].http://www.uddi.org/pubs/uddi-v3.00-published-20020719.htm.
[8]CHRISTENSENE,CURBERAF,MEREDITHG,etal.Webservicesdescriptionlanguage(WSDL)1.1 [EB/OL].(2001-05-15)[2014-03-15].http://www.w3.org/TR/wsdl.
[9]AI-MASRIE,MAHMOUDQH.Discoveringthebestwebservice[C]//The16thInt’lConfonWorldWideWeb,2007:1257-1258.
[10]AL-MASRIE,MAHMOUDQH.QoS-baseddiscoveryandrankingofwebservices[C]//ProceedingsofIEEE16thInternationalConferenceonComputerCommunicationsandNetworks,2007:529-534.
编辑:梁王欢
Design and implementation of Web service discovery system based on Lucene
YE Junhon, WANG Yong, QIANG Baohua
(School of Computer Science and Engineering, Guilin University of Electronic Technology, Guilin 541004, China)
Abstract:A two-phase Web service discovery method based on user feedback is proposed for the complex user requirements. Web service discovery system based on Lucene is introduced, it consists of WSDL processing module, the vectorization module, similarity calculation module and QoS module. The system supports the function of WSDL parsing, WSDL indexing and querying, custom weighting and QoS. Finally, with the real 2507 WSDL documents from Guelph University, a proper Web service discovery test collection is constructed to test the query performance of system. The experimental results demonstrate that the system has higher value of P@N and NDCP, which validates its feasibility and efficiency.
Key words:Web service; user feedback two-phase query; WSDL; Lucene
中图分类号:TP312
文献标志码:A
文章编号:1673-808X(2016)01-0029-06
通信作者:王勇(1964-),男,四川阆中人,教授,博士,研究方向为计算机网络技术与应用、信息安全。E-mail:ywang@guet.edu.cn
基金项目:国家自然科学基金(61163057,61163058);广西自然科学基金(2012GXNSFAA053228);广西可信软件重点实验室开放基金(KX201308)
收稿日期:2015-04-20
