数字仪表信息的自动提取方法*
2016-03-15胡成军马旭勃
胡成军 衡 军 马旭勃
(海军潜艇学院 青岛 266042)
数字仪表信息的自动提取方法*
胡成军衡军马旭勃
(海军潜艇学院青岛266042)
摘要利用计算机视觉自动提取数字仪表信息具有现实工程意义。针对采用液晶屏显示多种字体、包括非数字字符集的数字仪表,引入通用光学字符识别引擎用于仪表信息自动提取。为提高识别的准确率、实时性和鲁棒性,从图像获取、图像处理、识别引擎定制以及有效性判断等方面采取相应措施。
关键词计算机视觉; 光学字符识别; 数字仪表; 图像处理
An Automatic Data Extraction Method for Digital Meters
HU ChengjunHENG JunMA Xubo
(Navy Submarine Academy, Qingdao266042)
AbstractFor those digital meters which adopt LCD screen and output information including non-digital characters using various fonts, an automatic data extraction method is proposed with the introduction of general optical character recognition engine. To meet the real-time and robustness demand and to improve the accuracy of recognition, various measures related with image acquisition, image processing, customization of optical character recognition engine and results validation are described.
Key Wordscomputer vision, optical character recognition, digital meters, image processing
Class NumberTP391
1引言
数字仪表已在各行业得到了广泛应用,出于成本控制或设计原因,仍有相当多的仪表不提供程控接口。实际应用中,常常会有需求将这些仪表的数据采集到计算机系统中进行后续处理。手工录入不仅费时费力易出错,而且无法胜任长时间、高频度的工作需求。这种情况下,基于计算机视觉技术,通过数码摄像实时捕获仪表读数的图像,经图像处理、图像识别后自动提取出数值信息成了一个必然选择。
文献中已有大量数字仪表图像识别方法相关的研究[1~3],这些工作多集中在利用仪表显示的特殊性(如7段数码管形式)基于模板匹配或特征统计方法设计新的分类识别算法。这些算法具有很强的针对性。但当仪表采用液晶屏显示各种字体风格、包括标点符号等少量非数字字符在内的信息时,上述方法将无法使用。
为此,本文引入通用光学字符识别(optical character recognition,OCR)技术来实现数字仪表信息的提取。通用OCR技术的优点是能够识别多种字体、更大的字符集,缺点是识别的准确率、实时性难以保障。由于提取的仪表信息通常需要用于后续的自动化处理,因而对识别的准确率、实时性要求很高。本文给出了一个包括图像获取、图像处理、OCR引擎定制、有效性判断在内的利用OCR技术实现计算机视觉自动提取数字仪表信息的方法,使用效果显示了该方法的有效性。
2总体设计
利用计算机视觉自动提取仪表信息所需要的硬件包括一个高清摄像头和与之相连的通用计算机。摄像头稳定地固定在数字仪表上方以捕获仪表图像。摄像头的分辨率、成像质量对于仪表信息提取的准确率具有至关重要的影响。通用计算机运行相应的图像获取、分析和识别软件。多数情况下,仪表信息的后续处理也在同一台计算机上运行。
软件结构上,仪表信息获取软件可分成如图1所示的三层结构:

图1 仪表信息获取软件的三层结构
图像获取模块通过特定编程接口驱动摄像头获取仪表的彩色图像,从中分割出包含且仅包含待识别文字信息的子图像转发给上一层。图像处理模块位于中间层,经过转换为灰度图像、图像降噪、图像增强、二值化等一系列过程获得最终待识别的黑白图像。最后利用通用OCR引擎从图像中识别出仪表文字信息,经过有效性判断后将合法信息转发给后续处理模块。层次结构的优点是每一层的模块都是可替换的,可以方便地尝试不同的图像处理、识别算法组合。
仪表信息获取软件可以封装成可独立运行的程序,通过进程间调用方式与其它程序交换信息,也可以接口库的形式存在,其它程序通过编程接口直接调用。后者执行效率高,也更为灵活。我们采用了后一种实现方式。
3图像获取
3.1视频采集接口库的选择
图像获取的基本方式是通过调用视频采集接口库实时捕获仪表视频,然后根据需要或者定时从视频流中抓取图像帧。不同的视频接口库对于图像获取的速度、质量等都有较大影响。
在Windows平台上,目前主要有两种视频采集技术。一是传统的VFW(Video for Windows)库。VFW库与硬件设备无关,通用性强,但性能稍差。二是最新的DirectShow技术。它采用面向流媒体的架构,提供了高质量的多媒体流回放和捕获功能,能直接控制底层硬件设备,支持硬件加速,是目前Windows平台上性能最好的视频回放采集库。
我们硬件方案中使用了HD Pro Web Cam C920便携式摄像头。若使用传统的VFW技术,只能采集到640×480分辨率的图像。得益于DirectShow技术的采用,不仅可以设置曝光、白平衡、亮度、对比度、清晰度等摄像头属性,还能以每秒24帧的速率获得1920×1080分辨率的图像。这对后续的文本字符识别是非常重要的。
3.2摄像头校准
摄像头的基本原理是小孔成像模型,不可避免地会引入图像的扭曲变形。如式(1)采用齐次坐标系描述了从三维世界坐标系到二维像素坐标的投影变换:
(1)
上式中,[xyz1]T代表三维空间中的点,[uv1]T是投影的像素点。矩阵A称为摄像头的内部参数,由光学中心、焦距等固定不变的参数组成。旋转和平移矩阵R、T建立了从世界坐标到摄像头坐标系统的映射,称为摄像头外部参数。外部参数与摄像头的空间姿态有关,是图像产生径向、切向扭曲变形的主要原因。
摄像头校准[4]的关键是求解摄像头的内部、外部参数。基本方法是利用摄像头获取特定图案(如黑白格棋盘)在不同位置的多幅图像,然后基于上述几何投影公式解方程组[4]。只要摄像头位置不变,只需校准一次,获得的摄像头内外部参数矩阵可以保存下来一直用于修正后续扭曲变形的图像。
图像的扭曲变形与摄像头的质量、空间姿态有关。不同的OCR算法对图像变形的容忍度不同。毫无疑问,提供可选校准摄像头功能是有意义的。
3.3识别区域的确定
摄像头获取的原始图像通常包含了不相关的内容,我们感兴趣的区域(Region of Interest,ROI),即待识别的文字区域只占一小部分。图像获取的最后一步是将识别区域分割出来。
尽管可以实现算法自动确定识别区域,例如多数OCR引擎具备布局分析功能,能针对常见的书籍杂志等布局分割出可识别的文字块和不可识别的图像块,但由于ROI往往不包括全部的可识别文字块,利用算法自动确定ROI并不可靠。同摄像头校准一样,对于仪表读数提取而言,识别区域只需指定一次即可。因此,实践中更有效的方法是由用户手工框选出需要识别的区域。
ROI对应的子图像是图像获取模块的最终结果。由于大多数OCR引擎对识别图像的最小分辨率有要求。当图像分辨率不足时,还需要采用图像上采样技术利用插值增大图像的像素数。但此时更合理的作法是确保能对焦的前提下使摄像头靠近仪表。
4图像处理
OCR算法的识别对象是黑白图像。已有的OCR引擎,或者不能处理彩色图像,或者利用其缺省图像处理算法先转换为黑白图像后再进行识别。由于图像获取的方式、环境等千差万别,单一的图像处理算法不可能适应所有应用,后者往往难以得到高识别率。利用通用OCR引擎提取仪表数据的关键之一是实现专用的图像处理算法。
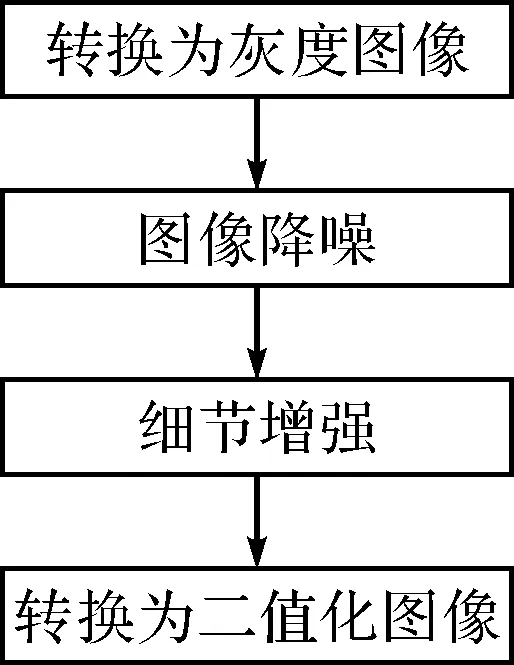
图2 图像处理流程
每个OCR引擎的识别算法各不相同,对理想的待识别图像要求也不相同。实现合适的图像处理算法依赖于对OCR识别特征的理解和实践中的反复测试。尽管针对每个OCR引擎的图像处理算法细节不会完全相同,但大体处理流程是相似的。
我们的应用中采用了如图2所示的一系列图像处理过程。
4.1转换为灰度图像
图像处理的第一步是将RGB彩色图像转换为256阶灰度图像。基于人眼对三元色敏感度的不同,颜色空间的转换常常采用如下算法[5]:
Y=0.299*R+0.587*G+0.114*B
(2)
其中,R、G、B是每一像素点颜色的红、绿、蓝分量,Y是灰度图像中灰度颜色值,取值为0~255。
在仪表图像中常常只存在两种固定不变的主体颜色:背景色和前景色。我们希望转换后的灰度图像中前景和背景灰度色差最大。因此,只需考察原始图像中的红、绿、蓝通道,取其中前景、背景差别最大的通道色分量作为灰度值即可。
4.2图像降噪
图像噪声通常作为空间上不相联系的离散和孤立的像素出现,通常具有相对更高的空间频率频谱。因此,对于噪声清除,简单的低通滤波器是很有效的。由于图像中的文字部分同处于频谱的高频段,降噪算法多少会使得文字细节变得模糊。选择图像降噪算法必须非常谨慎。降噪算法的选择不能依靠人眼对降噪效果的主观判断,而应该建立在对最后OCR识别的准确率是否有提高上。
常用的图像降噪算法[6]包括均值滤波、中值滤波、基于形态学开闭运算的滤波等。由于我们选择的OCR算法以文字的形状结构为模式特征,对噪声并不是太敏感,因此在实际应用中,我们采用了窗口大小为3*3的均值滤波算法。均值滤波是最简单、运算速度最快的线性滤波算法,小的邻域窗口不会对图像中文字的细节部分造成破坏,另一方面,对图像中孤立的噪声点有较好的抑制削弱作用。在最后的图像二值化阶段,大多数被削弱的噪声像素会被清除。
中值滤波是一种非线性滤波技术。它将像素点的灰度值设置为邻域窗口内的所有像素点灰度值的中值。中值滤波需要对邻域窗口内的像素值进行排序,因此执行开销较大。实际测试中,中值滤波算法对于OCR算法识别率并没有改善。而采用基于形态学开闭运算的降噪算法时,甚至会降低OCR算法的识别率。原因可能是待识别的字符形状和尺寸差异较大,很难选择合适的结构元素,结果导致或者没有什么降噪效果,或者破坏了文字的结构。
4.3细节增强
当光照条件不好时,摄像头获取的图像中常常会有文字不清晰,甚至字符形状出现断裂的现象。对文字信息部分进行细节加强可以使得文字更为清晰。此步骤的关键是强化高频部分。我们采用高提升滤波器(High-boost filter)[6]来解决此问题。滤波操作可以用图像与生成核的卷积运算表示。高提升滤波器的生成核取值为
(3)
其中,c是一个小常数,例如:取值为2。
4.4图像二值化
从256阶灰度图像转换为黑白二值图像是图像处理的最后一步。根据运算的范围不同,图像二值化方法可分为全局阈值方法[7]和局部阈值方法[8~9]。全局阈值法根据图像的直方图或灰度空间分布确定唯一的一个阈值,将此阈值上下的颜色值分别修正为黑白二色,由此实现灰度图像到二值图像的转化。局部阈值法通过定义考察点的邻域,比较考察点与其邻域的灰度值来确定当前考察点的阈值。局部阈值算法适合处理非均匀光照条件导致整体图像的灰度分布值变化较大的情况,但它也存在出现伪影等问题。
二值化算法的选择必须满足实时性要求,并且考虑到环境光照的情况。若图像整体的灰度变化不大,目标文字与背景明显分离,特别是直方图呈现典型的双峰形状,此时经典的Ostu全局阈值算法[6~7]几乎是最好选择。若环境光源复杂,图像存在亮度分布不均和灰度突变的情况,宜采用局部阈值法。
5光学字符识别及有效性判断
OCR技术发展至今,目前市场上已有相当成熟的商用产品,开源领域也有免费可用的项目。所有这些OCR产品几乎都是通用的,即可以识别所支持语言的全部字符集。仪表显示涉及的字符集通常非常小,原则上通用OCR产品都可以用于仪表信息识别,只要满足如下条件:
1) 提供二次开发的编程接口;
2) 针对仪表文字具有较高的识别率和识别速度。
这是由于识别出的仪表数据将用于计算机程序进一步处理,若OCR产品只能交互式显示识别结果将毫无意义。此外,与有人工校对的扫描书籍字符识别过程不同,仪表数据识别过程是无人值守、全自动的,识别的数据将用于后续的决策和自动化,因而对识别对准确率、速度的要求更高。
不同的OCR产品针对的应用领域不同,采用的算法也各不相同。判断OCR产品是否适合仪表数据的提取,只能通过针对具体仪表图像进行测试评估的方法。
例如:在对一个导航类数字仪表进行信息提取时,我们选择了开源的Tesseract OCR[10]引擎。主要原因是它是识别率最高的开源OCR引擎之一,另外开源软件可以任意修改定制的特点意味着有可能针对具体应用提高识别率。在该应用中,只需要识别经纬度、航向等数值,涉及的字符集为数字0~9、度‘°’、分‘′’和小数点‘.’等12个字符等。仪表中,这些字符均以标准宋体字显示。因此我们选择了宋体从8pt一直到36pt所有文字字符,使用虚拟打印技术输出黑白二值化的文字图像。然后将所有文本样本和输出的样本图像输入到Tesseract OCR引擎中进行学习,学习的最终结果是得到样本文字所对应的模式识别特征库。在线识别时,只使用上述特征识别库。实践表明,这种作法对识别的准确率有了很大提升。
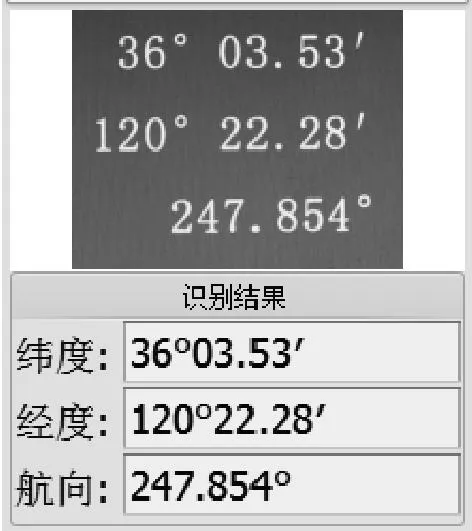
图3 仪表信息提取相关界面
Tesseract OCR引擎缺省情况下只输出的所识别的字符,我们对此进行了修改,在输出结果中同时输出识别的可信度、字符对应的位置等信息,并在完成识别后,增加了一个数值有效性的判断过程。对于每个识别结果,当可信度低于预设的阈值时,直接判定识别结果无效。此外,实践中我们发现识别中最常见的错误是占空间较小的标点符号。利用经纬度、航向的格式进行正则表达式匹配,若仅仅是标点符号不匹配,则根据输出的位置信息进行自动修正。若格式匹配,还要进行语义合法性判断,如纬度值是否大于90°,经度值是否大于180°,航向值是否超过360°等。最后是利用当前识别的坐标与上一次识别的坐标计算两点间的距离,基于识别时间间隔和最大行进速度计算最大距离,只有两点间距离小于后者才会作为有效值转发给后续模块处理。经过上述处理后,该应用的仪表数字信息提取达到了令人满意的可靠性和实时性。
图3是该导航类应用的显示界面中与仪表信息提取相关的部分。
6结语
越来越多的仪表采用液晶屏显示多种字体的常规文字信息。借助具有较高识别率、识别速度的通用OCR引擎来提取这些仪表信息是可行的方案。通过对通用的OCR引擎进行定制优化,如针对特定字体的小字符集离线学习生成专门的识别特征库,能显著提高OCR引擎的识别率。此外,还需要采集校准过的高清图像,并针对采用的OCR算法设计一套包括图像降噪、细节增强、二值化在内的专门的图像处理算法。本文所介绍的方法已在仪表数据提取应用上得以运用,仪表信息提取的质量完全能够满足系统的需求。
参 考 文 献
[1] 范新南,郭建甲,苏丽媛.基于数学形态学的数字仪表数码识别快速算法[J].计算机测量与控制,2006,14(11):1589-1593.
FAN Xinnan, GUO Jianjia, SU Liyuan. Study on Digits Recognition Algorithm of Digital Meter Based on Mathematical Morphology[J]. Computer Measurement & Control,2006,14(11):1589-1593.
[2] 刘科,侯立新,卞昕.基于机器视觉的仪表示值识别算法研究[J].计量学报,2013,34(5):425-429.
LIU Ke, HOU Lixin, BIAN Xin. Study on Digit Recognition for Digital Meter Based on Machine Vision[J]. Acta Metrologica Sinica,2013,34(5):425-429.
[3] 崔行臣,段会川,王金玲,等.数显仪表数字实时识别系统的设计与实现[J].计算机工程与设计,2010,31(1):214-217.
CUI Xingchen, DUAN Huichuan, WANG Jinling, et al. Design and implementation of numeral instrument real-time digital recognition system[J]. Computer Engineering and Design,2010,31(1):214-217.
[4] Zhang. A Flexible New Technique for Camera Calibration[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2000,22(11):1330-1334.
[5] The OpenCV Reference Manual[M/OL]. Release 2.4.6.0, 2013: 265-265, http://opencv.org/.
[6] 岗萨雷斯,伍兹.数字图像处理[M].第三版.阮秋琦,等译.北京:电子工业出版社,2011:203-210,402-438,100-101,479-483.
R. Gonzalez, R. Woods. Digital Image Processing[M]. Third Edition. Prentice Hall,2007.
[7] N. Otsu. A Threshold Selection Method from Gray-level Histograms[J]. IEEE Transactions on Systems, Man, and Cybernetics,1979,9(1):62-66.
[8] W. Niblack. An Introduction to Image Processing[M]. Prentice-Hall,1986:115-116.
[9] J. Bernsen. Dynamic Thresholding of Grey level Images[C]//Proc. Int. Conf. on Pattern Recognition, Berlin, Germany,1986:1251-1255.
[10] Ray Smith. An Overview of the Tesseract OCR Engine[C]//Proc 9th Int. Conf. on Document Analysis and Recognition, USA,2007:629-633.
中图分类号TP391
DOI:10.3969/j.issn.1672-9722.2016.02.036
作者简介:胡成军,男,博士,副教授,研究方向:作战仿真、指挥自动化
*收稿日期:2015年8月12日,修回日期:2015年9月23日
