MapReduce框架下运用K-modes聚类算法进行日负荷曲线预测*
2016-03-15廖一鸣赵文硕
李 彦 王 颖 廖一鸣 赵文硕
(华北电力大学控制与计算机工程学院 北京 102206)
MapReduce框架下运用K-modes聚类算法进行日负荷曲线预测*
李彦王颖廖一鸣赵文硕
(华北电力大学控制与计算机工程学院北京102206)
摘要提出一种MapReduce框架下运用K-modes聚类算法,并基于电力大数据对日负荷曲线进行预测的方法。将预测结果与传统K-modes聚类算法的预测结果进行对比,结果表明:K-modes聚类算法进行分布式处理的方法是可行的,使用这种方法对日负荷曲线进行预测效果更好,提高了预测的精确性,更好地指导电力生产。
关键词大数据; MapReduce; K-modes聚类算法; 日负荷曲线预测
Daily Load Curve Forecasting by Using K-modes Clustering Algorithm Under the Framework of MapReduce
LI YanWANG YingLIAO YimingZHAO Wenshuo
(School of Control and Computer Engineering, North China Electric Power University, Beijing102206)
AbstractA method using K-modes clustering algorithm under MapReduce framework, and forecasting daily load curve based on the method of power data is proposed. The prediction results is compared with the traditional K-modes clustering algorithm, and the results were analyzed. Results show that: the K-modes clustering algorithm for distributed processing method is feasible, and this method can predict daily load curve better, and improve the precision of the prediction, guide the electric power production better.
Key Wordsbigdata, MapReduce, K-modes clusteringal gorithm, dailyload forecasting
Class NumberTP181
1引言
国家电网是当今世界上最大的自动化电能计量系统。其收集并且保存的数据总量达10PB,国家电网即将迎来大数据时代[1]。对电网而言,根据所采集大量用户的用电数据,运用大数据技术对日负荷曲线进行精确地预测具有重要意义。
MapReduce是一种能处理大规模数据集的并行运算问题的编程模型。MapReduce框架有一定的应用范围,可伸缩性便是对算法最重要的要求,即分到每个节点的任务一定是相同的、独立的。K-modes聚类算法便具有可伸缩性,且利用这种算法对日负荷曲线进行预测是一种常见的预测方法。国内外针对这种预测方法进行了大量的研究[4~7],因此可尝试将其运用于Mapreduce框架下对日负荷曲线进行预测。
2MapReduce框架及K-modes算法
2.1MapReduce框架
MapReduce将存储在HDFS中的大规模数据分解为小规模数据后分发给集群中的多个节点去协作完成。
一个MapReduce任务由四部分部分构成:客户端;JobTracker;TaskTracker;分布式文件系统。MapReduce任务分为两个阶段:Map阶段和Reduce阶段。Map阶段执行分解后的小任务并得到中间结果,Reduce阶段负责把这些中间结果汇总。具体执行过程如图1所示。

图1 MapReduce框架执行过程
2.2K-modes算法

(1)
式中,n×k的隶属度矩阵为U;对象集X中所包含元素的个数表示为n;所划分类的个数表示为k:Z={z1,z2,…,zk}是k个对象构成的非空有限集合;zl表示所划分类的类中心。
d(xi,zl)为对象xi与类中心zl之间简单匹配的相异度量。Ui,l表示对象xi隶属于第i类的程度。
为使目标函数在满足约束条件的情况下趋近极小化,K-modes算法利用基于频率的方法交替更新隶属度矩阵和聚类中心,直至目标函数收敛。[8]
3K-modes聚类算法应用MapReduce框架
3.1K-modes聚类算法应用MapReduce框架的思路
聚类算法是一种迭代式算法,数据完成一遍后,由结束条件来决定是否需要进行下一次迭代。
具体运行步骤: 1) 假设数据集需要被分成k簇,随机选出k个样本作为初始中心点。 2) 计算出距各样本差异最小的中心点,将样本划入该中心点所在的簇,并算出各个属性的众数。 3) 这一轮结束,算出目标函数的值,然后使用每簇中各个属性的众数替换中心点相应属性的值。 4) 重新计算每个样本到新的簇中心的距离,若某个样本与其他簇中心的差异相较于与本簇中心的差异小,那么将其划分到差异较小的那一簇中,然后再次计算各个簇的属性众数。 5) 重复3)、4)步骤直到目标函数的值不变。
3.2实例说明
以日负荷峰点的分为两类的过程为例说明上述执行过程,采用数据为北京地区相关数据,如表1。
执行步骤: 1) 1~6月分到节点Mapper1,7~12月分到节点Mapper2。然后由Reducer节点进行汇总。 2) 选择A、B两中心点作为初始中心分别取值为:CenterA=(16:00~17:00=7,17:00~18:00=62,18:00~19:00=22,19:00~20:00=2);CenterB=(16:00~17:00=2,17:00~18:00=20,18:00~19:00=73,19:00~20:00=5)Mapper读取数据并进行对比。 3) 每个节点做两个工作:(1)比较各月与两个中心点的距离,将该月份归到距离较小的那组。(2)计算众数矩阵。结果如表2和表3所示。 4) Reduce节点得到临时结果,并对其进行汇总。

表1 北京地区2012~2013年16:00~20:00段

表2 Mapper节点1统计结果

表3 Mapper节点2统计结果
5) Main函数进行代价的比较,若与前一次代价相同,程序结束,若比前一个代价小,则更新中心点,直到代价不变或变大为止。
结果被分为两类:第一类:11、12、1、2、3、4月;第二类:5、6、7、8、9、10月。经查阅相关资料,第一类也被称为早峰点负荷月,第二类也被称为晚峰点负荷月。
4预测结果以及结果对比
日负荷曲线存在一定的周期性和规律性。相比于对日负荷曲线进行独立分析,对其历史样本进行聚类,能够更好反映日负荷曲线规律性。[9]
然而负荷历史数据的绝对数据数量级不同,计量单位也不统一,应先对数据进行归一化处理。[10]处理后的历史数据聚类分类结束后,结合分类结果和待预测日相关数据预测出该日的日负荷曲线。
本文利用北京地区2012~2013年度日负荷曲线及气象等历史数据。预测了2013年四个季节的典型日负荷曲线。分别选取4月15日、夏季最高负荷日、10月15日和冬季最高负荷日分别作为春夏秋冬的典型日。预测结果如图2~5所示。

图2 春季典型日负荷曲线预测图
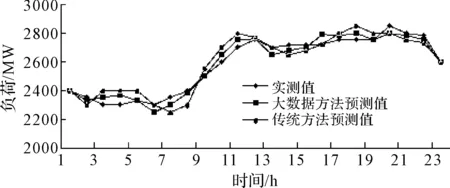
图3 夏季典型日负荷曲线预测图
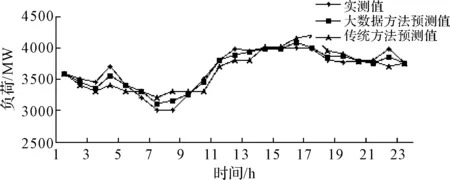
图4 秋季典型日负荷曲线预测图
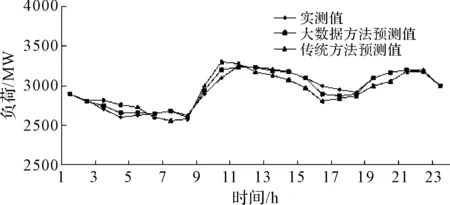
图5 冬季典型日负荷曲线预测图
以冬季典型日负荷曲线为例,大数据方法测试值平均误差是8.42,传统方法测试值平均误差是27.42。春季、夏季、秋季的典型日负荷曲线也有类似结论。从中可以看出使用大数据方法对日负荷曲线进行预测具有更高的精确性。
5结语
本文所得结论: 1) 在MapReduce框架下使用K-modes聚类算法对电力大数据进行处理的思路可行。 2) 与传统方法的预测结果对比发现大数据方法预测结果具有更高的精确性。
发现的问题: 1) K-modes是迭代型算法,计算耗时长。需优化初始中心选择、提升算法效率。 2) 大数据应用于智能电网过程中,由于数据量大、数据质量低、硬件设备缺乏等原因。大数据的很多构想处于理论阶段,距实际生产尚有一段时间。
参 考 文 献
[1] 李伟,张爽.基于Hadoop的电网大数据处理探究[J].电子测试,2014(1):5-6.
LI Wei, ZHANG Shuang. Research on the large data processing of power network based on Hadoop[J]. Electronic Test,2014(1):5-6.
[2] 李伟卫.基于Hadoop平台的数据挖掘技术研究[D].咸阳:西北农林科技大学,2013:24-27.
LI Weiwei. Research on data mining technology based on Hadoop platform[D]. Xianyang: Northwest Agriculture and Forestry University,2013:24-27.
[3] 罗军舟.云计算:体系架构与关键技术[J].通信学报,2011(7):11-14.
LUO Junzhou. Cloud Computing: Architecture and key technologies[J]. Communications Journal,2011(7):11-14.
[4] 刘莉,王刚.K-means聚类算法在负荷曲线分类中的应用[J].电力系统保护与控制,2011,39(23):2-3.
LIU Li, WANG Gang. K-means clustering algorithm in the load curve classification[J]. Power System of Protection and Control,2011,39(23):2-3.
[5] 李翔,顾洁.运用聚类算法预测地区电网典型日负荷曲线[J].电力与能源,2013,1:47-50.
LI Xiang, GU Jie. The use of clustering algorithm to predict the regional power grid typical day load curve[J]. Power and Energy,2013,1:47-50.
[6] 陈柔伊,张尧,武志刚,等.改进的模糊聚类算法在负荷预测中的应用[J].电力系统及其自动化学报,2005,3:3-5.
CHEN Rouyi, ZHANG Yao, WU Zhigang, et al. Application of improved fuzzy clustering algorithm in load forecasting[J]. Power System and Its Automation,2005,3:3-5.
[7] Huang Z X. Extensions to the K-means Algorithms for Clutering Large Data Sets with Categorical Values[J]. Data Mining and Knowledge Discovery,1998(2):225-227.
[8] 李飞.初始聚类中心优化的K-means算法[J].计算机科学,2002,29(7):22-25.
LI Fei. Initial clustering center optimization of K-means algorithm[J]. Computer Science,2002,29(7):22-25.
[9] 艾学勇.地区电网典型日负荷曲线预测方法研究[D].上海:上海交通大学,2009,33.37.
AI Xueyong. Study on the typical daily load curve forecasting method of regional power network[D]. Shanghai: Shanghai JiaoTong University,2009,33.37.
[10] 张月琴,陈彩棠.基于新相异度量的模糊K-Modes聚类算法[J].电脑开发与应用,2012,5:32-34.
ZHANG Yueqin, CHEN Caitang. The development and application of[J]. based on the new K-Modes clustering algorithm,2012,5:32-34.
中图分类号TP181
DOI:10.3969/j.issn.1672-9722.2016.02.011
作者简介:李彦,女,硕士研究生,研究方向:软件工程。王颖,女,教授,研究方向:数据库应用技术、软件架构设计、嵌入式系统、WebGIS研究。廖一鸣,男,硕士研究生,研究方向:软件工程。赵文硕,女,硕士研究生,研究方向:软件工程。
*收稿日期:2015年8月12日,修回日期:2015年9月22日
