基于GeoNames和Solr的地名数据全文检索
2016-03-01胡丹露
魏 勇,胡丹露,李 响,王 丰
(1.信息工程大学 地理空间信息学院,河南 郑州 450052;2.61081部队,北京 100085)
基于GeoNames和Solr的地名数据全文检索
魏勇1,胡丹露1,李响1,王丰2
(1.信息工程大学 地理空间信息学院,河南 郑州 450052;2.61081部队,北京 100085)
地名与人们的生活息息相关,是最常用的社会公共信息之一,也是大众最熟悉的地理空间数据。地名在地理信息组织和传递中占据着举足轻重的作用,搭建起地理信息与空间位置之间的桥梁。地名数据库是通过计算机实现对地名信息资源的收集整理、标引著录、检索输出的自动化检索系统。随着社会的发展,地名信息需求迅速增长。地名数据库的建立,使地名资源得到充分开发和利用。地名数据库建设是国家信息化建设的重要基础,对于促进我国现代化建设具有非常重要的作用。
地名通常以非结构化的自然文本表示,这为地名信息的检索带来不便。传统的信息检索方式要求数据满足关系数据库第一范式所要求的最小原子值的要求,而地名名称通常以长字符串的形式表示,虽然通过构造SQL查询语句能够实现字符串的模糊检索,但这种方法需要对所有文本段落匹配,查询效率很低。全文检索是一种非常有效的信息检索技术,它能提供快捷的数据管理工具和强大的数据查询手段,快速进行大量文档资料的整理和管理工作。
本文提出一种基于开源地名数据库GeoNames和开源搜索引擎Solr提供地名数据全文检索服务的方法,首先分析GeoNames的数据结构,构建基于GeoNames的地名数据库并将地名数据入库处理,然后利用Solr对地名数据相关进行分词,建立全文索引,并提供地名数据全文检索服务。国内外许多学者已进行大量研究,并取得一系列成果[1-9]。
1地名数据全文检索处理方法
1.1GeoNames数据分析
GeoNames是一个免费的全球地理数据库,包含了将近200种语言的850万个地名和200万个别名信息,地名数据包括坐标、行政区划、邮政编码、人口、海拔和时区等属性[10]。GeoNames的数据收集自美国国家测绘部门、国家统计署、国家邮政局和美国陆军等相关机构。GeoNames地名数据的分布广泛,GeoNames中的地名数据具有很高的覆盖率,可用性较强。
1.1.1数据文件类型
GeoNames网站共提供18类数据文件,这些数据文件记录不同的数据,分别描述地名、别名、行政区划、语言、编码、时区、国家等各类信息,具体说明如表1所示。

表1 GeoNames文件说明
通过表1分析,XX.txt、allCountries.txt、cities1000.txt、cities5000.txt、cities15000.txt等5类文件均是地名数据文件,其中allCountries.txt是全部国家的地名数据,XX.txt是各个国家单独的地名数据文件,cities1000.txt、cities5000.txt、cities15000.txt是按照人口数量筛选出的城市地名数据文件,即allCountries.txt文件中包含XX.txt、cities1000.txt、cities5000.txt、cities15000.txt文件中的数据,因此本文使用allCountries.txt、alternateNames.txt、admin1CodesASCII.txt、admin2Codes.txt、iso-languagecodes.txt、featureCodes.txt、timeZones.txt、countryInfo.txt、modifications-
1.1.2字段类型
GeoNames中的地名信息主要保存在allCountries.txt文件,文件中每行数据表示一条地名信息,字段以空格分割,各字段说明及类型如表2所示。

表2 地名字段说明及类型
地名名称主要存储在name,asciiname,alternatenames 3个字段中,其中name字段为本地语言表示的地名名称,asciiname是地名的英文文本形式(中文地名为汉语拼音),alternatenames为地名的别名信息,一条地名可能包括多个不同语言、不同描述的别名,别名之间以逗号隔开。
1.2地名数据库设计
地名数据库是通过计算机实现对地名信息资源的收集整理、标引著录、检索输出的自动化检索系统[11-12],地名数据库的建立,能够使地名资源得到充分开发和利用。目前地名数据库主要使用关系数据库存储,利用关系表的结构来标示地名数据信息之间的联系。
本文使用MySQL数据库来存储地名数据,MySql是一个快速、多线程、多用户的SQL数据库服务器。MySQL数据库的代码是开源的,支持规范的SQL查询语言和多种数据类型,具有跨平台的特性,因此在网络服务器中得到了广泛的应用。根据1.1节的分析,本文分别创建7个数据表来存储各类文件信息:geo_name存储地名信息,geo_country存储国家信息,geo_alternames存储别名信息,geo_timezones存储时区信息,geo_admin1存储一级区域信息,geo_languagecodes存储语言编码信息,geo_featurecodes存储类型编码信息,geo_continent存储洲别信息。各个数据表的字段结构如图1所示。
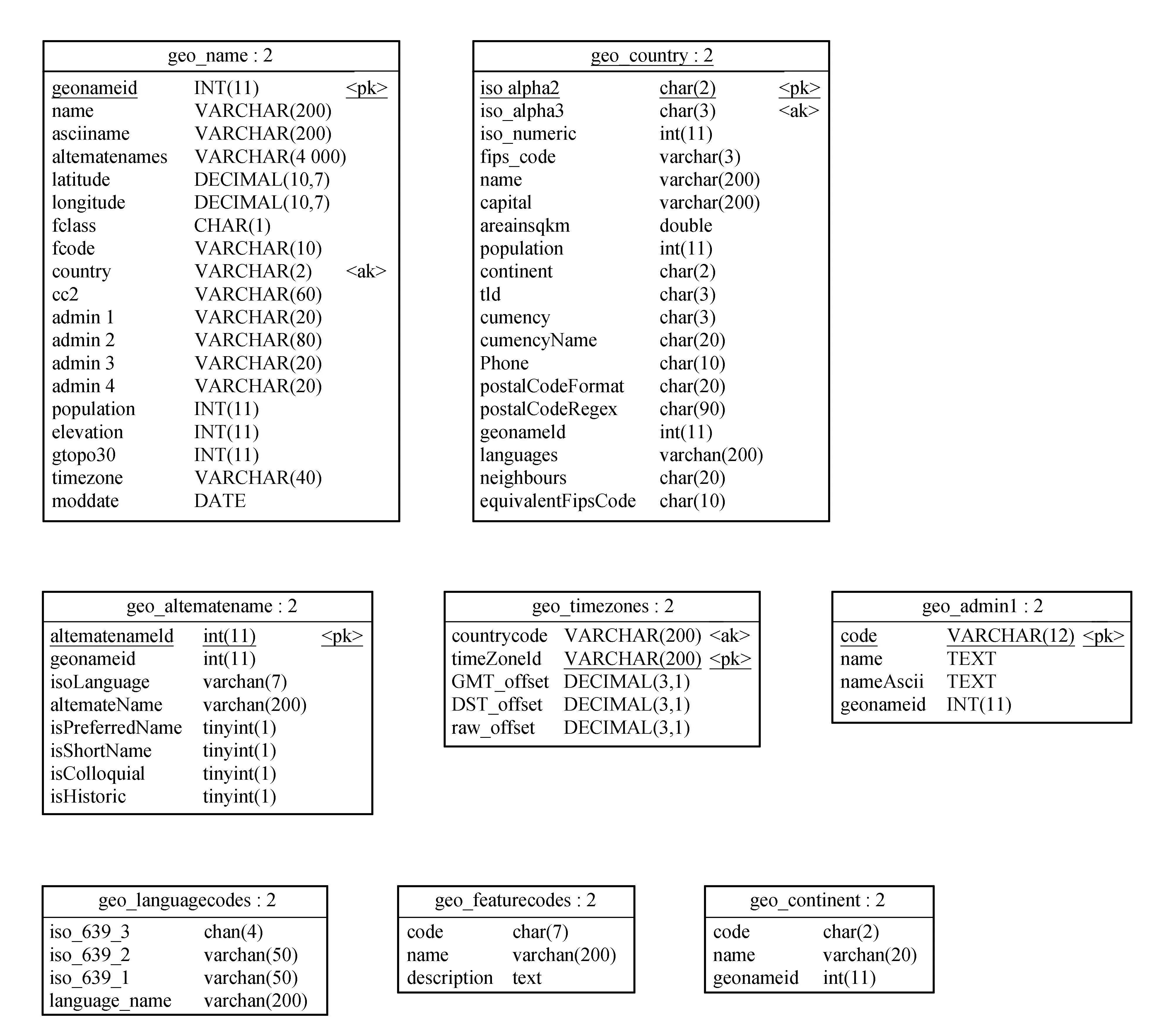
图1 地名数据库表结构
1.3构建倒排索引
本文使用Solr作为地名数据全文检索的搜索服务器。Solr是一个高性能的开源搜索服务器,它使用Java语言开发,主要基于HTTP和Lucene实现[13]。Solr向用户提供基于Web-service的API接口,用户通过向部署在servlet容器中的Solr Web应用程序发送HTTP请求来启动索引和搜索,实现对数据的索引的增加、删除、修改、查询。
倒排索引是全文检索的基础,它是指计算机程序通过扫描文本中的每一个词,对词汇建立索引,记录该词在文章中出现的次数和位置,建立“词-位置”结构的索引;当用户查询时,检索程序根据建立好的索引进行查找,并将查找结果反馈给用户。Solr支持从数据库(通过JDBC)、RSS提要、Web页面和文件中导入数据[14]。在构建索引时,只需要使用POST方法向Solr服务器发送一个描述所有字段及其内容的XML文档即可。通过配置Solr的DataImportHandler信息可以方便地从MySQL数据库查询字段并导入到Solr中建立全文索引。
构建倒排索引的一个关键问题是中文分词问题。词是表达概念的最小单元,与英语等西方语言用空格作为词分割标记的表达不同,汉语表达中的词没有明显的分割标记,Solr中的标准分词组件StandardTokenizerFactory只能简单地将中文文本按照单字分割,例如“中华人民共和国”的分词结果为“中华人民共和国”,这种分词方法将最小概念粒度的词汇强制切分为单字级别,严重影响检索精度。本文使用mmseg4j来作为Solr的中文分词组件,mmseg4j是基于MMSeg算法[15]的开源中文分词器,它实现lucene的analyzer和solr的TokenizerFactory接口,能够方便地在Lucene和Solr中集成使用。
GeoNames的地名信息主要存储在geo_name表中,是地名检索的主要对象。因此,本文对geo_name表中的各项字段构建倒排索引,其中name、alternatenames字段包含中文地名名称,使用mmseg4j中文分词组件来进行中文分词,其他字段使用StandardTokenizerFactory标准分词组件。
1.4访问地名检索服务
Solr提供一种基于Web服务的检索方式:用户通过向Solr Web应用程序发送HTTP请求;Solr接受请求,确定要使用的适当SolrRequestHandler,然后处理请求;再通过HTTP方式返回处理结果。Solr的HTTP请求格式为“http://服务器地址:端口号/solr/collection1/select?q=字段:检索词&wt=返回格式”,多个关键词之间可以使用AND,OR或NOT操作符来执行逻辑查询,服务器返回的数据格式包括xml,json,python,ruby,php,phps或自定义等多种格式。
2实验及应用
关系数据库查询语言SQL可以利用LIKE语法实现地名信息的模糊查询,但这种查询方法需要对数据库中的字段内容进行全部匹配,检索效率较慢。为了验证基于Solr的地名数据全文检索的有效性,本文设计SQL模糊检索与Solr检索的对比实验,使用两种查询方法对不同关键词进行检索,分别记录各自的检索结果数量和检索用时,详情如表3所示。

表3 SQL模糊检索与Solr全文检索对比
通过表3可以看出,基于Solr的全文检索与SQL模糊检索相比,检索用时只占后者的30.04%;单个地名词语的检索,基于Solr的全文检索到的结果数量与SQL模糊查询的结果差别不大;对于复杂地名词语的检索,基于SQL的模糊查询无法查询到数据结果,而基于Solr的全文检索能够查询到相应的地名记录。
本文基于GeoNames数据和Solr检索服务器,利用PHP编程语言,构建了“全球地名数据全文检索”原型系统,用于测试全球地名数据的全文检索服务,系统截图如图2所示。
3结束语
本文提出一种基于GeoNames和Solr的地名数据全文检索服务实现方法,通过分析GeoNames文件的数据结构,设计MySQL地名数据库,导入GeoNames地名数据,然后利用Solr创建地名数据索引,并提供基于Web-service API的地名数据全文检索服务。实验表明,基于Solr的全文检索平均用时是基于SQL的模糊查询检索平均用时的31.68%,同时基于Solr的全文检索能够对复杂的地名关键词进行检索,提高检索命中率。

图2 “全球地名数据全文检索”原型系统
通过构建地名数据全文索引可以实现复杂地名数据的简单查询,但对于自然语言描述的复杂地址匹配,需要根据地址模型和编码规则进行地名数据的智能语义解析,建立地址文本与空间坐标信息之间的映射,这是本文的下一步研究方向。
参考文献:
[1]HAHMANN S,BURGHARDT D.Connecting linkedgeodata and geonames in the spatial semantic web: 6th International GIScience Conference[Z].2010.
[2]POPESCU A,GREFENSTETTE G,BOUAMOR H.Mining a multilingual geographical gazetteer from the web: Proceedings of the 2009 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology-Volume 01[Z].IEEE Computer Society,2009:58-65.
[3]SMART P D,JONES C B,TWAROCH F A.Multi-source Toponym Data Integration and Mediation for a Meta-Gazetteer Service[M].Geographic Information Science,2010:234-248.
[4]张红辉,赵仁亮,周晓光.基于开源方式的多源网络地名数据库整合[J].地理信息世界,2014,21(1):22-28.
[5]张雪英,朱少楠,张春菊,等.基于XML Schema的多源地名词典集成方法[J].地理与地理信息科学,2012,28(2):1-4.
[6]张春菊,张雪英,朱少楠,等.基于网络爬虫的地名数据库维护方法[J].地球信息科学学报,2011,13(4):492-499.
[7]杨柳.空间数据全文检索方法研究[J].测绘工程,2012,21(6):8-12.
[8]周科松.全文检索与GIS一体化及在应急管理中的应用研究[D].上海: 华东师范大学,2009.
[9]刘亚,段丽娟,亢晓琛,等.基于MongoDB的地名信息管理[J].测绘通报,2014(10):117-120.
[10] AHLERS D.Assessment of the accuracy of geonames gazetteer data: Proceedings of the 7th Workshop on Geographic Information Retrieval[Z].ACM,2013:74-81.
[11] 汤馥旭.关于构建地名数据库的思考[J].中国地名,2009(12): 42-43.
[12] 牛汝辰,程锦,牛劲梅,等.新疆地名音转溯源规律研究[J].测绘科学,2015,40(2):48-51.
[14] SMILEY D,PUGH E.Apache Solr 3 Enterprise Search Server[M].Birmingham: Packt Publishing,2011.
[15] TSAI C.MMSEG: A Word Identification System for Mandarin Chinese Text Based on Two Variants of the Maximum Matching Algorithm[Z].2000.
[责任编辑:路晓鸽]
摘要:地名数据是一种重要的地理信息资源,目前我国的地名数据库建设多局限于国内地名,缺少国外数据。传统地名数据的检索多为关键字查询,查询效率低且无法用于复杂地名查询。文中提出一种基于开源地名数据库GeoNames和开源搜索引擎Solr的地名数据全文检索方法,通过分析GeoNames的数据类型和结构,构建MySQL地名数据库,并利用Solr建立地名索引,提供基于Web服务的地名数据全文检索。实验表明,基于Solr的地名数据全文检索能够显著提高地名数据检索效率,对于复杂地名查询,也能进行有效地检索。
关键词:地名数据;GeoNames;Solr;全文检索;Web服务
Geographic name full text query based GeoNames and SolrWEI Yong1, HU Danlu1,LI Xiang1, WANG Feng2
(1.School of Geospatial Information, Information and Engineering University, Zhengzhou 450052, China; 2.Troops 61081, Beijing 100085, China)
Abstract:Geographic name data is an important geographic information resources. The construction of China’s geographic name database pays close attention to domestic names, and is short of foreign data. Traditional geographic data retrieval is keyword query with poor efficiency and bad result for complex place name query. This paper proposes a technique of geographic name full-text retrieval based on open source database GeoNames and open source search engine Solr, analyses GeoNames data types and structures, builds MySQL database of names and establishes geographic names index with Solr, and provides a geographic name full text retrieval based web service. Experiments show that geographic name data full-text query based on Solr can significantly improve the efficiency of retrieval, and effectively respond for complex geographic name query.
Key words:geographic name; GeoNames; Solr; full text query; web service
作者简介:魏勇(1987-),男,博士研究生.
基金项目:国家自然科学基金青年科学基金项目(41401467);四川省应急测绘与防灾减灾工程技术研究中心开放基金(K2015B014)
收稿日期:2015-07-05
中图分类号:TP315
文献标识码:A
文章编号:1006-7949(2016)02-0028-05
