分布式并行化数据流频繁模式挖掘算法
2016-02-27李玲娟孙杜靖
马 可,李玲娟,孙杜靖
(南京邮电大学 计算机学院,江苏 南京 210003)
分布式并行化数据流频繁模式挖掘算法
马 可,李玲娟,孙杜靖
(南京邮电大学 计算机学院,江苏 南京 210003)
为了提高数据流频繁模式挖掘的效率,文中基于经典的数据流频繁模式挖掘算法FP-Stream和分布式并行计算原理,设计了一种分布式并行化数据流频繁模式挖掘算法—DPFP-Stream (Distributed Parallel Algorithm of Mining Frequent Pattern on Data Stream)。该算法将建立频繁模式树的任务分为local和global两部分,并设置了参数“当前时间”;将到达的流数据平均分配到多个不同的local节点,各local节点使用FP-Growth算法产生该单位时间内本节点的候选频繁项集,并按照单位时间将候选频繁项集及其支持度计数打包发送至global节点;global节点按“当前时间”合并各local节点的中间结果并更新模式树Pattern-Tree。在分布式数据流计算平台Storm上进行的算法实现和性能测试结果表明,DPFP-Stream算法的计算效率能够随着local节点或local bolt线程的增加而提高,适用于高效挖掘数据流中的频繁模式。
数据流;频繁模式;分布式并行化;Storm
0 引 言
数据流是按时间顺序到达的数据所组成的一个序列,其中的数据是动态的,数据量潜在无界、数据到达速率快。对此类数据的收集过程和挖掘过程是同时进行的,不允许反复扫描历史数据,需要用一次扫描算法(single-scan algorithm)来处理[1]。
流数据的挖掘有分类、聚类、关联分析等多种任务[2-4]。在流数据的关联规则挖掘算法中,经典的FP-Stream算法实现了对流数据的频繁模式挖掘。该算法将挖掘任务分为在线挖掘单位时间的候选频繁项集与离线处理历史频繁项集两个部分,通过倾斜时间框架存储候选频繁项集,并可以按照用户输入的参数查询相应时间的频繁项集[5-7]。
MapReduce是一种分布式计算框架,将一个算法抽象成Map和Reduce两个阶段进行处理,非常适合数据密集型计算,但是它是批处理的。Storm是一种典型的在线流式数据分布式计算架构,可以用来在线处理源源不断流进来的数据,也可以通过设置滑动时间窗口等机制,在实时处理到达数据的同时,实现类似MapReduce的功能[8]。
文中首先基于经典数据流频繁模式挖掘算法FP-Stream[9]和分布式并行计算的思想,设计了一种分布式并行化数据流频繁模式挖掘算法(Distributed Parallel algorithm of mining Frequent Pattern on data Stream,DPFP-Stream)。接着,考虑到将流挖掘算法部署到流平台上运行是算法实用化的前提,进一步基于Storm集群进行了DPFP-Stream算法的实现。为了评价该算法的性能,设计了线程处理压力测试实验,并分析了实验效果。
1 FP-Stream算法分析
FP-Tree(频繁模式树)是FP-Growth算法建立的一种数据结构,虽然它不能直接用于数据流的关联规则挖掘,但通过对FP-Tree加以改进,可以将其运用在数据流上[10-11]。基于此思想,Giannella.C等提出了FP-Stream模型,将频繁模式挖掘算法分为挖掘单位时间频繁项集与记录各时间段频繁项集两个部分[12]。第一部分设置了参数最大支持度误差(该值小于挖掘频繁项集的最小支持度),使用FP-Growth算法对单位时间内的数据进行挖掘,挖掘出支持度大于支持度误差的项集即候选频繁项集供第二部分处理;第二部分以FP-Tree为基础,引入倾斜时间窗口[13]建立Pattern-Tree,用来记录不同时间粒度的频繁项集中间结果;算法对外设置了接口供用户输入参数,用户可以自由地设置最小支持度、置信度与查询时间,根据不同时间段参数方便地查询频繁项集及关联规则。
图1给出了FP-Stream算法在一个单位时间内的处理流程。
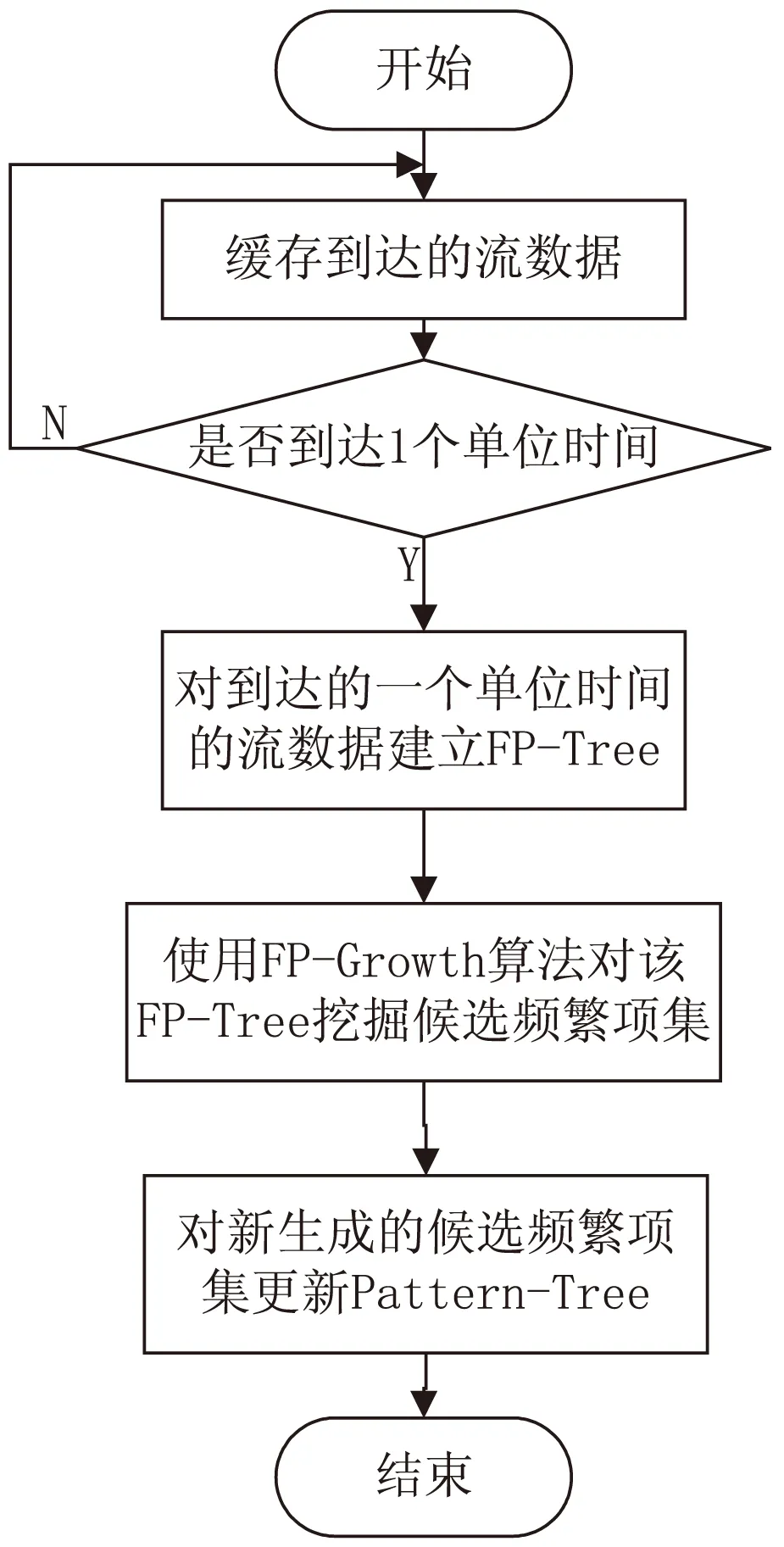
图1 FP-Stream算法单位时间内的处理流程
2 DPFP-Stream算法设计
2.1 基本思想
FP-Stream算法无法直接运用于分布式环境,因为当到达的数据流速过快,算法第一部分(用FP-Growth算法挖掘单位时间内的候选频繁项集)无法快速产生结果,为了提高挖掘速度必须提高最大支持度误差值,但这会影响挖掘精度。
针对这个问题,文中设计了DPFP-Stream算法。其基本思想是:将挖掘任务分为local和global两大部分,相应地,设置多个local节点和一个global节点,local节点为局部计算节点,global节点为全局合并节点。到达的流数据平均分配到不同的local节点,各local节点使用FP-Growth算法产生该单位时间内本节点的候选频繁项集,按照单位时间将候选频繁项集及其支持度计数打包发送至global节点;global节点合并各local节点的中间结果并发送至Pattern-Tree。此外,设置参数“当前时间”来保证被合并数据在时间上的对应性。
2.2 候选频繁项集的分布式并行化挖掘
候选频繁项集的挖掘以分布式并行化方式进行,到达的数据平均分配到各个local节点,每个节点设置一个缓存,接收一个单位时间的流数据,当接收时间到达一个单位时间,对这一块数据建立FP-Tree,根据算法设定的最大支持度误差阈值,找到该单位时间内的候选频繁项集(支持度大于最大支持度误差的项集),并将其按照时间打包发送至global模块进行处理。图2为基于单位时间内的数据生成FP-Tree的流程。
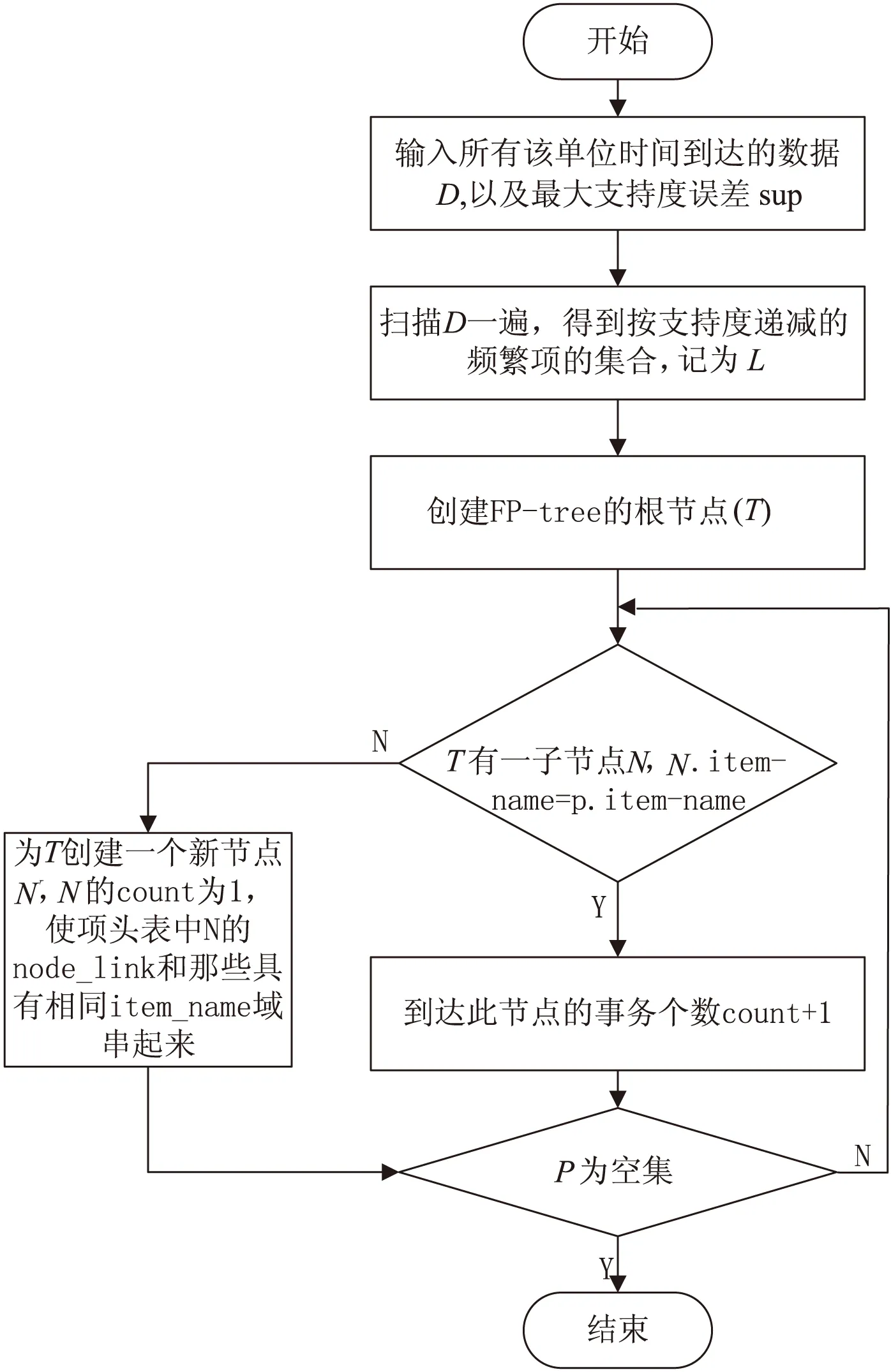
图2 建立单位时间内的FP-Tree的流程
建立了单位时间内的FP-Tree之后,使用经典的FP-Growth算法[14]挖掘该棵FP-Tree中支持度大于最大支持度误差的频繁项集,即候选频繁项集,具体过程可以描述如下:
输入:待挖掘的FP-Tree;
输出:所有的频繁项集。
步骤:
递归地挖掘每个条件FP-Tree,累加后缀频繁项集,直到找到FP-Tree为空或者FP-Tree只有一条路径,首先调用FP-Growth(Tree,null)。
过程FP-Growth (Tree,x)可以描述如下:
procedureFP-Growth(Tree,x)
ifTree含单个路径P
then{
for路径P中节点的每个组合(记作b)
产生模式b∪a,其支持度support为b中节点的最小支持度;
}
else{
foreachai在Tree的头部(按照支持度计数由低到高顺序进行扫描)
{
产生一个模式b=ai∪a,其支持度support=ai.support;构造b的条件模式基(即顺着headertable中item的链表,找出所有包含该item的前缀路径,这些前缀路径就是条件模式基),然后构造b的条件FP-Tree,即Treeb;
ifTreeb不为空
then调用FP_Growth(Treeb,b);
}
}
local节点在生成一个单位时间内的候选频繁项集之后,将该单位时间内的所有频繁项集与记录总数、当前时间一起打包发送至global节点进行合并。
2.3 分布式并行化挖掘结果的合并
由于处理能力会有所不同,各local节点处理生成中间结果并发送至global节点的速度可能不一致,这使得global节点会错误地将不同时间段的中间结果合并至相同时间段。为了防止此类情况的发生,DPFP-Stream算法对global节点与各local节点设置了参数“当前时间”,global节点依据各local节点发送的“当前时间”对中间结果进行合并。
global节点设置了阈值threshold,其作用是控制Pattern-Tree的合并。global节点合并一个local节点的中间结果至Pattern-Tree的过程可以描述如下:
输入:全局Pattern-Tree,单个local节点的中间结果MR,合并阈值threshold;
输出:合并后的全局Pattern-Tree。
步骤:
比较MR与Pattern-Tree的当前时间;
if MR.time==PatterTree.time
then{
for each frequent item in MR
{
在Pattern-Tree中找到相应节点,将支持度计数加入该节点的第一块时间窗口(若Pattern-Tree中无相应节点,则新建节点插入相应信息);
}
将该单位时间内记录总数加入Root节点的第一块时间窗口;
}
else if MR.time==PatternTree.time+1
then{
for each frequent item in MR
{
在Pattern-Tree中找到相应节点,将节点内窗口的数据向后滑动,并将支持度计数加入该节点的第一块时间窗口(若Pattern-Tree中无相应节点,则新建节点插入相应信息),Root节点内窗口的数据向后滑动,并将记录总数加入Root节点的第一块时间窗口;
}
Pattern-Tree.time+1;
}
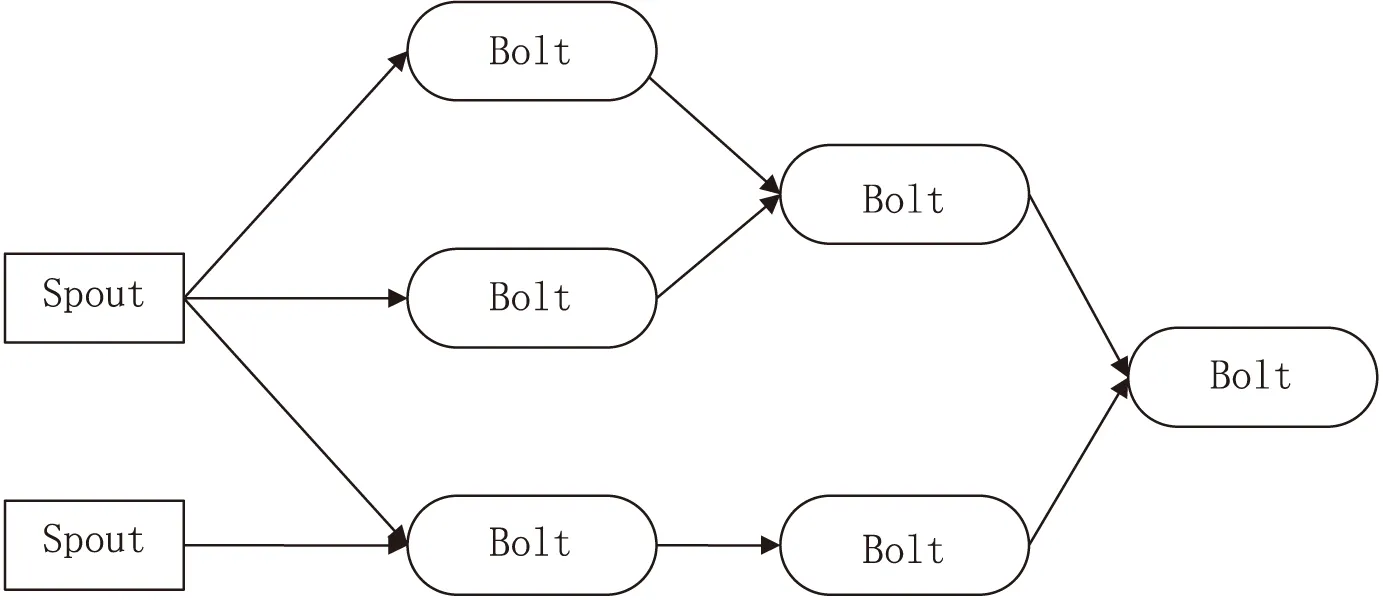
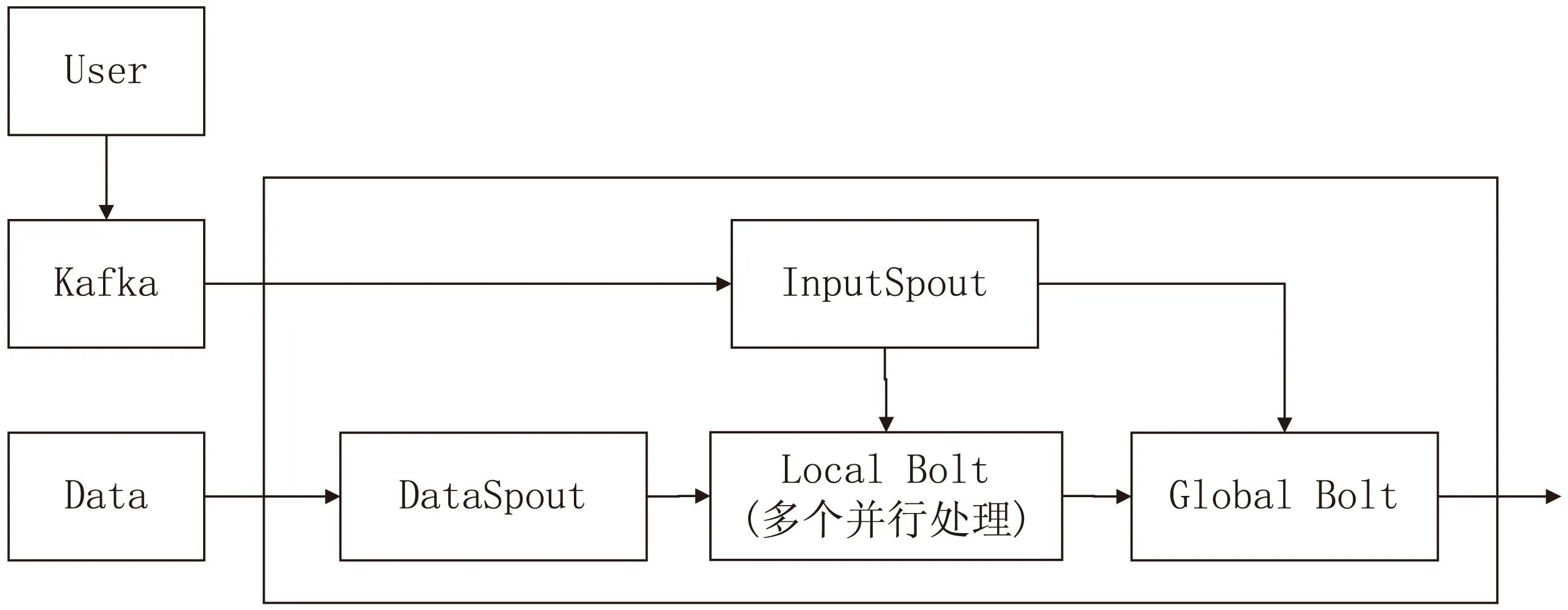
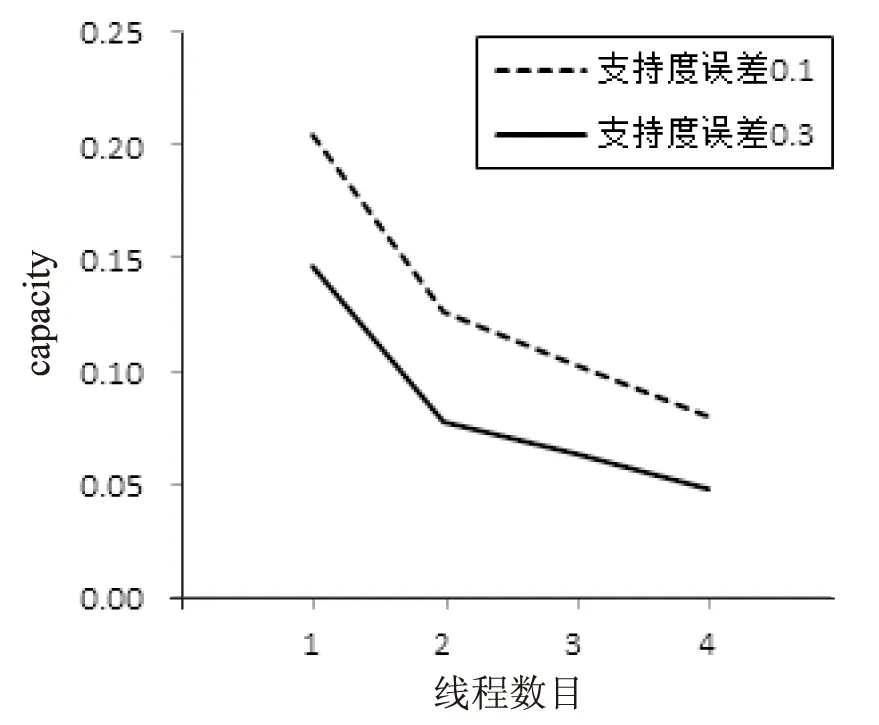
else if MR.time then{ 依据PatternTree.time-MR.time,找到该事件对应到倾斜时间窗口的具体位置,对MR中的所有频繁项集,在Pattern-Tree中进行更新; } else{ 将Pattern-Tree当前时间发送至local节点,更新local节点当前时间,使之与global节点一致; } 3.1 Storm系统 Storm[15]是Twitter支持开发的一款分布式的、开源的、实时的、主从式大数据流式计算系统,是一种典型的流式数据计算架构,数据在任务拓扑中被计算,并输出有价值的信息。 任务拓扑是Storm的逻辑单元,一个实时应用的计算任务将被打包为任务拓扑后发布,任务拓扑一旦提交后就会一直运行,除非显式地去中止。一个任务拓扑是由一系列Spout和Bolt构成的有向无环图,通过数据流实现Spout和Bolt之间的关联。如图3所示,Spout负责从外部数据源不间断地读取数据,并以元组形式发送给相应的Bolt,Bolt负责对接收到的数据流进行计算,可以级联,也可以向外发送数据流。 图3 Storm拓扑示例 3.2 DPFP-Stream算法在Storm上的部署 基于Storm流计算框架的编程模型,文中设计了DPFP-Stream算法在Storm上的部署方案。 图4为DPFP-Stream算法在Storm上的拓扑示意图。 图4 DPFP-Stream的Storm拓扑图 如图4所示,Kakfa[16]作为消息中间件,接收用户发送的配置参数与查询参数,发送至InputSpout供后续计算;DataSpout接收待挖掘数据,将到达的数据打上时间戳标记并平均发送至各Local Bolt线程进行计算;InputSpout接收用户输入的配置参数与查询参数,将所有参数(支持度、支持度误差、置信度、查询时间)发送至Global Bolt供挖掘计算与查询,同时将参数最大支持度误差发送至Local Bolt供生成候选频繁项集;Local Bolt为算法在Storm上实现的并行化部分,按时间戳对单位时间内到达的数据使用FP-Growth算法挖掘候选频繁项集;Global Bolt为算法在Storm上实现的合并部分,对各Local Bolt生成的中间结果进行合并,生成最新的Pattern-Tree;用户可向系统输入查询参数查询最新Pattern-Tree。 为了测试DPFP-Stream算法的分布式并行化效果,设计了如下实验。 (1)实验数据集与环境。 实验数据集是预处理过的超市购物数据集,实验中分别使用经典的FP-Stream算法与文中设计的DPFP-Stream算法对该数据集进行频繁模式挖掘。 实验环境:1个Nimbus节点、2个Supervisor的Storm集群,每台机器内存8 GB,处理器为主频2.70 GHz的i7处理器,操作系统为CentOS 6.4。使用Kafka作为消息中间件,设置一个producer每秒选取数据集中有特定关联规则的数据,打上相应时间戳,按照每秒10 000条的速率发送至Kafka,算法的Storm拓扑从Kafka中获取数据进行相应挖掘计算。支持度设为0.5,置信度设为0.8,经典FP-Stream算法的支持度误差设为0.3,DPFP-Stream算法的支持度误差设为0.1,线程数设为3。 (2)实验结果与分析。 在FP-Stream算法与DPFP-Stream算法的对比方面:各算法分别处理完100万条数据后,两种算法的挖掘结果一致,而Storm系统的StormUI中显示FP-Stream相应线程的capacity(线程处理压力)为0.143,DPFP-Stream相应线程的平均capacity为0.113。这说明,尽管DPFP-Stream的参数支持度误差设置的比较小,但是在得出一致的挖掘结果的同时,单个线程所承受的计算压力反而减小了。 在DPFP-Stream算法的线程处理压力随算法参数设置和线程数的变化方面:实验结果如图5所示,在每秒到达拓扑的数据流速率为10 000条不变的情况下,无论支持度误差为0.1或是0.3,DPFP-Stream算法的capacity都随着Local Bolt线程个数的增加呈倒数减小,说明算法的处理能力可随线程数的增加呈近线性增加;而当支持度误差为0.1时,虽然线程处理压力比支持度误差为0.3时大,但是可以挖掘出更多的频繁项集。 图5 DPFP-Stream算法多线程测试结果 从图中可以看出,DPFP-Stream算法能有效地降低计算处理压力,并且不影响挖掘结果。此外,在线程处理压力不变的情况下,由于DPFP-Stream算法可以设置更低的支持度误差,故能在一定的情况下挖掘出FP-Stream算法挖掘不到的结果。 基于FP-Stream算法和分布式并行计算思想,文中设计了一种分布式并行化数据流频繁模式挖掘算法(DPFP-Stream),并在流计算平台Storm上进行了算法实现与性能测试。结果表明,该算法借助分布式并行化机制,能以更小的线程处理压力获得同样的挖掘精度,也说明了文中对FP-Stream算法所做的基于Storm的分布式并行化工作的可行性和有效性。 [1] Li Lingjuan,Li Xiong.An improved online stream data clustering algorithm[C]//Proceedings of second international conference on business computing and global informatization.Shanghai,China:[s.n.],2012:526-529. [2] Gaber M,Zaslavsky A,Krishnaswamy S.Mining data streams:a review[J].SIGMOD Record,2005,34(2):18-26. [3] Han J,Kamber M,Pei J.Data mining:concepts and techniques[M].[s.l.]:Elsevier,2006:242-248. [4] 孙大为,张广艳,郑纬民.大数据流式计算:关键技术及系统实例[J].软件学报,2014,25(4):839-862. [5] 孙玉芬,卢炎生.流数据挖掘综述[J].计算机科学,2007,34(1):1-5. [6] Charikar M,Chen K,Farach-Colton M.Finding frequent items in data streams[C]//Proceedings of automata,languages and programming.Berlin:Springer,2002:693-703. [7] 李国徽,陈 辉.挖掘数据流任意滑动时间窗口内频繁模式[J].软件学报,2008,19(10):2585-2596. [8] Ma Ke,Li Lingjuan,Ji Yimu,et al.Research on parallelized stream data micro clustering algorithm[C]//Proceedings of ICCAET 2015.Zhengzhou,China:[s.n.],2015:629-634. [9] Giannella C,Han J,Pei J,et al.Mining frequent patterns in data streams at multiple time granularities[J].Next Generation Data Mining,2003,212:191-212. [10] 唐耀红.数据流环境中关联规则挖掘技术的研究[D].北京:北京交通大学,2012. [11] 刘学军,徐宏炳,董逸生,等.挖掘数据流中的频繁模式[J].计算机研究与发展,2015,42(12):2192-2198. [12] 程转流,王本年.数据流中的频繁模式挖掘[J].计算机技术与发展,2007,17(12):53-55. [13] Jin R,Agrawal G.An algorithm for in-core frequent itemset mining on streaming data[C]//Proceedings of fifth IEEE international conference on data mining.[s.l.]:IEEE,2005:210-217. [14] Han J,Pei J,Yin Y,et al.Mining frequent patterns without candidate generation:a frequent-pattern tree approach[J].Data Mining and Knowledge Discovery,2004,8(1):53-87. [15] Marz N.Storm:distributed and fault-tolerant realtime computation[EB/OL].2012.http://storm.apache.org. [16] Apache.Apache Kafka:a high-throughput,distributed,publish-subscribe messaging system[EB/OL].2015.http://kafka.Apache.org. Distributed Parallel Algorithm of Mining Frequent Pattern on Data Stream MA Ke,LI Ling-juan,SUN Du-jing (School of Computer,Nanjing University of Posts and Telecommunications,Nanjing 210003,China) In order to improve the efficiency of mining frequent pattern on data stream,a Distributed Parallel Algorithm of Mining Frequent Pattern on Data Stream,named DPFP-Stream,is designed in this paper based on the ideas of classical FP-Stream and the distributed parallel computing.It divides the task of building frequent pattern tree into two parts:local and global,and introduces a new parameter “current time”.The arrival data will be equally distributed into different local nodes.Then every local node uses FP-Growth algorithm to produce candidate frequent items,and packages them with relevant support count according to unit time,and sends them to the global node.The global node combines the results produced by local nodes according to the “current time” and updates the global Pattern-Tree.The results of implementing DPFP-Stream algorithm and testing its performance on Storm,a distribution data stream computing platform,show that the computing efficiency of DPFP-Stream can increase linearly with the increasing of local nodes or the local bolts,and DPFP-Stream is applicable to effectively mine frequent pattern from data stream. data stream;frequent pattern;distributed parallelization;Storm 2015-10-10 2016-01-20 时间:2016-06-22 国家自然科学基金资助项目(61302158,61571238);中兴通讯产学研项目 马 可(1991-),男,硕士研究生,CCF会员,研究方向为流数据挖掘、信息安全;李玲娟,教授,CCF会员,通讯作者,研究方向为数据挖掘、信息安全、分布式计算。 http://www.cnki.net/kcms/detail/61.1450.TP.20160621.1701.014.html TP311 A 1673-629X(2016)07-0075-05 10.3969/j.issn.1673-629X.2016.07.163 DPFP-Stream算法在Storm平台上的实现
4 实验与结果分析
5 结束语
