评价对象抽取研究
2016-02-24张彩琴
张彩琴
(吕梁学院数学系,山西吕梁033000)
评价对象抽取研究
张彩琴
(吕梁学院数学系,山西吕梁033000)
文章针对第三届中文倾向性分析评测中的评价对象抽取方法进行总结,分析各种方法的特点,最后提出评价对象抽取存在的问题及未来的研究方向.
评价对象;CRF模型;规则;模板
0 引言
近年来,互联网飞速发展.人们不仅能在互联网上随意表达自己的情感、观点、意见——导致大量主观性文本出现,而且希望能够从海量数据中迅速获取自己感兴趣的知识.如何在从这数不胜数的文本信息中快速获取有价值的知识已成为研究的热点,这就促使文本情感倾向的研究迅速发展.目前,文本情感倾向分析研究持续成为自然语言处理领域的一个研究热点问题,吸引了国内外许多学者的关注.
文本情感倾向分析涉及的研究任务是非常具有挑战性的.黄萱菁[1]将其简略地分为两大类:倾向性信息抽取和倾向性分类.评价对象是情感信息抽取任务中的一个重要的分支,其研究对于情感倾向分析至关重要.
评价对象(Opinion Target)是指评论文本所针对的对象或对象的属性.如,产品评论中某种产品对象(如“飞利浦HX5251”)或对象的部件(如“显示屏”)或属性(如“性价比”)等.它是情感分析任务中情感信息的一个重要组成部分.研究评价对象的抽取具有十分重要的价值.但由于网名描述评价对象的多样性和丰富性,致使从中文评论文本中准确的识别评价对象成为一个比较困难的问题.虽然中文倾向性分析评测将评价对象抽取列为主要的评测任务之一,但评测结果还不太理想[2,3].第三届COAE2011仍然将评价对象的抽取作为评测任务中的一项子任务.
1 研究方法
目前抽取评价对象主要有两种方法:一种是基于机器学习模型进行训练获得模型;另一种是根据句法结构获得候选特征集合,然后利用规则进行进一步筛选.第三届中文倾向性评测(COAE2011)论文集中关于评价对象抽取方法主要有:基于CRF模型、规则、模板、统计信息以及依存语法、句法分析等及其综合使用,共有12支队伍研究该项任务并提交结果.
1.1 基于CRF模型
CRF模型[4]是一种序列标注模型,能够很好的捕获上下文信息,在自然语言处理中具有举足轻重的作用,已被许多研究者成功应用于不同的任务中,如中文分词、词性标注、评价对象抽取、命名体识别等.本届评测中王中卿[5]、杨亮[6]、徐冰[7]都采用CRF模型加入不同的特征对评价对象进行抽取,均取得了不错的成绩.
文献[5]结合机器学习的方法和规则的方法对评价对象进行识别,即将词法特征和依存关系特征与CRF模型结合.特征描述如下表1.在本次评测中宏平均(0.091 606)与微平均均(0.144 700 9)取得了最好的成绩.

表1 识别评价对象的特征描述
文献[6]采用多特征融合的方法抽取评价对象:将词特征、词性特征、浅层句法特征加入CRF模型中.由于评价对象一般情况下是N或NP,故正确的识别词性对其抽取有很大的帮助.例如“操作系统使用起来非常繁琐,比Linux差远了”,进行分词词性标注后得到“操作系统/n使用/v起来/vf非常/d繁琐/a,/wd比/p Linux/x差/a远/a了/ule”,评价对象“操作系统”的词性为名词.但是对于短语级别的评价对象效果不好,故引入了浅层句法特征[7].特征描述如下表2.

表2 识别评价对象的特征描述
该方法同样取得良好的效果.但是更多的是考虑上下文语境对任务的影响,忽略了领域知识的因素,在后期的研究中,考虑领域知识与情感信息抽取的有效结合.
文献[8]从抽取的评价搭配中提炼评价对象.该文将搭配的抽取分为核心搭配抽取和扩展核心搭配两步.首先采用搭配词典进行匹配,如果失败,则采用以观点词为中心的窗口中的名词与观点词搭配,对于没有找到搭配的句子,将组块分析思想融入CRF模型进行自动识别.然后,采用一些规则对上述搭配中的噪声进行过滤,流程见图1.抽取结果受领域知识和上下文语境的影响.
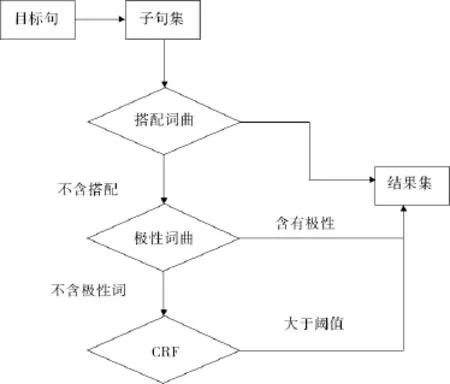
图1 评价搭配抽取流程图
1.2 规则与统计结合方法
史兴[9]等针对属性词-观点对的抽取,融合语法词性规则,利用互信息等统计信息以及机器学习的方法对其进行研究.
该文献首先用采取语法词性关系对属性词——观点对抽取,得到一个领域相关的属性词——观点词搭配表;然后从该搭配关系中提取出一个观点词表和属性词表,采用已有的字典对其扩展;再利用规则——属性词只可能与其最近的观点词进行搭配,对搭配关系进行再抽取,利用互信息对搭配关系中的噪声进行过滤;最后再利用互信息对观点词和属性词进行扩展.
两个词w1与w2的互信息计算公式如下(1)所示.

该方法在本次评测中效果不错,但还存在需要改进的方面:1)观点词、属性词扩展方面较粗;2)如何有效的提取跨小句出现的属性词-观点词对;3)如何制定相对全面的规则;4)如何将领域知识运用到该任务中.
朱圣代等[10]基于词频统计方法抽取评价对象.该方法首先对预料预处理,即分词、词性标注;然后提取其中的N或NP,过滤掉阈值低的N或NP及单个字;最后利用PMI进行筛选得到最终的评价对象.该方法的整体效果接近于平均水平.两个词的PMI计算公式如下:
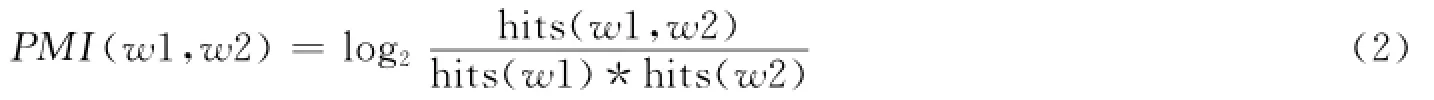
1.3 句法分析方法
唐都钰等[11]人基于短语句法路径库抽取评价搭配,进一步提取其中的评价对象.该方法首先通过已构建的观点词和评价对象故有的特征——名词,构建短语句法路径库并对其泛化;然后抽取评价搭配,并对其进行合并,即同一句子中如果两个评价搭配具有相同的评价词语并且评价对象相邻,那么将这两个评价对象合并,生成最终的评价对象;同理,对评价词进行合并.该方法还存在一些不足,如没有考虑领域知识,另合并会导致一些错误的产生.
李岩等[12]在观点句的基础上根据中文文本的结构信息和语法特点,应用词性标注、句法分析方法,对观点句中的评价对象进行抽取.抽取规则如下:
1)依据评价词词表寻找adj,然后根据句法分析合并修饰该adj的adv,将合并结果作为评价词;
2)查找每一个分句,如果存在SBV关系,则抽取出存在SBV关系的词对(评价对象,评价词);如果不存在,则查找DE关系,向后查找跟当前形容词有DE关系的名词,若没有DE关系,直接向前查找名词.
3)对于找到的评价对象,合并其父节点,将合并结果作为最终的评价对象.
1.4 基于规则和模板的方法
宋施恩等[13]首先采用三步特征扩展方法构建领域评价词,然后以该词为中心,m为窗口查找最近的名词或动名词,作为它的直接评价对象.
赵立东等[14]利用核心词扩展技术研究该项子任务.评价对象的核心词认为是具有领域实体性质的名词,如果句子中出现nn;n、n;n和n;n模板时,将其作为评价对象.该方法在精确率上取得较好的效果,但由于噪声使得召回率偏低.
张成功等[15]采用模板抽取评价对象.算法如下:首先设置一个动态滑动窗口,在其内分别向前、向后寻找与观点词最近的名词;然后以名词为中心扩展得到NP,扩展模板有:n+n,n+n+n,n+n+vn,n+v+n,n+vn,n+vn+n,n+x,n+的+n,n+的+vn,nl,nrf,nz,nz+的+n,v+n,vn,vn+n;若窗口内没有名词,则寻找vn或x,采用同样方式扩展.该方法各项指标都较低,而且不具有领域适应性.
王菲等[16]采取基于规则的方法抽取评价对象.该方法首先给出评价搭配抽取模式:n+adjs+end,n+v+adjs+end,adjs+的+n,adjs+的+v|vn+n,adjs+地+v+n,v+得+adjs,begin|n+v+n+adjs,begin+v+adj+end,n+z+adjs*+end,nouns+d+v+end),从中提炼出被修饰成分:n,n+v,v+n、v,n+v+n;然后通过计算相似词的方法对被修饰成分进行扩充.该方法采用的模式牺牲了部分召回率.
2 小结及存在的问题
本次评测中大部分的方法在电子领域取得的效果较好,原因如下:1)电子领域(D)的评价对象大多是产品自己本身或本身的一部分,词性特征较为明显.而娱乐领域(E)评价对象相对较多,有较强的不确定性.金融领域(F)中好多评价对象不是N或NP.2)系统抽取评价对象时主要是基于产品属性的,忽略了命名体、带引号或书名号的评价对象.3)对于切词系统中不能正确切分的词语,如“性价比”等无法处理.
在目前关于评价对象抽取的研究工作中,传统的有监督的方法虽然能取得不错的效果,但是在不同领域,需要重新训练模型,导致模型不具有领域适应性[17].另外不少研究者提出了无监督的方法,他们发现评价对象与评价词在句子中往往是相邻的而且存在某种关系.主要通过构建一些规则描述评价对象和评价词之间的关系进而抽取倾向性信息.但是规则的构建一般需要大量的人工参与,无法保证规则库的完备与重现.无监督方法中的通过语法、句法依存关系分析句子的结构,识别评价对象与抽取评价词,往往只适合于句子成分完整的文本,但对于结果不完整的句子或者口语化的网络评论文本,利用句法分析可能产生错误,导致最终抽取结果不正确.可见领域知识对该领域评价对象的抽取有一定的指导作用.领域知识的构建将是今后研究的一个方向.而且寻找一种适合不同结构的评论文本的评价对象抽取方法显得尤为重要.
[1]黄萱菁,张 奇.文本情感倾向分析[J].中文信息学报,2011,25(6):118-125
[2]赵 军,许洪波.中文倾向性分析评测技术报告[R].第一届中文倾向性分析评测(COAE2008),2008:1-22
[3]许洪波,姚天昉.第二届中文倾向性分析评测技术报告[R].第二届中文倾向性分析评测(COAE2009),2009:1-23
[4]Lafferty J,McCallum A,Pereira F C N.Conditional Radom fields probabilistic models for segmenting and labeling sequence data[C].Proceedings of the 18th International Conference on Machibe Learning.San Framcisce CA:Morgan Kaufmann Publishers Inc,2001:282-289
[5]王中卿,王荣洋.Suda_SAM_OMS(Suda Sentiment Analysis teaM Opinion Mining System)情感倾向性分析技术报告[C].第三届中文倾向性分析评测(COAE2011).山东:[s.n.],2011:25-32
[6]徐 冰,吴建伟.基于多特征融合的文本情感分析研究[C].第三届中文倾向性分析评测(COAE2011).山东:[s.n.],2011:106-112
[7]徐冰等.基于浅层句法特征的评价对象抽取研究[J].自动化学报,2011,37(10):1241-1247
[8]杨 亮,王 昊.DUTIR COAE2011评测报告.第三届中文倾向性分析评测(COAE2011),2011:33-41
[9]史 兴,房 磊.规则与统计相结合的观点极性分类与观点抽取[C].第三届中文倾向性分析评测(COAE2011).山东:[s.n.],2011:65-76
[10]朱圣代,徐向华,叶 正.评价对象、短语、搭配关系抽取及倾向性判断[C].第三届中文倾向性分析评测(COAE2011).山东:[s.n.],2011:136-142
[11]唐都钰,胡 燊.HIT_SCIR_OMS:情感分析系统[C].第三届中文倾向性分析评测(COAE2011).山东:[s.n.],2011:113-119
[12]李 岩,张佳玥,林宇航,等.PRIS_COAE COAE2011评测报告[C].第三届中文倾向性分析评测(COAE2011).山东:[s.n.],2011:42-51
[13]宋施恩,樊兴华.基于特征扩展的情感领域分析系统[C].第三届中文倾向性分析评测(COAE2011).山东:[s.n.],2011:157-163
[14]赵立东,王素格.基于多策略的中文文本倾向性分析技术[C].第三届中文倾向性分析评测(COAE2011).山东:[s.n.],2011:88-96
[15]张成功,刘培玉.基于词典的中文倾向性分析报告[C].第三届中文倾向性分析评测(COAE2011).山东:[s.n.,2011:149-156
[16]王 菲,吴云芳.词语搭配情感倾向的自动判别方法[C].第三届中文倾向性分析评测(COAE2011).山东:[s.n.],2011:52-64
[17]陈兴俊,魏晶晶.基于词对其模型的中文评价对象和评价词抽取[J].山东大学学报(理学版),2016,51(1):58-64
Comment Target Extraction Reseach Of The Third Chinese Opinion Analysis Evaluation(COAE2011)
ZHANG Caiqin
(Lvliang University,Department of Mathematics,Lvliang 033000,China)
To make made a summary and analysis about the method of comment target extractionof the third Chinese opinion analysis evaluation.The question and trend of the comment target extraction were concluded finally.
comment target;CRF model;rules;template
1672-2027(2016)04-0026-04
TP391
A
2016-08-27
张彩琴(1986-),女,山西吕梁人,硕士,吕梁学院助教,主要从事智能信息检索研究.
