基于PCA降维的协同过滤推荐算法
2016-02-23李远博
李远博,曹 菡
(陕西师范大学 计算机科学学院,陕西 西安 710062)
基于PCA降维的协同过滤推荐算法
李远博,曹 菡
(陕西师范大学 计算机科学学院,陕西 西安 710062)
在信息过载的时代,推荐系统通过分析用户的历史行为,为用户兴趣建模,主动给用户推荐能够满足他们兴趣和需求的信息,已经被广泛应用于电子商务等多个领域。但是在推荐系统中,用户评分数据极端稀疏,矩阵的稀疏性导致推荐算法在相似性计算时存在较大误差,进而导致最近邻居选择的不准确,从而影响推荐质量。针对上面存在的问题,文中通过对评分矩阵采用PCA降维的方法,降低了评分矩阵的稀疏性,保留了最能代表用户兴趣的维数,使得相似性计算更加准确,保证了最近邻居选择的准确性,从而提高了推荐质量。实验结果表明,在公开数据集上与传统的协同过滤推荐算法相比较,文中提出的算法具有较高的准确度和覆盖度。
主成分分析;降维;协同过滤;推荐算法
1 概 述
随着人类进入到信息化时代,信息呈现出快速、爆炸式增长,信息出现过载。推荐系统[1]通过对用户的历史记录的分析,为用户建立兴趣模型,主动给用户推荐能够满足他们兴趣和需求的信息。从电子商务、音乐视频网站,到在线广告和个性化阅读,到处都是推荐系统的应用。
在推荐系统中,协同过滤(Collaborative Filtering,CF)[2]是应用最广泛的个性化推荐算法。首先通过分析历史数据,计算出用户之间或者项目之间的相似度;其次根据相似度建立起近邻关系[3],然后在近邻关系中,选择与目标距离最近的用户对项目的评分数据来预测目标用户对特定项目的评分;最后针对目标用户产生相应的推荐。
随着电子商务信息规模的不断扩大,数据量都在增加,针对以前的推荐系统,很少有用户对项目进行评分,这就导致推荐系统评分数据的稀疏性[4]。对于任何一个优秀的推荐系统,用户对项目的评分数据往往只占有一小部分,而未评分数据常常比用户的已有评分更多,由于用户之间选择的差异也会加重数据的稀疏性。在传统的向量空间模型中,评分矩阵的稀疏性对于推荐系统中使用的统计方法都会产生计算不准确的影响。在推荐系统中,用户的最近邻居就是通过统计学方法进行相似性计算,因此如何解决矩阵的稀疏性成为推荐系统的关键。
为了降低评分矩阵的稀疏性,早期Pirasteh等通过将电影的类型和导演信息进行填充,进而来降低矩阵的稀疏性问题[5],该方法需要用户额外评价电影类型和导演等信息;Wang等首先对用户已经评分的数据进行聚类,然后结合Slope One算法来对未评分数据进行预测填充,以此来降低矩阵的稀疏性问题[6];Pitsilis等首先使用已有的评分数据建立信任关系模型,进而来预测未评分的数据,通过该方法可以有效解决矩阵的稀疏性问题和冷启动问题[7],但是此方法并不是社会网中真正意义上的信任关系;文献[8]中首先使用K-means算法对项目进行聚类分析,然后将聚类分类后的结果结合已评分的数据来计算用户相似性;黄创光等针对传统K近邻算法中存在K固定这一缺陷,提出了利用不确定近邻K来进行计算的最近邻居推荐[9]等。
2004年美国《连线》杂志主编ChrisAnderson发表了题为《TheLongTail》一文[10]。作者认为,基于互联网的销售方式以及其他因素已经将媒体和娱乐产业推向后一种模式为主导的世界,那些不起眼的产品“长尾”吸引了大量的用户,ChrisAnderson指出“你可以在长尾中找到任何想要的,有以前的旧专辑,他们仍然被人们怀念和喜爱并不断涌现出新的粉丝;有现场制作的音乐,B面的内容,混录版歌曲,设置封面;还有数千种风格流派不同的利基项目:例如整个TowerRecords唱片公司在80年代推崇的长发乐队或节奏电子音乐”。在互联网时代,由于网络货架成本的低廉,电子商务中物品不受货架的限制,大多数不热门商品都有机会销售,这些商品由于其数量庞大,总体销售额往往超过热门商品。在长尾分布中,热门商品代表着大部分用户的选择,而长尾商品则代表了用户的个性化选择。因此,在研究用户的兴趣需求的同时,如何挖掘长尾商品,来提高对用户的个性化推荐,进而提升销售额,这正是个性化推荐必须解决的主要问题。
在推荐系统中,通过对商品长尾分布的分析,挖掘用户的历史记录,分析用户的个性化需求,从而将那些不容易发现的但是用户感兴趣的长尾商品精确地推荐给用户。推荐系统本质上旨在向用户展示那些不那么广泛流行的项目,但这些项目符合用户的兴趣,这一点可以从他们过去的购买历史中推断。
文中通过对评分矩阵采用PCA降维,降低了评分矩阵的稀疏性,保留了最能代表用户兴趣的维数,使得相似性计算更加准确,保证了最近邻居选择的准确性,从而提高了推荐质量,并且验证了算法具有较高的准确度和覆盖度。
2 现有算法分析
协同过滤推荐算法推荐原理:如果大多数用户对项目的评分数据相似,那么当前用户也会有类似的项目评分[11]。协同过滤推荐利用用户对项目数据的评分记录,进而生成评分矩阵来分析用户的兴趣,利用统计学知识在已评分的用户中找到与目标兴趣相似的用户,从而找到目标用户的最近邻居,再结合这些邻居用户对项目的评分进行预测并产生推荐。传统的协同过滤算法步骤如下:
(1)求解用户和项目间的相似度矩阵;
(2)根据相似度矩阵求出目标的最近邻居;
(3)对未评分项目进行预测并进行推荐。
2.1 相似性计算
在推荐系统中,算法的第一步就是计算用户和用户之间的相似性。余弦相似度、皮尔逊相关系数和修正的余弦相似度[12]是目前最重要的度量方法。
(1)余弦相似度。
通过计算空间夹角的余弦值来求解用户之间的相似性。在推荐系统中,用户的评分被看作是n维向量空间,用户i和用户j之间的相似性可以表述为:
(1)
(2)皮尔逊相关系数。
它是一种线性相关系数,通过两个变量之间的协方差和标准差的商来计算,其表达式为:
(2)
(3)修正的余弦相似度。
余弦相似度在计算相似性时没有考虑不同用户的评分尺度,在推荐系统中,通常评分区间为1-5,有的用户喜欢打高分,有的用户打低分。此计算方法通过减去用户的平均评分来改善这一缺陷。其表达式为:
(3)
2.2 基于用户的协同过滤算法
基于用户的协同过滤算法,首先会生成用户的评分矩阵,其次根据用户评分矩阵,利用相似性计算方法得到用户之间的相似性,求出K近邻,最后根据K近邻来对未评分项目进行预测,并产生推荐。计算公式[13]如下:
(4)
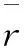
2.3 传统的相似性计算分析
在传统的计算方法中,相似性是利用用户对所有项目的评分数据来计算,这就会导致最终的评分矩阵数据维数高,评分向量的维数过高会增加相似性计算的复杂度,而且维数过高的向量对于相似性的度量也会造成负面影响。在统计学中对于已知的样本数目,存在维数的极限值,当使用的数据向量的维数一直增加时,算法的性能并不会随着维数的增加而增加,维数超过极限值之后,算法性能反而会退化。随着电子商务规模的不断扩大,用户和项目数据都在快速增长,但是数据量却极度稀疏,尤其是评分数据,在大型电子商务网站中,用户评分的项目数据一般不会超过总数的1%[14]。
文中对MovieLens数据集进行统计分析,其中有8.8%的电影仅仅被一个用户进行过评分,18%的电影被超过一百个用户进行过评分。如果将所有的项目都用来进行相似性计算,不仅不能区分用户之间的相似性,反而会给相似性计算带来误差,流行性物品不能反映用户的兴趣,而评分极其少的物品又会增加矩阵的稀疏性,对统计学方法而言没有意义。
基于此,文中在分析数据集的基础上提出了基于PCA降维的方法,将数据集进行简化,在保留主要特征的同时降低数据集的维数,同时明显降低了简化后的评分矩阵的稀疏性,由于降低了稀疏性,使得相似性计算更加准确,提升了最近邻居选择的准确性,从而提高了推荐质量。
3 基于PCA降维的算法
3.1 数据表述


表1 用户-项目评分矩阵
在统计学中,当维数很高时,导致可用数据很稀疏,然而从统计学意义上说,稀疏性也是一个重要问题。在推荐系统中,用户的最近邻居搜索就是通过相似性进行分组,然而在高维数据空间中,所有的可用数据变得很稀疏,因此使得相似性计算非常不准确。
3.2 项目流行度分析
对很多互联网数据的研究发现,互联网上的很多数据都满足一种称为PowerLaw的分布,这个分布在互联网领域称为长尾分布,其流行度满足表达式:
f(x)=axk
(5)
长尾分布出现在各个领域,其实长尾分布最早是被统计学家发现的。1932年,哈佛大学的语言学家Zipf在研究英文单词的词频时发现,如果将单词按照出现的频率进行排列,那么每个单词出现的频率和它在热门排行榜中排名的常数次幂成反比,这个分布后来被称为Zipf定律。为了研究项目的流行度是否具有长尾分布,文中对MovieLens数据集进行分析。
图1显示了MovieLens数据集中电影流行度的分布曲线。电影的流行度是指对电影进行过评分的用户总数。图中的曲线是双对数曲线,而长尾分布曲线就是这种双对数曲线,从而证明物品流行度具有长尾分布。

图1 MovieLens数据集中物品流行度的长尾分布
3.3 PCA降维
主成分分析(Principal Component Analysis,PCA)是一种分析、简化数据集的技术。主成分分析通常用于减少数据集的维数,同时保持数据集中对方差贡献最大的特征[15]。该方法依据样本空间中的位置分布,把样本点在多维空间中的最大变化方向,即方差最大方向,作为判断向量来实现特征提取。主成分分析由卡尔·皮尔逊于1901年提出,用于分析数据及建立数理模型。其方法主要是通过对协方差进行特征分解,以得出数据的主成分与它们的权值。
对于一个给定的样本空间Xm×n,用PCA对矩阵Xm×n进行降维分析,具体步骤如下:
(1)求出样本均值。
(2)计算Xm×n的协方差矩阵公式为:
(3)计算协方差矩阵的特征值和特征向量,其中特征值按照从大到小排列:
λ=(λ1,λ2,…,λn),λ1≥λ2…≥λn
(4)计算在每一维的投影:
得到一个降维的投影矩阵,该投影矩阵就是该样本空间的主成分并且按照主成分从大到小排列。
3.4 基于PCA降维的推荐
传统的向量空间模型存在数据灾难,对于成百上万的项目来说,用户的项目评分维度就会增加。在高维空间中的数据集可以通过削弱减至低维空间,而不必失去其重要性质。这一点可以通过降维方法有效反映。
在文中提出的基于PCA降维的协同过滤推荐算法中,计算用户和用户的相似性时先采用PCA方法对评分矩阵进行降维处理,然后进行相似性计算。Sarwar利用MovieLens数据集对余弦相似度、皮尔逊相关系数和修正的余弦相似度进行了对比[11]并将MAE作为评测指标。实验结果表明,利用修正的余弦相似度进行K近邻计算,进而进行评分预测推荐可以获得最优的MAE。因此文中采用修正的余弦相似度来进行相似度计算,在得到用户的相似度之后采用最近邻推荐。
鉴于降维的优点,文中引入PCA降维技术对用户评分矩阵进行降维,然后通过降维后的用户评分矩阵计算用户的相似性,提高相似性计算的准确性,保证最近邻居选择的准确性。
算法流程如图2所示。
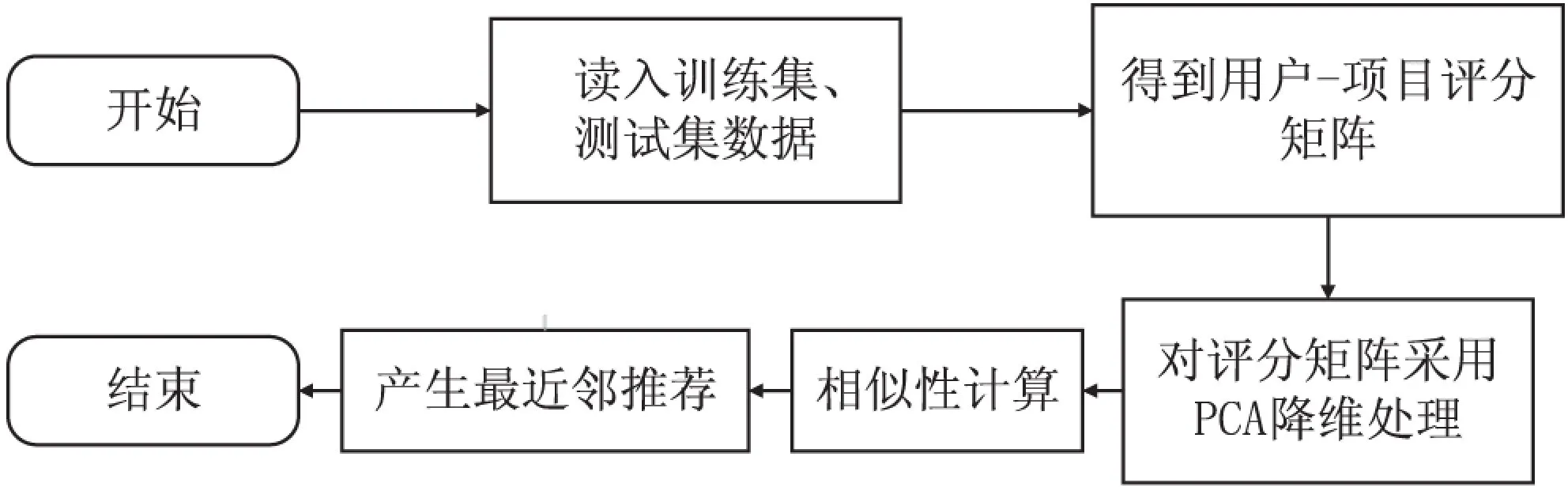
图2 基于PCA降维的协同过滤推荐算法基本流程
4 实验分析
4.1 数据集
文中以MovieLens数据集为例,来评测文中提出的基于PCA降维的协同过滤算法和传统的基于用户的协同过滤算法。在该数据集中,包含了943个用户对1 682个项目的10万条评分记录,每一个用户至少对20部电影进行评分,电影类别为19类,用户的评分范围为1-5。
4.2 评价标准
在推荐系统中,平均绝对误差(MAE)和覆盖度(Coverage)是两个最重要的评价指标。
MAE数值越低说明推荐算法越精准,计算公式如下:
(6)

覆盖度是一项被广泛应用于评价推荐算法发掘长尾的能力,覆盖率越高,说明推荐算法越能够将长尾中的物品推荐给目标用户。计算公式如下:
(7)
其中,IP(u)是推荐算法为用户u推荐的项目集;IR(u)是用户u在测试集上进行评分的项目集。
4.3 实验结果
最近邻K的个数往往能够影响推荐的效果,因此在实验中,针对不同的K,分别利用两种算法进行了MAE和Coverage的分析比较。
实验中通过PCA方法将用户评分矩阵维数降低到用户个数的矩阵,即将R943×1682降低到R943×943,实验结果如图3和图4所示。
由图3和图4可以看出,文中提出的基于PCA降维的协同过滤推荐算法具有较小的MAE和较大的Coverage。这是因为在计算用户相似性时,对用户评分矩阵进行了PCA降维,通过PCA降维,将用户评分矩阵中最能反映用户兴趣的特征进行了保留,去除了不能反映用户兴趣的噪声数据,使得评分矩阵的维数和稀疏性都有了明显降低。在此基础上进行用户相似性的计算更加准确,保证最近邻居选择的准确性,从而使算法的推荐更准确。

图3 不同推荐算法的MAE比较
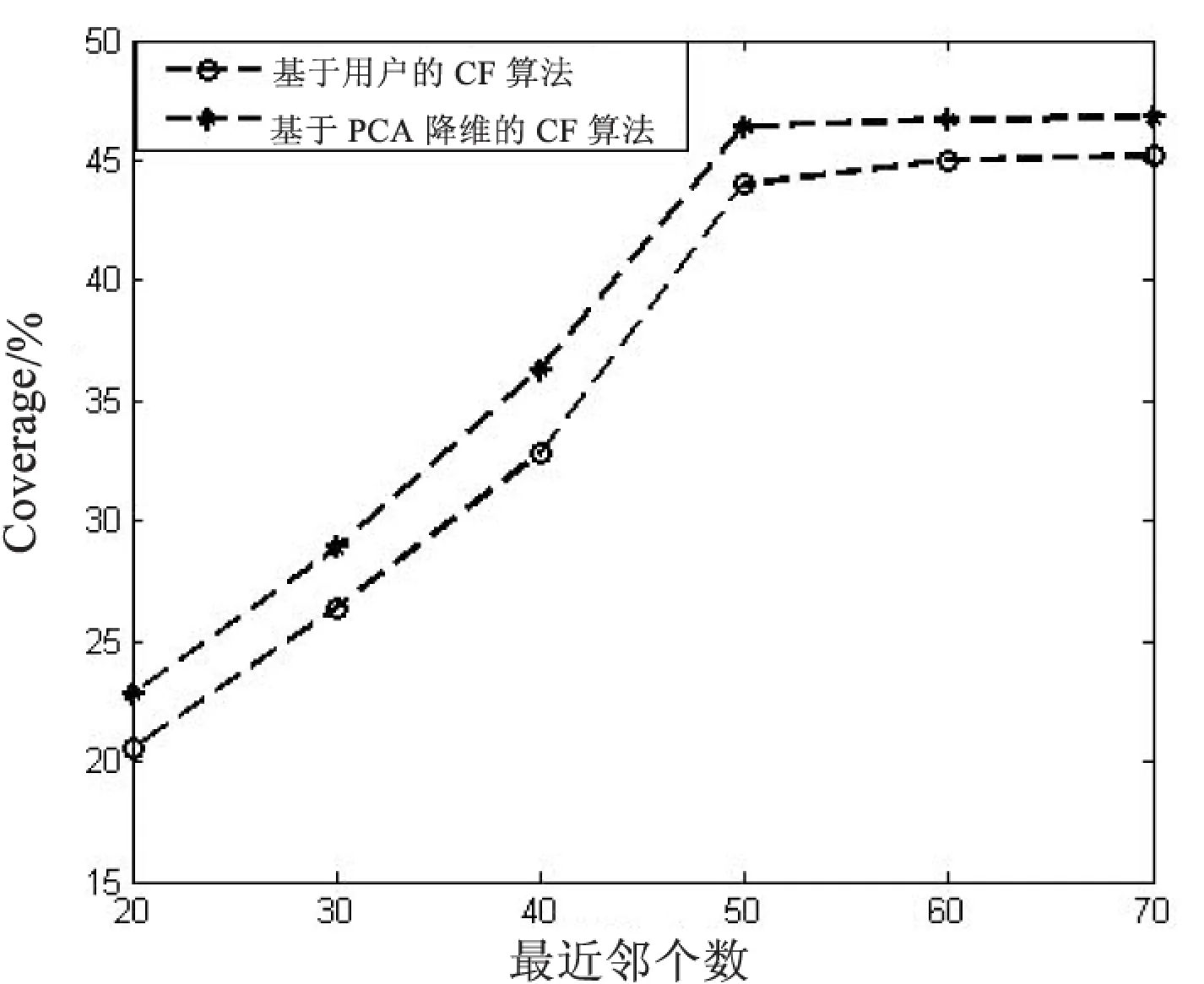
图4 不同推荐算法的Coverage比较
5 结束语
文中首先分析在用户评分数据极度稀疏的情况下统计学方法在计算用户相似性时存在的问题。针对用户评分矩阵的稀疏性,文中提出了如何用PCA方法对推荐系统中的用户评分数据进行降维处理,通过降维不仅降低了稀疏性,而且使得相似性计算中保留的数据是最能代表用户兴趣的特征向量,使得在计算相似性时更加准确,从而保证了最近邻居选择的准确性。通过对MovieLens数据进行降维处理,并通过实验验证了提出的算法可以降低评分矩阵的维数,并且有效降低了评分矩阵的稀疏性,解决了传统相似性度量方法在高维数据中存在的弊端,提高了推荐系统的推荐质量。
[1]KonstanJA.Introductiontorecommendersystems:algorithms
andevaluation[J].ACMTransactionsonInformationSystems,2004,22(1):1-4.
[2]BobadillaJ,OrtegaF,HernandoA,etal.Improvingcollaborativefilteringrecommendersystemresultsandperformanceusinggeneticalgorithms[J].Knowledge-basedSystems,2011,24(8):1310-1316.
[3]BellRM,KorenY.Improvedneighborhood-basedcollaborativefiltering[C]//Procof13thACMSIGKDDinternationalconferenceonknowledgediscoveryanddatamining.[s.l.]:ACM,2007.
[4]LiuLM,ZhangPX,LinL,etal.Researchofdatasparsitybasedoncollaborativefilteringalgorithm[J].AppliedMechanicsandMaterials,2014,462:856-860.
[5]PirastehP,JungJJ,HwangD.Item-basedcollaborativefilteringwithattributecorrelation:acasestudyonmovierecommendation[M]//Intelligentinformationanddatabasesystems.[s.l.]:SpringerInternationalPublishing,2014:245-252.
[6]WangJ,LinK,LiJ.Acollaborativefilteringrecommendationalgorithmbasedonuserclusteringandslopeonescheme[C]//Procof8thinternationalconferenceoncomputerscience&education.[s.l.]:IEEE,2013:1473-1476.
[7]PitsilisG,KnapskogSJ.Socialtrustasasolutiontoaddresssparsity-inherentproblemsofrecommendersystems[C]//ProcofACMrecommendersystemworkshoponrecommendersystem&thesocialweb.[s.l.]:ACM,2009:33-40.
[8]WeiS,YeN,ZhangS,etal.Collaborativefilteringrecommendationalgorithmbasedonitemclusteringandglobalsimilarity[C]//Procoffifthinternationalconferenceonbusinessintelligenceandfinancialengineering.[s.l.]:IEEE,2012:69-72.
[9] 黄创光,印 鉴,汪 静,等.不确定近邻的协同过滤推荐算法[J].计算机学报,2010,33(8):1369-1377.
[10]AndersonC.Thelongtail[J].WiredMagazine,2004,12(10):170-177.
[11] 项 亮.推荐系统实践[M].北京:人民邮电出版社,2012:44-64.
[12]SarwarB,KarypisG,KonstanJ,etal.Item-basedcollaborativefilteringrecommendationalgorithms[C]//Proceedingsofthe10thinternationalconferenceonWorldWideWeb.[s.l.]:ACM,2001:285-295.
[13] 罗 辛,欧阳元新,熊 璋,等.通过相似度支持度优化基于K近邻的协同过滤算法[J].计算机学报,2010,33(8):1437-1445.
[14]LindenG,SmithB,YorkJ.Amazon.comrecommendations:item-to-itemcollaborativefiltering[J].IEEEInternetComputing,2003,7(1):76-80.
[15]RaikoT,IlinA,KarhunenJ.Principalcomponentanalysisforlargescaleproblemswithlotsofmissingvalues[C]//ProcofECML2007.Berlin:Springer,2007:691-698.
Collaborative Filtering Recommendation Algorithm Based on PCA Dimension Reduction
LI Yuan-bo,CAO Han
(School of Computer Science,Shaanxi Normal University,Xi’an 710062,China)
In the era of information overload,recommender system can help users find their interest and recommend the satisfactory information to analyze their historical behavior,so it is widely used in electronic commerce and other fields.But the user rating matrix is extremely sparse in recommender systems.The sparsity of the matrix leads to great error in the calculation of similarity of recommendation algorithms,bringing about the nearest neighbor sections is not accurate,thus affecting the quality of recommendation.Aiming at the problems above,a dimension reduction method based on PCA was proposed to reduce the sparsity of user rating matrix,by this method the remain matrix retain the most representative characteristic of the user interest,so that the similarity calculation is more accurate to ensure the accuracy of the nearest neighbors,thereby improving the quality of the recommendation.The experimental results show that compared with the traditional collaborative filtering algorithm,the algorithm proposed reaches a high accuracy and coverage.
PCA;dimension reduction;collaborative filtering;recommendation algorithm
2015-01-28
2015-05-17
时间:2016-01-26
国家自然科学基金资助项目(41271387);陕西师范大学院士创新基金资助项目(999521);西安市科技计划基金资助项目(SF1228-3)作者简介:李远博(1988-),男,硕士研究生,研究方向为高性能计算、数据挖掘;曹 菡,博士,教授,研究方向为数据挖掘、智慧旅游、高性能计算。
http://www.cnki.net/kcms/detail/61.1450.TP.20160126.1517.002.html
TP301.6
A
1673-629X(2016)02-0026-05
10.3969/j.issn.1673-629X.2016.02.006
