基于依存句法和二叉树模型的评价对象抽取
2016-02-23张建华李晓乐
张建华,翁 鸣,李晓乐,刘 芳
(广西财经学院 实验教学中心,广西 南宁 530003)
基于依存句法和二叉树模型的评价对象抽取
张建华,翁 鸣,李晓乐,刘 芳
(广西财经学院 实验教学中心,广西 南宁 530003)
识别出评论中的评价对象有利于商家了解用户关心的产品特征,为进一步设计和升级产品提供决策。根据词之间的相互依赖关系,提出一种基于依存句法分析和二叉树模型的评价对象识别方法。首先通过依存关系分析,得到句法结构语句;然后采用二叉树模型,将名词和名词词组出现频率高的句法结构构造成二叉树;最后采用二叉树遍历算法对树库中的每一棵二叉树进行遍历,将所得的字符串进行组合,最终得到具有完整意义的评价对象。实验结果表明,该方法在两类测试集上都取得了一定的效果。
依存句法分析;评价对象;二叉树
0 引 言
用户常对购买服饰的尺码、款型或电脑价格、售后服务等做出评价,这些经过用户评价的实体属性被称为评价对象(Evaluation Object)[1]。识别出正确的评价对象对信息发布者和生产商都有着巨大的利益。商家从评价对象中能够了解用户最在意的产品特征,使其在生产商品时从用户的角度出发,设计生产出符合用户需要的产品。然而与传统的信息抽取不同的是,在网络评论中评价对象所在的上下文环境复杂,评论用语不规范,评论句长短不一。这使得评论中的很多句子无法被正确分词,同时造成词性标注错误。因此评价对象的识别问题面临着巨大挑战。目前已有研究人员进行了相关的工作。
Eirinaki等[2]将由大量形容词描述的名词作为关键特征,对名词累计计分,通过预设的阈值排除分值较低的名词,剩下名词作为重要的评价对象。文坤梅等[3]针对无主谓句法的句子建立root规则,抽取评价对象。针对极性词对潜在评价对象的依赖关系建立target规则,抽取评价词。为了提高召回率,在root规则和target规则上,根据评价对象之间的连接关系,建立extend规则,从已知的评价对象出发找到未知的评价对象。但仅对微博领域的句子进行处理。Qiu等[4]首先使用词性标注工具寻找形容词和名词,建立候选评价词库,然后使用句法分析工具建立评价词和评价对象之间的双向抽取规则。徐叶强等[5]利用词性规则抽取候选的评价对象,再通过一些特殊词以及评价对象的非完整性等对候选的对象进行噪声过滤,最后对评价对象进行置信度计算,从而确定最终的评价对象。许细清等[6]根据上下文线索对候选对象进行过滤,其中包括点互信息PMI方式;通过对候选对象和评论领域进行相关性分析确定评价对象。Yu等[7]在统计学和句法规则的基础上,根据评价对象出现的相对频率找到候选评价对象,通过改进它们的TF-IDF值,找到大于设定阈值的对象作为最终结果。戴敏等[8]在CRF模型的基础上引入丰富的句法特征抽取评价对象。文献[9]从评论中抽取频繁的名词、名词短语作为候选特征,通过对这些特征建立单一的SVM分类器来识别评价对象。CRF、SVM都属于监督学习的一种,这种方法依赖于大量语料集,需要人工对训练集事先标记。而网络上的信息大规模地增长,仅依靠人力对这些数据进行标记和训练根本无法实现。无监督学习模型LDA无需事先对数据集进行标记。Titov等[10]认为标准的LDA模型抽取的主题主要是针对某个品牌的,无法进一步细化到产品的具体特征上。为解决LDA在特征抽取时造成的品牌倾斜问题,Titov等提出一种多粒度的主题模型。文献[11]将LDA应用到句子级上,通过设置少量的主题数抽取评价对象,有效解决了Titov等提出的问题。但LDA更适合处理特征丰富的文本。
除上述方法之外,依存句法分析也经常被应用到数据挖掘和文本分析领域,也有一些研究者采用依存句法分析抽取评价对象[12-13]。不同于已有的研究工作,文中鉴于构成评价对象的名词或名词词组多出现在主谓关系、并列关系等句法结构中,在依存句法分析的基础上,采用二叉树对名词或名词词组出现频率较高的句法结构进行挖掘。首先通过依存句法分析生成依存句法关系结构语句,为方便对这些语句进行遍历,以其中一些结构语句(如主谓关系结构)为核心构造二叉树。然后遍历每一棵二叉树,最终识别出具有完整含义的评价对象。该方法在两类测试集上都取得了不错的效果。
1 评价对象抽取工作流程
图1是抽取评价对象的整个处理过程。
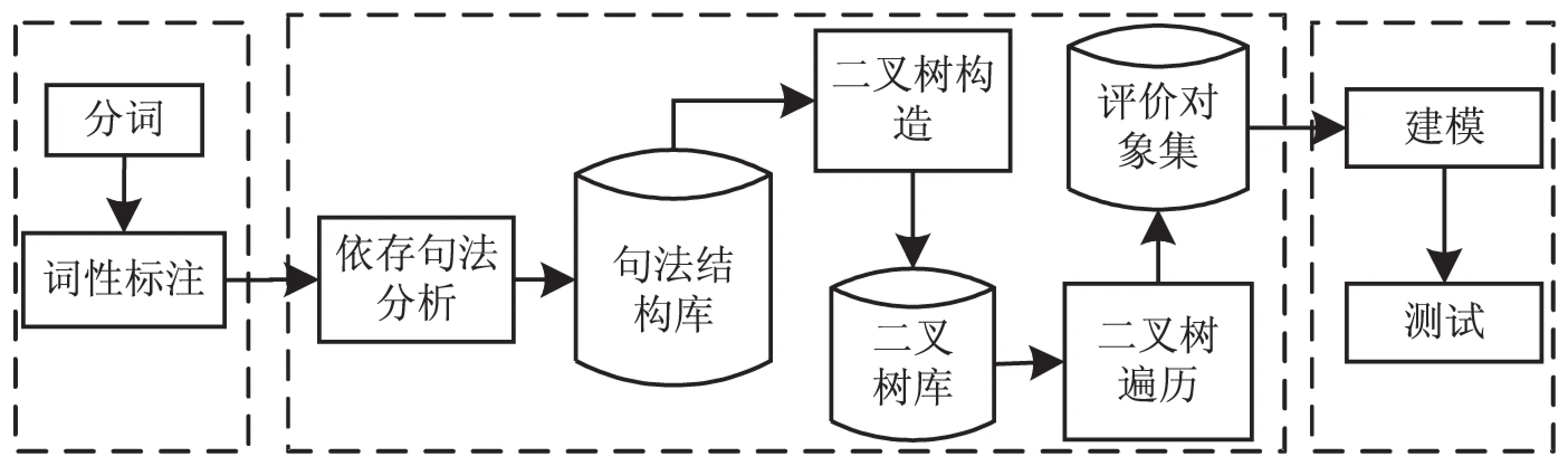
图1 评价对象抽取工作流程
描述如下:
(1)数据预处理。数据预处理主要是指分词和词性标注,这是依存句法分析的前提。
(2)依存句法分析。依存句法分析(Dependency Parsing,DP)最早由法国的语言学家L.Tesniere提出[14],指通过分析句子内各词语之间的依赖关系识别出“主谓宾”、“定状补”等语法关系。依存句法分析可服务于关键词识别、自动问答等与自然语言处理相关的各种任务。其分析结果对应于一棵依存树(如图2所示),依存树展示了句子各个成分之间的依赖关系。
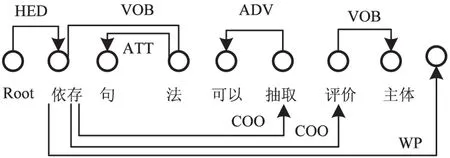
图2 依存树示例
通过依存句法分析,得到依存句法关系结构库,每一个句法结构描述了单词在文本中出现的位置以及各单词之间的句法关系。
(3)二叉树构造。为了发现文本中的评价对象,需要遍历句法结构库。文中将库中的结构语句构造成一棵棵二叉树,得到二叉树库。
(4)二叉树遍历。对二叉树库中的每一棵树进行中序或后序遍历,将得到的字符串组合得到最终的评价对象。
(5)建模与测试。为验证算法的性能,使用三类数据集分别用于建模和测试。
2 评价对象抽取
2.1 依存句法分析
通过依存句法分析,生成一系列依存句法关系结构,如表1所示。
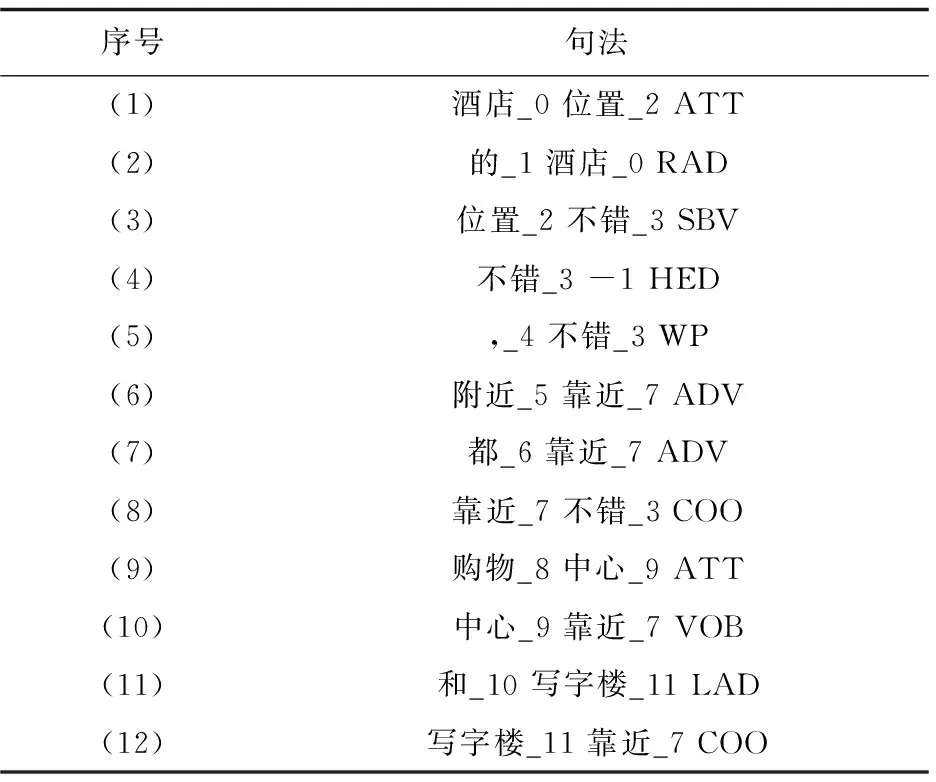
表1 依存句法关系结构示例
用户评论中的评价对象大都以单一名词或者名词词组的方式出现。通过依存句法分析发现,名词直接出现在一些主谓关系、并列关系、动宾关系等结构语句中。构成名词词组的词语主要出现在主谓关系、并列关系等前后结构中。如“酒店的位置不错”对应的句法结构为“酒店_0位置_2 ATT/的_1 酒店_0 RAD/位置_2 不错_3 SBV/不错_3 -1 HED”。完整的评价对象“酒店的位置”由词“酒店”、“位置”组成,“位置”出现在“位置_2 不错_3 SBV”主谓关系结构中,“酒店”出现在前面的结构“酒店_0位置_2 ATT”和“的_1 酒店_0 RAD”中,且三者之间通过一些共同的词语产生了联系。
文中主要对8种成分的依存关系进行分析。8种成分的依存关系及其示例见表2。
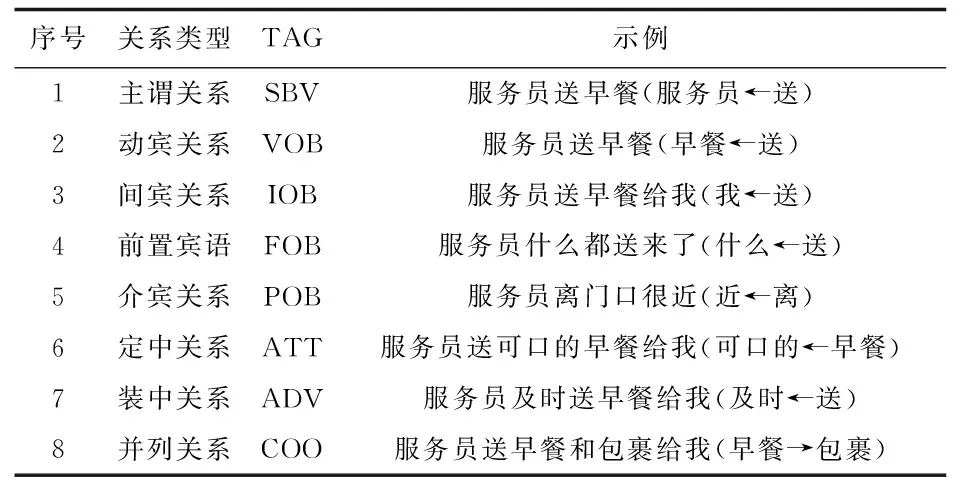
表2 依存关系类型及示例
2.2 二叉树构造和遍历
表3显示了在二叉树构造和遍历算法中使用的部分符号的含义,其余符号可类推。

表3 符号约定
算法1:二叉树构造。
1)将T分成M个独立的段落,构造第一棵二叉树。
(1)按行号依次遍历Tm,找到X1_x1Y1_y1SBV,继续遍历,若发现Y1_y1Y2_y2SBV,且X2=Y1,执行(2),否则执行(3)。
(2)将X2_x2Y2_y2SBV中的Y2作为根,X2作为Y2左孩子;同时将X1_x1Y1_y1SBV中的X1作为X2的左孩子,生成一棵二叉树。
(3)将X1_x1Y1_y1SBV中的Y1作为根,X1作为Y1左孩子,生成一棵二叉树。
(4)继续遍历Tm,寻找Z1_z1Y1_y1VOB。存在,将Z1作为Y1的右孩子;否则寻找Z1_z1Y1_yIOB,将Z1作为Y1的右孩子;否则寻找Z1_zY1_y1FOB,将Z1作为Y1的右孩子;否则寻找Z1_z1Y1_y1POB,将Z1作为Y1的右孩子。若都不满足,执行(5)。
(5)寻找C1_c1Y1_y1COO,存在记Y1=C1,再次执行(4),否则执行(6)。
(6)Y1没有宾语,Y1的右孩子为空。
2)第一棵二叉树构造结束,在第一棵二叉树的基础上构造后续的二叉树。
(1)X1作为第2棵二叉树的根,遍历Tm,寻找X1L1_x1l1X1_x1ATT或X1L2_x1l2X1_x1ADV或X1L3_x1l3X1_x1VOB,X1L1作为X1的左孩子,右孩子为空;按照x1l1、x1l2、x1l3由小到大的顺序构造X1的左子树。
(2)以X1L1为根,X1L1L1_x1l1l1X1L1_x1l1ATT或X1L1L2_x1l1l2X1L1_x1l1ADV,同(1),构造X1L1的左子树。
(3)同(2),构造X1L2,X1L3,…的左子树。
(4)寻找C2_c2X1_x1COO,X1的左子树作为C2的左子树,X1的右子树作为C1的右子树,构造以C1为根的后续二叉树。
3)若Y1的右子树不空,则构造一系列以Z为根的二叉树,否则执行4)。
(1)同2)步骤(1),构造Z1的左子树Z1L1,右子树空;构造Z1L1的左子树Z1L1L1,右子树空。
(2)同2)步骤(4),寻找句法关系D1_d1Z1_z1COO,Z1的左子树作为D1的左子树,Z1的右子树作为Z1的右子树,构造以D1为根的后续二叉树。
4)Y1的右子树为空,构造Y1树。寻找Y1L1_y1l1Y1_y1ATT或Y1L2_y1l2Y1_y1ADV,类似于2)步骤(1),若yl1
算法2:二叉树遍历。
(1)对二叉树进行中序遍历,得到的第一个节点X1(如果X2不存在,否则X2作为候选的评价对象)作为候选评价对象,Z作为候选评价词。
(2)后序遍历以X1、X1L1、X1L1L1…为根的二叉树,得到后序序列newX1、newX1L1、newX1L1L1,构造字符串X1=…+newX1L1L1+newX1L1+newX1,作为最终评价对象。
(3)后序遍历以Z1、Z1L1、Z1L1L1…为根的二叉树,得到后序序列newZ1、newZ1L1、newZ1L1L1,构造字符串Z1=…+newZ1L1L1+newZ1L1+newZ1,作为最终评价词。
(4)得到评价对象和评价词的二元组
(5)后序遍历以D1、D1L1、D1L1L1…为根的二叉树,得到后序序列newD1、newD1L1、newD1L1L1,构造字符串D1=…+newD1L1L1+newD1L1+newD1,作为新的评价词。
(6)得到新的评价对象和评价词的二元组
(7)若X1的并列对象C1存在,则后续遍历C1,得到C1…+newC1L1L1+newC1L1+newC1。得到新的评价对象C1和评价词二元组
图3是二叉树构造的示例。通过上述算法挖掘句子“酒店环境,房间档次都很不错,服务水平专业。住了两天,感觉确实比较不错,二楼自助烧烤给人宾至如归的感觉”的评价对象有“房间档次”、“酒店环境”、“二楼烧烤”。
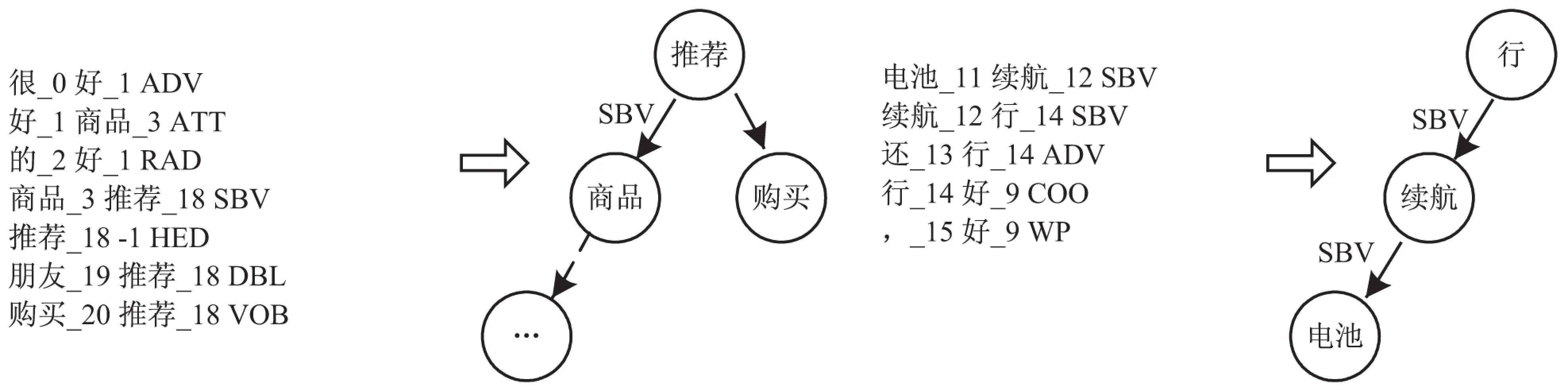
图3 二叉树构造示例
3 实验结果与分析
文中使用的数据集如表4所示。

表4 数据集
其中,CⅠ用于建模,CⅡ和CⅢ作为测试集来进一步验证算法的性能。CⅠ中文本长短不一,50字左右的评论占3/5左右;CⅡ中大部分评论的字数在100字左右;CⅢ中大部分的评论字数在20字左右。
三类数据集得到的各个性能指标如表5所示。
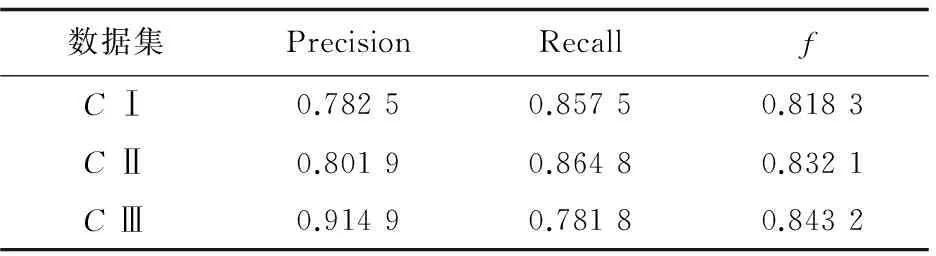
表5 测试结果
从表5中,可以得到以下结论:
(1)文中提出的算法在两类测试集上能够取得一定的效果。
(2)CⅠ和CⅡ的召回率比准确率高。数据集中,主观性句子的出现影响了准确率。虽然通过依存关系分析能够挖掘到主观句中的名词或名词词组,但这些词语仅是对事物的陈述,不含用户的任何感情色彩,并不能作为评价对象。
(3)CⅢ得到的召回率较低,准确率较高。由于CⅢ中大部分的评论句较短,句法结构不规则,生成的一些句法结构出现错误。
4 结束语
由于网络用语使用不规范,每一个商业领域都有自己专用的术语,使得评价对象在网络评论中的识别问题面临着巨大挑战。虽然一些分词、词性标注工具在处理新闻等时事类文章时表现出优越的性能,但是对网络评论这类语句的分词、标注处理得并不理想。为了解决评价对象识别问题,一些专家学者不断提出、改进新的算法,这些算法针对一些特定的问题能够取得较高的指标,但是目前仍没有形成统一的、相对成熟的模型来解决这类普遍的问题。
文中选择对评价对象出现频率高的句法关系结构构造二叉树,减少了对于无效句法关系结构的挖掘。经验证,该算法取得了不错的效果,且召回率在不同的数据集上都趋于稳定。在下一步的工作中,将针对主观性句子对算法的影响进行分析,在去除主观性句子的基础上进一步研究算法的性能,并将算法拓展到其他知识领域。
[1] 刘鸿宇,赵妍妍,秦 兵,等.评价对象抽取及其倾向性分析[J].中文信息学报,2010,24(1):84-88.
[2]EirinakiM,PisalS,SinghJ.Feature-basedopinionminingandranking[J].JournalofComputerandSystemSciences,2012,78(4):1175-1184.
[3] 文坤梅,徐 帅,李瑞轩,等.微博及中文微博信息处理研究综述[J].中文信息学报,2013,26(6):27-37.
[4]QiuG,LiuB,BuJ,etal.Opinionwordexpansionandtargetextractionthroughdoublepropagation[J].ComputationalLinguistics,2011,37(1):9-27.
[5] 徐叶强,朱艳辉,王文华,等.中文产品评论中评价对象的识别研究[J].计算机工程,2012,38(20):140-143.
[6] 许细清,林世平.Web文档评价对象抽取研究[J].计算机工程,2011,37(6):30-31.
[7]YuL,DuanX,TianS,etal.Topicextractionbasedonproduct
reviews[J].JournalofComputationalInformationSystems,2013,9(2):773-780.
[8] 戴 敏,王荣洋,李寿山,等.基于句法特征的评价对象抽取方法研究[J].中文信息学报,2014,28(4):92-97.
[9]YuJ,ZhaZJ,WangM,etal.Domain-assistedproductaspecthierarchygeneration:towardshierarchicalorganizationofunstructuredconsumerreviews[C]//Proceedingsoftheconferenceonempiricalmethodsinnaturallanguageprocessing.[s.l.]:AssociationforComputationalLinguistics,2011:140-150.
[10]TitovI,McDonaldR.Modelingonlinereviewswithmulti-graintopicmodels[C]//Proceedingsofthe17thinternationalconferenceonworldwideweb.NewYork:ACM,2008:111-120.
[11]BrodyS,ElhadadN.Anunsupervisedaspect-sentimentmodelforonlinereviews[C]//Proceedingsofhumanlanguagetechnologies:the2010annualconferenceoftheNorthAmericanchapteroftheassociationforcomputationallinguistics.Str-oudsburg,PA:AssociationforComputationalLinguistics,2010:804-812.
[12] 任 彬,车万翔,刘 挺.基于依存句法分析的社会媒体文本挖掘方法—以饮食习惯特色分析为例[J].中文信息学报,2014,28(6):208-215.
[13] 陶新竹,赵 鹏,刘 涛.融合核心句与依存关系的评价搭配抽取[J].计算机技术与发展,2014,24(1):118-121.
[14]DebusmannR.Anintroductiontodependencygrammar[J].HausarbeitfurdasHauptseminarDependenzgrammatikSoSe,2000,99:1-16.
Extraction of Evaluation Object Based on Dependency Parsing and Binary Tree
ZHANG Jian-hua,WENG Ming,LI Xiao-le,LIU Fang
(Experimental Teaching Center,Guangxi University of Finance and Economics,Nanning 530003,China)
It’s beneficial for finding productions’ feature that users care,by identifying the evaluation objects in comments,which provides decision basis for improving productions’ equality.According to the interdependence between words,an evaluation object identifying method based on dependency parsing and binary tree was proposed.By dependency relation analyzing,grammar relations sentences are found.Then construct binary trees with noun and noun phrases based on the binary tree model.Finally,traverse all binary trees,output relative strings,and combined the outputting strings,get evaluation objects with complete meaning.Experimental results show that this method has good effects in two specific test sets.
dependency parsing;evaluation object;binary tree
2015-05-12
2015-08-14
时间:2016-01-26
广西高等学校科学技术研究项目(2013YB215);广西财经学院数量经济学创新团队开放性基金项目(2014CX07)作者简介:张建华(1986-),女,硕士研究生,研究方向为数据挖掘、自然语言处理;翁 鸣,博士,副教授,研究方向为数据挖掘、电子商务。
http://www.cnki.net/kcms/detail/61.1450.TP.20160126.1520.042.html
TP393.4;TP391.1
A
1673-629X(2016)02-0052-04
10.3969/j.issn.1673-629X.2016.02.012
