基于Web的概念属性获取方法研究
2016-02-23刘亮亮汪平仄
刘亮亮,汪平仄
(1.上海对外经贸大学 统计与信息学院,上海 201620;2.江苏科技大学 计算机科学与工程学院,江苏 镇江 212003;3.中国科学院 计算技术研究所 智能信息处理重点实验室,北京 100190)
图1 通用的属性获取文法
图2 人物类属性获取模式
图4 基于并列结构的属性获取模式2
基于Web的概念属性获取方法研究
刘亮亮1,2,汪平仄3
(1.上海对外经贸大学 统计与信息学院,上海 201620;2.江苏科技大学 计算机科学与工程学院,江苏 镇江 212003;3.中国科学院 计算技术研究所 智能信息处理重点实验室,北京 100190)
属性是概念的内涵表达,描述概念的特征或性质,通过属性可以区分不同的概念,发现它们之间的差异。属性具备描述概念和鉴别概念的功能。基于Web的属性获取是指对给定的概念从Web网页中自动获取其属性集合。属性获取是概念知识获取的起点,也是领域本体自动构建的关键。文中从文本知识获取的角度对属性进行分类,并结合属性的元性质,探讨属性名称在Web语料中的基本表达方式(词汇句法模式),并通过词汇句法模式从大规模语料中获取属性名称,并且提出了基于统计和语义的候选属性验证方法。最后利用属性迭代获取模式进行属性迭代获取。通过几组概念的实例进行属性获取,实验结果表明,文中方法获取的属性的准确率较高。
知识获取;概念;属性;属性获取;语义
1 概 述
文本知识获取(Knowledge Acquisition from Text,KAT)是人工智能的重要研究内容,是指用机器学习等人工智能的方法,自动将自然语言描述的文本知识变为计算机可理解的形式。其最终目标是“在恰当的时间恰当的地点,以恰当的语言和恰当的粒度将恰当的信息呈现给恰当的用户”[1]。文本知识获取对知识服务、自然语言处理、本体工程、智能信息系统等研究起到了重要的支撑和促进作用。
已有的属性知识获取大致分为三类:手工整理的方法、基于语料的自动获取方法和基于Web网页搜索的自动获取方法。
WordNet[2]、HowNet[3]采用手工的方式得到包括属性在内的各类语义关系;维基百科[4]收集来自互联网用户对词条的释义,并从中筛选整理出各类词条的属性,以列表或表格形式呈现。
基于语料的方法通常是以大规模的领域无关语料库为基础的。基于词汇-语法模式的方法是最早的基于语料的自动获取方法之一。它首先确定要获取的关系类型;其次选定这种关系常见的几种词汇-语法模式作为已知模式在语料中发现新的词对集合,并根据新词对和已有词对在语料库中的上下文信息,抽取形成新模式;循环迭代此过程以发现更多的词对和模式。Hearst应用词汇-句法模式匹配自然语言文本语料,获取上下位关系[5]。
从本体性质出发给出属性的最上层分类:表性质的属性和角色属性。然后结合属性的语法性质,得到语言学上的分类:定量谓词、定性谓词和体词。其中,定量和定性谓词是对性质属性的刻画,体词则是对角色属性的刻画。最后把属性与Web语料作对应,得到它们与词类之间的映射,即定量谓词对应到数量词,定性谓词对应到形容词(包含程度副词+形容词),体词对应到名词,在文本知识获取中表现为一系列的概念词。
田国刚把这三类属性分别称为数量型、定性型和角色型属性。通过属性模式从语料中获取中文概念-属性对[6]。除了基于词汇-语法模式方法外,其他比较有代表性的方法还包括基于统计的方法。Yamada等使用词汇-句法模式和最大熵分类模型两种方法获取telic role和agentive role,结果显示最大熵分类模型的效果好于人工定义的模式[7]。
基于网页搜索的方法是在词汇-语法模式的方法基础上,利用搜索引擎提供的查询资源代替语料库,从中获取特定的关系。Brin使用双重迭代的模式-关系抽取方法从Web上获取特定关系[8](例如书名、作者)。Zhao等用表征属性的语素从一个机读词典中提取包含这些语素的词语,在Web中循环迭代地验证候选词并从中获取更多的属性语素[9]。Cimiano等利用正则表达式描述从Web获取属性名称[10]。Pasca提出了基于查询日志的属性获取[11]。Yoshinaga等提出从包含特定关键词的网页中,利用网页标签抽取属性名称[12]。
从总体的获取效果来看,基于语料的获取方法受限于语料来源、领域,由于数据稀疏问题,对通用领域的属性名称获取效果并不是特别理想。Pasca采用弱监督的方法而非基于模式的方法分别从文本和网页文档中获取属性名称,发现查询日志较之网页文档更适合基于鲁棒方法的类属性抽取[11]。
文中提出一种基于词汇句法模式的迭代获取方法。步骤如下:
(1)人工给出词汇句法模式,对给定的概念,使用词汇句法模式获取部分较为常用的属性;
(2)以第一步获取的属性作为种子属性,使用基于并列结构的句法模式,迭代获取更多的属性。
2 概念的属性获取方法
2.1 属性的初始获取模式
通过观察语料发现,在汉语中表达属性义时经常使用特殊标记“的”,因此把它作为一个常用的属性标记。
属性包括数量型、定性型和角色型属性。针对这三类属性,文中设计了三种不同的查询模式和匹配模式以分别获取和提取这三类属性,而不是仅仅采用一种通用的属性获取模式。根据对实验结果的分析,表明该分类是有效的,不仅得到了更高的精度,同时也增加了系统召回率。针对每个模式,定义了一个经验性的准确率,用于标识模式匹配到的结果的准确程度。
首先,为了保证系统的召回率,设计了一个通用的属性获取模式。这类模式对语料的限制比较宽松,因此得到的语料往往准确率较低,但是它能返回更多的结果,这样就保证系统总能得到一些属性。通用的属性获取文法如图1所示。
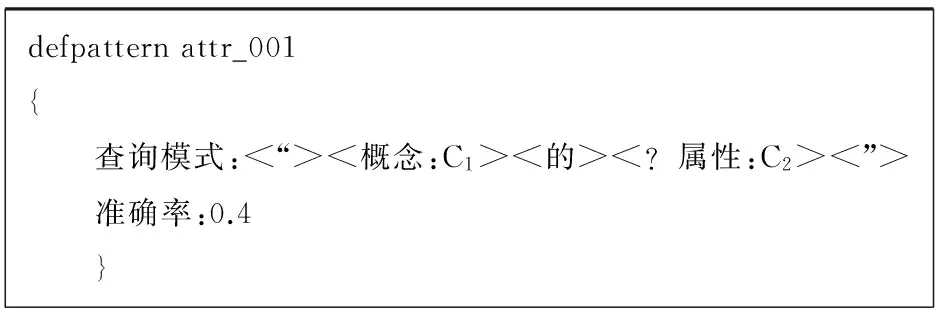
defpatternattr_001{ 查询模式:<“><概念:C1><的><”> 准确率:0.4}
图1 通用的属性获取文法
在查询模式中,域“<概念:C1>”会被替换成概念,而“”会被替换成一至多个通配符*,然后整个查询模式会作为关键词提交给Google搜索引擎接口,将“”匹配到的结果域作为候选属性提取出来。
对提取到的结果进行一系列预处理操作,包括过滤、剥离等。
过滤操作是对获取模式做一定的语义约束,只有满足约束的语料才能作为候选属性进入下一个模块。比如对概念“中国”,此模式匹配到句子“日本的运动品牌比中国的便宜吗”,在“中国”前面有“比”这个比较词。通过观察,概念前如果包含“比”这类词,概念后一般不会接属性词。因此,可以将此类语料过滤掉。
剥离操作是指剥离掉候选属性中不是属性的成分。比如对概念“中国”,此模式匹配到“中国的大部分国土面积不会丢失”,会将程度副词“大部分”和“不会丢失”这样的短语片段剥离掉,而只保留核心名词短语“国土面积”。其中名词短语的识别采用王石于2009年提出的方法[13]。
在属性的初次获取中,在保证一定召回率的情况下,更关注准确率。因为一旦有了一批准确率较高的属性,就能使用迭代方式得到更多的属性;而一旦初次结果准确率较低,则无法选取好的结果,势必会导致迭代效率大大降低,从而严重影响系统效率。因此,对每类属性分别给出一些特定的获取模式。以人物角色类属性为例,给定了如下模式,如图2所示,其他类的模式在文中不再列出。
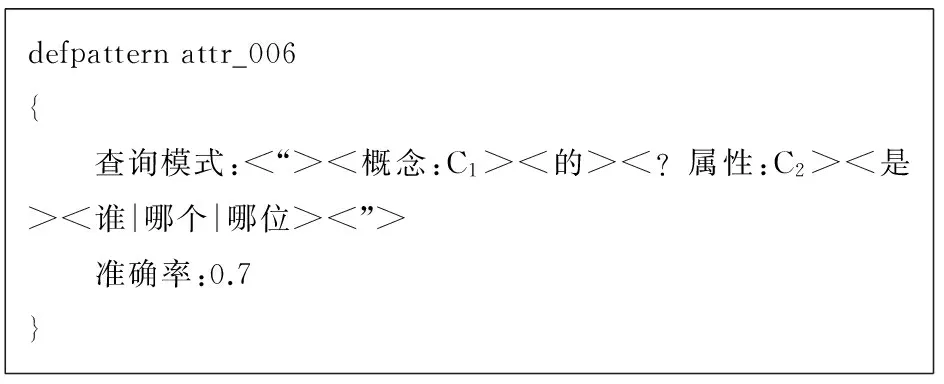
defpatternattr_006{ 查询模式:<“><概念:C1><的><是><谁|哪个|哪位><”> 准确率:0.7}
图2 人物类属性获取模式
这个模式在域“”后面加了约束“<是><谁|哪个|哪位>”,因此保证了“”匹配到的部分更接近于人物类属性。
2.2 初次获取结果的验证
对于概念“中国”来说,“人口数”、“国土面积”、“GDP”等属性会频繁出现在Web中用于描述“中国”,因此有如下假设:
假设1:对候选属性A,A在Web语料中出现频率越高,那么A作为一个属性的概率也越高。
对于给出的每个基本获取文法,它们得到结果的准确率也各不相同。因此,对每个文法统计得到了一个经验准确率。
假设2:对给定概念区做名词短语(NP)识别后,如果等于用户给定的概念,同时,目标区也只有一个NP,那么这个NP作为一个属性的概率也较高。
定义1:对于一个长度为n的字符串A=a1a2…an和一个长度为m的字符串B,B是A的前缀当且仅当B=a1a2…am,其中m≤n。
通过机器获取和手工校验的方式分别得到了属性的前后缀词典,词典中记录了属性的一些常见前缀和后缀。一般来说,大部分属性都包含有前后缀,因此,有如下假设:
假设3:对候选属性A,如果A包含了属性前缀或属性后缀,那么它作为一个正确属性的概率也较高。
定义2:给定概念C,C的属性集合为∑A,给定频繁阈值T,如果存在一个∑A的子集K={k1,k2,…,kn},n≥T,使得对K上的任意属性A,字符串P都是A的前缀,那么P称作C的频繁前缀。
定义3:给定概念C,C的属性集合为∑A,给定频繁阈值T,如果存在一个∑A的子集K={k1,k2,…,kn},n≥T,使得对K上的任意属性A,字符串P都是A的后缀,那么P称作C的频繁后缀。
假设4:对于给定概念C,包含C的频繁前(后)缀的候选属性作为一个正确属性的概念较高。
基于以上假设,文中设计了一组统计验证方式,对每条候选属性,统计计算得到一个置信度,并根据置信度的大小,推测属性的强弱关系。
统计验证函数如下:
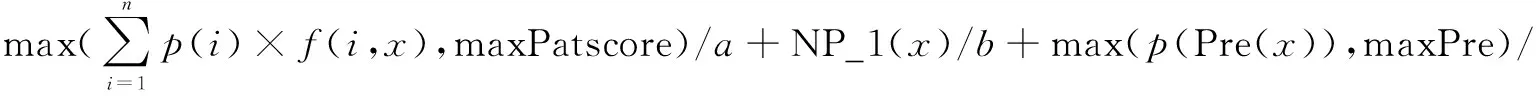
函数或参数说明如表1所示。

表1 函数或参数的定义
其中,a,b,c,d,maxPatscore,maxPre,maxSul取经验值。根据实验结果,它们分别取4,17,20,20,10,4,4时,效果较佳。
对于统计完毕的结果,需要做归一化处理,采用一般的归一化策略简单易行,而且事实证明是有效的。归一函数为:
3 属性的迭代获取
根据前面的初始获取结果,设计一类选择策略,从初始结果中选择一组认为准确率较高,同时也能用于迭代获取其余属性的种子集合。
种子的选择至关重要。对初次获取结果进行基于统计和基于规则的验证,得到一组结果及其置信度,选择那些好的结果,用于候选种子,然后使用Web验证,剔除候选种子中不好的属性,只有通过了Web验证的候选种子,才能被用于迭代。
属性的迭代获取采用基于并列结构的方法。
下面给出了2个基于并列结构的获取模式,见图3和图4。

defpatternattr_iter_seed_002{ 查询模式:<“><概念:C1><的><种子:C2><和|与|或|以及|及其><”> 准确率:0.4}

图3 基于并列结构的属性获取模式1
图4 基于并列结构的属性获取模式2
系统会将“”域的内容提取出来,并使用标点符号进行切分,将离概念最近的部分提取出来作为候选属性,并进入到下一步的过滤和剥离操作中。
候选属性的验证方法与2.2节中的方法相同。
4 实验和分析
4.1 测试集构造
测试集的构造至关重要。现实中的客观实体之间存在着差异,有人物、事物、组织、精神等等,因此,描述它们的方式和角度也各有差异。而属性作为区分和描述事物的概念的重要角色,它们之间也是因概念的不同而千差万别。根据前面的总结,属性分为数量型、定性型和角色型。每个事物的属性可能各有侧重,有些可能多使用数量型属性进行描述,比如:“珠穆朗玛峰”;而有些可能多使用定性型,有些则多使用角色型。在具体构造测试集中,构造了几组概念,而对每一类概念给出1~2个实例。具体如下:
·人物:毛泽东,刘德华
·事物:艾滋病,醋酸
·地方:北京,中国
·组织:中国科学院
·企业:商业银行
4.2 实验策略
对每个实体使用初次获取文法遍历一次,得到这个实体的候选属性。为了便于比较,从初次获取结果中选择置信度较高(经验值为0.8以上)的结果作为种子属性,使用迭代获取模块获取新的候选属性。对每个概念迭代三次。
4.3 实验结果
实验结果如表2所示。
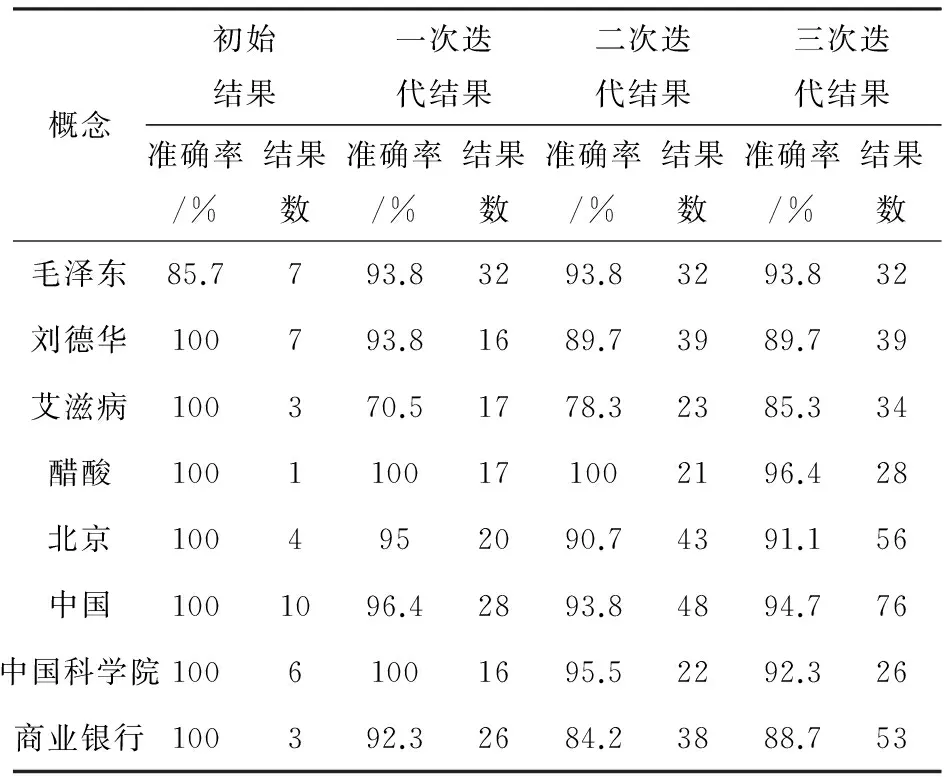
表2 实验结果
4.4 结果分析
对实验结果进行仔细分析,发现置信度在0.8以上的结果中,准确率都很高,最少的是85.7%,但结果数量较少。使用迭代模块以后,结果有所增加,但仍然不多。对错误的结果进行分类,总结出了下面几类:
(1)分词错误或名词短语识别错误。
这类错误比较常见。比如,求“艾滋病”的属性,得到“措施”,而原语料中为“预防措施”,经过分词和名词短语识别后,得出“措施”。这类错误只能在验证中排除,通过使用Web验证应该可以将此类错误排除,因为一般不会有以“艾滋病的措施”开头的句子。但这样做系统代价较大。
(2)剥离不完全。
这类由文法定义不足引起的错误最常见。比如,求“商业银行”的属性,得到“核心竞争力厦门”,而实际上应该为“核心竞争力”,后面的地名“厦门”未被剥离掉。这类错误不好排除。首先很难定义剥离规则将“厦门”剥离掉,因为不论从词性还是总结词典,都很难将其排除;其次,如果使用Web验证,也可能很难排除。
(3)非正确的属性。
这类出现不多,但不好验证。比如,求“北京”的属性,得到“价格”,而“价格”本身并不是“北京”的属性,但是在语料中“北京的价格”出现非常频繁,同时“价格”也是一个属性前后缀词,因此很难排除。目前使用跨任务的交叉验证,比如,已知“北京”、“南京”、“武汉”等同是“城市”的下位,但无法得到“价格”是“南京”和“武汉”等的属性,因此,可以暂时将“价格”放入“北京”的属性行列。但同时可能有另外一个问题,因为“北京”是首都,与其他省会城市角色不一样,所以属性也不可能一样,因此,可能还需要将“北京”的属性与“东京”“伦敦”等首都进行比较,因为它们同时也是“首都”的下位。
5 结束语
文中首先总结了目前国内外属性获取的基本方法,然后提出一种使用词汇-句法模式从Web网页中自动获取属性的方法。提出一种多语种的通用知识获取文法,并使用该文法,在无给定种子的情况下,从Web中自动获取属性名称,并使用一种基于统计的方法进行验证;然后对初始获取的结果进行手工挑选和修正,学习一组前后缀相关知识,并使用迭代获取文法从Web中迭代获取更多的属性名称。同时还提出一组基于语义和统计的候选属性验证方法。
从实验结果中得出,目前该方法的准确率较高,但是在保证准确率的情况下,结果数量有限,或是某一轮迭代后得不到新的结果。
因此,下一步将着重于提高系统召回率,找到更多的结果。可以从两方面进行努力:第一,选择更好的种子(但不一定是置信度更高的,需要适合进一步获取其他属性);第二,改良现有的属性迭代文法,设计新的属性获取文法。文法的设计直接影响系统的准确率和召回率,因此,完全有必要重新审视文法,找出其中的不足和缺陷并加以改正。
其次,任何一个概念,其属性之间是不完全平等的。比如给定概念“中国”、“人口”、“老年人口数”、“人口比例”、“人口分布”等是它的属性,其中,“人口”是这一类属性的统称,而“老年人口数”、“人口比例”、“人口分布”等则是分属于“人口”下的“子属性”。这种关系是有价值的,类属性是描述客观事物的宏观方面,而子属性则是一个具体方面。因此,有必要对属性做进一步的聚类分析,找出属性之间的继承关系。
最后,由前面的分析可以看到,目前系统只支持具体实例的属性获取,比如“中国”、“艾滋病”等。但是,对于抽象类的属性获取,比如“国家”、“疾病”却显得力不从心。这主要是由于属性获取文法对抽象类支持度不够。要解决该问题,可以使用两种策略:第一,设计抽象类的属性获取文法;第二,根据具体实例已经获取到的属性,和实例与类之间的上下位关系,往上提取中抽象类的属性。无论是哪一种方法,都将是一个很大的挑战,具有一定的意义。
[1] Reddy R.Three open problems in AI[J].Journal of the ACM,2003,50(1):83-86.
[2] Miller G.WordNet:a lexical database for English[J].Communications of the ACM,1995,38(11):39-41.
[3] 董振东,董 强,郝长伶.知网的理论发现[J].中文信息学报,2007,21(4):3-9.
[4] 中文维基百科.维基媒体基金会[EB/OL].2002.http://zh.wikipedia.org/.
[5] Hearst M.Automatic acquisition of hyponyms from large text corpora[C]//Proc of 14th international conference on computational linguistics.[s.l.]:[s.n.],1992:539-545.
[6] 田国刚.受限中文语料的自监督文本知识获取研究[D].北京:中国科学院研究生院,2007.
[7] Yamada I,Baldwin T.Automatic discovery of telic and agentive roles from corpus data[C]//Proceedings of the 18th Pacific Asia conference on language,information and computation.[s.l.]:[s.n.],2004.
[8] Brin S.Extracting patterns and relations from the world wide web[C]//Proc of selected papers from the international workshop on the world wide web and databases.[s.l.]:[s.n.],1998:172-183.
[9] Zhao J,Liu H,Lu R.Automatic extending HowNet's attribute lexicon on the web. signal-image technologies and internet-based system[C]//Proc of SITIS '07.[s.l.]:[s.n.],2007:315-320.
[10] Cimiano P,Wenderoth J.Automatically learning qualia structures from the web[C]//Proceedings of the ACL workshop on deep lexical acquisition.[s.l.]:[s.n.],2005:28-37.
[11] Pasca M.Organizing and searching the world wide web of facts step two:harnessing the wisdom of the crowds[C]//Proceedings of the 16th international conference on world wide web.[s.l.]:[s.n.],2007:101-110.
[12] Yoshinaga N,Torisawa K.Open-domain attribute-value acquisition from semi-structured texts[C]//Proceedings of 6th ISWC workshop.[s.l.]:[s.n.],2007:55-66.
[13] 王 石.中文实体名称的识别和语义分析方法研究[D].北京:中国科学院研究生院,2009.
Research on a Method of Conceptual Attribute Acquisition Based on Web
LIU Liang-liang1,2,WANG Ping-ze3
(1.School of Statistics and Information,School of Business Information,Shanghai 201620,China;2.School of Computer Science & Engineering,Jiangsu University of Science and Technology,Zhenjiang 212003,China;3.Key Laboratory of Intelligent Information Processing,Institute of Computing Technology,Chinese Academy of Sciences,Beijing 100190,China)
An attribute is the expression of connotation,which is used to explain some property of the conceptual word,and distinguish different concepts,and find their discrepancy.An conceptual word with attribute names are not an isolated vocabulary entry any more.Web-based attribute-acquisition is to acquire a set of attribute names from Web pages automatically for each given concept,enriching the semantics of the concept.Attribute acquisition is also a significant step of general knowledge acquisition from text,and an important task in automatic construction for domain ontologies.It makes a basic classification of attributes according to text knowledge acquisition in this paper and explores basic expressions (lexico-syntactical patterns) for attribute names in multi-linguistic Web corporal.After acquiring attribute names from large-scale corpus by patterns,a method based on statistics and semantic is proposed to validate.At last,attribute iteration patterns are applied to acquire new attribute names through iteration method.The results show that the precision of attribute acquisition is very high through the experiment of several group concepts.
knowledge acquisition;concept;attribute;attribute acquisition;semantic
2015-09-05
2015-12-16
时间:2016-07-29
国家自然科学基金资助项目(61203284);国家社科基金重点项目(10AYY003)
刘亮亮(1979-),男,讲师,博士,研究方向为知识获取、自然语言理解;汪平仄(1986-),男,博士,研究方向为大规模知识获取。
http://www.cnki.net/kcms/detail/61.1450.TP.20160729.1833.018.html
TP391
A
1673-629X(2016)08-0012-05
10.3969/j.issn.1673-629X.2016.08.003
