一种基于改进的TF-IDF和支持向量机的中文文本分类研究
2016-02-13郭太勇
郭太勇
(北京邮电大学网络空间安全学院,北京 100876)
一种基于改进的TF-IDF和支持向量机的中文文本分类研究
郭太勇
(北京邮电大学网络空间安全学院,北京 100876)
TF-IDF是一种应用在文本分类中常用的权值计算方法,传统的TD-IDF单纯考虑特征词频率以及包含特征词的文本数量,并没有很好的考虑特征词在文本中的重要程度以及类内分布均匀情况和类间分布离散的问题,可能会导致文本分类结果的偏差。本文引入卡方统计量CHI和特征词在文本中的位置作为修正因子并结合传统TF-IDF权值计算公式,很好的解决了特征词在类间分布以及关键词重要程度不足的问题,并应用支持向量机构建分类器,进行文本分类的实验验证。改进后的TF-IDF计算公式与传统TF-IDF相比,在查准率、查全率、F1测试值上都有一定程度的提升。
文本分类;TF-IDF;卡方统计量;支持向量机
0 引言
文本分类技术是信息检测和数据挖掘技术的基础,能够帮助用户从海量数据中获得自己需要的有用内容。它能够按照预先定义的文本主题类别,为文本集合中的每个文本确定一个类别,对文本进行准确、高效的分类,是许多数据管理任务的重要组成部分。目前文本分类技术已经广泛应用在搜索引擎、机器学习、信息过滤、数字图书馆、分类新闻组等领域。常见的文本分类算法有传统的增强学习算法、K-近邻算法[1]、朴素贝叶斯算法[2]、决策树学习算法、支持向量机[3]和神经网络算法等。
TF-IDF权重方法是文本分类领域中应用最为广泛的一种特征权值方法,由Salton在1988年提出,在此基础上,国内外学者进行了大量的改进工作,主要的改进集中在数据集偏斜、文本类内类间分布情况。其中,Forman[4]将概率统计方法度量运用于类别分布,并对IDF采用Bi-Nor-mal Separation计算方法。张玉芳[5]等提高了频繁在某个类中频繁出现的特征词权重并结合遗传算法进行分类。台德艺[6]等针对特征词在类内均匀出现和单一类别频繁出现的情况提出了TF-IIDF-DIC算法。张瑾[7]引入了特征词位置权值和词跨度权值对TF-IDF进行改进。
B.C.How等提出了CTD(category term descriptor)来减轻数据集偏斜对分类效果的影响。但是这些改进集中在对TF、IDF和类内区分能力的改进,并没有很好的解决特征词在类间分布的问题,而且存在着特征词权值波动,关键词区分能力不足等问题。
本文综合考虑特征词在类间的分布情况和特征词在标题中出现的情况,将卡方统计量CHI和特征词在文本中的位置引入TF-IDF权值计算公式中进行修正,使得不同的特征词具有适合的特征权重,较好的解决了特征词在类间分布的问题,并有效地提高了关键词的类别区分度。
1 基于改进TF-IDF的文本分类算法
1.1 传统的TF-IDF
Step1:词频TF的计算
词频用TF表示,即特征词在文档中的出现的次数。一般来数在文档中出现频率高的特征词有较大的权重,文档中出现频率低的特征词有较小的权重。在文本di中特征词tj的权重为wij,TF公式如下:

其中mj为特征词tj在文本di中的频数,Mi为文本中词的总数。
Step2:逆文档频率IDF的计算
逆文档频率用IDF表示,一般认为含有的某个特征词的文档篇数越多对应的分类能力越差。因为一些介词虚词出现概率较大,但是其对分类影响不大,还有的词在多个类别中出现,就不能代表某个单一的特定类别,它也对分类贡献度不大。IDF公式如下:
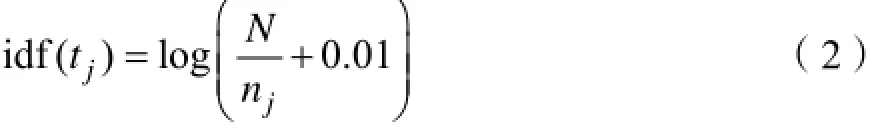
其中N表示训练集中的文本总数,nj表示包含特征词tj的文本数。
TF方法对高频的特征词具有比较好的识别性,但是有的高频词是对分类没有帮助的常用词,有的特征词是低频的能够很好地代表文档类别却很有可能被忽略掉。IDF方法使得在大多数文档中出现的特征词的重要性降低,而能够增强出现次数较少的特征词的重要性。
Step3:对TF-IDF归一化处理
文本集合中的文档长度不一,为了避免TF-IDF偏向于长文本的状况出现,将TF-IDF作归一化标准处理,公式如下:
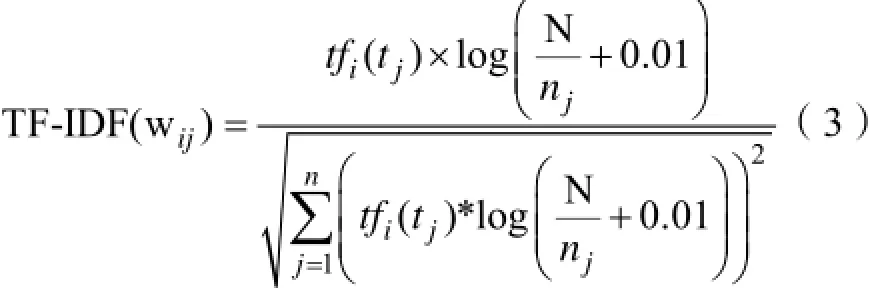
N代表在文本di中特征词的个数,nj表示包含特征词tj的文本数。
1.2 改进的TF-IDF算法
传统的TF-IDF主要考虑DF、IDF以及数据归一化,但是对于特征词在类别内部和类别之间的分布情况没有进行有效处理。举个例子来说,含有特征词t的C类文档总数为h,特征词在其他类别的文档总数为k,则特征词在文本集中出现的总次数为h+k,当h很大,k较小时,理论上t应该能很好的代表C类文本,但是由传统的TF-IDF公式可得,h越大,特征词的IDF越小,则该特征项权值较小,说明区分能力很弱,显然这与实际情况是不符的。
本文基于以上缺陷,考虑了特征词在类间的分布情况,将卡方统计量CHI引入TF-IDF进行修正。同时考虑到特征词在文本中的位置也会对分类结果产生明显的影响,标题和文档关键位置的特征词应当具有更好的类别区分能力,本文考虑了特征词在标题中出现的情况,引入一个位置调节因子λ,引入的CHI和位置因子具体定义如下:
(1)卡方统计量CHI
特征选择方法能够降低文本向量空间的维度,简化文本了文本模型,使得分类的效率和精度都有所提高。常用的特征选择方法[8]有文档频率(DF)、信息增益(IG)、互信息(MI)和卡方统计量(CHI)等。
卡方统计量用来表示特征t和类别c之间的相关程度。特征词的卡方统计量越大,该特征词与类别的相关性越高,对类别的代表能力更强,特征词应当具有更高的权重。
卡方统计量公式如下:
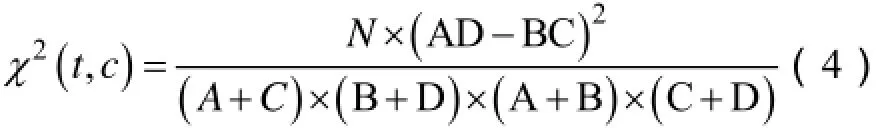
其中N为训练集中文档的总数,ABCD如下表1所示:
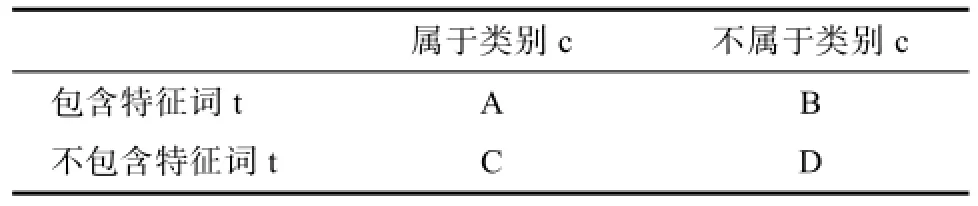
表1 类别特征列联表Tab.1 Class feature table
(2)特征词位置因子λ
特征词在同一篇文档中的不同位置出现时,该特征词的重要性也是不一样的。在标题中出现的特征词很有可能直接区分出本文档所属的类别,此类的特征词对文本具有很好的区分度,应当具有更高权重。本论文将针对标题中出现的特证词引入一个位置因子λ,λ是一个由大量实验得出的经验系数,本文规定在标题中出现的特征词的λ数值为3。
(3)TF-IDF修正公式归一化
实验训练集和测试集中的文档长度不一,为了避免TF-IDF偏向于长文本的状况出现,将TF-IDF作归一化标准处理,同时为了避免特征词权重过于不均衡,还将特征词的CHI进行了对数化处理:logCHI。
所以,改进后的TF-IDF计算过程如下:
Step1:计算TF
Step2:计算IDF
Step3:计算卡方统计量CHI
Step4:标题特征词位置因子λ引入
Step5:对修正后的TF-IDF进行归一化处理
综合以上考虑并结合原有的文档频率TF和逆文档频率IDF,本文改进后的TF-IDF特征权重公式为:
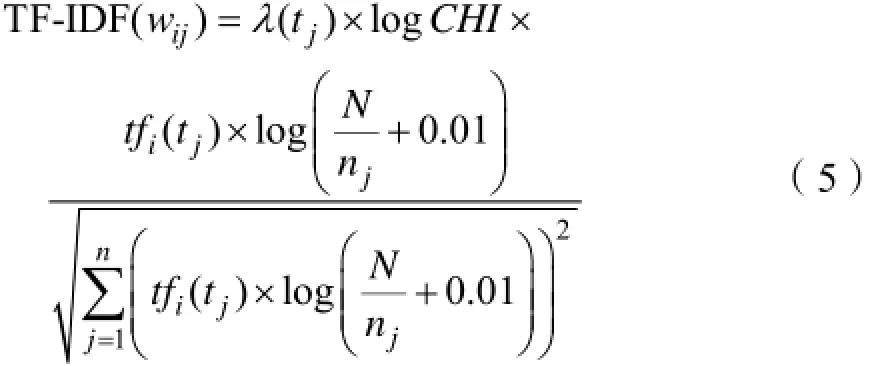
1.3 文本分类算法
通过上面对TF-IDF算法的改进,并使用SVM进行了文本分类,本文改进后的分类算法的具体实现流程为:
1)使用中文分词系统对文本进行预处理,并去除停用词等;
2)通过对文本特征项进行特征选择,并使用改进的TF-IDF权值计算公式计算特征项权值,将文本表示为特征向量的形式;
3)使用SVM分类器对训练集中的已知类别文本进行学习;
4)使用学习后的SVM分类器对测试集合文本进行分类。
其中中文分词系统采用jieba分词系统[9],jieba分词支持三种分词的模式:精确模式、全模式和搜索引擎模式。其中精确模式能够将句子最精确的切分开来,最适合做文本分类。结巴分词支持多种语言组件,本文使用的版本是Python组件。
本文使用支持向量机(SVM)进行文本分类实验,采用的是一套由台湾大学林智仁(Chih-Jen Lin)教授在2001年开发的支持向量机的库LibSVM[10],能够方便的进行文本分类,而且LibSVM程序是开源的,容易做各种扩展,并且程序较小,输入参数少,使用灵活。
SVM分类结果的好坏与核函数的选择有很大关系,目前主要有线性核函数、多项式核函数和径向基核函数,本文采用的是径向基核函数[11]Radial Basis Function)。
2 文本分类仿真实验
实验数据来源于搜狗实验室[12]文本分类语料库,选取了军事、体育、旅游、财经、IT、房产、教育、娱乐八个类别各300篇文章共2400篇文档组成训练集,然后选取以上八个类别各120篇共960篇文档组成测试集, 训练文本集合测试文本集互不重合。
2.1 评价标准
对于优化后的TF-IDF算法性能究竟如何,需要进行实验来验证文本分类系统的性能。对于分类结果,国际上用通用的评估指标[13],分别是查准率(Precision)、查全率(Recall)和F1测试值3项。本文采用以上三项指标对改进后的TF-IDF算法进行评估。
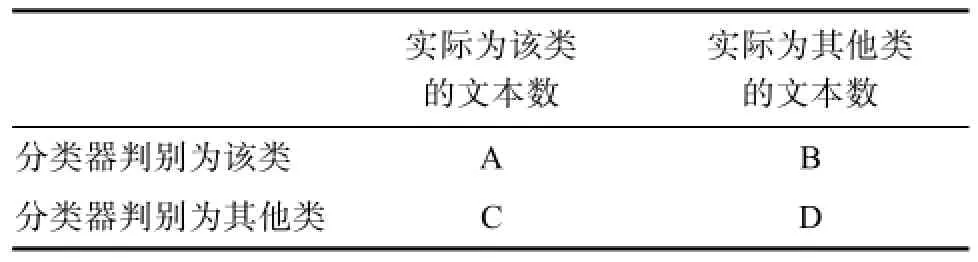
表2 分类器判别列联表Tab.2 Classifier discriminant contingency table
由表2可知,它们对应的公式如下:

2.2 实验过程
文本分类主要步骤如下:
(1)对测试集和训练集的文本进行中文分词(jieba)处理,并去除停用词;
(2)使用卡方统计量进行特征选择后,利用改进后的TF-IDF计算特征权值,形成文本特征向量;
(3)将处理后测试集中的文本输入svm分类器进行训练;
(4)将训练集中的文本输入训练后的svm分类器进行预测。
3 实验结果分析
对数据集文本进行TF-IDF权值计算后,部分特征词的TF-IDF改进前后对比如下表3所示:

表3 改进前后TF-IDF对比Tab.3 Improvement before and after TF-IDF contrast
由上表可以看出改进后的TF-IDF中“民族”“联赛”“足协”等的权值变化较大,更能反映出类别的代表能力,“超市”“会计”等的权值变化较小,由此可以看出特征词的权值经过改进后都有不同的变化,具有了更好的类别代表能力。
使用svm对处理后训练集的文本进行学习,并使用测试集进行测试后的实验结果如下表4和5所示,其中A为实际为该类且分类器判别为该类,B为实际为其他类但分类器判别为该类,C实际为该类但分类器判别为其他类文档个数。

表4 传统的TF-IDF文本分类结果Tab.4 Traditional TF-IDF text classification results
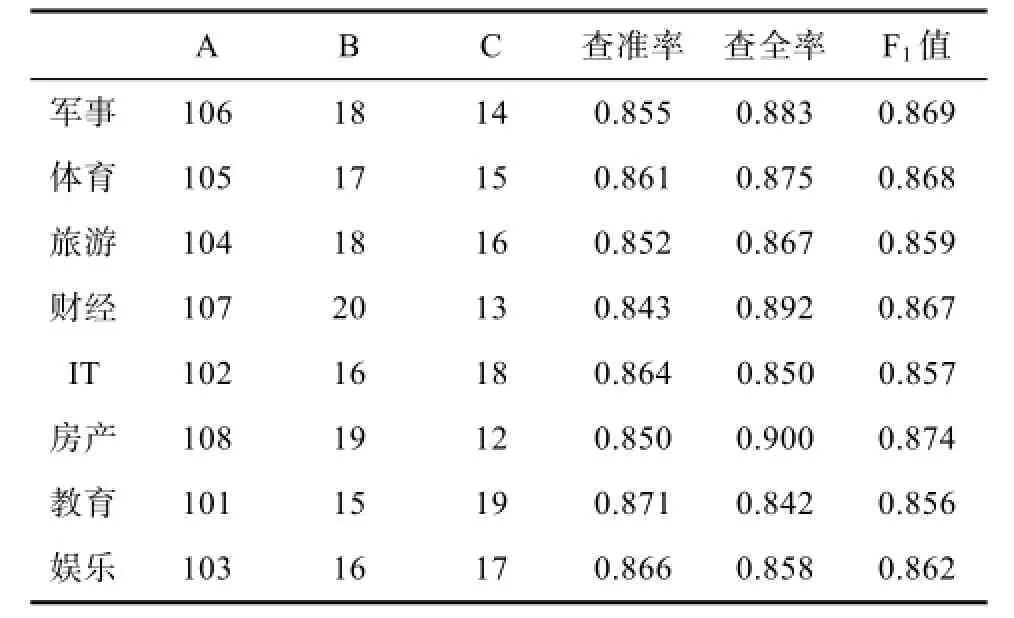
表5 改进后的文本TF-IDF分类结果Tab.5 Improved TF-IDF text classification results
由表4和5可得,传统的TF-IDF的平均查准率、查全率和测试值分别为83.56%、83.74%、83.56% ,改进后的TF-IDF的平均查准率、查全率和测试值分别为85.76%、87.09%、86.40%,相比较而言,改进后的算法分类效果均好于原算法。
为了更直观的观察两种算法结果,查准率、查全率和测试值的折线图对比如下:

图1 两种方法查准率对比图Fig.1 Two methods of precision comparison chart
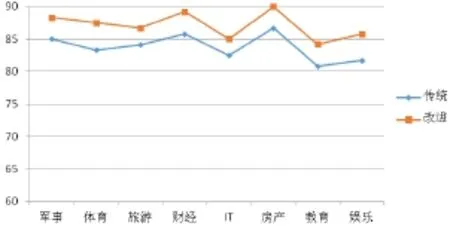
图2 两种方法查全率对比图对比Fig.2 Two methods of Recall comparison chart

图3 两种方法F1值对比图对比Fig.3 Two methods of F1-Measuremacro average value comparison chart
从图1、2、3可以看出,改进后TF-IDF算法在八个类别的查准率、查全率、F1值上比传统的TF-IDF有3%左右的提升,证明改进后的TF-IDF算法在文本分类上的表现均好于传统TF-IDF。
4 结语
本文着重研究点在TF-IDF算法的改进,并针对传统TF-IDF的不足,提出将特征选择函数卡方统计量(CHI)和特征词在文本中的位置因子引入TF-IDF,改进后的TF-IDF使得特征词有了更合适的权重,能够更准确地表示特征词对于类别的区分度,使得整体的分类效果有一定的提升。
但是特征词的权重受很多因素影响,卡方统计量主要考虑特征词在文本中出现与否,比较偏向低频词,特征词在文中不同的位置都应有不同的权重,本文着重考虑在标题中出现的,部分特征词的多义性,特征词在类内出现的均匀与否以及在类间的分布情况都应该被赋予不同的权重,以上这些情况都是下一阶段重点研究的方向。
[1] 奉国和, 吴敬学. KNN分类算法改进研究进展[J]. 图书情报工作, 2012, (21): 97-100+118. FENG G H, WU J L.KNN, improved classification algorithm research progress of[J]. library and information service, 2012, (21): 97-100+118. (in Chinese)
[2] 钟磊. 基于贝叶斯分类器的中文文本分类[J]. 电子技术与软件工程, 2016, (22): 156. ZHONG L. Chinese text classification based on Bias classifier[J]. electronic technology and software engineering, 2016, (22): 156. (in Chinese)
[3] 李希鹏. 基于混合核函数支持向量机的文本分类研究[D].中国海洋大学, 2012. LI X P. Research on text classification based on the hybrid kernel function support vector machine[D]. Ocean University of China, 2012. (in Chinese). FORMANG.BNS feature scaling: an improved representation over TF-IDF for SVM text classification[C]//Proceedings of the 17th ACM Conference on Information and Knowledge Management. USA, California: ACM, 2008: 263-270.
[4] 张玉芳, 彭时名, 吕佳. 基于文本分类TFIDF方法的改进与应用[J]. 计算机工程, 2006, (19): 76-78. ZHANG YF, PENG S M, LV J. Improvement and application of TFIDF method based on text categorization[J]. Computer Engineering, 2006, (19): 76-78. (in Chinese).
[5] 台德艺, 王俊.文本分类特征权重改进算法[J]. 计算机工程, 2010, (09): 197-199+202.
[6] TAI D Y, WANG J. Text classification feature weight algorithm[J]. Computer Engineering, 2010, (09): 197-199+ 202. (in Chinese).张瑾. 基于改进TF-IDF算法的情报关键词提取方法[J]. 情报杂志, 2014, (04): 153-155. ZHANG J. Methods[J]. Journal of information, information extraction of keywords based on improved TF-IDF algorithm 2014, (04): 153-155. (in Chinese).
[7] 杨杰明. 文本分类中文本表示模型和特征选择算法研究[D]. 吉林大学, 2013. YANG J M. Research on text representation model and feature selection algorithm in text categorization[D]. Jilin University, 2013. (in Chinese). jieba中文分词系统[EB/OL]. https://github.com/fxsjy/jieba/.
[8] jieba Chinese word segmentation system https://github.com/ fxsjy/jieba/. [EB/OL]. (in Chinese)
[9] LIBSVM分类器[EB/OL]. http://www.csie.ntu.edu.tw/~cjlin/ libsvm/.
[10] LIBSVM classifier http://www.csie.ntu.edu.tw/~cjlin/libsvm/. [EB/OL]. (in Chinese).
[11] 黄翠玉. 文本自动分类研究——基于径向基函数[J]. 情报科学, 2013, (05): 67-71. HUANG C Y. Research on Automatic Text Categorization Based on radial basis function [J]. information science, 2013, (05): 67-71. (in Chinese)
[12] 搜狗实验室文本分类语料库[EB/OL]. http://www.sogou. com/labs/resource/list_yuliao.php. Sogou laboratory text classification corpus [EB/OL]. Http://www.sogou.com/labs/ resource/list_yuliao.php. (in Chinese)
[13] 王静. 基于机器学习的文本分类算法研究与应用[D].电子科技大学, 2015. Wang J. Research and application of text classification algorithm based on machine learning[D]. Electronic Science and Technology University, 2015. (in Chinese)
A Method Based on TF-IDF and Improved Support Vector Machine Research on Chinese Text Categorization
GUO Tai-yong
(School of CyberSpace Security, Beijing University of Posts and Telecommunications, Beijing 100876, China)
TF-IDF is a commonly used weight in text classification method, the traditional TD-IDF only consider the frequency characteristics of words and characteristic words contain the number of texts, and no distribution of discrete problems and uniform distribution considering the feature words good degree of importance in the text and in class, may lead to biased text the classification results. This paper introduces chi-square test CHI and statistic feature words in the text position as a correction factor and a formula for combining traditional TF-IDF weights and solves the problem of feature words in distribution between categories and keywords of degree, and the application of support vector machine classifier construction, experimental verification for text classification. The improved TF-IDF formula is compared with the traditional TF-IDF, have a certain degree of improvement in precision and recall, F1-Measuremacro average value.
Text Categorization; TF-IDF; Chi-Square statistics; Support Vector Machine
TP181
ADOI:10.3969/j.issn.1003-6970.2016.12.030
郭太勇(1988-),男,硕士,网络安全。
本文著录格式:郭太勇. 一种基于改进的TF-IDF和支持向量机的中文文本分类研究[J]. 软件,2016,37(12):141-145
