基于权值的Hadoop调度算法改进与实现
2016-01-22朱健军吴哲夫
朱健军,张 彤,吴哲夫
(浙江工业大学信息学院,浙江 杭州 310023)
摘要:针对当前Hadoop集群自带的任务级调度分配方法在实际处理作业时存在资源分配不均的问题,提出了一种基于权值的任务调度分配算法。该算法结合节点当前的负载状态、节点物理性能和任务优先级等作为依据,通过权值排序当前的作业队列并将空闲资源优先分配给权值高的任务,从而实现运行过程中作业任务的自适应动态调度。实验结果表明,改进算法相比原来的FIFO算法有30%的性能提升。
关键词:云计算;任务调度;权值
DOI: 10.13954/j.cnki.hdu.2015.01.005
基于权值的Hadoop调度算法改进与实现
朱健军,张彤,吴哲夫
(浙江工业大学信息学院,浙江 杭州 310023)
摘要:针对当前Hadoop集群自带的任务级调度分配方法在实际处理作业时存在资源分配不均的问题,提出了一种基于权值的任务调度分配算法。该算法结合节点当前的负载状态、节点物理性能和任务优先级等作为依据,通过权值排序当前的作业队列并将空闲资源优先分配给权值高的任务,从而实现运行过程中作业任务的自适应动态调度。实验结果表明,改进算法相比原来的FIFO算法有30%的性能提升。
关键词:云计算;任务调度;权值
DOI:10.13954/j.cnki.hdu.2015.01.005
收稿日期:2014-11-06
基金项目:浙江省自然科学基金资助项目(LY13F010011)
作者简介:朱健军(1974-),男,浙江杭州人,讲师,云计算网络.
中图分类号:TP301.5
文献标识码::A
文章编号::1001-9146(2015)01-0027-04
Abstract:To address the problem of unfair resource assignment in task scheduling method on Hadoop platform, this paper proposed an improved scheduling algorithm based on weight. The algorithm considered the current node state, node physical properties as well as job priority to queue the job, and then sorted the free resource to the first job task based on the weight to implement adaptive dynamic task scheduling during system operation. The experimental results show that it gives about 30% performance better than FIFO algorithm.
0引言
Hadoop作为云计算系统的MapReduce开源实现,在大规模的数据处理方面得到了广泛应用。在Hadoop平台上[1]用户可以不考虑任务的底层实现,只需开发云计算的应用程序,然后将任务提交给Hadoop云平台。Hadoop具有很强的容错性,并可方便地增加集群节点个数、线性扩展集群规模,使集群能适应处理更大规模的数据集。Hadoop已经成为了许多互联网公司基础计算平台的核心。但Hadoop也有自身的一些不足,特别是在实际使用过程中暴露出来的MapReduce调度器[2]的低效性和对异构系统适应能力差的问题。目前常见的调度算法主要有默认调度算法FIFO,该方法采用单一的先进先出队列,不考虑作业的大小或优先级,效率较低;延迟调度算法[3]则采用了时间推移来改善数据公平性与本地性的冲突;LATE算法[4]根据异构集群中任务执行速率变化的特性,将后进任务调度到执行速度较快的空闲节点执行。本文从资源利用率角度出发,在计算能力调度算法[5]的基础上,根据作业优先级、资源需求、节点距离[6]等因素来计算作业的权重值,同时实时观察和反馈执行状态,进一步自适应地调节节点工作负载,实现任务调度过程中的负载均衡,从而提高集群的任务执行效率。
1Hadoop任务调度
1.1 资源调度模型
集群资源的组织和分配管理是Hadoop系统中最基本的功能模块之一,如图1所示,其资源分配过程可以概括为以下7个步骤。
1)节点管理器通过周期性心跳汇报节点信息;
2)资源管理器和节点管理器返回心跳应答,释放Container列表信息;
3)资源管理器收到节点管理器信息后触发节点更新事件;
4)资源调度器在收到节点更新事件后,按照一定策略将该策略节点上的资源分配给各应用程序;
5)应用程序向资源管理器发送周期心跳,以领取最新分配的Container;
6)资源管理器收到应用程序心跳信息后分配的Container以心跳应答的形式返回;
7)应用程序收到新分配Container列表,将其进一步分配给内部的各个任务。
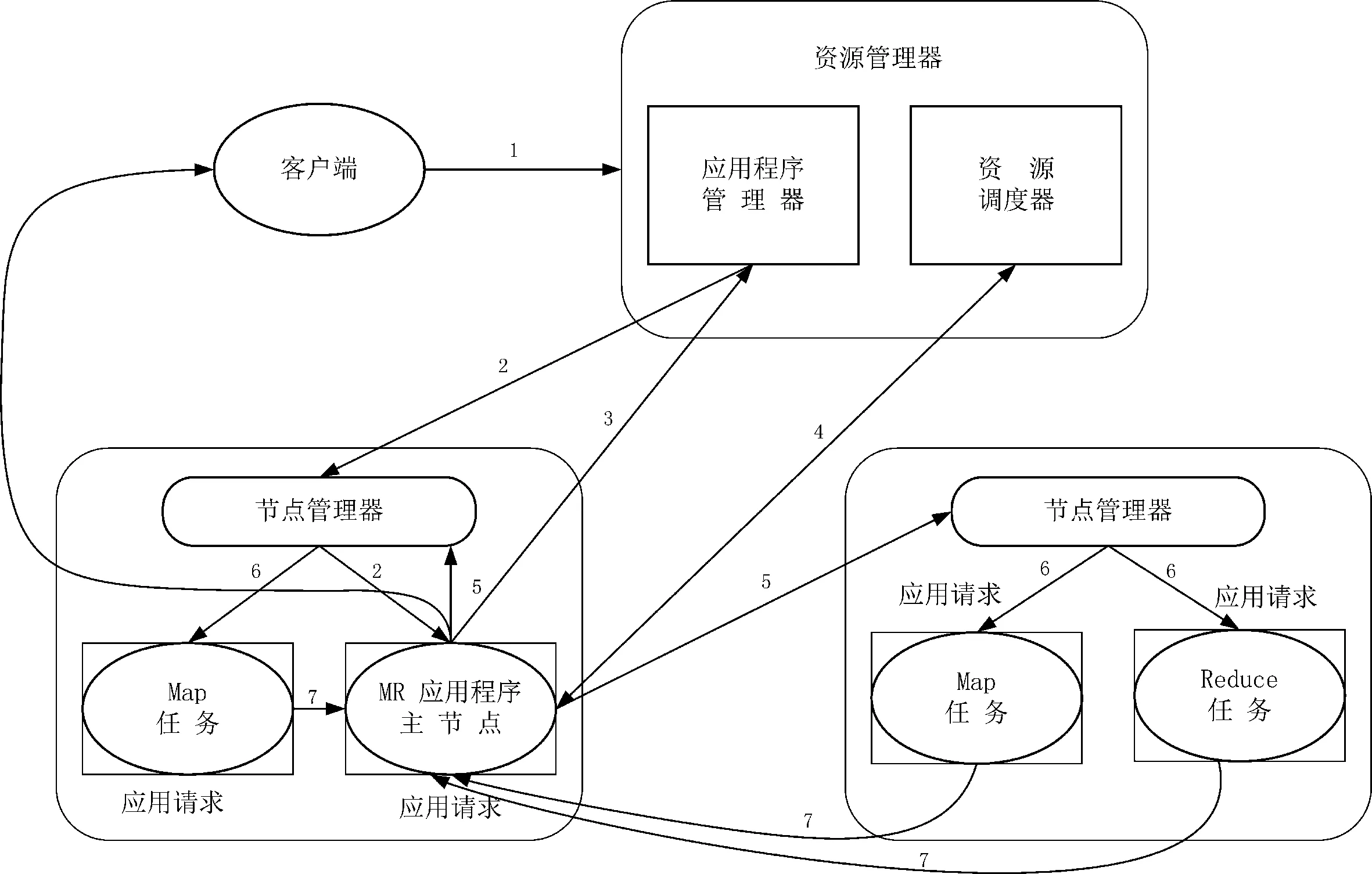
图1 资源调度器资源分配流程
1.2 加权计算能力调度算法
从以上调度模型可知,Hadoop采用了3级资源分配策略,当某个节点上有空闲资源时依次选择队列、应用程序和Container请求,其调度过程如下:1)选择队列。Hadoop采用基于优先级的深度优先遍历算法;2)选择应用程序。选定叶子队列后,容量调度器按照提交时间对叶子队列中的应用程序进行排序并依次遍历,以找到一个或多个最合适的Container;3)选择Container。对于同一个应用程序,所请求Container可能是多样化,涉及不同的优先级、节点、资源量和数量。当选中一个应用程序后,容量调度器将尝试优先满足优先级高的Container,对于同一类优先级则优先满足本地性因子高的Container。
在原算法中作业队列是先按照作业提交时间和作业优先级进行排序,然后选择队列头部的作业。本文改进算法首先根据作业权重对每个队列的作业进行排序,然后将空闲时隙分配给选中队列的第一个作业的Container。因此,改进算法中作业权重的选择是作业排序的重要参考依据。
为使调度任务避免长期等待,改进算法优化了分配步骤中Container的排列顺序,即根据实际情况来动态调整Container的权值。在分析权重排序时,令avgResource表示请求的平均资源大小,Resource表示某个Container的资源请求量,containerNum表示Container的数量,则有:

(1)
为保证优先级,如果container[i]的权重为weight[i],将优先级体现在权重中,设立如下公式:

(2)
式中,V表示一个轮转周期内处理的任务数总量,一般情况下V为一个常数。于是可以得到:
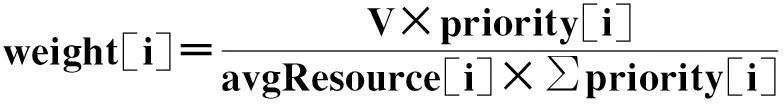
(3)
同时,考虑到Container请求中的期望资源所在节点、Container数目和Container提交时间等参数对Container选择的影响,由此可得:

(4)
式中,ctime,stime分别表示当前时间和任务提交时间,resouceDist表示资源与计算节点的距离。
算法中的伪代码设计如下:
Input: JobInfo
Output: null
update parameter of job
factor=cTime/sTime+container/sum(container)
if container numbers of job>0
Then
job weight=(priority/sum(priority))*factor*resourceDist
else
job weight=0
end if
改进算法增加的参数、优先权值和资源节点距离对应的取值如表1、表2所示。

表1 优先级对应具体值
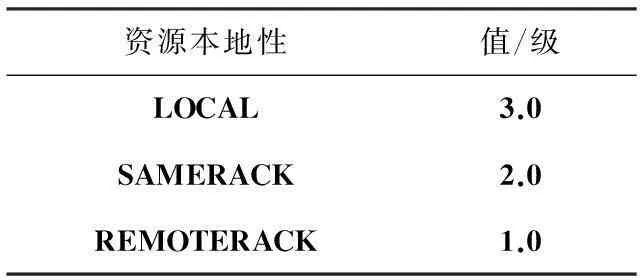
表2 资源本地性对应具体值
2实验结果及分析
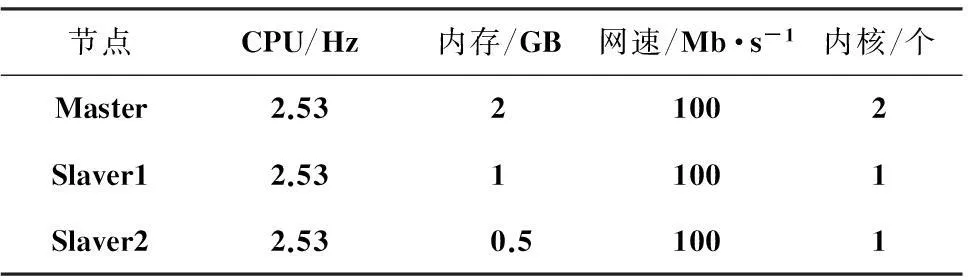
表3 节点配置参数
本实验环境采用3台机器构成的Hadoop异构集群,其操作系统为Ubuntu12.04,Java版本为jdk1.7.0_45,Hadoop版本为2.2.0。3个节点配置参数如表3所示。
实验采用了Hadoop自带WordCount实例,通过计算处理任务时的花费时间来比较自带算法和改进调度算法的性能。将10个作业提交到集群上运行,作业的大小不同,而且其各自的任务优先级、资源节点距离也各不相同,其详细信息如表4。集群任务分别采用FIFO、计算能力调度算法和本文改进算法来执行,所完成时间对比如图2所示。
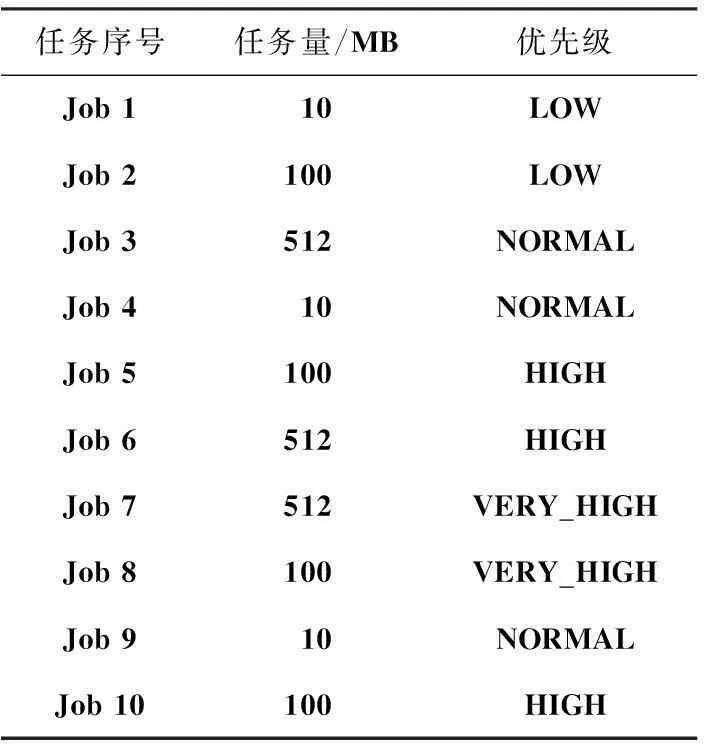
表4 任务作业的参数
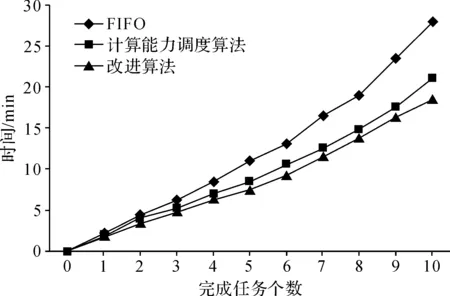
图2 作业在不同调度算法下的完成时间
从图2可以看出改进算法在任务数较少时并没有太大优势,但随着作业数量增多,改进算法相比计算能力调度算法而言已有一定的改善,相比FIFO算法的优势则更为明显。这是因为改进算法进一步优化了原来的计算能力调度算法,特别针对系统任务数较多时,优化分配了Container的排列顺序,并通过动态性的调整Container权值,使其在调度过程中能够自适应调整作业的权值,减少了系统任务调度和作业执行过程中的等待时间。实验数据结果表明,在任务数较多的情况下,改进算法性能相较于系统默认的FIFO算法提高了将近30%,而对于计算能力调度算法也提高了7%左右。实验结果表明,本改进算法确实进一步提高了Hadoop中原先的计算能力调度算法性能。
3结束语
作业调度系统是Hadoop平台的核心,在很大程度上影响了平台的性能和系统运行效率。本文提出的改进算法在计算能力调度算法的基础上,根据作业优先级、资源需求量和资源本地性等因素计算作业的权值,当系统出现空闲时优先调度权值高的作业。改进算法动态地调整了作业的执行顺序,降低了作业在争夺资源过程中产生的等待时间,从而提高了系统的运行效率。
参考文献
[1]董成西.Hadoop技术内幕:深入解析YARN架构设计与实现原理[M].北京:机械工业出版社,2014:30-52.
[2]Dean J, Ghemawat S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM,2008,51(1):107-113.
[3]Zaharia M, Borthakur D, Sen Sarma J, et al. Delay scheduling: a simple technique for achieving locality and fairness in cluster scheduling[C]//Proceedings of the 5th European conference on Computer systems. ACM,2010:265-278.
[4]胡丹,于炯,英昌甜,等.Hadoop平台下改进的LATE调度算法[J].计算机工程与应用,2014,50(4):86-89.
[5]Hadoop. CapacityScheduler[EB/OL]. [2014-09-22]. http://hadoop.apache.org/docs/current/had-oop-yarn/hadoop-yarn-site/CapacityScheduler.html.
[6]Jayalath C,Stephen J,Eugster P.From the Cloud to the Atmosphere: Running MapReduce across Data Centers[J].IEEE Transactions on Computers,2014,63(1):74-87.
Improvement of Scheduling Algorithm in Hadoop Based on Weight
Zhu Jianjun, Zhang Tong, Wu Zhefu
(CollegeofInformationEngineering,ZhejiangUniversityofTechnology,HangzhouZhejiang310023,China)
Key words: cloud computing; task scheduling; weight
