IPC自动分类技术的研究与应用
2016-01-18吴宏洲
吴宏洲

摘要:一种无需语料库和复杂数学模型支持的IPC分类简单方法。该方法借助IPC分类表、同义词库、人工辅助植入同义词或上位词增加权重等手段,调整分类倾向,来捕捉文献相应的主分类和相关分类。该方法可作为信息加工专利文献分类的辅助工具。
关键词:IPC分类;分类表;同义词库;上位词;相似度算法
中图分类号:TP391 文献标识码:A 文章编号:1009-3044(2015)33-0116-04
Research and Application of IPC Automatic Classification Technology—the Auxiliary Automatic Classification of the Realization of the Algorithm
WU Hong-zhou
(The China patent information center, Beijing 100088, China)
Abstract:A method of the IPC classification is simple without the help of a complex mathematical model and corpus. The method using the IPC classification comparison table, a synonym sets, artificial auxiliary implanted synonyms or hypernym , to increase the weight, to adjustment of classification, to capture the corresponding main classification and related classifications. This method can be used as auxiliary tool for the classification of information processing of patent literature.
Key words:the IPC classification; Classification entry table;A synonym base; Hypernym; Similarity algorithm
在专利信息技术领域中,自动分类技术的研究自2010年变为实用,成为标志性里程碑。多年来基于历史信息的海量计算占主导。笔者致力于简单实效的轻量级软件研究,提出一种基于分类表的简约方法。通过实验来验证其可行性。
1 实验背景
早期手工分类,从粗到细,完全由分类员完成。主要工具是查阅专利分类表。随着计算机应用的发展,分类表由书籍变成电子版,又经历了网络版、网页版变迁。2010年以后才真正标志性地实现了自动分类技术的应用,将研究变为实用。一种基于历史文献的分类方法至今占据着主导位置。
1.1 基于历史文献的分类方法
以历史文献作训练空间,构建语料库,通过数学模型运算获得相似度评分,提供备选方案。其中数学模型可以多种。如SVM、KNN、Naive Bayes等等[1]。其优点是对已分类文献分类效果良好。其缺点是需配备海量装备,代价大。
这种方法后来也受到两点质疑。
1)发明专利的创新性
由于专利文献由两类构成:一类是开创性发明,另一类是改进性发明。对于开创性发明,其新技术方案所依据的基本原理与已有技术有质的不同。这类专利之间相似度很低。因此基于历史的方法,问题会出在参照物信息不充分上。
2)IPC分类的渐变性
在专利审查流程中有一种预警机制。当某个时期某个领域专利案件量增长超出预期就会报警。同时引起两个部门的注意。A)宏观战略研究部门,主要观测是否将有引领潮流的革命性技术到来,例如:纳米。预测5到10年将进入市场,对宏观经济产生影响。B)审查业务管理部门,检测到案件量当超过某个数量级的阀值时,就要考虑审查增员问题,或者考虑该分类是否需要再细分。一种变化是增加小组细目,另一种变化停止原小组细目,重新分配一个新的大组,然后再分到各个小组细目。因此,专利分类表会根据需要随时调整。因此基于历史的方法问题会出在参照物信息不确定上。
1.2 基于分类表的分类方法
分类表作为指导性工具,曾经是手工时代的产物,早已被自动化工具所取代,目前只剩备忘录作用。笔者以为分类表不仅有良好层级结构,还有规则指向,交叉参考等。如能充分利用,可以开发出分类导航(XML- Xslt版已初具导航作用)产品;将括弧中规则指向和交叉参考与人工智能相结合,自动分类可以达到极高准确率,当然引入规则会变得相当复杂。分类表简单使用,已经具备可计算性。这恰恰是轻量级分类方法须采用的重要手段之一,不可或缺。这种方法也有许多困难需要面对。例如:
1) 专利文献语言文化差异
专利文献格式严格,结构特征明显。作者撰写文档,须通过形式审查才能进入审批流程。由于对撰写具体内容不作限定,说明书的撰写水平受作者的语言文化背景、地域差异、学识和规范习惯等因素影响,因人而异。发明标题中的词素非常重要,需要抓住主题重点;权利要求书的描述是树形结构,可以程式化固定。例如:“一种”(独立权利要求),“根据”(从属权利要求),可以构成林、树、杈关系。这对主分类和相关分类分析有参考价值。笔者曾抽样分析,结果令人失望。严格按统一规范来撰写的并不多,失去利用价值。要求文字术语统一规范,更是难事。
2) 专利分类表术语不统一规范
电子版分类表中符号混乱,文字缺乏统一规范。通过取样几个近义词,便可略见一斑。参见表1。
某些词语意思相近,复杂而繁多,分布在不同分类中,给解析带来困难。
3) 抽象专利分类表与具象专利文献之间术语差异
该差异是两者不在一个层面自然形成的,需要一个沟通机制。由此,引出基于同义词的术语分类方法。
1.3 基于同义词的分类方法
专利文献加工中人工标引主要的工作就是标注文献的关键词和同义词。该方法主要作为提高专利检索查准率、查全率的必要手段之一。而对于文档自动分类来说,利用分词技术来获取文档中有限高频词。两者目标一致,方法有别,一个人工,一个计算技术。由于计算技术缺乏模糊识别、灵活和准确的理解力。因此,最终还是需要适当植入人工标引关键词来弥补计算技术的缺陷,提高准确性。
其哲学思想也与数学方法论不相矛盾。如果把专利文献和专利分类看作向量空间模型,文档空间被看成是被简化了的一组能够代表文档的高频正交词条有限特征向量空间,词条频度权重,看作特征轴上的投影。IPC分类也是有限特征向量空间子集,由不同的特征排列组合而成。某些特征被不同的分类空间所共用。像星座群一样,每个星座对不同的分类群起的作用不同,有些分类群整体很耀眼,有些分类群整体有些黯淡,甚至没有光芒。如果文档空间向量与ipc空间向量存在交集,在ipc某些特征轴上能够直接找到投影;否则,就相离。如果,某些特征通过变换折射也可以找到投影,那么认为,两者之间间接存在交集。这里折射变换的原理也就是同义词和上位词植入的基本原理。
如果直接用分类表来解析文献,寻求的分类目标可能会发散。因为文档空间与IPC分类空间不直接在一个层面上,坐标没有对应关系,投影回到原点。有人会提出按照文档结构分类方法,认为标题或文摘部分很重要,通过增加整个标题或文摘的权重来施加影响力。这对于空间的形状会有所改善,但并未发生质的改变。也只是改变了投影形状量的大小。只有,真正将文档空间中不在同一个层面的那些高频特征词,通过上位词或同义词的折射变换,才可以改善其在分类空间中的投影,以突显或还原其真实形态。
利用这一方法,通过逐一折射扫描,捕捉分类空间的投影。不仅可以原型再现,还可以通过局部放大,来达到逐一捕获主IPC和或其他相关IPC的目的。分类会因同义词强化效果大大改善,达到很好的收敛性。
因此,建立一个完善的同义词库意义重大。提供捡拾同义关系词的入口,是基于同义词分类方案进入一个良性循环的必要手段。这是需要全员参与的工作,需要群体的智慧。同样,提供一个可植入关键词的入口,对于不依赖于现有或历史,也是设计者需要考虑的。
建立同义词或上位词关系词方法其实简单。例如:蛋白质是由肽构成的,肽是由氨基酸构成的。那么建立“肽→蛋白质”关系,肽是上位词,蛋白质是下位词。文献中使用了“…蛋白质”,就植入上位的“蛋白质”和“肽”;又例如:文献用“英文/英语”,那么就植入其上位词“外语”,建立“外语→英语”关系。新建立的关系词被积累保存到同义词库,一劳永逸。
与基于历史文献语料库相比,同义词库无疑是轻量级的。同义词库可以弥补专利分类表中词语抽象的不足,用来化解专利文献中词语具象的复杂性。在专利分类表和专利文献之间搭建起沟通的桥梁。
2 IPC自动分类的技术实现
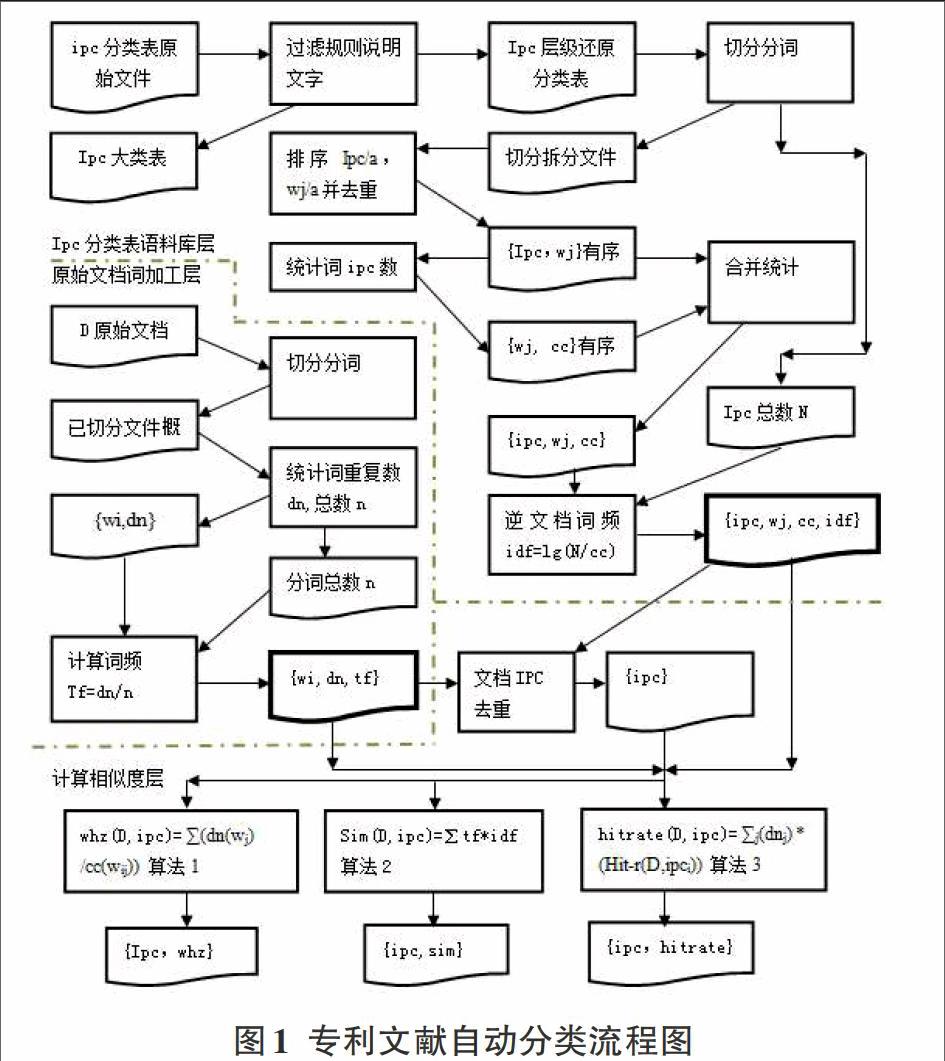
IPC自动分类的实现,其专利文献自动分类实验流程图,如图1所示。
专利分类流程图分为两个部分,可以分开实现,IPC分类表语料库加工层最终得到的是分类表语料库。由{ipc,wj,cc,idf}构成,内容参见定义1。
定义1:ipci,用以表示IPC分类表中的某个专利分类号;wij,用以表示ipci分类描述文字切分出的某个特征词;cc(wij)表示,特征词wij在IPC分类表中有多少分类与之有关;N,用以表示IPC分类表中总共有多少分类条目;idf(wij) ,用以表示IPC分类条目中的词条相对于总体分类的反文档数,是wij的重新评估的权重,idf(wij)=log(N/ cc(wij))。
原始文档加工层,最终得到文档目标语料。由{wi,dn,tf}构成,内容参见定义2。
定义2:D,用以表示原始文献;wk,用以表示D中切分出的词条;dn(wk),用以表示wk的重复数;n,用以表示D中的总词条数,n=∑dn(wk);tf(wk),用以表示wk的词频,tf(wk)= dnk/ n;
计算相似度层,用三种算法分别计算相似度排名。参见自动分类算法。
2.1 IPC自动分类的算法
本文给出自定义的两种算法和一种已有算法进行对比。即:
l WHZ算法——一个自定义算法
l Tf-Idf算法——一个已有算法
l Hit-Rate算法——一个自定义算法
2.1.1 WHZ算法
whz算法属于自定义算法,用来抑制版权争端,与Tf-Idf和BM25算法相当。
定义3:
文档D与分类条目ipci相似度,用whz(D, ipci )表示。
whz(D, ipci )= ∑( dn(wj)/cc(wij))
其中,dn(wj)代表文档词条wj重复度权重,cc(wij)代表ipci条目中wj词条被多少个其他ipc分类条目所共用或分享。
2.1.2 Tf-Idf算法
Tf-Idf算法属于已有算法,其标准形式的定义有 BM25算法[略]。
定义4:
文档D与分类条目ipci相似度,用Tf-Idf (D, ipci )表示,或sim(D, ipci )表示。
sim(D, ipci )= ∑j(tf(wk) *idf(wij))
=∑j((dn(wj)/n )* log(N/ cc(wij))
其中,dn(wj)代表词条wj重复数,cc(wij)代表词条wj逆文档数,亦即词条与其他ipc分类也相关的ipc条目数。
2.1.3 Hit-Rate算法
由于whz自定义算法,与tf-idf算法总体趋势接近。为防止前两种算法接近重叠,我们又从另外角度给出了一种自定义的算法。其主旨是,将ipc条目其所涉及分词,与专利文献中高重复度的词相匹配,匹配占比越大,得分越高,与ipc条目越相似。
定义5:
函数has(wij)如果wij出现在文献D中,则取值1,如果没有出现在文献D中,则取值0;Hit-r(D,ipci),用于表示命中率或占比。
Hit-r(D,ipci)= (∑j has(wij) ) / (∑j (1));
其中j=1..m,则∑j (1)=m。
文档D与分类条目ipci相似度,用Hit-Rate(D, ipci) 表示。
Hit-Rate(D, ipci)=( ∑j(dnj ))* (Hit-r(D,ipci))
= (∑j(dnj ))* (∑j has(wij) ) / (∑j (1))
3 实验效果(The experiment effect)
抽样考察4个发明公开专利文献。取试验样本4个发明公开专利的“标题+文摘”,参见表2。
表2 试验样本4个发明公开专利的“标题+文摘”
[专利\&标题+文摘\&1\&
专利文献切分分词,参见表3。
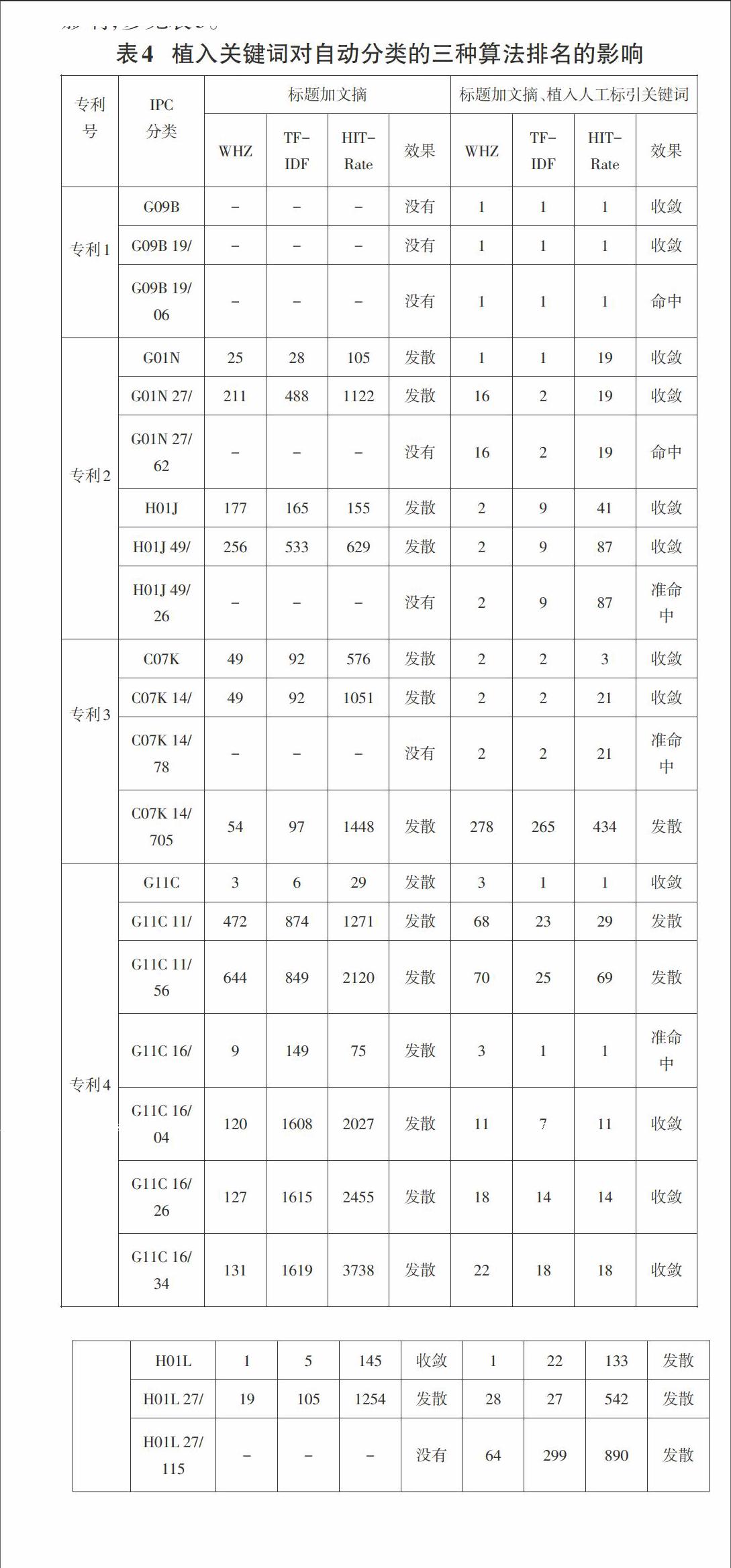
观测实验结果,植入关键词对自动分类的三种算法排名的影响,参见表5。
直接通过分类表计算自动分类相似度排名,收敛性较差。参见表4左部结果。植入同义词调整后,分类效果明显改善,基本收敛。参见表4右部结果。
笔者通过植入同义词和上位词来改善分类表解析不收敛的问题。如果调整得不到希望的分类,亦即,分类不收敛,就要重新调整其他同义词方向,来改变策略,直至得到与文献内容相符合且最接近的分类为止。
从实验效果看,本文所用的分类表与同义词修正相结合的分类方法,收敛效果明显。与实际采用何种算法无关,要发散都发散,要收敛都收敛。无疑TF-IDF优于自定义。
4 结论
IPC自动分类技术作为计算机辅助工具来使用,可为人们提供一种具有参考价值的分类信息,供使用者选择。本文所述分类方法是一种基于分类表和同义词相结合的方法,不依赖于历史信息也不受限于历史信息的不足,不需要大量训练数据的方法。其优点是:能将专利文献中的不同权重的高频词,通过同义词库的扩充,与分类表直接比对,不需要花费大量资源收集专利文献语料库,只需借助有限同义词植入来调整分类运算,来解决分类不收敛的问题。该方法在存储量和运算量方面属于轻量级的,且运算速度快,加工一篇文献不到1秒,需要的资源不多。通过植入同义词或上位词调整权重,可以改变某些分类的发散或收敛方向,来达到逐一捕获主ipc和每一个相关ipc的目的。可作为半自动的简单灵活的分类捕捉工具。其缺点是算法受限于同义词库的建立,取决于植入同义词的经验,调整植入词,改变某些分类的发散或收敛方向,需要使用者自己凭经验来掌握和控制。初期需花费一些时间将分类表作一个初步同义词整理,然后通过工作进行中不断来扩充同义词库,使之趋于完善。该方法对CPC自动分类的实现有借鉴意义。
参考文献:
[1] 刘玉琴,桂婕,朱东华.基于IPC知识结构的专利自动分类方法[J].计算机工程,2008, 34(3):207-209.
