基于概念簇的多主题提取算法
2016-01-15马甲林,张永军,王志坚
网络出版地址:http://www.cnki.net/kcms/detail/23.1538.TP.20150302.1106.006.html
基于概念簇的多主题提取算法
马甲林1,2,张永军1,2,王志坚1
(1.河海大学 计算机与信息学院,江苏 南京 211100; 2. 淮阴工学院 计算机工程学院,江苏 淮安 223003)
摘要:现实世界存在着大量的多主题文本,多主题在信息检索、图书情报等领域有着广泛的应用。传统主题提取算法大多是针对文本整体提取一个主题,且存在缺乏语义信息、向量高维和稀疏等缺陷。以《知网》为知识库,构建概念向量表示文本,根据概念的语义及上下文背景对同义词进行归并、对多义词进行排歧,并利用概念间语义关系实现语义相似度计算;在此基础上提出基于概念簇的多主题提取算法MEABCC,该算法通过对概念进行聚类,得到多个主题簇;在使用K-means算法进行概念聚类时,通过“预设种子”方法对其进行改进,以弥补传统K-means算法对初始中心的敏感性所引起的时空开销不稳定、结果波动较大的缺陷。实验结果表明,该算法具有较好的准确率、召回率和F1值。
关键词:语义;稀疏;上下文背景;知识库;概念簇;多主题提取; K-means;MEABCC
DOI:10.3969/j.issn.1673-4785.201405066
中图分类号:TP18 文献标志码:A
收稿日期:2014-06-01. 网络出版日期:2014-03-02.
基金项目:国家自然科学青年科学基金资助项目(11201168).
作者简介:
中文引用格式:马甲林,张永军,王志坚. 基于概念簇的多主题提取算法[J]. 智能系统学报, 2015, 10(2): 261-266.
英文引用格式:MA Jialin, ZHANG Yongjun, WANG Zhijian. Multi-topic extraction algorithm based on concept clusters[J]. CAAI Transactions on Intelligent Systems, 2015, 10(2): 261-266.
Multi-topic extraction algorithm based on concept clusters
MA Jialin1,2, ZHANG Yongjun1,2, WANG Zhijian1
(1. College of Computer and Information, Hohai University, Nanjing 211100,China; 2. School of Computer Engineering, Huaiyin Institute of Technology, Huaian 223003, China)
Abstract:There are a large number of multi-topic documents existing in the real world, and the extraction of multi-topic is widely used in the fields of information retrieval, library science and intelligence. In the traditional theme extraction algorithm, in most cases a theme is extracted for the whole text, which lacks of semantic information and has high-dimensional vector and sparse defects. Setting concept vectors to represent text based on the repository of cnki.net, merging synonyms and discriminating polysemy according to the semantic of concepts and context, thereby achieving the computation of semantic similarity in light of the semantic relation among concepts. The multi-topic extraction algorithm based on the concept of clusters (MEABCC) is proposed. The MEABCC acquires multiple topics by clustering concepts. The conceptual clustering made by K-means algorithm is improved through the method of presetting "default seed", which makes up the undulating time and space overlay and the unstable results. This happen to be caused by sensitivity to initial centers of traditional K-means algorithm. The experiments showed that MEABCC has good accuracy, recall and F1 values.
Keywords:semantic; sparsity; context; knowledge base; concept clusters; multi-topic extraction; K-means; MEABCC

通信作者:马甲林. E-mail:majialin@126.com.
现实世界存在着大量的多主题文本,据统计36.85%文章包含多个主题,Sekine和Nobata主持的一项研究表明,日本新闻文章中的44.62%在谈论多个话题。从文本中提取反映不同观点的多个子主题,在信息检索、图书情报和信息安全等领域有着非常广泛的应用[1-2]。大多数传统主题提取方法是针对一篇文章从整体考虑提取一个主题,未能区分出文内混杂的多个子主题,文献[3]认为子主题体现在主观句子的语义中,提出CRF模型从主观句子的极性角度提取子主题,该方法以形容词、副词词性判断句子语义的贬褒极性,未涉及其他语义信息;文献[4]使用滑动窗口的方法可以从网络评论文本提取局部子主题,适用于网络评论文本;另外,常用的LDA(latent Dirichlet allocation)模型提出于2003年,该模型虽然目前使用广泛,但LDA是一个完全基于统计的方法,在向量空间模型(VSM)下存在向量高维和稀疏、忽略词汇语义及上下文背景等问题,同时提取过程受到同义词和多义词的干扰,因而在质量和效率上表现欠佳[3-5]。
本研究利用《知网》知识库,采用概念向量模型(CVM)取代传统VSM模型表示文本,同时在CVM模型下同义词将被自动归并,再根据上下文语义相关性对多义词进行排歧处理;其次通过计算概念的语义相似度取代传统相似度计算,在此基础上提出基于概念簇的多主题提取算法(MEABCC),该算法采用无监督学习的方法,通过改进经典K-means算法对文本概念进行聚类后得到多个子主题簇,其中,使用“预设种子”方法改进来K-means算法,以弥补传统K-means算法K个初始中心选择的随机性所引起的时空开销不稳定、结果波动较大的缺陷。
1概念向量模型
文本处理的首要问题是文本表示,本研究以中科院计算机语言信息工程研究中心董振东主持创立的《知网》为知识库,建立基于概念的向量模型来表示文本。
1.1同义词和多义词处理
《知网》是一个以汉语和英语词汇所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。在《知网》中,词汇语义描述被定义为概念 。每一个词可以表达为几个概念,概念是由一种知识表示语言(DEF)来描述,这种用来描述概念的“词汇”又叫义原,相比词汇的规模,义原的数量很少。《知网》定义了1500多个义原,分为3类:基本义原、语法义原和关系义原,DEF中基本义原反映了概念的主要语义,例如:词汇“爱好者”,在《知网》中用DEF的基本义原为:DEF={Human|人,*Fondof|喜欢,#WhileAway|休闲},所表达的意思是:“爱好者”是个人,这个人喜欢某个东西,本词语是和休闲相关[7],它们之间存在语义相关性。在《知网》中,如果某个词只有一个意思,那么这个词对应唯一的概念,而多义词往往对应多个概念,为了找到某个多义词在文中的具体含义,作如下定义:
定义1 对于任意中文词汇c0,在《知网》中描述其对应概念的DEF的基本义原集为{c1,c2,…,cm},(m>=1)则称c0与{ c1,c2,…,cm}属于同一个语义类。
语义类不仅与概念对应,而且与描述概念的DEF对应,语义类揭示了词语之间的语义联系,描述某个DEF的基本义原在语义上是相关的,某个语义类和文章语境相符时,文中很可能出现该语义类包含的词汇,利用这一语言现象可以消除词汇歧义。如图1:多义词“水分”,在语义类包含{“植物”、“土壤”、“阳光”、“生长”}中“水分”的含义是指“物体内含有的水”,而在语义类包含{“经济”、“数据”、“增长”、“报告”}中“水分”的含义是指“夹杂不真实成分”。
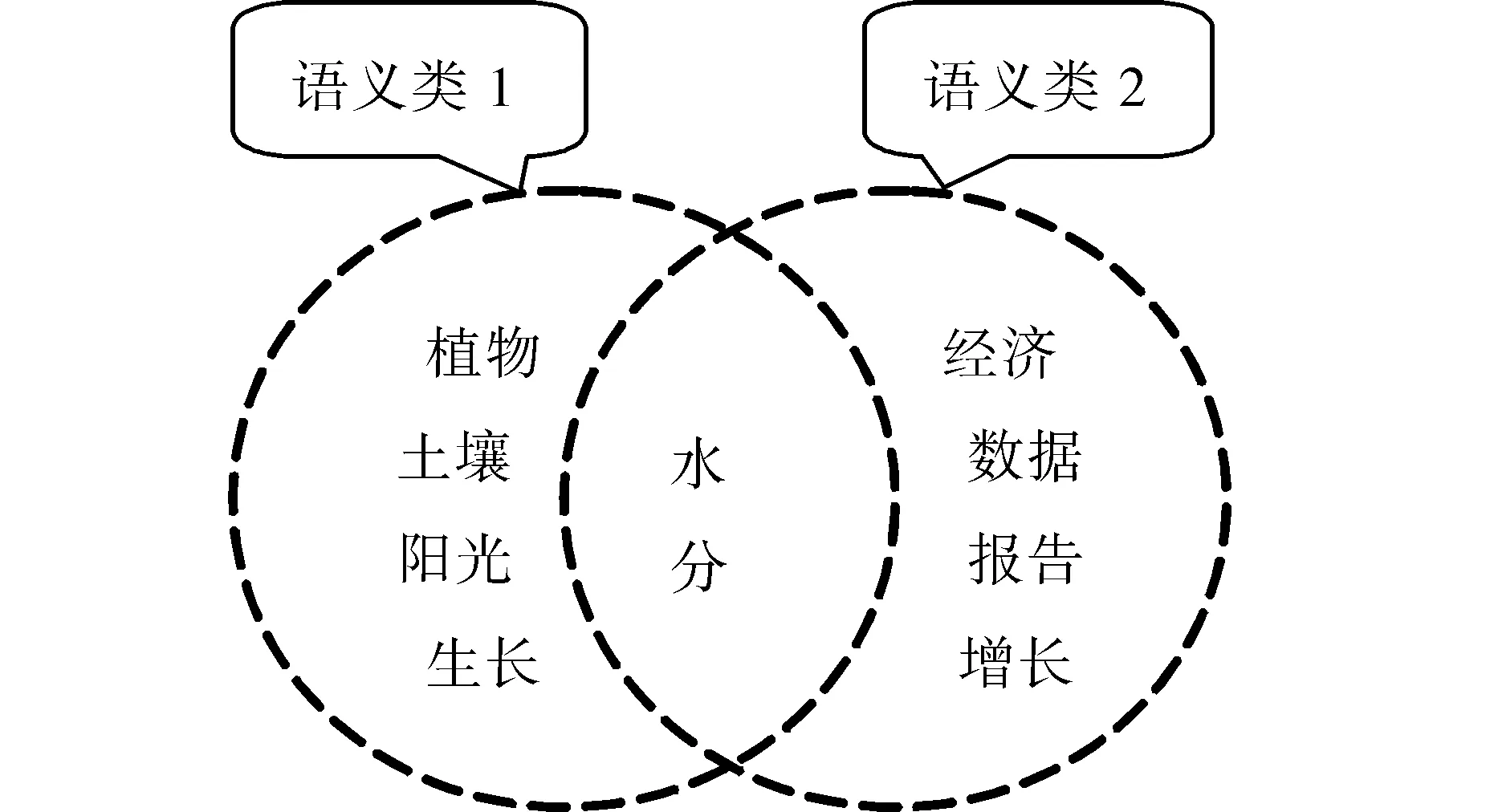
图1 “水分”语义类示意图 Fig.1 The semantic class schematic diagram of ′moisture′
由于汉语的复杂性,同一篇文章中一词多义和同义词的情况非常多,单纯的机械词频统计方法无法处理涉及词汇语义的问题,这是影响文本主题提取质量的一个重要因素。为了解决多义词排歧和同义词归并问题,本研究利用《知网》,同义词在概念映射阶段被归并到同一概念上;多义词对应多个概念,根据语义类成员词和上下文背景的语义相关性来为多义词选择适合该文语境的语义类。定位多义词在文中最佳语义类的思路是:如果某个语义类所属成员词汇在本篇文中出现权值之和越大,说明该语义类比其他语义类更符合文章主题,则该语义类是该多义词的在此文中最合适的语义类。词汇wi在文章中所含的信息量H(wi)计算公式
(1)式中:ST表示待处理文本,TF(wi,ST)表示词汇wi在文中出现的频率,P(wi)为词wi的概率分布。
定义2 多义词c,它的第i个语义类Li权值为[7]
(2)式中:n为某个语义类Li成员词在文中出现的个数。语义类权值越大,该语义类成员词对文章主题的贡献越大。
定义3多义词c,在《知网》中对应多个语义类,选择符合该文背景的最佳语义类公式为
(3)1.2 概念向量构建算法
传统基于特征词的向量空间模型(VSM),认为向量是正交的,即词汇之间互不相关。显然,这和现实情况不符,众所周知,文献中各个词汇之间存在着复杂的语义联系[5]。利用《知网》知识库,构建概念向量模型来表示文本,可以建立起词汇之间语义联系,为后续进一步的语义计算提供了可能。CVM构建过程首先对文本进行分词和预处理后得到文本的特征集,然后对特征集中的每个特征进行概念映射;特征词到概念的映射过程中大量的同义词被归并到相同的概念中,实现了强度较大的降维;其次利用《知网》概念描述语义的特点,根据语义类和上下文背景的相关性,实现多义词排歧,其构建算法如下。
算法1概念向量构建算法
输入:文本T;
输出:文本T的概念向量T。
步骤如下:

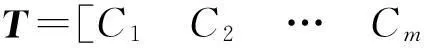
3)依次查询《知网》知识库,对特征词进行概念映射;
①查询《知网》,若T的特征词Cm对应唯一的概念,则Cm为单义词或同义词,直接获取Cm的概念,转至4);
②: 若Cm对应多个概念,则Cm为多义词,所以Cm对应多个语义类表示为{L1,L2,…,Lp}(p≥1) ,采用如下步骤为Cm进行多义词排歧:
Fori=1 top
{
利用式(1)计算语义类Li所有成员词汇的信息量;
利用式(2)计算Li权值;
}
Nexti;

4)对TG按照概念进行整理合并得到:
式中:Gq为TG集合中无重复的概念, q,i,j,k≤m;//现实同义概念的归并;
5)输出文本T对应概念向量T
2多主题提取算法
对于单主题提取,机械统计的主题提取方法通过词频统计按照权值大小抽取主题句,能够得到质量达到简单应用级别的主题句[6]。然而,现实中存在着大量的多主题文献,单纯的统计方法无法抽取多主题。本研究提出的MEABCC多主题提取方法是以1.2节提出的概念向量来表示文本,利用《知网》中义原的树形层次体系结构计算义原相似度,进而计算概念的相似度,然后通过改进K-means算法对组成文本的概念进行聚类,形成多个子主题概念簇。
2.1概念相似度计算
相似度是衡量2个词汇语义关系的一个重要指标,涉及到词语的词法、句法、语义甚至语用等多方面的信息。其中,对词语相似度影响最大的是词的语义。在《知网》中,词汇被描述为概念,词汇的相似度计算就转化为对概念的相似度计算。词语距离与词语相似度之间有着密切的关系。2个词语的距离越大,其相似度越低;反之,2个词语的距离越小,其相似度越大[8]。
《知网》通过多个义原来描述概念,义原之间存在着各种复杂的关系,如:上下位关系、同义关系、对义关系等。其中,最重要的是上下位关系,所有的义原根据上下位关系构成了一个树状的义原层次体系, 所以可以通过计算义原距离得到概念的距离进而获得概念的相似度[9]。假设2个义原在义原树层次体系中的路径距离为d,d的计算过程如下:







