人民币冠字号码识别预处理算法研究
2016-01-08冯博远,任明武,张煦尧等
人民币冠字号码识别预处理算法研究*
冯博远1,任明武1,张煦尧2,杨静宇1
(1.南京理工大学计算机科学与工程学院,江苏 南京 210094;2.中国科学院自动化研究所,北京100190)
摘要:近年来,人民币冠字号码的识别受到越来越广泛的关注,其在打击经济犯罪,维持市场稳定和社会和谐等方面都具有很强的实用性和广阔的应用前景。一个稳定高效的人民币冠字码识别系统在很大程度上依赖于图像预处理的结果。提出了一套完整的人民币冠字码识别预处理方案,其中包括图像采集、倾斜校正、采集方向识别、冠字号码区域定位和二值化、字符提取等算法,并对三种冠字码区域二值化方法进行了比较和分析。实验结果表明,所提出的预处理方法精度很高,为后续的冠字码字符识别工作提供了可靠的技术保障。
关键词:人民币冠字号码识别;预处理;二值化;字符提取
中图分类号:TP391.4 文献标志码:A
doi:10.3969/j.issn.1007-130X.2015.06.017
收稿日期:*2014-04-10;修回日期:2014-07-02
基金项目:国家自然科学基金资助项目(60875010)
作者简介:
通信地址:210094 江苏省南京市南京理工大学计算机科学与工程学院
Address:School of Computer Science and Engineering,Nanjing University of Science and Technology,Nanjing 210094,Jiangsu,P.R.China
Image preprocessing for RMB serial number recognition
FENG Bo-yuan1,REN Ming-wu1,ZHANG Xu-yao2,YANG Jing-yu1
(1.School of Computer Science and Engineering,Nanjing University of Science and Technology,Nanjing 210094;
2.Institute of Automation,Chinese Academy of Sciences,Beijing 100190,China)
Abstract:In recent years, the research on RMB (renminbi bank note, the paper currency used in China) serial number recognition has drawn more and more attentions. It has promising applications in financial crime reduction, financial market and social stabilization. The accuracy of RMB recognition relies heavily on the image preprocessing results. In this paper, we propose an entire preprocessing system, including the steps of RMB image sampling, skew correction, identification of RMB orientation, serial number region detection and binarization, and character extraction. Experimental results demonstrate that the proposed method achieves high precision and facilitates the subsequent character recognition task.
Key words:RMB serial number recognition;preprocessing;binarizaiton;character extraction
1引言
文本图像通常含有非常复杂的背景,从中精确提取单个字符具有很大的难度。然而,许多字符识别应用都依赖于完整的单个字符,例如车牌识别、银行票据识别等。近年来,针对不同的应用需求,已经提出了很多有效提取字符的方法,但对于含有复杂背景和干扰的人民币冠字号码识别[1,2],字符提取的相关方法和资料还是非常有限。
人民币是中国大陆境内法定的流通货币,每张人民币都含有一组特有的冠字码串,由10个字符组成,包括两个英文字母和八个阿拉伯数字。冠字号码是区分人民币最主要的依据,相当于他们的“身份证”。可靠高效的冠字码识别系统可以帮助我们追踪纸币的流通、打击经济犯罪、维持贸易市场的稳定以及维护社会的和谐统一。
本文针对含有复杂背景、光照变化、污渍和磨损的人民币冠字码识别问题,提出了一套完整的识别预处理方案,从人民币图像中精确提取出单个冠字码字符,为后续的识别模块提供样本。纸币图像的采集通过集成在点钞机中的接触式图像传感器CIS (Contact Image Sensor)完成。通过单次扫描,我们可以得到一张透射图像和一张反射图像,如图1所示,其中,透射图像(图1a)包含被扫描纸币正反两面的信息,由于两面图案的透射,导致冠字码区域纹理非常复杂。而反射图像(图1b)的冠字码区域背景为统一的白色,字符的提取相对比较容易。但是,我们在扫描人民币时,并不考虑其朝向,由于反射扫描方法只能采集到一面纸币的信息,如果想从反射图像中提取字符,则需要同时使用两个CIS扫描设备(纸币正反两面都需要采集,从而保证得到的两张图像中包含冠字号码),导致设备成本大幅增加。所以,这里我们只能从背景更为复杂的透射扫描图像中提取冠字码字符。

Figure 1 Scanned RMB images 图1 人民币扫描图像
我们注意到,在通过透射方法采集到的人民币图像中,冠字码字符周围存在一些小圆圈,有的圆圈甚至粘连在字符笔画上,对冠字号码的提取带来很大的干扰。这些小圆圈叫做“欧姆龙环”,被多个国家的纸币使用,如图2所示,它们以特定的方式排列成一种图案(五边形或者三角形),用来防止纸币被复印机、扫描仪等设备复制。由于这些圆圈的灰度值和宽度与冠字码字符笔画很接近,单纯的基于字符笔画模型[3]和基于灰度值[4]的二值化方法都无法准确地分割出完整的单个字符。

Figure 2 “EURion constellation” in RMB 图2 冠字码区域的“欧姆龙环”
针对以上问题,本文使用了一种基于占空比和块对比度[5]算法融合的二值化方法[6],结合冠字号码分布的先验知识,能够精确提取出所有单个字符。整个识别预处理系统由CIS图像采集、边缘检测、倾斜校正、朝向判断、字符区域定位和二值化,以及字符提取六个部分组成,系统流程如图3所示。

Figure 3 Working flow of the proposed method 图3 系统流程图
2冠字号码区域定位
人民币在扫描过程中,难免会发生倾斜,为了得到没有倾斜的冠字码,在进行其他操作前,需要对得到的图像进行倾斜校正。如图4所示,CIS采集的人民币图像中不含有纸币区域的灰度值为255,利用灰度梯度变化可以很容易找到纸币的四条边缘(图4a)。通过霍夫变换得到边缘对应的角度后,可以通过图像旋转去除人民币图像的扫描倾斜(图4b)。

Figure 4 Skew correction 图4 倾斜校正
由于扫描时纸币的正反和朝向不同,如图5所示,冠字码可能出现在扫描图像的四个位置。为了快速确定纸币的朝向从而找出冠字码区域位置,我们提出一种基于降分辨率和模板匹配的扫描朝向判断方法。给定一幅经过旋转校正的人民币扫描图像,我们提取该图像两侧大小为W×H的区域作为朝向检测区域。将该区域分辨率降为(W/5)×(H/5),然后和储存的四个方向的朝向检测低分辨率模板做匹配,共能得到八个匹配结果,最匹配的结果即对应此时人民币的扫描朝向(图6)。本文根据扫描图像中人民币的大小设检测区域的宽度W为350个像素,高度H为670个像素。由于冠字号码在人民币图像中的位置固定,得到人民币边缘和扫描朝向后,我们可以通过先验知识确定冠字号码的大致区域,如图7a所示。

Figure 5 Four scan orientations 图5 人民币扫描朝向

Figure 6 Identification of scan orientations 图6 扫描朝向判断
3冠字号码区域二值化
由于灰度冠字码图像受到复杂背景和圆圈的影响,直接从灰度图像中提取冠字码十分困难,我们首先将得到的冠字号码区域二值化,然后从二值化的结果中提取单个冠字码字符。
3.1占空比的二值化方法
通过对第2节得到的冠字号码区域做水平和垂直方向投影,我们可以进一步得到更加精确的冠字码区域,如图7a矩形框所示。通过观察发现,每张人民币的冠字码字符笔画在精确定位的区域内所占空间比例几乎相同,由于冠字码相对背景的灰度值较低,我们认为处在直方图低P(t)比例的像素点为冠字码字符笔画,而其余区域为背景。由于采集到的人民币图像大小相同,对应的冠字码所占像素比例也相同,通过对采集到的冠字码区域进行估计,本文将P(t)设置为15%。
(1)
(2)
其中,Hist()为精确定位的冠字码区域灰度直方图。求解时,从灰度值1开始不断枚举t,直到公式(2)成立,算法结束,t即为所求的二值化阈值。图7e展示了使用占空比二值化的结果。
3.2基于笔画宽度的二值化方法
不同人民币图像冠字码字符的宽度几乎是一致的,而且字符笔画的灰度值比背景的灰度值低。根据字符笔画的这两个特点,我们提出了一种基于笔画宽度的二值化方法。对于图像中的一个像素点i,如果以其为中心、一半笔画宽度r为半径的区域R内,所有像素点的灰度值都小于其在d角度邻接区域Kd内像素的值,则认为该像素属于字符笔画。本文中,Kd为区域R邻接的d角度方向相反的四个像素点。基于笔画宽度的二值化方法结果见图7d。

Figure 7 Serial number binarization and extraction 图7 冠字码二值化和提取
(3)
(4)
3.3块间对比度的二值化方法
块间对比度二值化[5]方法主要利用了字符笔画上像素点的灰度值低于背景像素灰度值的特性。对于图像中的每个像素点i,求以其为中心、半径为W的图像块的均值,然后和与该块邻接的四个方向上同样大小的图像块均值作对比,如果该像素点对应的块均值比d方向上相邻的两个图像块的均值都低,则认为该像素属于d方向的字符笔画(如图8所示)。
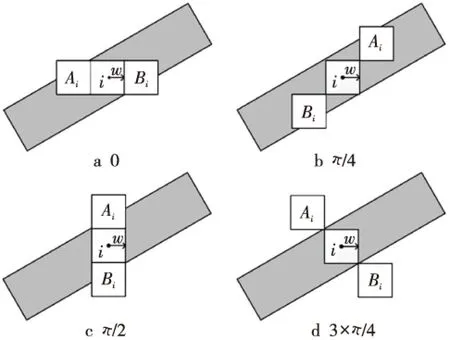
Figure 8 Block contrast calculation 图8 计算块间对比度
(5)
(6)
块对比度二值化方法利用笔画宽度信息,可以有效抑制圆圈、褶皱以及污损对图像二值化造成的影响,其结果如图7f所示。
为了得到更好的字符分割结果,我们将基于占空比和块间对比度的二值化方法进行了融合,当前像素点只有同时被两个二值化方法认为是字符笔画时,它才被赋值为1,否则为0,融合结果见图7g。
3.4后处理
通过后处理操作可以进一步优化二值化结果。首先,由于冠字码字符的大小较大,二值化结果中面积小于三个像素的连通区域被认为是背景区域。其次,我们将得到的二值化冠字码图像做水平和垂直方向投影,投影结果外的图像区域为背景。最后,我们利用八方向运算模板[7](如图9所示)去除分割结果中字符笔画的单像素毛刺。后处理结果见图7h。

Figure 9 Logic operators 图9 八方向运算模板
3.5冠字码字符提取
从二值图像中提取单个冠字码字符分为水平方向和垂直方向定位两个步骤。水平方向定位确定每个字符的左右边缘,垂直方向定位则寻找字符的上下边缘。
由于每张人民币图像中冠字码字符宽度和水平间隔都基本相同,我们首先利用冠字码字符分布的先验知识给出水平方向的粗定位结果,然后分别计算每个字符的水平质心。根据质心对字符的左右边缘进行偏移调整,同时去掉字符笔画与水平边缘的空隙。重复以上两个操作直到字符边缘位置不再发生变化,就可以得到精确的字符左右边缘。
记录所有患者的年龄、性别等基本信息;查明高血压史、糖尿病史、吸烟史、是否伴有血脂异常等相关高危因素信息、以及用于防治冠心病的基本药物情况(如ACEI/ARB类、CCB类、他汀类药物等)。
由于在图像分割结果中,字符笔画的上下边缘可能粘连被误判为前景的圆圈和背景纹理,而且冠字码字符的高度不一致,垂直方向的字符定位比水平方向复杂很多。本文使用一种基于局部灰度对比度[6]的边缘定位方法。首先,我们假设每个字符的高度为冠字码字符串水平方向的投影高度,从而得到字符的候选垂直边缘。然后根据每个字符垂直方向的质心分别对上下边缘的位置y进行调整。针对每条边缘(上边缘或下边缘),我们计算其上下ω个像素范围内的局部灰度对比度,最大局部对比度的位置即对应字符最优的垂直边缘。字符的上下边缘分别用Vt和Vb表示,Ct和Cb分别为上下边缘的局部灰度对比度,最优边缘的搜索范围W=[y-ω,y+ω],Avgt和Avgb为候选边缘垂直方向宽度为字符宽度、高度为H的邻域灰度均值。ε是大于0的常数,确保公式(8)和公式(10)的分母不为0。本文中,搜索范围ω为5个像素,H取值10。
(7)
(8)
(9)
(10)
上述局部灰度对比度垂直边缘定位方法既利用了字符垂直边缘邻域的灰度值对比度,又体现了边缘的强弱,在保证字符笔画提取完整的基础上可以有效去除残缺的背景和圆圈对字符边缘定位的影响,单个字符精定位结果如图7i所示。
4实验及讨论
4.1冠字码区域二值化结果
我们对上文中提出的三种二值化方法和传统的Otsu二值化方法[8]进行了测试和分析。性能评价标准采用国际文档图像二值化竞赛DIBCO 2011[9]中的召回率、精度、F准则F-Measure、峰值信噪比PSNR(Peak Signal to Noise Ratio)、距离倒数失真度量DRD(Distance Reciprocal Distortion Metric)和误判惩罚度量MPM(Misclassification Penalty Metric)。实验结果见表1。
从实验结果可以看出,针对含有复杂背景的人民币冠字码图像,基于占空比和块间对比度的二值化方法比基于笔画宽度的方法性能更好,这两种方法融合的结果经过后处理操作,召回率可以达到82.55%,精度达到92.74%。基于块间对比度的二值化方法利用图像块的均值判断当前像素点是否属于字符笔画,比需要逐像素对比灰度值的使用笔画宽度的分割方法更为鲁棒,可以抗一定的噪声干扰,结果也更加准确。上文中三种针对字符区域的二值化方法性能都明显优于传统的Otsu方法。

Table 1 Binarization results
4.2冠字码字符提取结果
为了测试识别预处理算法提取单个字符的性能,我们标定了500张扫描的人民币图像,包含5 000个冠字码字符。这些人民币图像含有大量的背景纹理和圆圈,同时受到采集光照变化和污损的影响。
本文参用三个标准来评价字符提取的准确度,分别为传统的重叠度量BOM(Basic Overlap based Metric)、基于阈值的重叠度量TOM(Thresholded Overlap based Metric)[10]和ICDAR重叠度量ICDARmetric[11]。这里TOM方法的阈值T设置为0.75,即当单个字符召回率(精度)为75%时,则认为找到该字符。其中,图像的二值化采用了基于占空比和块间对比度相结合的方法。我们分别计算每张图像的BOM、TOM和ICDARmetric,最终的提取结果为所有图像提取单个字符准确度的平均值。如表2所示,依赖于精确的图像分割和鲁棒的字符边缘定位,我们获得了很高的提取精度。在实验中,我们发现二值化结果对字符提取的影响非常大,特别是当字符周围残留的背景纹理较多时,则很难定位字符的边缘。

Table 2 Character extraction results
5结束语
本文针对复杂条件下的人民币冠字码识别,提出了一套完整的预处理方案,其中包括纸币图像采集、边缘检测、倾斜校正、扫描朝向判断、冠字码区域定位和二值化以及字符提取等操作,并对三种不同类型的文字区域二值化方法进行了比较和分析。实验结果表明,对含有复杂背景纹理、光照变化和污损的人民币图像,我们的识别预处理方法可以准确高效地提取冠字码单个字符,为后续的识别做准备。在今后的研究中,我们将尝试跳过单个字符提取,直接利用字符串识别技术识别冠字码字符串。
参考文献:
[1]Duan Jing-hong, Luan Dan. Research on an automatic number recognition method for RMB banknotes[J]. Computer Engineering & Science, 2008, 30(1):66-68. (in Chinese)
[2]Yuan Wei-qi, Zhang Yu. A fast recognition system for paper currency numbers [J]. Computer Engineering, 2005, 31(24):153-155. (in Chinese)
[3]Ye Xiang-yun, Cheriet M, Suen C Y.Stroke-model-based character extraction from gray-level document images [J]. IEEE Transactions on Image Processing, 2001, 10(8):1152-1161.
[4]Hontani H, Koga T. Character extraction method without prior knowledge on size and position information [C]//Proc of International Vehicle Electronics Conference, 2001:67-72.
[5]Kamel M, Zhao A. Extraction of binary character/graphics images from grayscale document images [J]. Graphical Models and Image Processing, 1993, 55(3):203-217.
[6]Feng Bo-yuan, Ren Ming-wu, Zhang Xu-yao, et al. Extraction of serial numbers on bank notes [C]//Proc of International Conference on Document Analysis and Recognition, 2013:698-702.
[7]Lu Shi-jian, Su Bo-lan, Tan C L. Document image binarization using background estimation and stroke edges [J]. In-
ternational Journal of Document Analysis and Recognition, 2010, 13(4):303-314.
[8]Otsu N. A threshold selection method from gray-level histograms [J]. IEEE Transactions on Systems, Man and Cybernetics, 1979, 9(1):62-66.
[9]Pratikakis I, Gatos B, Ntirogiannis K. ICDAR 2011 document image binarization contest (DIBCO 2011) [C]//Proc of International Conference on Document Analysis and Recognition, 2011:1506-1510.
[10]Mariano V Y, Min J, Park J H, et al. Performance evaluation of object detection algorithms [C]//Proc of International Conference on Pattern Recognition, 2002:965-969.
[11]Pan Yi-feng,Liu Cheng-lin.Performance evaluation for text localization algorithms:An empirical study [C]//Proc of Chinese Conference on Pattern Recognition, 2010:1-5.
参考文献:附中文
[1]段敬红, 栾丹. 人民币号码自动识别方法研究[J]. 计算机工程与科学, 2008, 30(1):66-68.
[2]苑玮琦, 张昱. 纸币号码快速识别系统[J]. 计算机工程, 2005, 31(24):153-155.

冯博远(1986-),男,山西太原人,博士生,CCF会员(E200039416G),研究方向为字符识别、图像处理和机器学习。E-mail:fengboyuannj@gmail.com
FENG Bo-yuan,born in 1986,PhD candidate,CCF member(E200039416G),his research interests include character recognition, image processing, and machine learning.
