一种面向重尾分布的SSD磁盘调度算法
2016-01-08魏元豪,吴小华,吴庆波等
一种面向重尾分布的SSD磁盘调度算法*
魏元豪1,吴小华2,吴庆波1,邵立松1
(1.国防科学技术大学计算机学院,湖南 长沙 410073;2.二炮装备研究院四所,北京 100085)
摘要:存储设备上的大量文件其长度呈重尾态分布,IO请求的响应延迟和请求大小有着密切关系,并且固态硬盘的IO操作不对称。基于以上几点,在内核NOOP调度算法的基础上提出一种针对重尾数据分布下的IO调度算法。该算法通过减少大量小片请求的等待时间,提高固态硬盘的性能。经实验验证,相比内核的NOOP调度算法,平均响应时间减少17%。
关键词:IO调度;固态硬盘;重尾分布
中图分类号:TP333 文献标志码:A
doi:10.3969/j.issn.1007-130X.2015.06.002
收稿日期:*2014-03-28;修回日期:2014-05-14
作者简介:
通信地址:410073 湖南省长沙市国防科学技术大学计算机学院
Address:College of Computer,National University of Defense Technology,Changsha 410073,Hunan,P.R.China
An I/O scheduling algorithm of SSD based on heavy-tailed distributions
WEI Yuan-hao1,WU Xiao-hua2,WU Qing-bo1,SHAO Li-song1
(1.College of Computer,National University of Defense Technology,Changsha 410073;
2.The Fourth Research Institute of the Second Artillery Equipment Academy,Beijing 100085,China)
Abstract:The size of the files stored in the network server has heavy-tailed feature. Access latency is dependent on the size of the accessed files, and the IO operations of Solid State Disk (SSD) are asymmetric. Therefore, based on the kernel NOOP scheduling algorithm, we propose an I/O scheduling algorithm of SSD based on the heavy-tailed distributions to improve the performance of SSD access by reducing the waiting time for lots of small files. Experimental results show that the proposed algorithm can reduce response time by 17% on average compared with the kernel NOOP scheduling algorithm.
Key words:IO scheduler;SSD;heavy-tailed distributions
1引言
网络和存储设备上存在的大量数据呈现出重尾分布规律[1],决定了IO请求中必然大量存在小片数据的请求,偶发大块数据请求[2]。固态硬盘SSD(Solid State Disk)存在读写不对称和写惩罚缺陷[3]。内核中的Deadline和CFQ(Completely Fair Queuing)调度算法过于繁杂,不适用于固态硬盘[4]。NOOP(NO OPeration)调度算法不考虑扇区位置,直接派发请求,适用于随机IO设备,但没有针对数据的重尾特性加入相应优化机制。文献[5]中设计的FIOS(Force Control I/O Server)调度算法,同时兼顾了调度的公平性和SSD的性能。但是,作者更多地是从SSD角度出发设计调度算法,没有针对特定的应用场景对调度算法加以优化。文献[6]中设计的整个IO系统仍然是从SSD的内部结构出发的。
本文在分析了应用层以及通用块层请求块大小统计规律的基础上,面向数据的重尾分布特性,以NOOP算法为基础设计并实现适用于固态硬盘的HTIOS(Heavy-Tailed distributions IO Scheduler)调度算法。该算法将优先响应读请求和小片写请求,对大块写请求依据大小排序处理,减少存储系统的平均IO响应时间。第2节概述HTIOS算法的设计基础,第3节算法实现,第4节给出了实验验证。
2算法设计依据
2.1数据的重尾分布规律
重尾分布被证明是复杂系统中普遍存在的、本质的而且不可消除的特性[7]。文献[8]证明了UNIX文件系统中的文件长度具有重尾分布特性。文献[9]以香农信息理论为基础证明了网络文件长度呈重尾态分布。大量文献已经证明,在网络空间存在的海量数据是呈重尾态分布的。而重尾态分布具有以下分布规律:(1)样本空间中大量的小抽样观察值和少量的大抽样观察值并存;(2)大抽样值决定抽样的均值和方差;(3)重尾分布表现出强烈的局部突发性[1]。
网络空间的数据分布规律缩放到单个的Web服务器数据仍然是成立的[8]。由于应用的特殊性,Web服务器存在大量的HTML文件、图片和少量的动画,这样客观形成一个重尾场景。我们研究国内主要媒体及电商的Web服务器均可以得到类似的分布规律。例如天猫网的Web服务器数据分布图1所示。
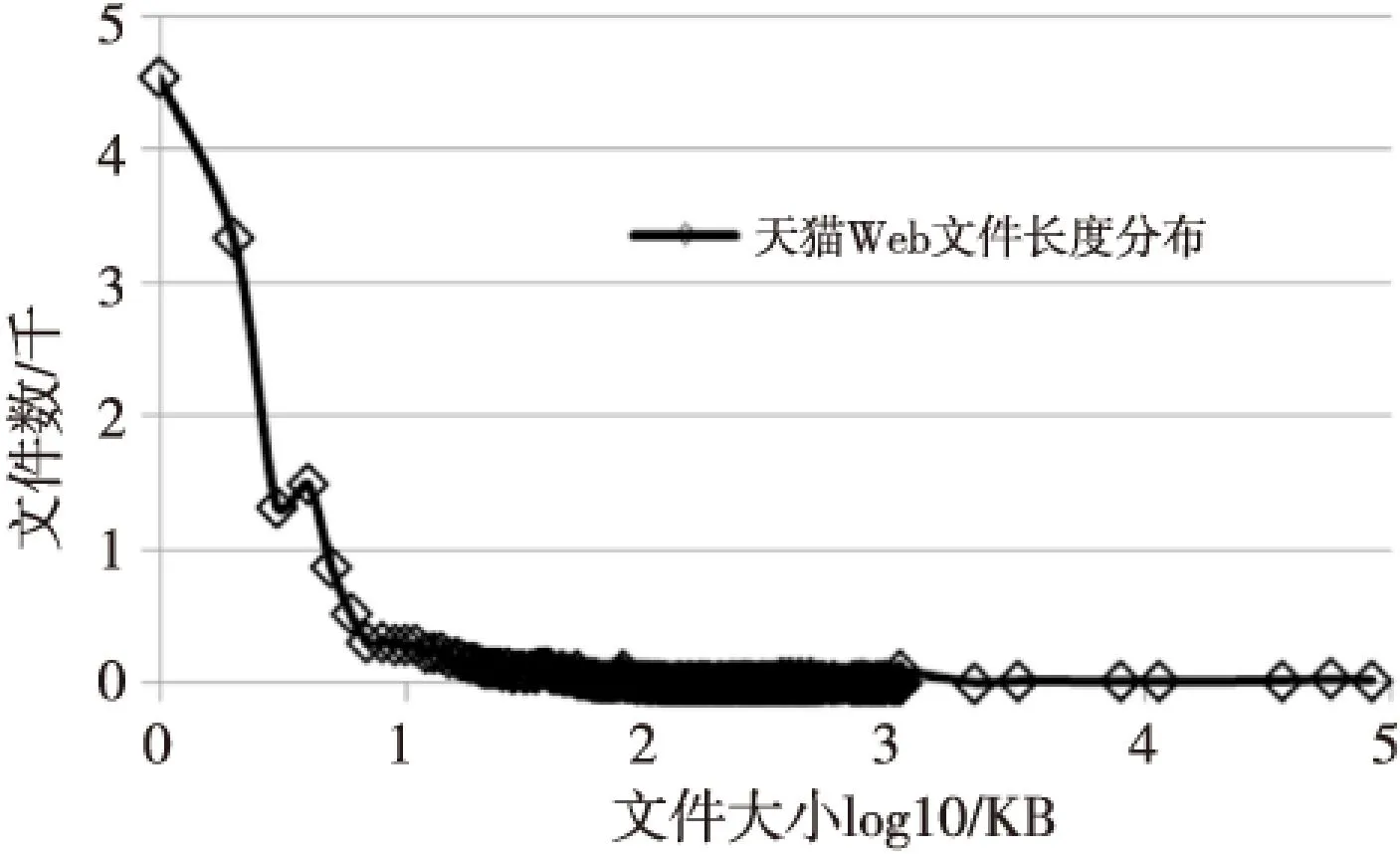
Figure 1 Length distribution of Tmall Web files 图1 天猫网Web服务器文件长度分布
这就表明这种重尾数据应用场景确实存在,而针对这种应用场景优化系统软件也是有必要的。
2.2操作系统IO层次
Linux操作系统的IO层次可以概括为如图2所示的结构。文件系统层在文件级别实现对数据的管理,而文件又被组织为不同粒度的逻辑块。如ext4文件系统的逻辑块大小为4 KB。IO请求经过文件系统层被均匀切分为4 KB粒度的块请求。由于小文件通常在 KB级别,大量小文件在10 KB以下。所以,对小文件的IO请求在通用块层被合并的概率很小。而大文件通常在MB级别,大的视频文件可以在GB级别。所以,对大文件的IO请求在通用块层很容易被相邻合并成大块的数据请求。
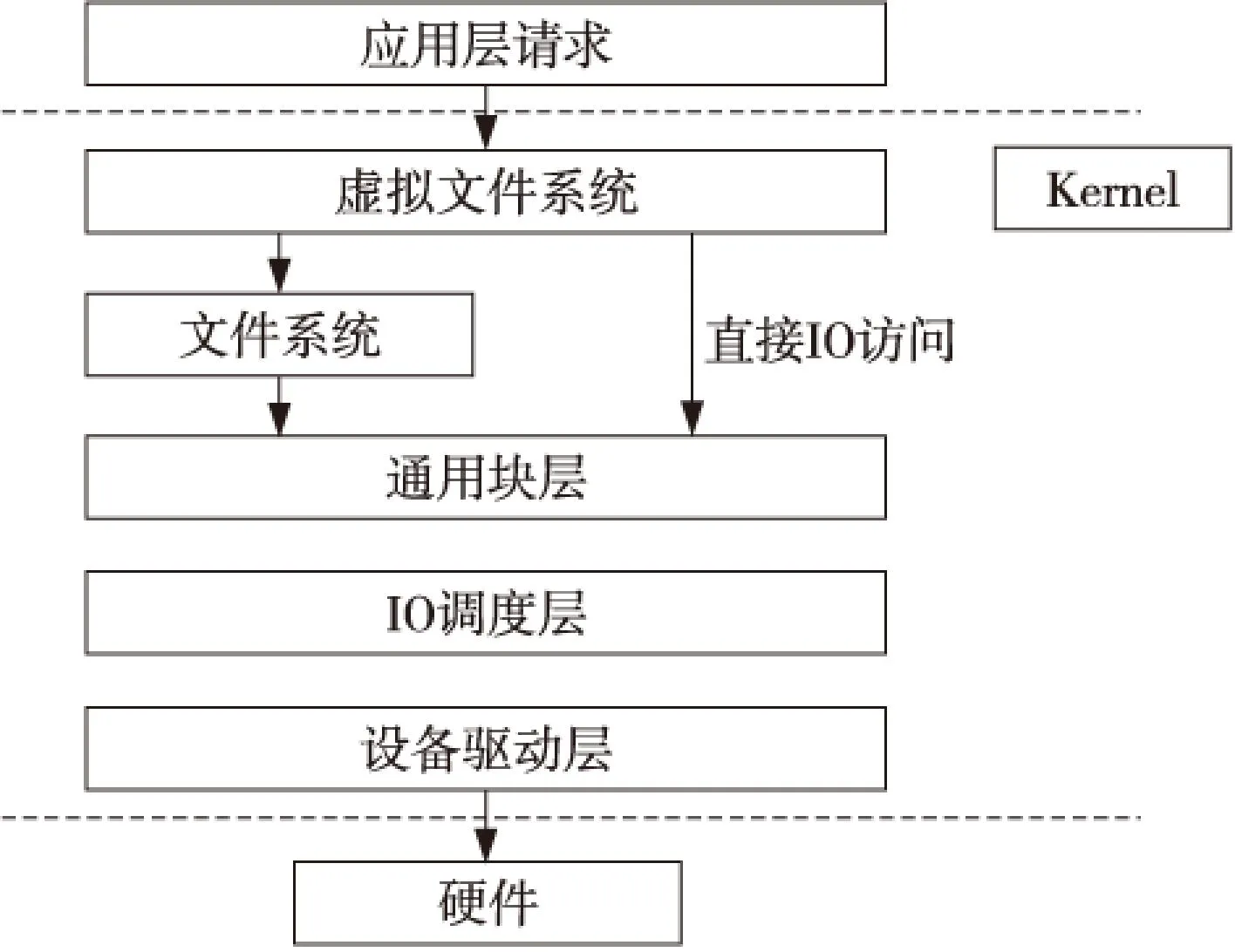
Figure 2 Linux system’s IO hiberarchy 图2 Linux系统IO层次
我们将从电商网站下载获得的数据作为样本空间,将样本空间置于SSD上并做随机IO。测试用固态硬盘为Kingston SVP200S37A/120 GB。得到的通用块层的(块请求)request大小分布图如图3所示。
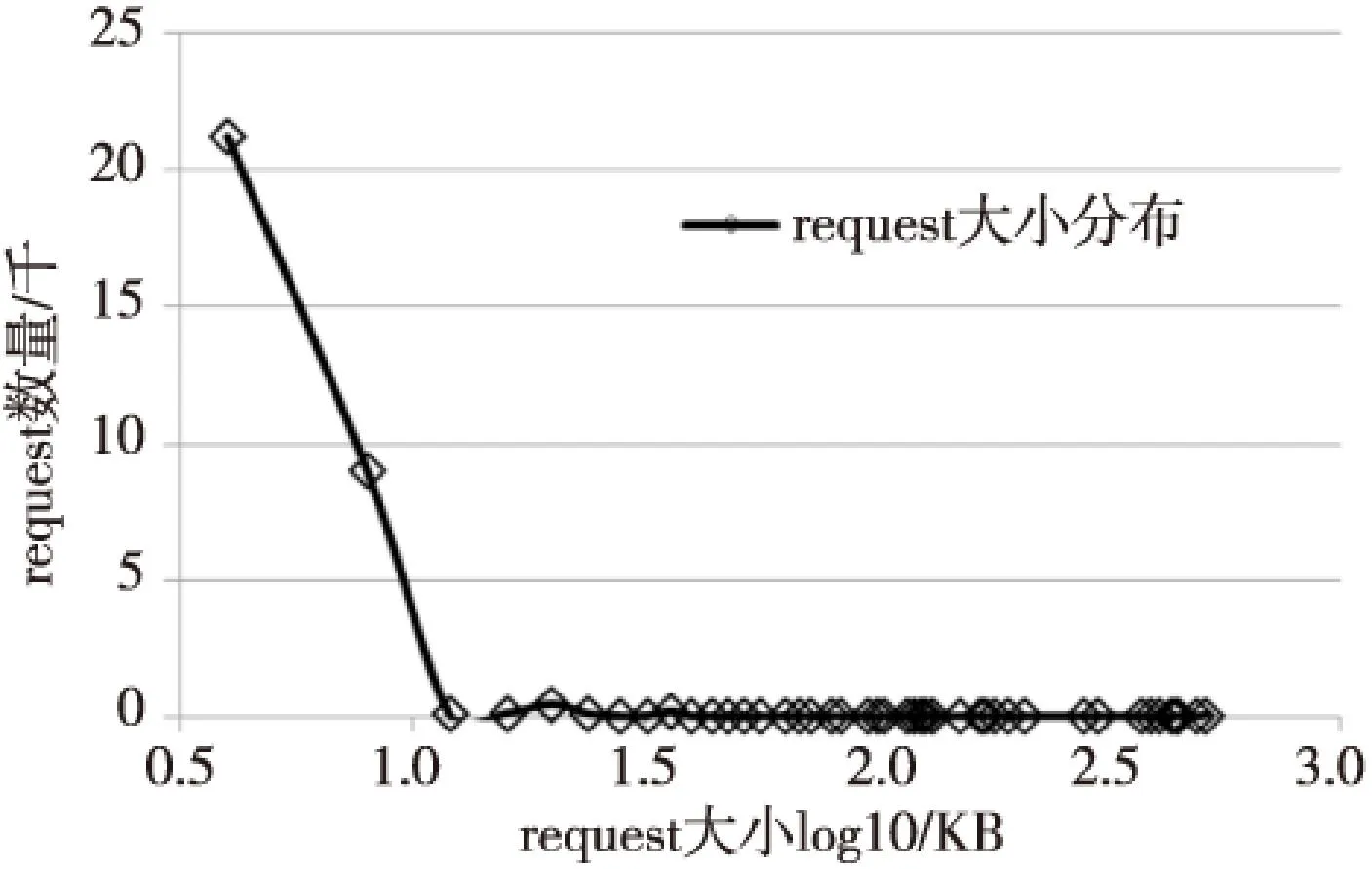
Figure 3 Size of generic block layer request distribution 图3 通用块层request大小分布
由此实验知,经过文件系统对应用层IO请求的4 KB粒度均匀化,以及通用块层的相邻合并后,request大小依然表现出应用层的数据重尾分布特性。因此,在IO调度层对IO请求做出优化是合理的。
2.3request块大小与响应时间关系
在上述实验环境下,对样本空间做随机读写。并对request延迟进行统计,放大10倍后的结果如图4所示。
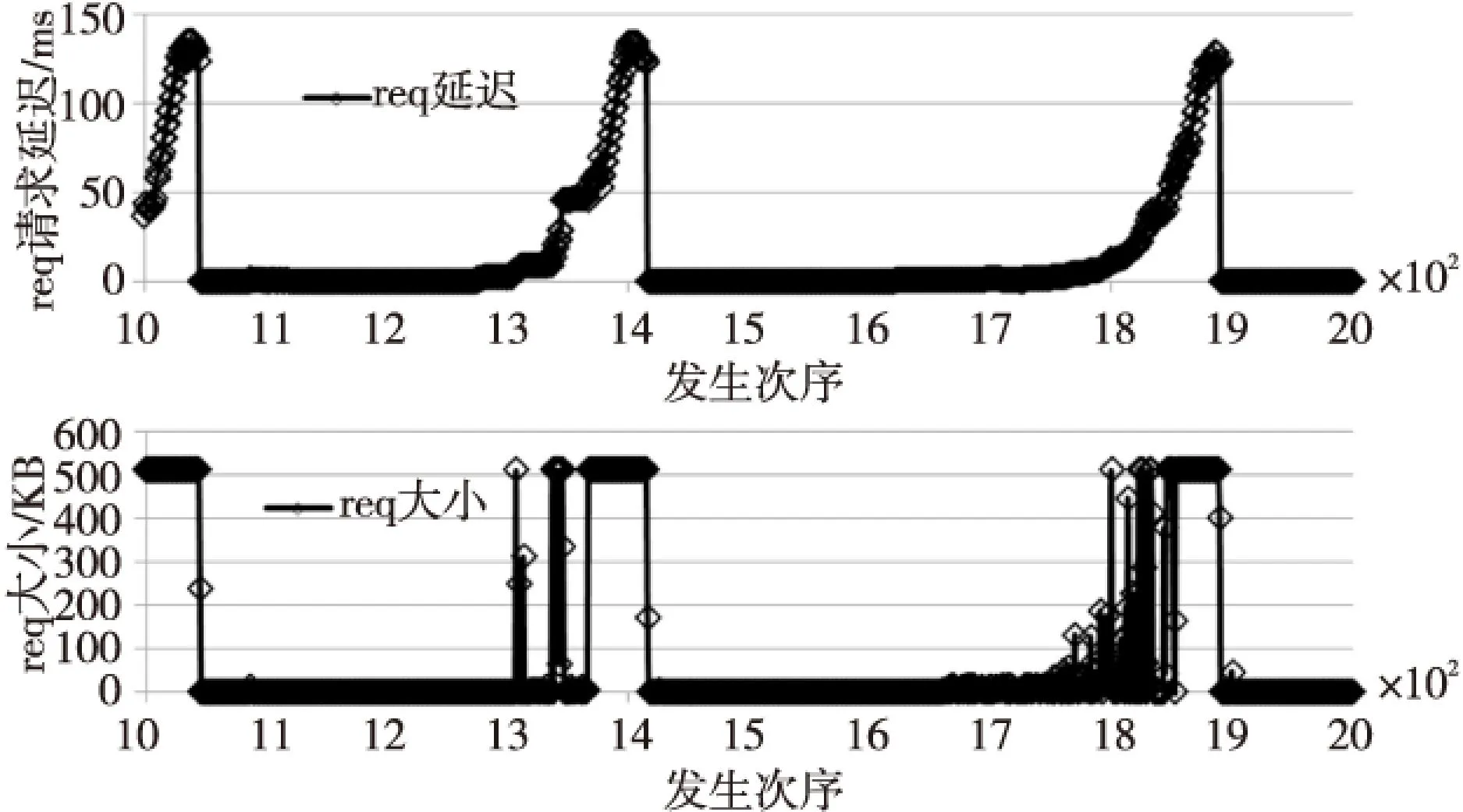
Figure 4 Relationship between request delay and size 图4 request延迟及大小分布关系
图4测试结果表明,请求大小和请求延迟有着非常紧密的统计关系。绝大多数的小片数据请求响应延迟很短。对图4再做5倍放大,结果如图5所示。图5中1 320~1 360中间有大量的小片request请求被大块request阻塞延迟,并与随后的大块request请求造成更大的拥塞波峰。进一步针对SSD的读实验结果如图6所示。结果显示,读请求延迟的变化不大。
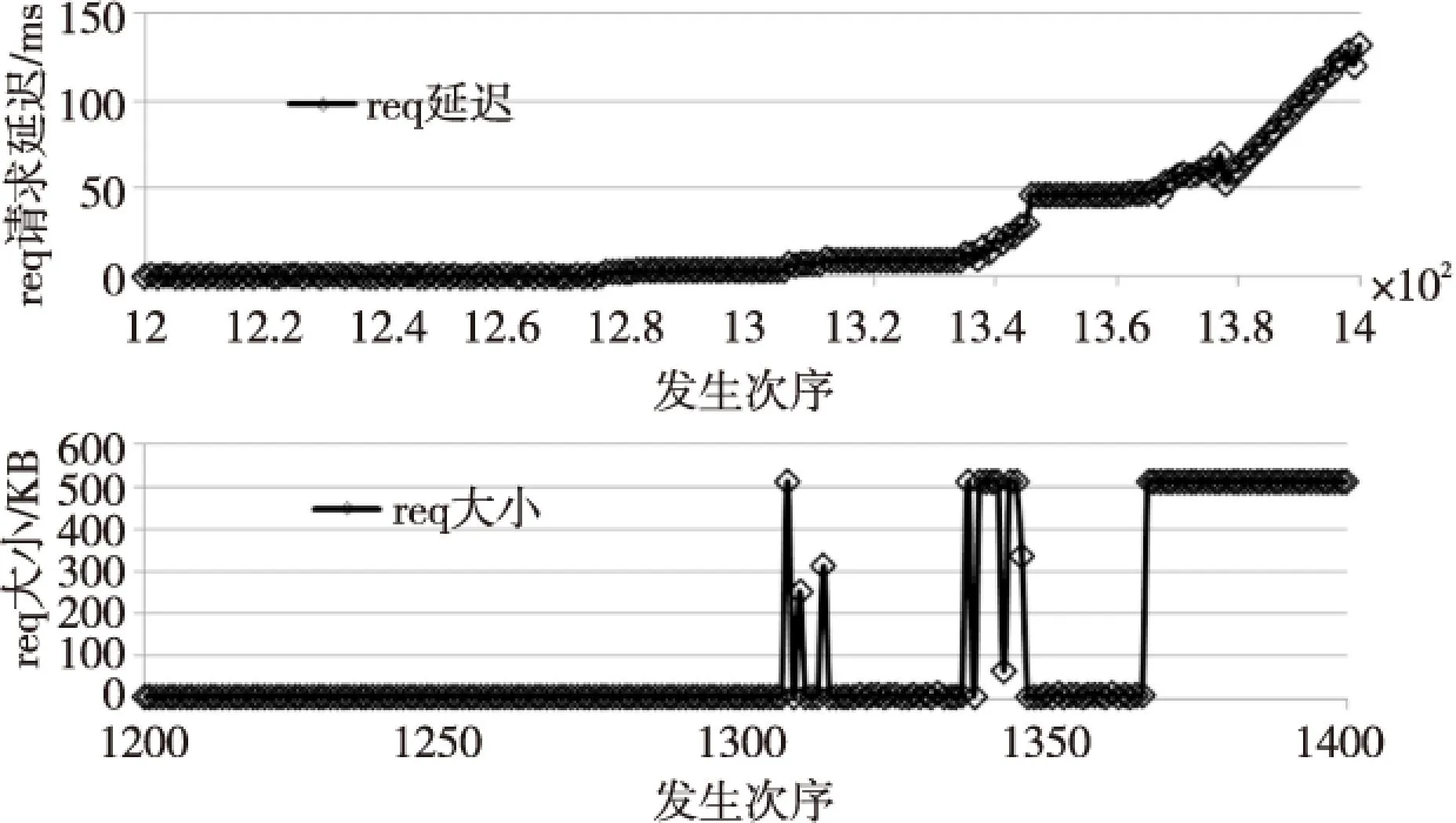
Figure 5 5 times enlarged Figure 4 图5 5倍放大图4

Figure 6 Delay of read request 图6 读请求延迟
以上实验表明,重尾数据下突发性的大块数据写请求会造成SSD响应延迟陡然增大,极易出现局部性能崩塌。因此,调度算法中应该针对这一特征进行优化。
3HTIOS调度算法
基于第2节的分析,本文在HTIOS调度算法中针对重尾数据分布下突发性的大块写请求予以优化。
3.1排序优化
不同大小的请求按不同顺序处理,其平均响应延迟差距巨大。图7模拟请求先后顺序不同造成的延迟差异。
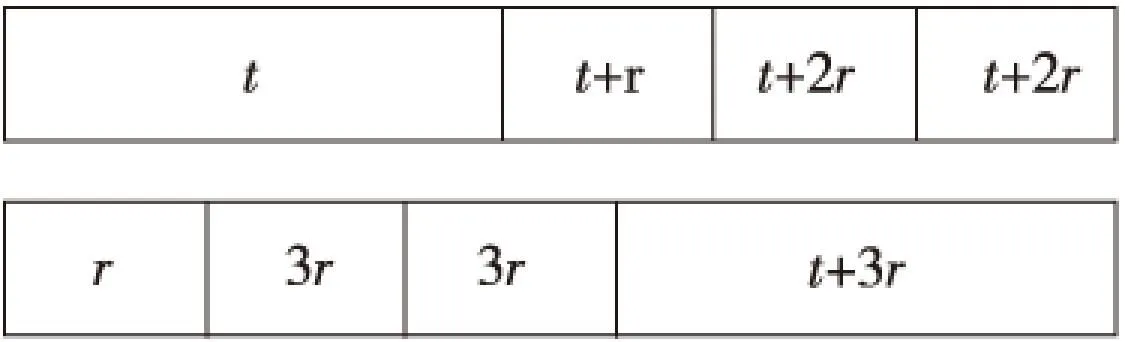
Figure 7 Sort optimization 图7 排序优化效果
令大块数据请求延迟为t,而小片数据请求延迟为r,则不难计算出前者的平均延迟为(4t+6r)/4,而后者为(t+9r)/4。当t远大于r的时候,排序优化效果就会非常明显。
由第2节实验知,读请求和小片写请求延迟都很小,HTIOS算法中将这两类请求优先派发。重尾数据分布下的突发性大块数据请求,其响应延迟陡然增加。所以,针对大块的写请求在HTIOS中依据大小排序,并依序派发。
为避免大块写请求过度饥饿,本文借鉴Deadline算法,加入饥饿阈值。当大块写请求被饥饿次数到达阈值时,泄流大块写请求。基于请求大小的排序队列优先处理小请求,而如果不断有小请求加入,大块请求会长时间得不到响应,甚至饿死。本文借鉴Deadline算法引入超时时间,为写请求加入时间戳。HTIOS调度算法检测并派发超时请求,保证不会有请求被饿死。
3.2算法实现
HTIOS调度算法流程如图8所示。如果有超时请求,调度器直接将超时请求派发出去;没有超时请求时,优先派发读请求或小片写请求。只有当大块写请求饥饿或者没有高优先级请求时,调度器才派发大块写请求。
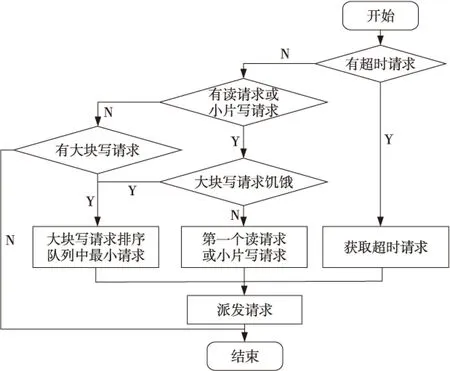
Figure 8 Flowchart of HTIOS 图8 HTIOS算法流程图
4性能测评
测试环境为:Linux 2.6.32内核,Sparc处理器,4 GB内存,固态硬盘为Kingston SVP200S37A/ 120 GB。实验中的负载为每个进程400次的随机IO操作,实验设计并发量分别为20、40、60。
内核中四种调度器,只有NOOP调度器是为随机存储设备设计的。NOOP与其他三种调度器的平均延迟对比如图9所示,可见NOOP存在一定优势。
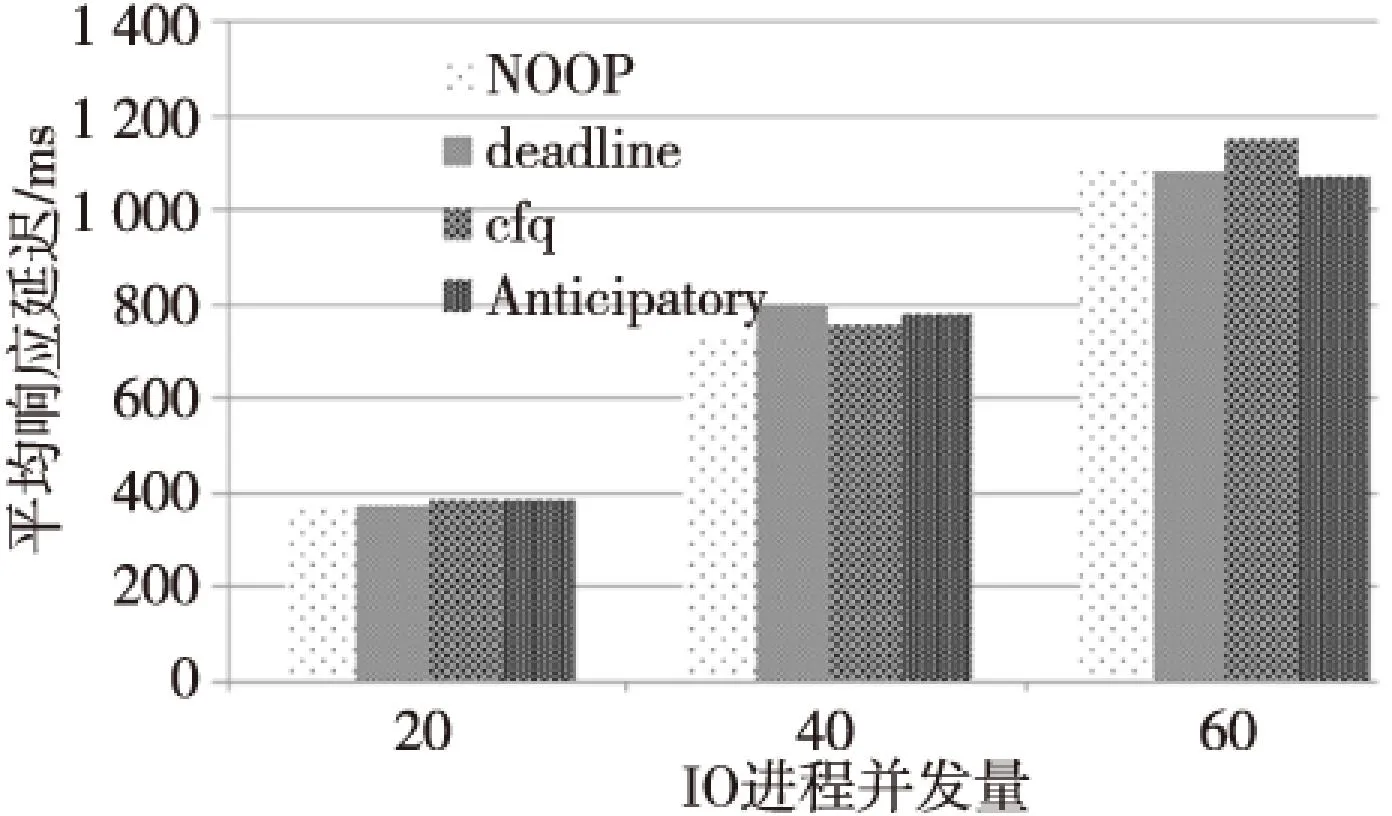
Figure 9 Performance comparison of kernel IO algorithm 图9 内核IO调度算法性能对比
如图10所示为HTIOS调度算法相比NOOP的优化效果。
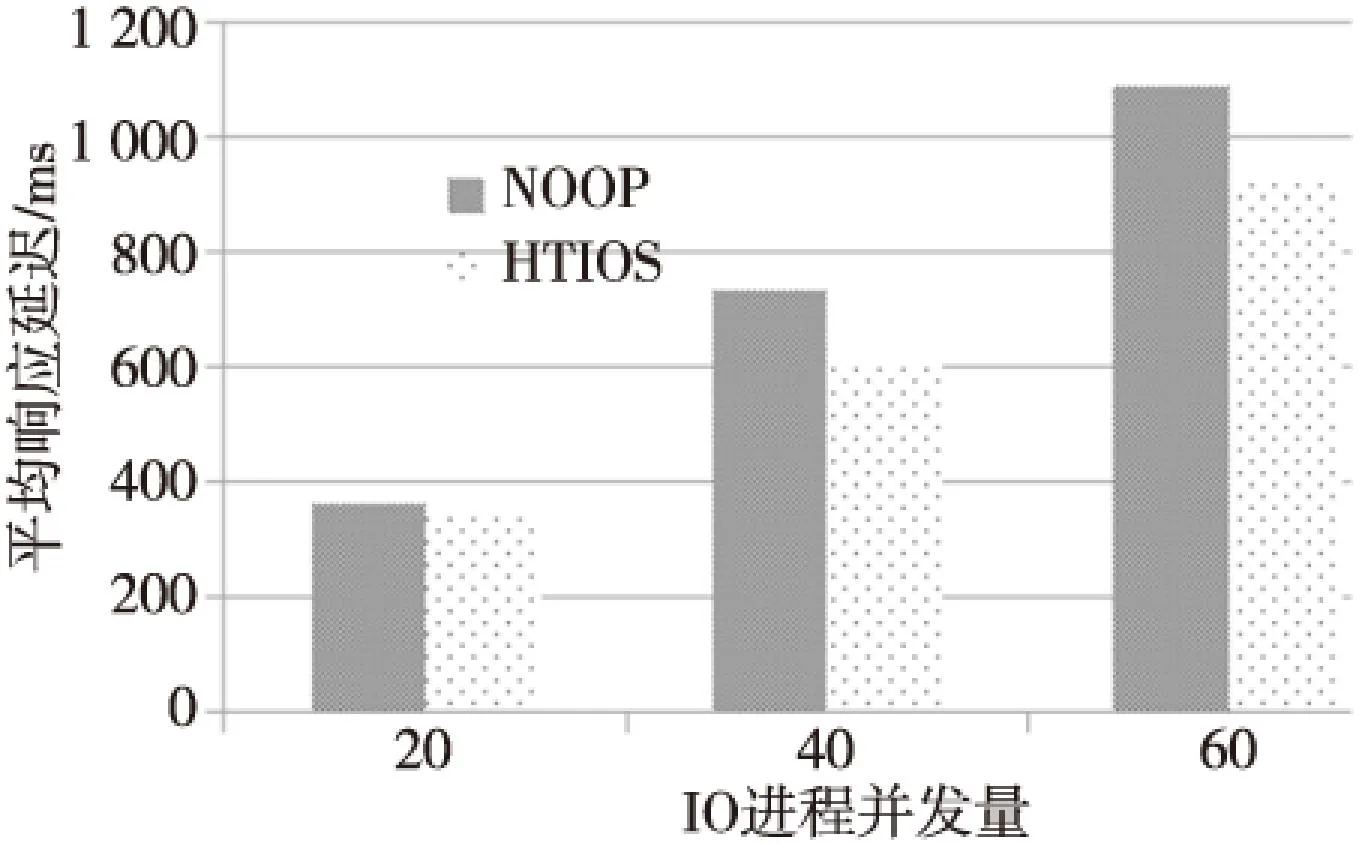
Figure 10 Performance comparison between HTIOS and NOOP 图10 HTIOS与NOOP性能对比
三种并发量下HTIOS调度算法比NOOP算法的优化比分别为9%、17%和15%。在低并发量时,调度队列相对较空闲,所以大块请求对小片请求的迟滞作用较小。在较高并发环境下调度队列相对繁忙,故而大块数据请求极易阻塞后续小片数据请求。所以,并发量为20时的优化比,较之并发量为40时的优化比略小。过度拥挤的调度队列,空间被大多数小请求占据,大块请求无论何时发生都会拥塞后面小请求。故而优化效果随着并发量的逐渐增加呈减小趋势。实验结果中,并发量增加到60后优化比有所下降。
5结束语
固态硬盘提高了存储系统的性能,打破了机械硬盘的物理屏障。重尾态数据的突发性大块写请求,极易造成其后的小片数据请求被长时间迟滞。本文针对数据的重尾分布特性,设计并实现了HTIOS
调度算法。不同并发量的负载测试表明,HTIOS调度算法可以有效地减小固态硬盘在重尾态数据下的平均响应时间,因此,有效地改善了重尾数据下固态硬盘存储系统的IO性能。
参考文献:
[1]Crovella M E,Taqqu M S,Bestavros A. Heavy-tailed probability distributions in the World Wide Web[M]//A Practical Guide to Heavy Tails:Statistical Technique and Applications,1998:3-25.
[2]Crovella M E. Self-similarity in World Wide Web traffic:Evidence and possible causes[C]//Proc of IEEE/ACM Transactions on Networking,1997:835-846.
[3]Kang J U,Kim J S,Park C,et al. A multi-channel architecture for high-performance NAND flash-based storage system[J]. Journal of Systems Architecture,2007,53:644-658.
[4]Love R. Linux kernel development [M]. Beijing:China Machine Press,2013.
[5]Park S,Shen Kai. FIOS:A fair,efficient flash I/O scheduler[C]//Proc of the 10th VSENIX Conference on File and Starage Technologies,2012:1-15.
[6]Kang S,Park H,Yoo C. Performance enhancement of I/O scheduler for solid state devices[C]//Proc of IEEE International Conference on Consumer Electronics,2011:31-32.
[7]Shao Li-song.Research on Internet end-to-end congestion control algorithms[D].Changsha:National University of Defense Technilogy,2006.(in Chinese)
[8]Kihong P,Kim G,Crovella M. On the relationship between file sizes,transport protocols,and self-similar network traffic[C]//Proc of the 1996 International Conference on Network Protocols,1996:171-180.
[9]Fabrikant A,Koutsoupias E,Papadimitriou C H.Heuristically optimized trade-offs:A new paradigm for power-laws in the Internet[C]//Proc of Internet Colloqium on Automata,Languages,and Programming(ICALP),2002:110-122.
[10]Park S,Kim Y,Urgaonkar B,et al. A comprehensive study of energy efficiency and performance of flash-based SSD [J]. Journal of Systems Architecture,2011,57:354-365.
参考文献:附中文
[7]邵立松. 互联网端到端拥塞控制算法研究[D].长沙:国防科学技术大学,2006.

魏元豪(1986-),男,河南鹤壁人,硕士生,研究方向为固态硬盘性能优化。E-mail:weiyuanhao@126.com
WEI Yuan-hao,born in 1986,MS candidate,his research interest includes performance optimization of solid state drive.
