一种基于人工免疫的本体匹配算法
2016-01-08董济德,谢强,丁秋林
一种基于人工免疫的本体匹配算法*
董济德,谢强,丁秋林
(南京航空航天大学计算机科学与技术学院,江苏 南京 210016)
摘要:针对目前本体匹配算法存在运行效率低和匹配准确度不高等问题,提出一种基于人工免疫的动态本体匹配算法,用来快速地从现有本体中筛选出用户所需的子本体。该算法根据用户行为信息构建抗原本体模型,利用情景匹配确定其领域上下文环境,然后通过结构匹配获得匹配度最高的本体,最后对本体执行语义匹配得到最终需要的子本体。实验表明,该算法提高了本体匹配的准确度和效率。
关键词:本体匹配;抗原本体;情景匹配;结构匹配;语义匹配
通信地址:210016 江苏省南京市秦淮区御道街29号南京航空航天大学计算机科学与技术学院
Address:College of Computer Science and Technology,Nanjing University of Aeronautics and Astronautics,29 Yudao Rd,Qinhuai District,Nanjing 210016,Jiangsu,P.R.China
An ontology matching algorithm based on artificial immunity
DONG Ji-de,XIE Qiang,DING Qiu-lin
(College of Computer Science and Technology,Nanjing University of Aeronautics and Astronautics,Nanjing 210016,China)
Abstract:Because of the low efficiency and low accuracy existing in the traditional ontology matching algorithms, we introduce an automatic ontology matching algorithm based on artificial immunity to rapidly get the required sub-ontology from the existing ontology pool. The algorithm constructs an antigen ontology model according to the information of users’ behaviors, determines its domain context by matching the context, obtains the ontology with the highest matching degree via structure matching, and finally gets the right ontology through semantic matching. The experimental results show that the algorithm can improve the precision and the efficiency of ontology matching.
Key words:ontology matching;antigen ontology;context matching;structure matching;semantic matching
1引言
本体作为一种语义和知识层面上的概念共享模型[1],可作为用户和计算机以及计算机与计算机之间的知识载体,从而实现语义网中知识的统一化表示。从知识工程领域上解释,本体是一种表述语义知识的方法[2],并包含了对术语以及关键词语的语义解释。本体定义了一个统一化表述语义的数据视图,并且可以用来对同一框架内的异构数据源进行建模。另外,本体可为不同数据源模型之间提供相互沟通交流的能力,并对模型内蕴含的信息进行集成。
虽然本体在语义和知识层次上得到了广泛的应用,但基于本体的知识表示方法在一定程度上并没有充分解决本体的互操作以及相互通信的问题。相同或者相似领域间的本体亟需一种方法建立联系,因此,本体匹配被人们提出,用来解决本体之间的协调与通信问题。本体匹配作为一种打破本体与本体之间的独立性的方法,是一种用来查找本体之间或本体内部元素之间相似程度的关键技术,能够解决不同领域内或者相同领域内本体异构的问题,被一致认为是解决人机交互、机机交互时语义异构问题的有效方法。而且,本体匹配对于本体映射与集成、本体的检索以及本体重用、本体知识集成、语义Web服务的匹配,以及基于本体的软件需求工程等是不可缺少的重要环节[3]。
本体匹配目前是一个活跃的研究领域,研究人员对此提出了众多解决方案。在生物医学和生物信息学的知识领域,本体匹配发展得益于对词汇和本体的主动研究和应用。统一医学语言系统UMLS(Unified Medical Language System)正是一个由国家医学图书馆事业创建的规模浩大的医学和生物术语单一存储库[2]。目前,对本体匹配的研究主要围绕语义或者结构方法展开。黄涛等人[1]提出的基于虚拟路径的本体匹配算法OMA-VP(Ontology Matching Approach based on Virtual Path)对本体结构匹配进行改进,提出了虚拟路径的概念,一定程度上提高了本体匹配的准确度。但是,该算法仅是对本体匹配局部性的改进,并没有在全局上降低本体匹配效率,而且匹配准确度不确定。OLA(OWL-Lite Alignment)[2]采用加权平均值沿多个本体特征之间的匹配,并引入了一种基于数值分析的实体集的相似性计算机制,使得本体匹配准确度有所提高,但算法的匹配效率较低。ASMOV算法[2]对OLA进行了一系列的改进,以图形化本体的表示方法描述本体之间的关联,根据术语关键词、结构以及实体三个层次分别计算出术语相似性、结构相似性和实体相似性的大小;然后对计算结果进行参数校准,从而得到最终本体匹配值。但是,该算法没有考虑用户的上下文语境,因此本体匹配的准确度并不理想。Falcon-AO(Finding,aligning and learning ontologies,ultimately for capturing knowledge via ontology-driven approaches)是由东南大学瞿裕忠教授和胡伟博士等人[1]开发的本体对齐工具,它利用一个语言匹配器并结合了一种以二部图结构表示的待匹配本体结构的方法,通过计算概念之间语义相似系数进行了相似性分析,但大量的冗余计算降低了算法的执行效率。H-Match是由意大利米兰大学Castano S等人提出的面向分布式的本体的动态匹配方法,通过输入两个待比较本体得到两个本体中具有语义相似性的元素对[1],来确定两个本体之间的相似度。但是,该算法没有充分解决因本体异构而引发的匹配问题,同时该算法也没有解决本体情景不匹配的情况下出现的匹配问题。盖克[3]提出了一种基于概念上下文的本体匹配算法CBOMA(Context-Based Ontology-Matching Algorithm),通过构建概念结构层次树来实现对本体自上而下的匹配,提高了本体匹配的准确度,但无法解决不同领域内本体匹配相似度高的问题。王晓云等人[4]将改进的蚁群算法应用到本体匹配算法中,通过构建距离矩阵、能量损耗矩阵和信息素矩阵来对本体匹配算法流程的进行优化,其匹配精确度虽然得到提高,但大量的冗余计算降低了算法执行效率。针对目前本体匹配算法中存在的问题,本文提出了一种基于人工免疫的动态本体匹配算法AOMA-AI(Automated Ontology Matching Algorithm based on AI)。人工免疫算法既能够提供噪声忍耐、无监督学习、自组织以及记忆等学习机理,又结合了神经网络和机器推理等系统的一些优点,因此能够提供解决新问题方法的潜力[5,6]。AOMA-AI算法核心思想是根据用户行为信息构建抗原本体模型,利用情景匹配确定其领域上下文环境,然后通过结构匹配获得匹配度最高的本体,最后对本体执行语义匹配得到最终需要的子本体。AOMA-AI基于人工免疫算法,对待匹配的本体赋予一定的生存期限,在匹配过程时不断更新本体集合,这是其他本体匹配算法中所不具有的。所以,利用人工免疫算法的收敛快、耗时低等优点,AOMA-AI算法在进行本体匹配时可进一步提高本体匹配准确度和效率。
2AOMA-AI算法框架
本体匹配的过程是对抗原本体的系统解读,即将外界的本体通过匹配算法与系统中既定义的流程本体对应。所谓抗原本体,是对用户行为信息进行本体化描述而得到计算机可识别的本体。本体匹配图如图1所示。

Figure1 Ontology matching process 图1 本体匹配过程图
图2给出了AOMA-AI算法的组成框架,其大致可以分为四步:(1)根据用户行为信息构建抗原本体模型;(2)利用情景匹配确定其领域上下文环境;(3)通过结构匹配获得匹配度最高的子本体;(4)对本体执行语义匹配,得到最终的子本体并输出。

Figure 2 Structure of AOMA-AI 图2 AOMA-AI算法框架图
3基于人工免疫的本体匹配算法
3.1本体相关定义
传统本体按照分类法来组织,包含了四个基本的建模语言,即概念类(Concept)、实体类(Instances)、属性(Property)和公理(Axioms)[3,7]。概念采用框架结构,包括概念的名称以及用自然语言对概念的描述[7];实体类是指属于某概念的基本元素,即该概念类对应的具体实体;公理主要是用来描述属性与属性之间的包含关系以及类与类之间的从属关系,同时公理也用来表示取值限制。
定义1本体可以用一个五元组表示:O={C,R,Hc,A,I},其中,C称为本体中的概念集;R代表了领域中概念之间的相互关系,形式上定义为n维的笛卡尔积的子集,其基本关系可表示为part-of、kind-of、instant-of和attribute-of四种;Hc是本体概念的层次关系,其中Hc⊆C×C,Hc(C1,C2)表示C1是C2的子类;A为公理集合,是定义在概念和属性上的限定和规则;I为C概念类对应的实例[7]。
关键词定义2抗原本体,也称为任务本体,是从用户输入信息中获取来实现对信息的标准化、本体化描述而得到的计算机可识别的本体。
定义3记忆本体是这样一类本体,即经过抗原本体的多次刺激后,本体集合中的某一个或某一些本体多次被选中而转化形成的本体。
本体表示是本体匹配过程中的一个重要环节。文献[8]中提供了一种本体结构图OSG(Ontology Structure Graph)的表示方法,该方法能够形式化表示出本体以及本体内实体的从属关系。鉴于本体结构图能够充分表示本体结构,以及本体内实体与实体之间、实体与属性之间的从属关系,本文也采用本体结构图表示本体,并且形式化地表示出本体之间匹配的过程。另外,由于本体在加入情景感知的特性后使本体具有了对象化、情景化的可分辨性的特征[9],本文进行本体匹配时能够根据本体情景减少匹配次数,从而提高效率。
3.2AOMA-AI算法设计
根据用户输入信息,首先利用程序构建出抗原本体O;然后构建出本体内的实体E;最后在本体内插入属性值。上述过程结束后,提取用户输入信息关键词W,然后进入算法本体匹配过程。
AOMA-AI从本体集群中匹配最优本体的计算方法如公式(1)表示:
(1)
其中,Sim函数是本体匹配函数;Si为本体群中第i个本体子群;S′为待匹配本体;δ为设定的阈值;O则为本体子群Si中的某一个本体。
接下来将介绍本体匹配函数的详细过程。
本文本体匹配分为初始匹配、外匹配和内匹配三个过程,分别对应于情景匹配、结构匹配和语义匹配三个部分,详细匹配过程如下:
(1)初始匹配,即为情景匹配。在基于语义Web的知识查找系统中,领域匹配是本体匹配中很重要的一步。在特定领域确定的情况下,对后续的本体进行结构和语义匹配能够提高匹配的查准率和查全率[1],此处的领域匹配是对各领域内关键词的匹配过程。
(2)外匹配,即为结构匹配,对于两个待比较本体,如果其结构上差异程度非常大,那么后续的语义匹配就显得没有意义,所以,对本体的结构匹配非常重要,能够在一定程度上减少迭代次数,降低时间复杂度。
(3)内匹配,即为语义匹配,是这次匹配过程的主要组成部分,该匹配包含了贪婪实体匹配和属性匹配两个过程。
设F={C,H,E}为计算相似度值的操作集,分别对应于上述的三种匹配过程,C为本体的上下文概念集,H为层次结构,E为本体内实体。对于目标本体O和待匹配本体集S中的任意本体O′,那么,相似度匹配计算结果可用公式(2)表示:
(2)
其中α、β、γ分别为控制参数,而且α、β、γ满足以下条件:

AOMA-AI算法的流程过程可用以下八个步骤描述,其中(1)~(3)为情景匹配部分,(4)~(6)为结构匹配部分,(7)为语义匹配部分,(8)为算法流程输出部分。AOMA-AI算法的具体描述如下:
关键词(1)获取抗原本体O的描述W,并确定本体O′集中每个功能描述关键词Mi(i=1,2,3,…,n),即首先考察每个本体是否存在与抗原本体关键词W相关联的概念(例如同义概念、父子概念、包含或者被包含概念等)[10];同时,设定一个匹配阈值θ来保证情景匹配结果的准确性,阈值θ初始值为θ0,并随着匹配迭代过程不断更新。
(2)通过词语相似性公式(3),计算抗原和本体集内各本体的领域相似度[11]:
SimC(O,O′)=Comm(W,Mi)-
Diff(W,Mi)+Winkler(W,Mi)
(3)
关键词其中,Comm表示两个最大匹配字串所占比例,Diff表示未匹配比例,Winkler函数的返回值表示修正参数[12],其相应的计算公式如公式(4)~(6)所示:
(4)
Diff(W,Mi)=
(5)
Winkler(W,Mi)=
WinkerImpro(W,Mi,Comm(W,Mi))
(6)
WinkerImpro(W,Mi,comm)=
CPL*0.1*(1-comm)
关键词其中,CPL(Common Prefix Length)为待比较W和Mi相同前缀的长度值;p为调节系数,根据文献[3]取p=0.6。
中图分类号:TP391 文献标志码:A
doi:10.3969/j.issn.1007-130X.2015.06.014
收稿日期:*2014-06-17;修回日期:2014-09-18
基金项目:江苏省产学研联合创新资金资助项目(SBY201320423)
作者简介:
(3)利用公式(3)得出领域相似度最大的本体并进行判断。如果SimC(O,O′)≥θ,则可以确定该本体领域即可作为抗原的领域,可直接进入本体结构和语义匹配来计算Sim(O,O′)值的大小。如果比较本体为记忆本体,并且Sim(O,O′) ≥δ,则输出匹配的记忆本体,否则将遍历本体集合,查找与之匹配的子本体。
(4)情景匹配结束后,接下来是结构匹配和语义匹配的过程。首先,利用本体的概念关系计算本体结构匹配度大小值SimH(O,O′);其次,构建本体的实体相似度矩阵,计算本体语义匹配度的大小SimE(O,O′)。请注意,本文在结构匹配中也需要设定一个阈值,只有当SimH(O,O′)大于阈值时才能继续执行语义匹配过程(为降低算法复杂性,该阈值暂设为一定值)。
(5)本体结构匹配主要包括实体的结构匹配,下面将详细介绍匹配过程。首先,实体结构匹配主要是对本体内实体与实体之间关系的匹配,其中本文对实体与实体的关系界定是父子、兄弟和不相关三种。假设待匹配本体O和O′中的实体e和e′,且两实体对应的父实体为u和u′,对应的子实体分别为v和v′,对应的实体结构图如图3所示。
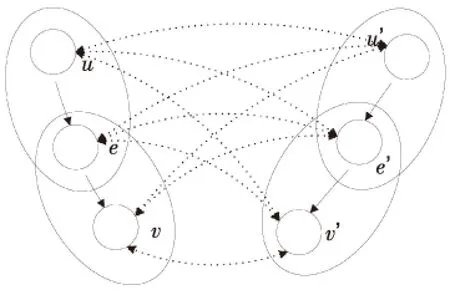
Figure 3 Ontology structure matching 图3 本体结构匹配图
(6)本体结构匹配的计算公式描述如(7)所示:
SimH(O,O′)=WpSimEp(u,u′)+
WeSimEe(e,e′)+WdSimEd(v,v′)
(7)
而且,对应的约束条件为:
Wp+We+Wd=1
其中,shortcut为实体e和e′之间最短路径长度,Path(e,e′)表示实体e和e′之间最短路径的方向改变次数;≡表示对等关系,≤表示从属关系,∈表示部分整体关系;Cbase(e,e′)是对实体e和e′的逻辑关系的表示方法;C为对关系的单位表示[1];Wp表示前驱元素及其属性的语义相似性分配的权重比例,We表示实体的独立性语义相似性分批的权重,Wd表示实体与后驱元素的相似性比例[1]。
(7)本体实体的语义相似度计算过程。
首先,构建相似度实体矩阵S,具体形式如下所示[13]:
其次,定义基于相似度矩阵S的关联集合AS,获取AS的方法如下公式所示:
此处对el、et的取值限制如公式(8)所示:
(8)
第三,实体内部的相似度主要是属性相似度计算(有关词语相似度则是根据公式(3)进行计算),其相应的计算公式如(9)所示:

(9)

最后,计算实体的相似度,具体的计算方法如公式(10)所示:
(10)

(8)根据公式(1)和公式(2),从本体集合中检索出与抗原本体匹配度值最高的本体O′并输出,得到用户所需的本体。
4实验结果及分析
4.1评估标准
为了测试本体匹配算法的有效性,本文从质量和性能两个方面对AOMA-AI算法进行效率评价[1]。在质量评价测试中,最著名的标准是来源于信息检索领域的查准率(Precision)和查全率(Recall)两个指标[1]。查准率表示算法匹配过程中匹配正确次数的数量占所有匹配次数的百分比;查全率表示的是运用匹配算法得到的正确匹配次数占所有计算正确结果的数量的比例[1],在理想情况下,Precision= Recall=1。
但是,在实际评价中,单独使用查准率或查全率都不能准确地评价算法的质量。查全率和查准率结果之间会出现很大的误差,如果仅靠这个标准并不能完全判定评价算法的质量[1]。文献[1]采用了另外两种评估变量F-Measure和OverAll来调整查准率和查全率的综合测量结果。本文也采用这两个评估指标来评价算法的效率。

(11)

(12)
4.2算法分析
从算法流程上讲,AOMA-AI算法是对OMA-VP算法[1]和ASMOV算法[2]的改进。ASMOV算法的本体匹配过程包含术语匹配、结构匹配和实体匹配三个过程,OMA-VP算法的本体匹配过程包括结构匹配和语义相似匹配,结合上述两种匹配算法的优点,AOMA-AI的本体匹配过程除了包括结构匹配和语义匹配两个过程之外,新增了情景上下文匹配过程用来减少本体匹配的迭代次数,从而降低匹配时间,提高本体匹配效率。
设本体集合S,且|S|=n,平均每个本体中包含x个实体;由于三种算法中本体与本体之间匹配过程包括了结构和实体匹配过程,不妨设任意两个本体O1与O2之间匹配的平均时间为T(O1,O2),结构匹配平均时间为T(Hc),实体匹配平均时间为T(E)。T(O1,O2)与T(Hc)和T(E)的关系为T(O1,O2)=T(Hc)+T(E)。
设记忆本体集合M长度|M|=l,此处l为常数值。
本体匹配算法时间复杂度分析过程如下:
首先,AOMA-AI算法时间复杂度分析。AOMA-AI采用了分治策略,即将本体集合S集合逐次分解子本体集合,然后递归调用。具体过程描述为:首先,通过情景匹配初步分解为m个子本体Si(1≤i≤m,m≤n),选择满足条件的子本体集;然后,通过情景匹配递归调用子本体集,从中获取符合条件的子本体Sij(1≤j≤r,r≤m)。因此,AOMA-AI算法的平均时间复杂度可表示为O(logn)(T(O1,O2));AOMA-AI算法的最差时间复杂度为O(n)(T(O1,O2))。由于记忆本体集合M的存在,使得AOMA-AI算法时间复杂度最优可表示为O(1)( T(O1,O2))。
其次 ,OMP-VP、CBOMA和ASMOV算法的时间复杂度分析。OMP-VP、CBOMA和ASMOV算法是对本体集合S中的所有本体遍历,其时间复杂度直接表示为O(n)(T(O1,O2)),并不存在最优时间复杂度的情况。
因此,通过比较AOMA-AI、OMP-VP、CBOMA和ASMOV算法的时间复杂度可以看出,ASMOV算法在进行本体匹配过程时,利用对本体集合的预操作减少了本体匹配的迭代次数,相对其他本体匹配算法而言,匹配效率有所提高。
本体匹配算法准确性分析如下:AOMA-AI算法是对OMA-VP算法的改进,新增情景匹配过程用来保证本体O1和O2的结构和语义匹配过程是在领域上下文相似的前提下进行的,这样可以对相似词语进行过滤,提高本体匹配的准确度;AOMA-AI算法与ASMOV算法相比,除了情景匹配的优点外,还明显简化了本体比较的过程,减少冗余计算,从而提高了算法效率;AOMA-AI算法和CBOMA算法相比,相同点是对实体匹配都是对术语和属性匹配,而AOMA-AI算法通过情景匹配获取用户情景上下文来确定本体领域提高匹配准确度,并且引入了记忆本体集来提高本体匹配效率。
4.3实验结果
本次实验硬件环境为E7500 2.93 GHz的CPU,2 GB内存,软件环境为Eclipse-SDK-3.7。根据第3节本体匹配过程,设计出其中某一本体的实体结构图,该图中没有标记处实体内属性,匹配过程如图4所示。
图4中本体O为根据用户信息构建出的抗原本体,而本体O′则是本体集合中的本体。图4表示出本体匹配时实体匹配过程假设抗原本体O和本体O1中均包含四个实体,那么本体匹配过程是通过比较时实体相似度构建出相应的本体相似度矩阵。

Figure 4 Internal entity comparison of ontologies 图4 本体内部实体比较
AOMA-AI算法阈值δ、θ的确定,对于δ值的选取如图5所示。

Figure 5 Result of δ 图5 δ值结果
选取δ值太大,将会使得记忆本体集成为虚设,而δ值过小,则将会受制于记忆本体集合而对匹配的准确性产生影响,因此本文对δ值设定了最大可能区间δ∈[0.5,0.8]。图5a中显示了δ值从0.5到0.8的变化结果,且当δ=0.7时其匹配度能满足条件,且匹配效率高。
对于θ的初始化值θ0的选取将影响本体匹配结果,由于θ的大小是随迭代过程变化的,所以对于θ0值初始化值设定为θ0∈[0.3,0.7]。图5b显示了θ0值从0.3到0.7变动时本体匹配的变化结果(θ0不妨取0.4)。设θ值变化公式为:θ=θ0+[logmn]*m/n(m 对于参数α、β、γ值的选取对实验结果的影响,如图6所示。 Figure 6 Results of parameter selection 图6 参数选择结果 当α取值太大时,本体匹配将会受限于本体上下文领域而忽视了本体结构和语义匹配结果;当α取值太小,则会对匹配结果值造成很大的影响。从图6显示结果可以看出,当α∈[0.4,0.5]时,本体匹配平均值最大,为了使得算法容易控制,本文中将参数α和β值暂时定为0.4和0.3。 本文根据OAEI 2014测试数据集来测试AOMA-AI算法的运行效果。对于OAEI 2014数据集,本文选取#101、#102、#103、#104、#301、#302、#303和#304数据作为本文算法的测试数据集。AOMA-AI算法对传统本体匹配算法的改进主要有两点:第一,融入人工免疫算法,以提高本体匹配效率;第二,加入情景匹配,以提高本体匹配的准确度。所以,这次实验过程主要是结合以上两点展开的。 (1)算法效率比较。由于某特定的抗原本体对数据集多次刺激后生成了相应的记忆抗体,这时通过对传统本体匹配算法ASMOV[2]、基于人工免疫的本体匹配算法AOMA-AI以及无人工免疫的本体匹配算法AOMA(AOMA算法是AOMA-AI算法的一部分,是在不考虑记忆本体集合时执行全本体匹配的算法,即进行本体匹配过程时跳过记忆本体集合直接执行情景匹配、结构匹配和语义匹配的过程)的运行时间进行对比,得到三种算法运行时间,如图7所示。 Figure 7 Running time of the algorithms 图7 算法运行时间 从图7可以看出,当同一抗原本体要求多次与测试数据集合进行匹配时,基于人工免疫的本体匹配算法的耗时明显地低于原本体匹配算法的耗时,而且人工免疫算法还对本体设置了生存期,对于超过生存期的本体进行隐藏。所以,随着匹配次数的增加,基于人工免疫本体匹配算法提高了本体匹配的效率。 (2)算法准确度比较。对于本体匹配准确度的评估,本文参照文献[1]的标准,即用F-Measure和OverAll来比较原本体匹配算法和AOMA-AI算法的匹配准确度的差异。评价指标F-Measure和OverAll的比较结果分别如图8和图9所示。 Figure 8 Result of F-Measure 图8 F-Measure结果 Figure 9 Result of OverAll 图9 OverAll结果 从图8和图9结果中可以看出,相对ASMOV算法而言,AOMA-AI算法确实提高了本体匹配的准确度。分析其中原因,可以看出当在数据集中的本体加入情景属性时,抗原本体与数据集中的本体要首先进行情景匹配,而只有抗原本体和数据集本体的语境相似度值大于或等于阈值θ的时候,才能进行后续的结构和语义匹配过程,这样既能排除不同领域内的本体匹配结果的干扰,也能减少本体内部的冗余计算量。 5结束语 本文利用人工免疫算法的收敛快、耗时低的特性,AOMA-AI算法将人工免疫算法融入到本体匹配算法中,有效地提高了本体匹配度和匹配效率,为后续中根据匹配本体为用户推荐相应的知识提供基础。然而,当用户情景上下文不明确时,该算法将进行本体模糊匹配,这时由于对用户行为信息不明确,仍会存在计算量冗余的问题。后续将进一步研究如何在用户上下文不明确时,根据用户历史信息以及其他相同用户的行为信息,尽最大可能为该用户提供情景支持。 参考文献: [1]Huang Tao,Cui Hong-yang,Liu Qing-tang,et al. Ontology matching approach based on virtual path[J].Computer Science,2009,37(11):207-209.(in Chinese) [2]Jean-Mary Y R,Shironoshita E P,Kabuka M R. Ontology matching with semantic verification[J].Web Semantics Science,Services and Agents on the World Wide Web,2009,7(3):235-244. [3]Gai Ke. A Research on context-based ontology-matching algorithm[D]. Harbin:Harbin Institute of Technology,2010.(in Chinese) [4]Wang Xiao-yun, Xu Qi-yu. An improved ant colony optimization for ontology matching[C]//Proc of International Conference on Computer Research & Development,2011:235-238. [5]Han Xu-ming,Wang Li-min. Improved artificial immune algorithms and their applications[M].Beijing: Publishing House of Electronics Industry,2013.(in Chinese) [6]Yang Gu-gang. An improved artificial immune algorithm [C]//Proc of the 6th International Conference on Natural Compuation,2010:2837-2841. [7]Dai Wei-min. Technology and method of sematic web information organization[M]. Shanghai:Xuelin Press,2009.(in Chinese) [8]Sun Cheng-zhu, Xu Xiao-fei, Deng Sheng-chun. Ontology representation method for virtual enterprise model[J].Computer Integrated Manufacturing Systems,2009,151(2):277-286.(in Chinese) [9]Xu Jian-feng,Wang Dong. Object-oriented and ontology context-aware modeling based on XML[C]//Proc of International Conference on Computer Science and Network Technology,2012:1795-1797. [10]Guan Dong,Cai Zi-xing,Kong Zhi-zhong. Research on grid service matching based on ontology[J].Journal of Chinese Computer Systems,2009,30(8):1640-1641.(in Chinese) [11]Stoilos G,Stamou G,Kollias S. A string metric for ontology alignment[C]//Proc of the 4th International Semantic Web Conference,2005:625-628. [12]Freckleton R E. Freckleton scaling ontology alignment[D]. Colorado:University of Colorado,2013. [13]Hu Wei,Qu Yu-zhong. A practical ontology matching system[J].Web Semantics Services & Agents on the World Wide Web,2008,6(3):237-238. 参考文献:附中文 [1]黄涛,崔弘扬,刘清堂,等.一种基于虚拟路径的本体匹配算法[J]. 计算机科学,2009,37(11):207-209. [3]盖克.基于概念上下文的本体匹配算法研究[D] .哈尔滨:哈尔滨工业大学,2010. [5]韩旭明,王丽敏. 人工免疫算法改进及其应用[M]. 北京:电子工业出版社,2013. [7]戴维民. 语义网信息组织技术与方法[M]. 上海:学林出版社,2009. [8]孙成柱,徐晓飞,邓胜春.面向虚拟企业模型的本体表示方法[J].计算机集成制造系统,2009,15(2):277-286. [10]管东,蔡自兴,孔志周.网格服务本体匹配算法研究[J]. 小型微型计算机系统,2009,30(8):1640-1641. 董济德(1986-),男,山东日照人,硕士,研究方向为信息推送和人机交互。E-mail:jidedong2008@126.com DONG Ji-de,born in 1986,MS,his research interests include information pushing,and human-computer interaction. 谢强(1974-),男,四川泸州人,博士,副教授,研究方向为信息安全和人机交互。E-mail:xieqiang@126.com XIE Qiang,born in 1974,PhD,associate professor,his research interests include information security,and human-computer interaction. 丁秋林(1935-),男,江西抚州人,博士,教授,研究方向为企业信息化和信息系统集成。E-mail:qlding@nuaa.edu.cn DING Qiu-lin,born in 1935,PhD,professor,his research interests include enterprise informationization, and information system integration.






