基于0-1矩阵的时空关联规则提取方法研究
2016-01-07郑瑾
基于0-1矩阵的时空关联规则提取方法研究
主要研究计算机应用。
郑瑾
(福建船政交通职业学院信息工程系,福州 350007)
摘要:基于Apriori算法提出了基于0-1矩阵的时空关联规则挖掘算法,并以挖掘不同年代的土地覆盖现状之间的时空关联关系作为试验案例,对比Apriori算法的提取结果和提取效率,研究结果表明:该算法不仅减少了扫描数据库的次数,而且减少了冗余候选项集的产生,提高了时空关联规则的提取效率。
关键词:0-1矩阵;时空关联规则;Apriori算法
0引言
数据挖掘(Data Mining)是指从数据库或数据仓库中提取隐含的、潜在的、有用的、最终可理解的知识和规则等,其中关联规则是DMKD中的重要内容之一[1],它反映出在给定的数据库或数据仓库中,大量数据之间存在的内在关联关系,形如X->Y的蕴含式。随着地理信息系统(Geographical Information System,GIS)与遥感技术(Remote Sensing,RS)的迅速发展,空间数据呈现出“爆炸式”增长,由于空间数据具有空间性、时间性、多维性、海量性、复杂性、不确定性等特点[2],因此,如何从海量的空间数据中获取有用的知识成为许多学者重点关注的问题。李德仁教授在1994年于加拿大渥太华举行的地理信息系统国际学术会议上,首次提出了从GIS数据库中发现知识(Knowledge Discovery from GIS,KDG)的概念[3],系统性地分析了各种空间或非空间的知识类型与挖掘算法。目前,空间关联规则挖掘的主要方法是通过将空间数据库进行泛化,建立一般事务数据库,并利用关联规则挖掘算法,如Apriori算法,从中提取空间关联模式。K.Koperski[4]与陈刚[5]等都曾将Apriori算法应用于空间关联规则领域,提取有趣的空间关联模式。若同时考虑时间维与空间维两因素,则关联规则将从平面扩展到立体,形成了时空关联规则。
时空关联规则旨在发现时空数据库或时空数据仓库中各数据项集之间潜在的、有用的时空关联关系,是时空数据挖掘领域中最为关键的技术难点之一。李波等通过建立具有时间与空间特征的洪泽湖水质数据库,基于相关数据矩阵获取洪泽湖水质的时空相关性及其时间和空间分布规律[6];沙宗尧提出了时序空间关联规则挖掘方法,并应用于土地类型变化的时空关联分析中[7];岳慧颖提出了SKDM(Shi Kong Data Mining)算法,先后考虑空间与时间的双重约束[8];Florian Verhein等提出了一种应用于交通高区域进行属性约减的STAR(Spatio-Temporal Association Rules)算法,将关联规则扩展到时空领域[9];Marcin Gorawski等基于Apriori算法的基础上,扩展了自连接的约束条件,从而生成了使用关联模式[10];夏英等则是综合分析了SKDM与Apriori算法的基础上提出了STApriori算法,并应用于交通系统中分析交通拥堵趋势[11]。时空关联规则挖掘需要同时考虑时间与空间的约束,本研究基于Apriori算法原理,并在综合考虑空间数据特点的基础上,提出了基于0-1矩阵的时空关联规则挖掘算法,重新定义了时空数据频繁项集,最后将该算法应用于不同年代的土地覆盖类型之间的时空关联性分析,以证明该算法的有效性。
1算法原理
Apriori算法是数据挖掘领域中关联规则挖掘的经典算法之一,该算法于1994年由R.Aglawal等[12]人提出的,该算法的详细原理和过程见文献[12]。其本质思想是使用一种逐层搜索的迭代方法,根据挖掘出的频繁-(k-1)项集通过Apriori-gen()函数,产生用于挖掘频繁k-项集的候选项集合(k>=2),依此循环直至不能再产生新的频繁项集为止。该算法每产生一个频繁k-项集,都需要扫描一次数据库,并且会产生大量的候选项集,造成冗余项集比较多,时间开销比较大,尤其是面对海量数据时,其局限性表现得更为明显。基于Apriori算法的缺陷,许多学者开始探讨如何提高Apriori算法的效率,许多基于Apriori的改进型算法也相继被提出,如FP-Growth算法[13]等。
本研究在基于布尔矩阵的Apriori改进型算法[14]原理的基础上,结合空间数据的特点,重新定义时间数据频繁项集,提出了基于0-1矩阵挖掘最大频繁项集的时空关联规则挖掘算法,该算法的基本思想是定于最小支持度与置信度,基于Apriori算法提取频繁1-项集与包含每个频繁1-项集的事务ID,每个频繁1-项集都带有时间约束条件,并构建行标题为频繁1-项集,列标题为事务ID的0-1矩阵,该矩阵中,值取‘1’表示该事务ID包含对应的频繁1-项集,反之不包含。针对该布尔矩阵,计算矩阵中每一列包含‘1’的数量,若相同数量‘1’的总列数大于最小事务支持度,则将该值假定为最大频繁项集的可能长度,依此循环,可得到最大频繁项集的所有可能性长度。基于该长度值,从频繁1-项集中产生最大频繁项集的候选项,并计算每个候选项的支持度,如果支持度超过最小事务支持度,则频繁,反之不是。最后依据频繁项集的非空子集仍频繁的原理得到所有频繁项集。由此可见,该算法的基本原理主要包括以下3个方面。
1.1构建0-1矩阵
定义最小事务支持数,首次扫描事务数据库时,利用Apriori算法提取频繁1-项集,每个频繁1-项集都需要带有时间约束条件与包含该频繁1-项集的事务标识号,定义频繁1-项集的0-1数组,长度为事务数据库的数量,在该0-1数组中,频繁1-项集带有的事务标识号TID在数组中对应位置的值为‘1’,不带有的标识号在数组中值为0。最后将所有的频繁1-项集的0-1数组构建成频繁1-项集0-1矩阵。
定义1频繁1-项集的0-1数组为Im[N]TI={BLT1,BLT2,…,BLTn}(1≤n≤N),其中Im为第m个频繁1-项集,N为事务单元的数量,TI为时间约束条件,T1至Tn分别表示第1个至第n个事务单元的TID,BLT1至BLTn只取0或1。
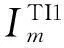
输入:事务数据库—DTI,最小支持度-m_sup
Begin
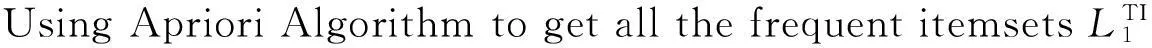

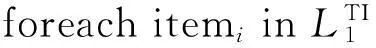
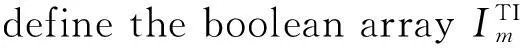
foreachtinD
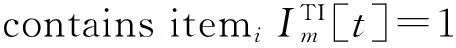
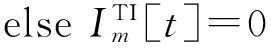

end for
end for
End
1.2提取最大频繁项集
在0-1矩阵中,每列代表了一条事务单元记录,列中‘0’值表示该事务单元中不包含对应的频繁1-项集,反之,值‘1’则表示含有的频繁1-项集。因此,‘1’的数量代表了该事务单元同时含有的频繁1-项集的数量,如果含有相同数量‘1’的事务记录数的数量大于最小事务支持数,则可以将‘1’的数量值拟定为最大频繁项集可能性长度,将所有可能性取值从大到小排序,并依次根据频繁1-项集获取可能性长度的最大频繁项集的候选项集,通过0-1矩阵来获取每个候选项集的支持,若支持度大于预先设定的最小事务支持数,则为最大频繁项集,反之不是,若都不是最大频繁项集,则最大频繁项集的长度为1。
定义3MaxLen[n]为存储最大频繁项集可能性长度的数组,其中n为该数组的数量。
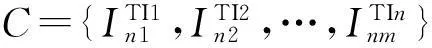
定义5候选项的支持度Support(C)=In1[N]TI1&In2[N]TI2&…Inm[N]TIn,其中‘&为布尔运算中的‘与’计算,以下为该部分的伪代码描述:
输出:最大频繁项集-Lk
Begin
常用算法包括以下几种:平滑、中职与均值滤波。基于以往滤波经验,改进平滑滤波,分析中值和均值两种方法的结合。
count the number of value 1 in the current column
end for
pos_len=count the number of the columns with the same number of value 1
if pos_len>m_sup
return MaxLen[n]
end if
Sort(MaxLen[n])
foreach value in MaxLen[n]
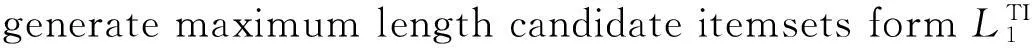
foreach itemset in candidate itemsets
if Support(itemset)>m_sup
itemset is frequent
end if
if Maximum frequent itemsets is not null
break;
end if
end for
end for
End
1.3提取所有子频繁项集
根据最大频繁项集的非空子集也频繁的原理,利用得到的最大频繁项集,产生余下所有的频繁项集,所有产生的频繁项集的支持度仍然按照定义5中的原理进行计算获取,最后利用所有的频繁项集来产生关联规则。
2算法实现及性能比较
为了证明该算法的有效性,本研究以挖掘不同年代的土地覆盖现状之间的时空关联关系作为试验案例,以2005年—2010年从遥感影像提取的厦门市土地利用现状图作为试验数据,分别利用该算法和Apriori算法提取不同年代土地覆盖类型之间的时空关联规则,最后对比并分析两者提取效率的差异性。
2.1数据预处理
根据目前时空关联规则挖掘的主要思想,需要对不同年代的土地覆盖现状数据进行预处理,将空间数据泛化,建立时空事务数据库。基于Imam Mukhlash和Benhard Sitohang[15]提出空间数据预处理框架,需要进行以下2个方面的空间数据预处理。
2.1.1数据准备与处理
获取从遥感影像解译的从2005年至2010年的厦门市土地利用覆盖现状矢量数据,并对该数据进行矢量转栅格处理,将处理结果重采样成分辨率为100 m的栅格数据。最后,利用试验区的行政区范围,对以上数据进行范围界定,以保证各空间数据范围的一致性。
2.1.2读取栅格数据属性值,构造事务表
以单个格网单元作为单条事务记录,每条事务记录由6部分组成,分别是各年代土地覆盖现状对应栅格的值,每个值都带有时间约束条件,形如{TID、土地利用类型1(时间1)、土地利用类型2(时间2)、土地利用类型3(时间3)、…、土地利用类型6(时间6)},最后采用C#面向对象语言与ArcEngine组件快速读取栅格数据属性值、构造属性事务表以及实现Apriori算法和本文所提出算法。
2.2算法比较
针对已构建的总事务记录数为167 155的属性值事务表,设置最小事务支持数分别为100、200、400、800、1 600、3 200、6 400、12 800、25 600,同时假设最小支持度为0.03,最小置信度为0.2。基于以上设置的参数,将已程序化的该算法和Apriori算法在CPU为Pentium(R)Dual-Core2.60 GHz、内存为2 GB、操作系统为Microsoft Windows7的PC机上运行并提取空间关联规则,最后比较2种算法的提取效率,结果如图1所示。从图1中的比较结果,可以很明显地发现:本文所提出的算法在关联规则提取效率上要优于原始的Apriori算法,而且更为稳定。
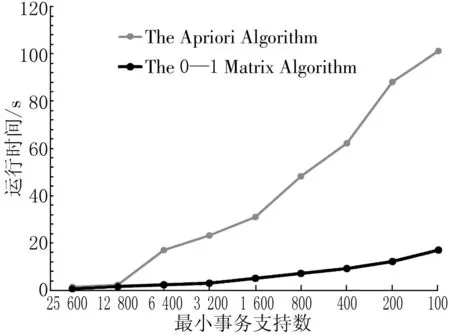
图1 2种算法的效率比较
3结语
本研究基于Apriori的算法原理,借鉴基于布尔矩阵的空间关联规则提取方法,并综合考虑空间数据的特征,提出了一种新的时空关联规则挖掘算法——基于0-1矩阵的时空关联规则提取算法,该算法同时考虑时间与空间2个因素,解决了Apriori算法的缺陷,减少了扫描数据库的次数,在提取过程中,只需要扫描一次数据库,并优先通过产生最大频繁项集的候选项来得到最大频繁项集,大大减少了候选项集产生的数量,极大地提高了时空关联规则的提取效率。但是该算法仍然有许多方面需要斟酌:1)在0-1矩阵,可能存在连续的多个‘0’值,会造成内存资源浪费。2)缺乏对频繁模式集的质量评价,Jiawei Han指出如何得到压缩的、高质量的频繁模式以及对频繁模式的解释是未来急需解决的问题[16]。3)没有考虑空间数据的自相关性,陈江平等发现数据的空间自相关性对关联规则的挖掘存在作用和影响[17]。以上3点,也将是下一步研究工作的重点。
参考文献
[1] Han Jiawei,Kamber M.数据挖掘概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2007:5-6.
[2] 张俊.时空关联性分析方法研究与应用[D].重庆:重庆大学,2011:7.
[3] 李德仁,王树良,李德毅.空间数据挖掘理论与应用[M].北京:科学出版社,2006:3-4.
[4] Koperski K.Han J.Discovery of spatial association rules in geographic information databases [J].Lecture Notes In Computer Science,1995,951:47-66.
[5] 陈刚,何政伟,杨斌.地形特征与山地气候变化空间关联规则数据挖掘研究[J].地理与地理信息科学,2010,26(1):37-40.
[6] 李波,濮培民,韩爱民.洪泽湖水质的时空相关性分析[J].湖泊科学,2001,14(3):259-266.
[7] 沙宗尧.时序空间关联规则挖掘及其应用研究[J].地理空间信息,2008,6(5):18-21.
[8] 岳慧颖.含有时空约束的关联规则挖掘方法研究[D].哈尔滨:哈尔滨工程大学,2004:52-54.
[9] Florian Verhein,Sanjay Chawla.Mining Spatio-Temporal patterns in object mobility database[J].Data Mining and Knowledge Discovery,2008,16(1):5-38.
[10] Marcin Gorawski,Pawel Jureczek.Using Apriori-like Algorithms for Spatio-Temporal Pattern Queries[C]//Proceedings of the International Multiconference on Computer Science and Information Technology,IEEE,2009:43-48.
[11] 夏英,张俊,王国胤.时空关联规则挖掘算法及其在ITS中的应用[J].计算机科学,2011,38(9):173-176.
[12] Agrawal R,Imelinski,Swani A.Mining association rules between sets of items in large database[J].International Journal of Science and Modern Engineering,2013,1(5):2319-6386.
[13] HAN Jia-wei,PEI Jian,YIN Yi-wen,et al.Mining Frequent Patterns without Candidate Generation:A Frequent-Pattern Tree Approach[J].Data Mining and Knowledge Discovery,2004,8(1):53-87.
[14] 陈俊明.基于布尔矩阵的空间关联规则提取方法研究[J].测绘与地理空间信息,2014,37(5):123-126.
[15] Imam Mukhlash,Benhard Sitohang.Spatial Data Preprocessing for Mining Spatial Association Rule with Conventional Association Mining Algorithms[C]//Proceedings of the International Conference on Electrical Engineering and Informatics.Institute Teknologi Bandung,Indonesia June,2007:17-19.
[16] Han Jia-wei,Cheng Hong,Xin Dong,et al.Frequent pattern mining:current status and future directions[J].Data Mining and Knowledge Discovery,2007,15:55-86.
[17] 陈江平,黄炳坚.数据空间自相关性对关联规则的挖掘与实验分析[J].地球信息科学学报,2011,13(1):109-117.
doi:10.3969/j.issn.1009-8984.2015.02.030
收稿日期:2015-04-09
作者简介:郑瑾(1983-),女(汉),福州,讲师,硕士
中图分类号:TP391
文献标志码:A
文章编号:1009-8984(2015)02-0114-04
The study on method of extracting spatial-temporal association rules based on 0-1 matrix
ZHENG Jin
(DepartmentofInformationEngineering,
FujianChuanzhengCommunicationsCollege,Fuzhou350007,China)
Abstract:In this article,an algorithm of extracting spatial-temporal association rules based on Apriori algorithm has been put forward.A case has been studied on extracting the association rules between land covers in different periods and the extracting results and extracting efficiencies has been compared with Apriori algorithm.The study results show that:the new algorithm improves the efficiency of extracting spatial-temporal association rules by reducing the times of scanning the data,and reducing the generation of redundant candidate sets.
Key words:0-1 matrix;spatial-temporal association rule;Apriori algorithm
