基于皮尔逊相关系数的有机质谱相似性检索方法*
2015-12-29李宏彬赫光中果秋婷
李宏彬,赫光中,果秋婷
(咸阳职业技术学院医学院医学技术研究所,陕西咸阳 712000)
基于皮尔逊相关系数的有机质谱相似性检索方法*
李宏彬,赫光中,果秋婷
(咸阳职业技术学院医学院医学技术研究所,陕西咸阳 712000)
对基于皮尔逊相关系数的有机质谱谱图相似性评估方法进行了研究。以质量数为自变量,丰度为因变量,经过一定的数据预处理过程后两个化合物的谱图转化为两个数组,这样不同化合物就可套用皮尔逊相关系数进行相关性计算。采用皮尔逊相关系数方法对具有同分异构相似性和化学结构式相似性的两组有机物质谱图谱组内、组间进行相似性计算,具有一定相似性的同一组内,谱图之间呈现较高的相关系数分值;不同组的谱图呈现非常低的相关系数分值。因此使用皮尔逊相关系数方法进行谱图相似性评估是可行的。对丰度进行非线性变换,可以大幅度提高算法的变异系数,提高质谱数据库的搜索效率。
皮尔逊相关系数;质谱;相似性检索
质谱是通过制备、分离、检测气相离子质荷比(质量-电荷比)的分析方法来鉴定化合物的一种分析化学技术。质谱分析具有极高的灵敏度,很少的样品用量,快速和准确等优点,因此被广泛地应用于化工、环境、能源、材料、医药、生命科学等领域。不同的物质有不同的质谱,利用这一性质,可以进行化合物分子质量和相关结构信息的分析。质谱分析的基础是谱图库检索,即将质谱检测获得的谱图同已验证的质谱数据库内的谱图进行匹配,由于每张质谱谱图的数据量非常大,检索过程通常由计算机来完成。检索算法的准则:(1)当质谱数据库中存在待检物质的谱图时可以将其析出;(2)当质谱数据库中不存在与待检物质完全一致的谱图时,能够按照相似性程度次序列出数据库中与待检物质近似的化合物。
目前已出现了一些质谱谱图相似性检索策略,如日本岛津QP5000-GC/MS气相质谱和色谱联用仪的CLASS 5OOO[1]相似性系数计算,见式(1):

式中:SI——未知谱和参考谱之间的相似性分值;
Iui——未知谱在谱图中某个位置的丰度;
Iri——参考谱在谱图中某个位置的丰度。
使用唯一因子即质谱丰度的相似性检索方法还有美国LAM[2]提出的基于质谱丰度内积相似度的公式(2):

加拿大的Wu[3]提出的基于余弦相似度的公式(3):

式中:l——两张质谱中质荷比在某一容差值范围内匹配峰的个数。
以上方法过多的强调了谱图的丰度因素,而没有考虑质荷比m/z对相似性的贡献,效果略差。南开大学律祥俊[4]对上述公式进行了改进,提出了用丰度I和质荷比m/z的乘积作为峰权重因子的不相似性系数DI计算公式(4):
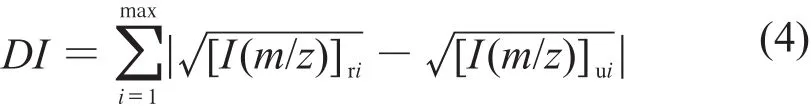
式中:[I(m/z)]ri——未知物谱某一谱线的丰度与质荷比乘积;
[I(m/z)]ui——参考谱某一谱线的丰度与质荷比乘积。
吉林大学的扈庆等[5]也提出含有I和m/z乘积因子的相似性系数公式(5):
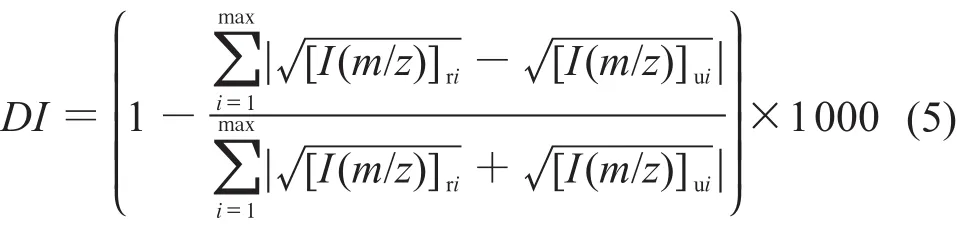
天津大学宋爽[6]提出应对未知谱和参考谱图的谱峰进行非线性缩放,缩放的公式为(m/z)aIb,a和b的大小直接影响最后的相似性检索结果,并建议使用a=3和b=0.5的基于P范数的公式(6):

式中:Wui,Wri=[(m/z)i]3I0.5。
这些算法各具优势,推动质谱谱图相似性检索技术向更科学和高效发展。
1 实验方法
一些基于相关性的方法如余弦相关和皮尔逊相关系数等常被用于化学指纹图谱如光谱、色谱的相似性测量[7]。皮尔逊相关系数是反映两个数据变量的关联程度的一种统计学方法,它的取值r介于1和-1之间,绝对值越大,意味着两个变量的关联程度越强,绝对值越趋近于0,关联程度越弱。在本研究中按3级划分:|r|<0.4为不相关;0.4≤|r|<0.7为显著性相关;0.7≤|r|<1为线性高度相关。皮尔逊相关系数r=1称完全正相关,r=-1称完全负相关。针对质谱谱图的特点,笔者提出一种基于皮尔逊相关系数的质谱谱图相似性精确检索方法,见公式(7):
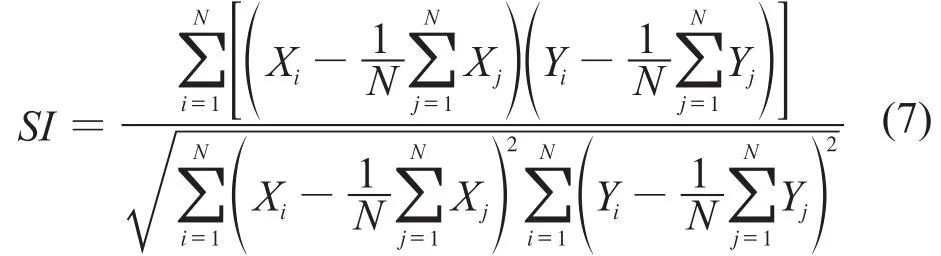
式中:SI——未知谱图X和参考谱图Y的相似性分值;X——未知谱的丰度序列集合;Y——参考谱的丰度序列集合;N——待比较谱线数目。
在计算皮尔逊相关系数之前,对两组质谱数据进行预处理。首先,设定比较区间,比较区间设定为质量数0与两者质量数最大值之间;其次,应根据质谱数据的质量数精度设定数据步长,例如质量数精度为0.1,则设定两组待比较数据的质量数步长均为0.1,并在两组数据质量数为小数后一位的位置进行插值生成扩编数据(若原两组数据在该小数位置有值则值保留,否则均插值0);第三,设置质谱数据丰度门限,数据中丰度高于门限的数据将被保留,否则将被置0。例如,对于质谱数据A{11,5,30,51,8,13,4}和丰度门限10,则处理后的数据为分别为A1{11,0,30,51,0,13,0}。预处理之后两组数据具有相同的数据长度,并保留了具有显著丰度值的质量数位置,然后套用皮尔逊相关系数进行相似度计算。2005版本的NIST/EPA/NIH的质谱数据库(NIST 05)包含163 198个不同有机化合物的190 825张质谱数据,利用NIST 05数据库附带新的质谱查询软件MS Search Ver2.0的分子式查询方式获得一些待比较有机化合物的质谱谱峰数据和结构简式,然后利用数值计算软件MATLAB套用皮尔逊相关系数分析这些化合物之间的相似性分值。
2 结果与讨论
为了检验皮尔逊相关系数作为有机质谱谱图相似性评估方法的合理性,选取具有同分异构相似性和化学结构式相似性的两组数据。由于同分异构体之间具有相同的分子式,化学结构式相似的物质具有若干类似的功能基,无论前者还是后者经质谱仪处理后都应该拥有更多相似的碎片谱线,因此质谱谱线数据的相似程度相对于关联性少的物质之间应该更高一些。如图1所示,首先利用从NIST 05数据库下载的化学式同为C7H8的13种同分异构体的质谱数据,两两进行皮尔逊相关系数计算,计算结果见表1。

图1 化学式为C7H8的同分异构体结构简式及其编号
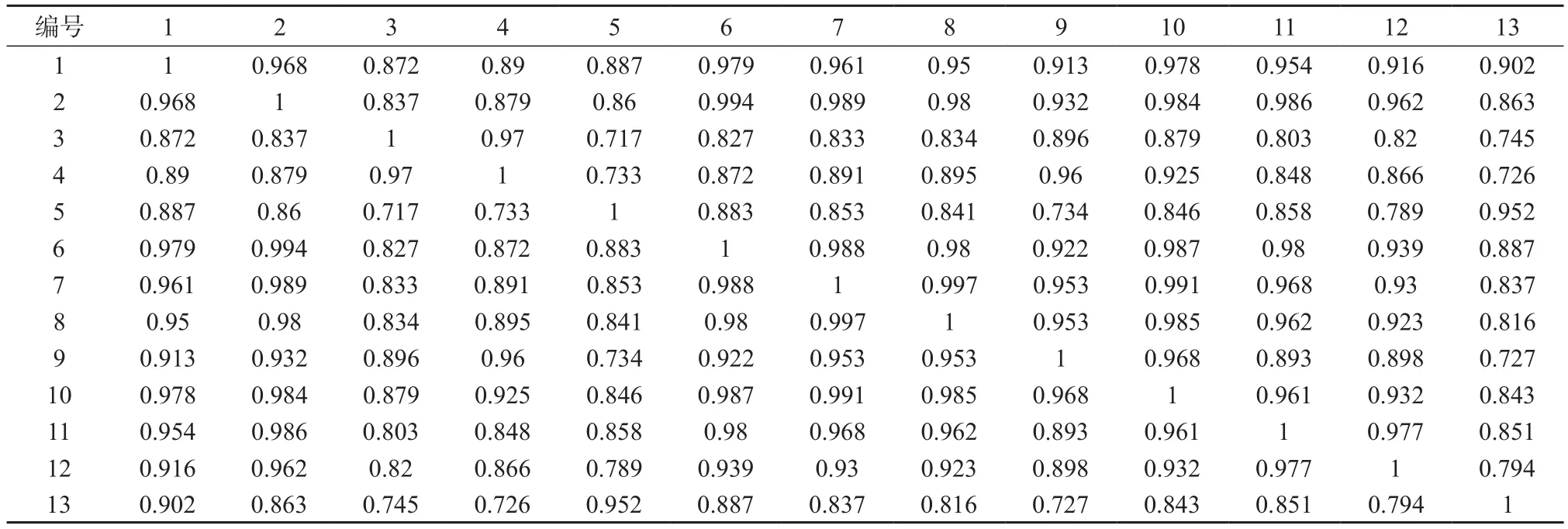
表1 C7H8的13种同分异构体之间的质谱皮尔逊相关系数(组1)
计算后发现这些同分异构体质谱之间的相关系数非常高,平均值接近0.906,标准偏差为0.076 8,变异系数为8.48%。平均值反映这一组物质之间的质谱数据平均相似程度,标准偏差和变异系数反映数据之间的离散程度。
如图2所示,从NIST 05数据库下载了化学式不同但同为正烷烃相似结构的甲烷到十三烷的质谱数据,两两进行了皮尔逊相关系数的计算,计算结果见表2,它们之间的平均相关系数达为0.540,相似性弱于表1数据,标准偏差为0.412,变异系数为76.3%,数据离散程度远高于第一组。从表2数据中也可以发现,分子结构差异越小,则质谱皮尔逊相关系数分值越高。

图2 一些正烷烃的结构简式及其编号

表2 图2中的不同正烷烃之间的质谱皮尔逊相关系数(组2)
对分子结构差异大的C7H8各同分异构体与上述正烷烃之间的质谱相关系数进行计算,计算结果见表3。由表3数据可知,它们之间的平均相关系数很小,为-0.082,远小于组1和组2,标准偏差为0.032 1,变异系数为-39.4%,数据之间的离散程度较大。

表3 C7H8的同分异构体与一些正烷烃之间的质谱皮尔逊相关系数(组3)
将上述组1(分子式为C7H8的同分异构体两两之间)、组2(甲烷到十三烷两两之间)和组3(C7H8的同分异构体同正烷烃之间)的质谱相似性用其它质谱谱图相似性评估方法(1 岛津,2 Lam,3 Wu,4律祥俊,5 扈庆,6 宋爽)进行计算,然后将计算得到的数据同皮尔逊相关系数进行相似性比较,结果如图3所示。由图3可知,皮尔逊法在组1和组2的相似性评估分值与方法1岛津和方法5扈庆相关性较高,而在组3与上述其它方法评估后数据的相关性相对差一些。
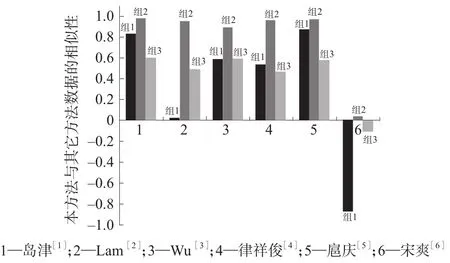
图3 皮尔逊相关系数评估法和其它质谱图相似性评估方法的相似性比较
变异系数是反映数据(序列数据和表数据)离散性的一个参量,对于一组高度相关的质谱数据例如C7H8的同分异构体,数据变异系数越高,则越有利于数据筛选和计算机检索。用不同方法对相关性较高的组1和组2的计分数据进行了变异系数研究,研究结果如图4所示。谱图相似性更高的组1中,变异系数相对略低,而在相似性较高的组2中,变异系数相对较高。

图4 不同的质谱图相似性评估方法对组1和组2数据评估后变异系数比较
组1、组2和组3质谱数据经不同的非线性变换后,用皮尔逊公式(7)计算相关系数,得到相关系数的均值、标准偏差和变异系数,结果见表4。
由表4可知,经不同的非线性变换后进行皮尔逊相关系数计算,能够改变数据间的变异系数。引入质核比因子m/z(方法2到5)或对原始丰度值进行大于1的幂运算变换(方法6到8),都不能显著提高组1数据(同分异构体组,质谱谱图间相似度高)的变异系数,而使用对原始丰度值进行小于1的幂运算变换,如方法9到13,可以有效提高组1数据间的变异系数。当在数据库中搜索匹配的谱图出现多个相似性分值接近的候选谱图时,可以进行适当的小于1的幂运算变换,拉开分值间的差距,这样能提高质谱数据库的搜索效率。
3 结论
对基于皮尔逊相关系数的有机质谱谱图相似性评估方法进行了研究,通过对具有同分异构相似性和化学结构式相似性的两组有机物质谱图谱组内和组间进行相似性计算,验证了用皮尔逊相关系数方法进行谱图相似性评估是可行的。实验还发现对原始丰度值进行小于1的幂运算变换,可以大幅度提高算法的变异系数,这对于提高质谱数据库的搜索效率有很大帮助。
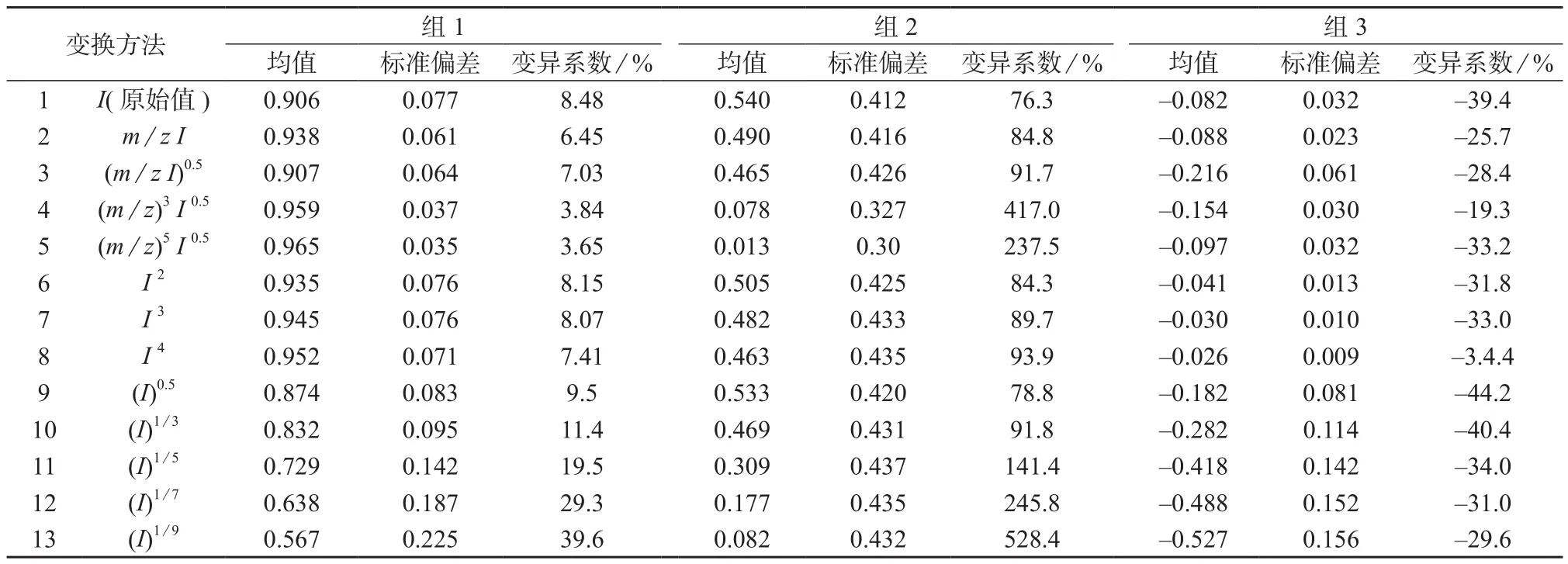
表4 皮尔逊相关系数均值、标准偏差和变异系数
[1] 许禄.化学计量学[M].北京,中国科学出版社,1992.
[2] Lam H,Deutsch E W,Eddes J S,et al. Building Consensus Spectral Libraries for Peptide Identification in Proteomics[ J]. Nature Methods,2008,5(10): 873-875.
[3] Wu Zhan,Lajoie G,Ma Bin. MSDash: Mass spectrometry database and search[J]. Computational Systems Bioinformatics/Life Sciences Society Computational Systems Bioinformatics Conference,2008,7(1): 63-71.
[4] 律祥俊,林少凡,张金碚,等.一种有机质谱谱图的库检索新算法[J].高等学校化学学报,1994,15(5): 678-680.
[5] 扈庆,方向和田地.一种有机质谱检索的匹配算法[J].计算机与应用化学,2005,22(11): 977-979.
[6] 宋爽.气相色谱-质谱联用仪的纯净谱图提取与检索算法的研究[D].天津大学,2011.
[7] Christensen J H,Mortensen J,Hansen A B,et al. Chromatographic preprocessing of GC-MS data for analysis of complex chemical mixtures[J]. Journal of Chromatography A,2005,1 062(1): 113-123.
[8] Stein S E,Scott D R. Optimization and testing of mass spectral library search algorithms for compound identification[J]. Journal of the American Society for Mass Spectrometry,1994,5(9): 859-866.
[9] Jeffries N. Algorithms for alignment of mass spectrometry proteomic data[J]. Bioinformatics,2005,21(14): 3 066-3 073.
[10] 王耀君,孙世伟,卜东波,等.串联质谱谱库搜索鉴定技术综述[J].计算机工程,2012,38(7): 269-272.
日本研制出新型癌症荧光检测试剂
日本东京大学等机构的研究人员研制出一种卵巢癌新型荧光检测试剂。据称,该试剂可检测出1 mm以下的微小卵巢肿瘤。相关研究报告发表于不久前出版的英国《自然·通讯》杂志上。
在通过手术切除卵巢肿瘤时,如能切除1 mm以下的微小肿瘤,治疗效果将大幅提高。但是,医生很难将微小肿瘤与正常卵巢组织区分开来。东京大学浦野泰照教授等报告说,他们开发出一种名为“gGlu-HMRG”的荧光检测试剂。这种试剂本身无色透明,但其与卵巢癌细胞的β-半乳糖苷酶发生反应后,会发出强烈荧光。动物实验显示,在向患卵巢癌实验鼠的肿瘤部位喷洒这种荧光检测试剂后,数分钟内癌组织就会发出明亮荧光,肉眼便可观察到,分辨精度小于1 mm。研究人员以荧光为标记,成功切除了动物体内的肿瘤。
研究人员认为,由于检测时只需使用微量试剂,所以副作用很小。如果改善试剂使其能与其它酶结合,这种试剂还有望用于检测其它癌细胞。他们准备进一步验证这种试剂的安全性和精确性,争取3~5年内开展临床试验。
(仪器信息网)
甘肃加快检验检测认证机构整合
不久前,甘肃省整合检验检测认证机构工作领导小组第一次会议在兰州召开。会议审议了《甘肃省整合检验检测认证机构领导小组议事规则》《甘肃省整合检验检测认证机构指导意见》及庆阳产品质量检验检测中心、甘肃省特种设备检验研究集团和甘肃省建材研究设计院3家试点单位的整合试点方案。
副省长夏红民指出,各地、各有关部门、各行业要充分认识整合检验检测机构工作的重要性,在发展理念、体制机制创新、技术创新上有新突破,抓好整合试点工作。要落实整合检验检测认证机构各项工作任务,对检验检测认证机构的功能定位进行科学界定,抓紧制定检验检测认证机构整合实施方案,大力推动我省检验检测认证机构做强做大,切实深化检验检测认证机构体制机制改革。要加强组织领导,完善配套政策,清理地方法规,强化宣传引导,为做好检验检测认证机构整合提供必要保障。
(仪器信息网)
Similarity Retrieval Method of Organic Mass Spectrometry Based on the Pearson Correlation Coefficient
Li Hongbin, He Guangzhong, Guo Qiuting
(Institute of Medical Technology,Medical School,Xianyang Vocational and Technical College, Xianyang 712000, China)
A method for similarity evaluation of organic mass spectra based on the Pearson correlation coefficient was studied. With mass number as independent variable, abundance as the dependent variable, after certain data pretreatment process, the spectra of two compounds was transformed into two arrays, so that the spectrum correlation between two different compounds could be calculated with Pearson correlation coefficient. Pearson correlation coefficient method was used to calculate mass spectrum similarity between intra-group and inter-group of two groups organic material which has isomerism similarity and chemical structural similarity, the spectras between different groups showed very low correlation coefficient scores, so the Pearson correlation coefficient method was feasible to evaluate spectra similarity. Nonlinear transform of abundance could greatly improve the coefficient of variation of the algorithm and the efficiency of mass spectrum database search.
Pearson correlation coefficient; mass spectrometry; similarity retrieval
O657
:A
:1008-6145(2015)03-0033-05
10.3969/j.issn.1008-6145.2015.03.009
*咸阳职业技术学院2013科研基金项目(2013KYC05)
联系人:李宏彬;E-mail: leehbin@126.com
2015-03-16
