应用非参数项目反应理论模型分析人格量表*——以EPQ 个性问卷N 分量表为例
2015-12-27王晓洁张敏强简小珠蔡圣刚
王晓洁,张敏强,简小珠,蔡圣刚
(1.华南师范大学心理学院/心理应用研究中心,广州510631;2.井冈山大学教师教育研究中心,吉安343009;3.华南师范大学经济与管理学院,广州510631)
1 前言
1.1 项目反应理论和非参数项目反应理论在人格量表中的应用
项目反应理论(Item Response Theory,简称IRT)是相对于经典测量理论(Classical Testing Theory,简称CCT)而言的一种新的测量理论,它较多应用在成就测验中,而随着理论的发展,其应用领域已扩展到了人格量表。Roskam(1985)率先指出IRT项目参数在人格量表中的意义。随后,越来越多IRT 模型用于人格量表的研究,主要集中在量表的项目分析和记分解释方面,并将IRT 方法与传统的CTT 方法进行比较(Lange & Houran,1999;Rapson,2005;朱宁宁,张厚粲,2005;杨业兵等,2008)。Reise 和Waller(2003)对进行人格量表数据分析的IRT 模型选择进行了讨论。
这些研究都基于参数项目反应理论(Parametric Item Response Theory,简称PIRT),使用2PLM、3PLM或等级反应模型等PIRT 模型。近十年,有研究者开始关注项目反应理论中另一大分支——非参数项目反应理论(Nonparametric Item Response Theory,简称NIRT)在人格量表中的应用研究。Junker 和Sijtsma(2001)对非参数项目反应理论的使用提出三条理由:(1)为参数项目反应模型提供一种更深的理解;(2)为参数项目反应模型的局限性提出更适应更有弹性的框架;(3)为短量表和小样本提供比大样本测验更容易更准确的方法。
Chernyshenko 等人(2001)将NIRT 模型应用到人格量表中,他们分别用2PLM,3PLM,等级反应模型和NIRT 模型与16PF 和大五人格测验数据进行拟合比较,发现非参数模型与实际数据拟合最好。Meijer 和Baneke(2004)进一步探索应用NIRT 模型解释和分析人格量表,并与PIRT 模型比较。他们将MMPI-2 中的抑郁分量表与莫肯模型(Mokken Model)进行拟合分析,说明NIRT 模型易于应用并且能够避免PIRT 模型得到的错误结果。另外,NIRT 模型还常用于构建等级量表(Hierarchical scale)(Stewart & Watson,2010;Watson & Robert,2008)。
1.2 非参数项目反应理论模型介绍
Meredith 于1965 年将非参数模型引入项目反应理论中,Mokken(1971,1997)在此基础上将NIRT模型做了系统的阐述与研究,提出适用于二级记分项目的Mokken 模型。非参数项目反应理论的基本思想是:用被试在量表中的得分来对被试的潜在特质进行排序,而这样排序的结果与用被试的潜在特质排序的结果等效。与PIRT 模型不同,Mokken 模型不定义被试应答模式与潜在特质之间的函数关系。也就是说,当数据与Mokken 模型拟合时,只能得到被试潜在特质在此特质量尺上的位置信息,而不能得到被试潜在特质与项目参数的点估计值。
Mokken(1971,1997)提出两种模型——单调匀质模型(The Monotone Homogeneity Model,MHM)和双单调模型(The Double Monotonicity Model,DMM),DMM 比MHM 多了一个不变的项目顺序假设,可以认为DMM 是MHM 的特例。MHM 基于三个基本假设:(1)单维性,(2)局部独立性,(3)项目反应函数的单调性。如果一个数据集满足以上三个假设,就称其为Mokken 量表。
1.2.1 Mokken 模型拟合检验
在Mokken(1971,1997)模型中,适宜性系数H(Scalability coefficient)表示量表数据结构与期望量表结构的误差。适宜性系数有三种:由项目j 和项目k 组成的成对试题的适宜性系数Hjk、项目j 的适宜性系数Hj和整个量表适宜性系数H。分别定义如下:
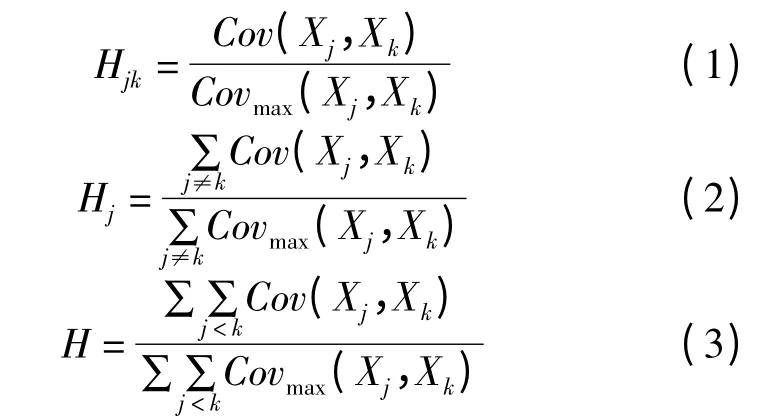
其中,Xj和Xk分别表示被试在项目j 和项目k上的得分,Cov(Xj,Xk)表示Xj和Xk的协方差,Covmax(Xj,Xk)为边缘分布情况下,项目j 和项目k的最大协方差。Mokken(1971)根据适宜性系数对Mokken 量表作出以下定义:(1)量表中所有项目对的协方差值或成对适宜性系数值为正,Cov(Xj,Xk)>0 或Hjk>0,j≠k,并且(2)所有的项目适宜性系数值大于或等于常数c,Hj≥c,0 <c <1。通常选择c=0.3。
适宜性系数不但是数据与模型拟合的指标,Hj也可作为项目j 的区分度指标,与Logistic 模型中的a 参数类似。Mokken(1986)和Koning(2002)等人指出H 值越高,根据量表总分对被试潜质进行排序就越有效。
单维性假设检验:自下而上的顺序选题过程(Bottom-up item selection procedure)是根据适宜性系数从题库中构建一个或多个单维量表的方法(Hemker,Sijtsma,& Molenaar,1995)。MSP5 软件提供了构建单维量表的自动选题程序(Molenaar & Sijtsma,2000)。Hemker,Sijtsma 和Molenaar(1995)根据模拟实验结果,建议用顺序选题法检验量表维度时,应选择不同的适宜性系数下限c 多次运行自动选题程序,并总结出判断量表维度的法则。
单调性假设检验:项目j 的单调性就是检验它的正向应答概率是否为潜质水平的非递减函数。可以在MSP5 中进行检验(Molenaar & Sijtsma,2000),其中每个项目的Crit 值作为单调性的指标,若Crit值超过80,则不满足单调性;若Crit 值在40 和80 之间,应根据项目内容和量表目的考虑是否保留;若Crit 值小于40,则认为它基本满足单调性,个别的违背单调性情况可视为被试抽样误差。
1.2.2 项目反应函数及特征曲线
在Mokken 模型中,通常使用核平滑方法估计项目反应函数(Item Response Function,IRF),它是一种非参数回归方法,基于局部加权的思想。通过TestGraf 软件能够得到各个项目在其余分数上的IRF 直观图示,即项目特征曲线(Item Characteristic Curve,ICC)(Ramsay,2000),其余分数指除被检验的项目外,其他项目的量表总分。Mokken 模型对IRT 没有特定形式,如Logistic 的要求,与实际数据吻合。
1.2.3 平均项目信息函数
TestGraf 提供了几种检验潜质测量准确性的方法,平均项目信息曲线是其中一种(Ramsay,2000)。二级记分项目的信息函数为

这里的潜质值θ 同样由其余分数代替。Pj(θ)使用核平滑方法计算,表示潜质为θ 的被试在第j 个项目选择1 时的概率。平均项目信息量越大,说明根据总分对被试潜质进行排序的结果越准确。同时,从平均项目信息曲线还可以得出量表测量特性信息。
1.3 研究目的
以艾森克个性问卷(Eysenck Personality Questionnaire,EPQ)中的情绪稳定性(N)分量表为例(龚耀先,1983),比较Mokken 模型及PIRT 模型与量表的拟合度、项目分析和测量准确性等结果,PIRT 模型选择2PLM 和3PLM。从而分析NIRT 模型用于人格测验分析的可行性、优势和适用性。
2 方法
2.1 测量工具及被试
选用龚耀先1983 年修订的艾森克个性问卷成人版(EPQ)中的情绪稳定性(N)分量表(龚耀先,1983),该分量表共有24 个项目。被试为来自广州某高校的1451 名在校大学生,其中男生799 人,女生652 人,平均年龄为19.49 ±1.03。所有被试完成EPQ 问卷所有88 个项目。
2.2 统计分析
使用MSP5 检验量表的单调性和单维性,并计算量表适宜性系数H 及各项目的适宜性系数Hj,使用TestGraf98 软件估计Mokken 模型下各项目的IRF 和平均项目信息函数,得到项目ICC 和平均项目信息曲线。PIRT 的参数值、及其ICC、测验信息曲线由MULTILOG7.03 估计得出,用BILOG3.0 计算实际数据与2PLM、3PLM 的拟合χ2值。为了验证MSP5 检验单维性的准确性,再使用SPSS15.0 对数据进行主成分分析。
3 结果
3.1 假设检验
3.1.1 单调性检验
首先在MSP5 中进行单调性检验,结果显示除项目27 外,其余23 个项目没有出现任何违背单调性的情况。项目27 的Crit = 26 ,小于40,那么可以认为它出现的个别违背单调性情况是由抽样误差引起的。经过检验,可以认为N 分量表中24 个项目全部满足单调性假设。而且所有项目的ICC 都是单调递减的,验证MSP5 检验单调性的准确性。
3.1.2 单维性检验
从c = 0.1 开始,由低到高选择不同的适宜性系数下限c,在MSP5 中多次运行自动选题程序来检验量表的单维性。结果显示,当下限c = 0.1 和0.2 时,得到相同的量表,所有项目都在这个量表中,没有项目被拒绝,量表的适宜性系数H = 0.33 。将下限提高到0.3 时,项目15、27、51、67、86 与其他项目不在同一量表中,得到19 个项目的量表,量表的适宜性系数H = 0.38 。而当c = 0.4 时,量表变为10 个项目,量表适宜性系数H = 0.44 ,并形成另外三个更小的量表,还有6 个项目被拒绝。根据Hemker 的经验法则(Hemker,Sijtsma,& Hamers,1995),可以将下限为0.2 或者0.3 时的量表作为最终结果,因此,情绪稳定性量表满足单维性假设。
应用SPSS15.0 对数据进行主成分分析,结果发现分量表第一和第二因子的负荷量分别为24.8%和5.5%,第一因子负荷量是第二因子的4.5 倍,而且碎石图的第一因子拐点明显,可以认为此分量表满足单维性要求。
3.2 项目分析
在Mokken 模型下,计算每个项目的适宜性系数Hj。估计被试在2PLM 和3PLM 中的参数值,并对所选Logistic 模型与实际数据的拟合性做χ2检验。所有结果见表1。
所有项目的Hj值在0.24 到0.44 之间,2PLM和3PLM 的a 参数值在0.82 到2.13 之间,都在正常范围内,说明所有项目都有较好的区分度。仔细观察Hj与2PLM 和3PLM 的a 参数值的关系,发现Hj与a 参数大小基本一致。Hj大于0.35 的项目,a参数值大多都在1.50 以上,Hj小于0.30 的项目,a参数值都在1.20 以下。而项目12、73 和82 不遵循此规律,项目12 的适宜性系数在24 个项目中最大,H12= 0.44 ,但是a 参数值却偏小,只有1.15 和1.18。项目82 类似,H82= 0.33 ,是中等水平,a 参数值在24 个项目中最小,为0.82 和0.83。
2PLM 与实际数据的χ2检验结果显示项目12、35、73 和82 与模型不拟合,3PLM 与实际数据的χ2检验结果显示除27、59、63 和74 项目外,其他均与模型不拟合,那么不适合用3PLM 分析N 量表。
单调性与单维性检验结果显示24 个项目都与Mokken 模型拟合,可以认为N 量表是Mokken 量表,H = 0.33 。
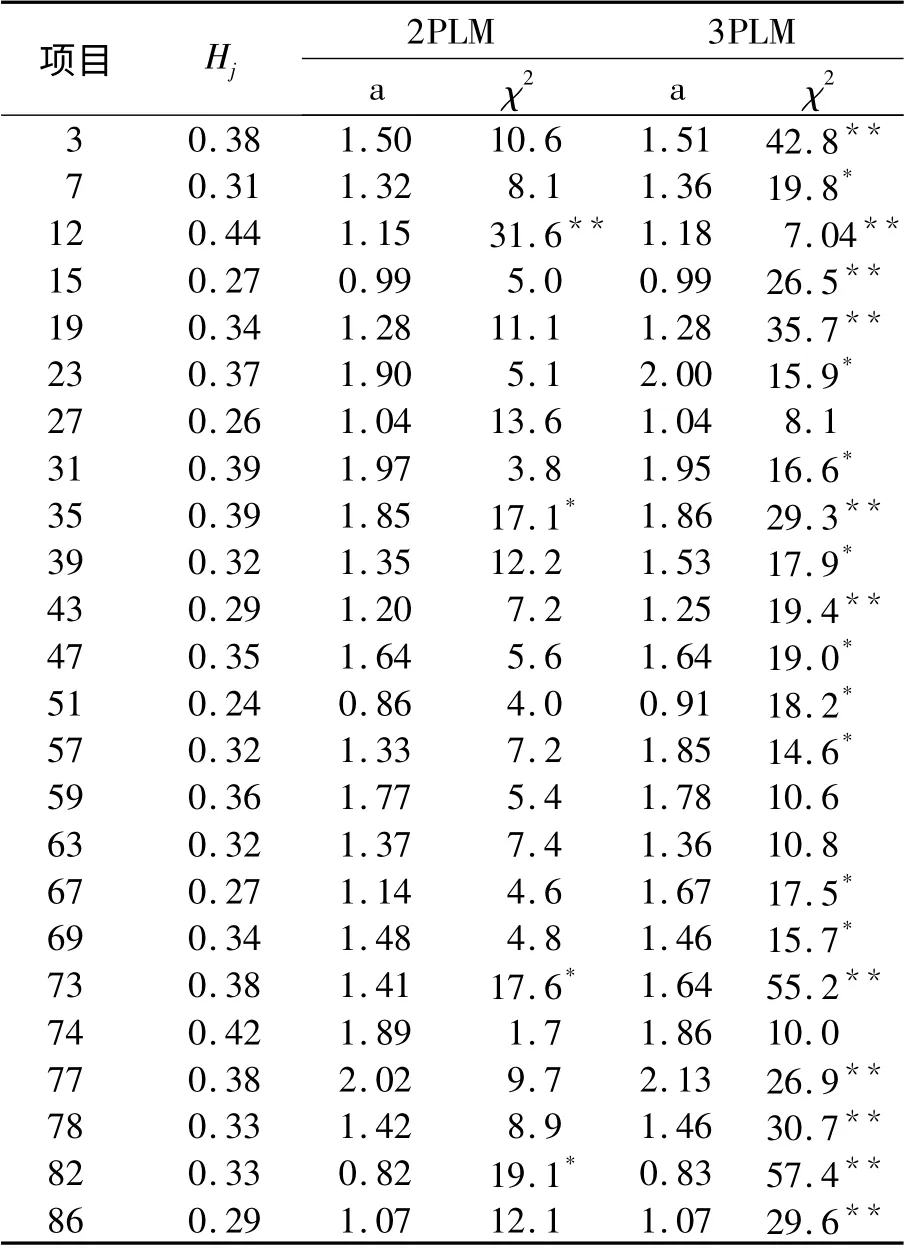
表1 N 量表各项目的Hj 及2PLM、3PLM 中的a 参数值
3.3 项目特征曲线
分别估计24 个项目在Mokken 模型和2PLM 下的ICC,由于TestGraf 得到的是选项特征曲线,而N量表为二级记分,所以图中有两条对称的曲线,标为1 的即为该项目的特征曲线。对比两种模型下的ICC,结果发现大部分项目在两个模型中的ICC 图非常接近,而4 个与2PLM 不拟合的项目在两种模型下的ICC 差异较大,尤其是项目12 与82。图1给出这两个项目的ICC 图,在Mokken 模型下的ICC不符合Logistic 形态,见图1a,它们的曲线在低分段急剧上升,高分段变化平缓,项目12 选择1 的概率范围在0 到0.9 之间的被试其余分数约为0 到8,项目82 选择1 的概率范围在0 到0.9 之间的被试其余分数约为0 到10。这说明它们能够较好区分中低分被试,而且区分度较高,特别是项目12,H12=0.44 。如果用2PLM 的ICC 分析这两个项目,见图1b,则在低分段急剧上升的趋势不明显,不能反映数据的真实情况,从而得出这两个项目区分度不高的错误结果。
从这两个项目看出,采用与数据不拟合的模型分析项目会得出错误结果。如果删除又错过有用信息,因为这些项目本身可能有应用价值。如项目12 与82 相比其它项目能够更有效地区分中低分被试。
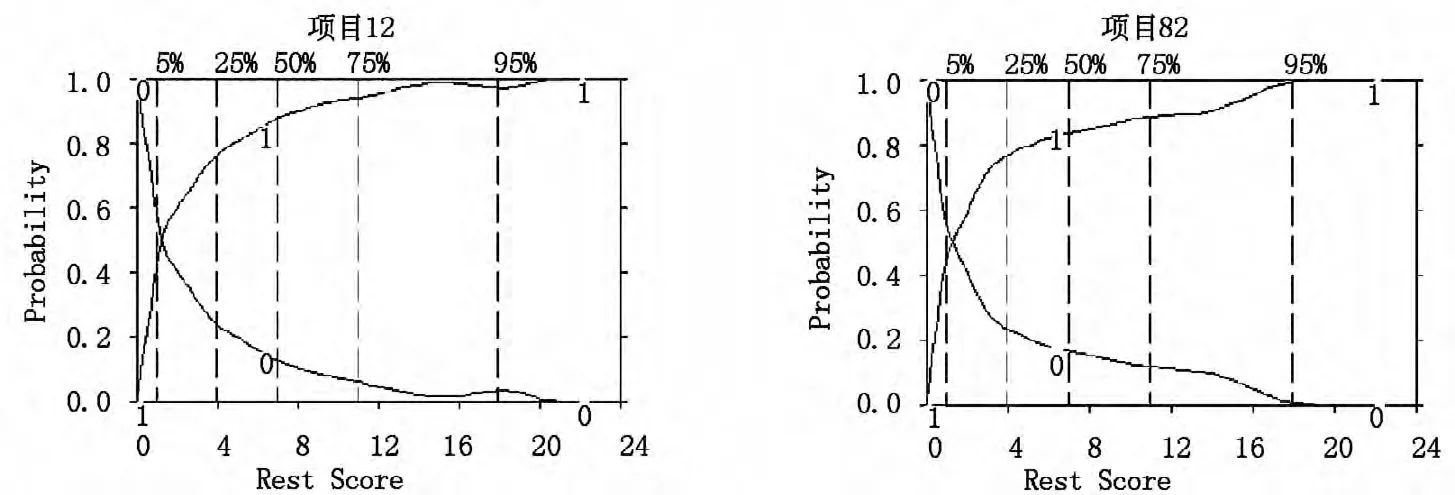
图1a 项目12、82 在Mokken 模型下的ICC
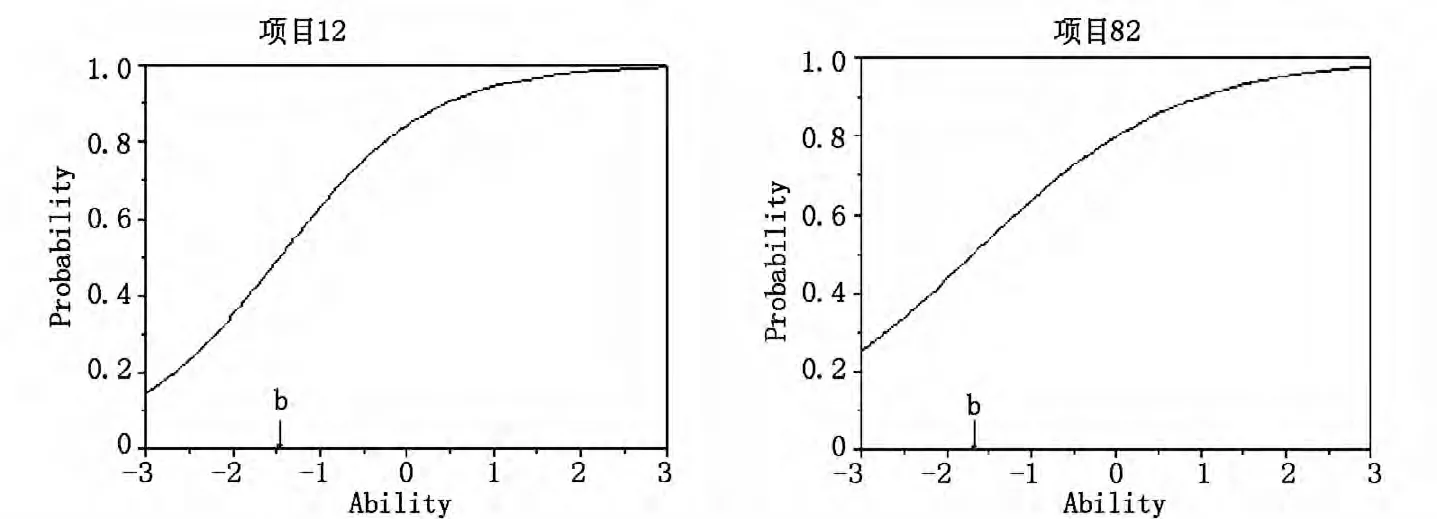
图1b 项目12、82 在2PLM 下的ICC
3.4 测量准确性
个不拟合项目,剩余19 个项目的平均项目信息曲线。图2c 和2d 分别是2PLM 中,24 个项目和删除4 个不拟合项目后的测验信息曲线。
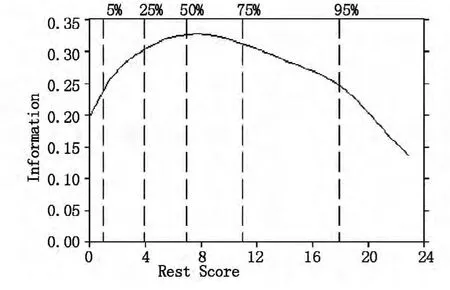
图2a Mokken 模型下24 个项目平均项目信息曲线

图2b Mokken 模型下19 个项目平均项目信息曲线
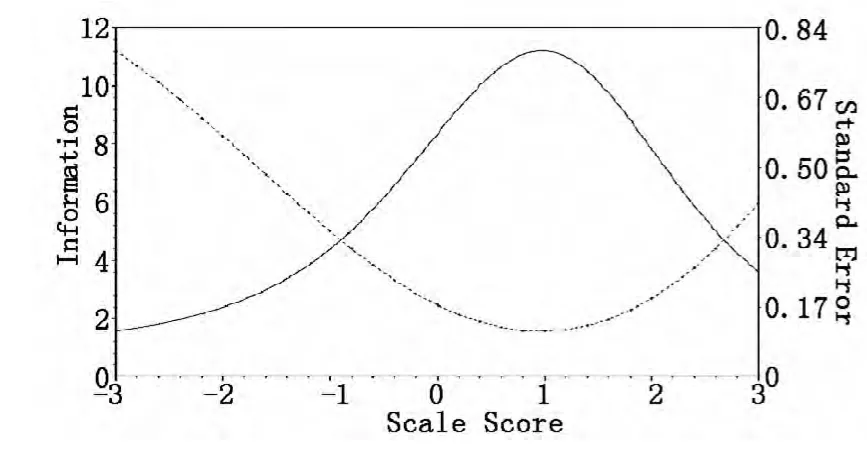
图2c 2PLM 中24 个项目测验信息曲线
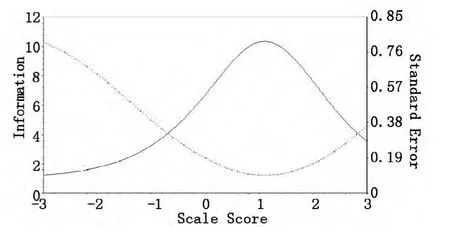
图2d 2PLM 中20 个项目测验信息曲线
从图2a 中看出,量表其余分数为2 到18 的被试提供了较大的信息量,对于中低分的被试根据量表总分对情绪稳定性排序的结果较准确。其中被试其余分数为7 或8 分时,项目的平均信息量最大约为0.32。而删除项目15、27、51、67、86 后,平均项目信息量有所提高,为0. 40 左右,增量大约为0.080。N 量表在2PLM 下,测验最大信息量为11.21,最大平均项目信息量是0.47。删除不拟合的4 个项目,其余20 个项目的测验最大信息量为10.3,最大平均信息量增加到0.51,增量是0.045。从中可以看出,虽然在Mokken 模型中测量准确性不如2PLM 高,但也在可接受范围内,说明按照量表总分对被试潜质进行的排序是较准确的。而且高Mokken 模型拟合标准,使量表平均项目信息量的增量比2PLM 删除不拟合项目增加的平均项目信息量大0.035,差异较明显。那么根据Mokken 模型的拟合程度鉴别删除性能不好项目比PIRT 模型拟合检验更加准确有效。
4 讨论
文中展示NIRT 模型如何用于分析人格量表,并与PIRT 模型量表拟合性和项目分析结果做比较,从中总结出NIRT 模型用于人格测验的优势和适用性。
4.1 NIRT 模型用于人格测验的优势
第一,NIRT 模型基于弱假设,容易与数据拟合。只要符合单调性与单维性假设的项目都可以用NIRT 模型分析,而PIRT 模型要求数据较严格,没有拟合特定形式参数模型的项目就要被删除,但是这些项目可能在某些特定潜质水平或特定样本上仍然是有用的(Meijer,& Baneke,2004)。NIRT 模型可准确地分析这些项目性能。
第二,NIRT 模型比PIRT 模型灵活,更贴近实际数据。PIRT 模型限制项目的IRF 符合Logistic 形式,可能导致研究者无从获得贴近实际数据的项目IRF,而偏离了真实情况。NIRT 模型对项目IRF 没有特定形式的要求,完全根据实际数据获得,可能是任何形式,相比PIRT 模型更加灵活。而人格测验的反应模式复杂多样,需要应用灵活的NIRT 模型使研究者了解更多更加贴近实际情况的信息。
第三,可根据NIRT 拟合程度构建准确有效短量表。人格量表的项目一般较多,在特定情况下需要使用较短量表施测,那么提高NIRT 模型拟合标准删除不拟合项目可以构建测量准确有效的短量表。如研究中将下限提高到0.3 时,得到19 个项目的量表,平均项目信息量明显提高。若需要更短的量表,那么0.4 的下限可构建10 个项目的N 量表。PIRT 模型删除不拟合项目后,平均项目信息量提高较小。这说明与PIRT 模型不拟合的项目并不是性能最差项目,那么根据PIRT 模型拟合性构建短量表不够准确有效。
第四,NIRT 模型原理简单易懂。为了准确反映人格量表项目存在非0 下渐近线和非1 上渐近线现象,Reise 和Waller(2003)提出使用4PLM。然而PIRT 模型本身算法复杂,将参数增加到4 无疑更加难以理解,参数估计也更加难以实现。很多研究者已经强调过进行数据推断或检验假设时使用的模型越简单和越灵活越好(Junker & Sijtsma,2001;Santor &Ramsay,1998)。Mokken 模型建立在协方差和非参数回归技术之上,这些方法都简单易懂,而且MSP5 软件和TESTGRAF98 软件操作方便,易于掌握。
4.2 NIRT 模型用于人格测验的适用性
综上所述,NIRT 模型以及它相关的分析技术非常适用于人格量表分析。然而,并不是说用NIRT模型替代PIRT 模型进行所有人格量表分析。毕竟NIRT 模型存在最大的一个弊端就是只能根据被试在量表上的总分,对潜质特质进行排序,而不能直接估计被试潜质数值,因此测量准确性比PIRT 模型稍差。那么,必须要考虑NIRT 模型分析人格量表的适用性。
第一,NIRT 模型可作为PIRT 模型的补充。若要使用PIRT 模型,如2PLM、3PLM 分析或构建人格量表时,可以在之前进行NIRT 模型分析。将其作为检验单调性、单维性假设的方法。更重要的是NIRT 模型得到的贴近实际数据的IRF 可以作为判断选用哪一种PIRT 模型研究数据,和对项目进行初步分析的依据。
第二,NIRT 模型可作为PIRT 模型的替代模型。如果研究数据与PIRT 模型拟合较差,此时可以用NIRT 模型完全替代PIRT 模型进行数据分析。
第三,NIRT 模型可用于构建人格量表维度。常用的人格量表一般都是以某种人格理论为基础,根据不同的潜质特质分为几个不同维度的分量表,那么NIRT 单维性检验的选题策略就尤其有用。
5 结论
N 量表与Mokken 模型完全拟合,与2PLM 有4个项目不拟合,而不拟合项目用Mokken 模型分析比2PLM 模型准确,根据NIRT 模型拟合程度删除项目后,平均项目信息量的增量明显高于根据2PLM拟合程度删除项目后的增量。NIRT 模型适用于人格测验,优势体现在比PIRT 模型易与数据拟合且更加灵活,有效构建短量表,原理简单易懂。人格测验研究中,NIRT 模型可作为PIRT 模型的补充和替代模型,也可作为构建量表维度的方法。
6 研究展望
Molenaar(2001)指出,NIRT 中的MSP5 等分析过程可以使数据得到充分的利用,从而与短量表或小样本数据拟合。也就是说NIRT 模型适用于小样本的数据,而PIRT 模型需要较大的样本量,当人格量表样本量较小时,NIRT 模型如何体现出相对PIRT 模型的优势可作为以后的研究方向。
龚耀先.(1983).修订艾森克个性问卷手册.长沙:湖南医学院.
杨业兵,苗丹民,等. (2008). 应用项目反应理论对《中国士兵人格问卷》的项目分析.心理学报,40(5),611 -617.
朱宁宁,张厚粲.(2003).CTT 与IRT 方法对人格量表结果处理的比较研究.心理学探新,23(3),48 -51.
Chernyshenko,O.S.,Stark,S.,Chan,K.,et al. (2001).Fitting item response theory models to two personality inventories:Issue and Insight.Multivariate Behavioral Research,36(4),523-562.
Hemker,B.T.,Sijtsma,K.,& Molenaar,I. W. (1995). Selection of unidimensional scales from a multidimensional item bank in the polytomous Mokken IRT model. Applied Psychological Measurement,19(4),337 -352.
Junker,B. W.,& Sijtsma,K. (2001). Nonparametric item response theory in action:An overview of the special issue.Applied Psychological Measurement,25(3),211 -220.
Koning,D.E.,Sijtsma,K.,& Hamers,J.H.M.(2002).Comparision of four IRT models when analyzing two tests for inductive reasoning. Applied Psychological Measurement,26(3),302 -320.
Lange,R.,& Houran,J.(1999).Scaling MacDonald’s AT-20 usingitem -response theory.Personality and Individual Differences,26,467 -475.
Meijer,R.R.,& Baneke,J.J.(2004).Analyzing psychopathology items:A case for nonparametric item responsetheory modeling.Psychological Methods,9(3),354 -368.
Mokken,R.J.(1971).A theory and procedure of scale analysis.The Hague,The Netherlands:Mouton.
Mokken,R. J. (1997). Nonparametric models for dichotomous responses. In W. J. van der Linden & R. K. Hambleton(Eds.),Handbook of modern item response theory(pp.351 -367).New York:Springer-Verlag.
Mokken,R. J.,Lewis,C.,& Sijtsma,K. (1986). Rejoinder to“The Mokken scale:A critical discussion”. Applied Psychological Measurement,10(3),279 -285.
Molenaar,I.W.(2001). Thirty years of nonparametric item response theory. Applied Psychological Measurement,25(3),295 -299.
Molenaar,I. W.,& Sijtsma,K. (2000). MSP5 for Windows,a program for Mokken scale analysis for polytomous items.Groningen,The Netherlands.
Ramsay,J.O. (2000). TestGraf. A program for the graphical analysis of multiple-choice tests and questionnairedata.McGill University.
Rapson,G. (2005). An item response theory analysis of the Carver and White(1994)BIS/BAS Scales.Personality and Individual Differences,39,1093 -1103.
Reise,S. P.,& Waller,N. G. (2003). How many IRT parameters does it take to model psychopathology items?Psychological Methods,8(2),164 -184.
Roskam,E. E. (1985). Current issues in item responsetheory:Beyond psychometrics. In E. E. Roskam(Ed.),Measurement and personality assessment(pp.3 -19). Amsterdam:Elsevier Science.
Santor,D.A.,& Ramsay,J.O.(1998).Progress in the technology of measurement:Applications of item response models.Psychological Assessment,10(4),345 -359.
Stewart,M.E.,Watson,R.,Clark,A.,et al. (2010). A hierarchy of happiness?Mokken scaling analysis of the Oxford Happiness Inventory. Personality and Individual Differences,48,845 -848.
Watson,R.,Roberts,B.,Gow,A.,et al.(2008).A hierarchy of items within Eysenck’s EPI. Personality and Individual Differences,45,333 -335.
