分步增值评分——提高主观题评分质量的有效方法
2015-12-27刘斯佳张建新
刘斯佳,张建新
(1.中国科学院心理研究所,北京100101;2.中国科学院大学,北京100049)
1 问题的提出
1.1 主观题评分中存在的问题
主观题包括简答题、论述题、应用题、作文题等。相对客观题,主观题能更为真实地反映考生的能力,因此被广泛运用于人员选拔考试和语言类考试中,对人员的录用和筛选具有重要的现实意义。然而,主观题评分的客观性和有效性却不容乐观(关丹丹,2008)。前期研究发现甚至某国家级考试论述题依然存在评分员宽严程度异常的现象(李中权,孙晓敏,张厚粲,张立松,2008)。作文题作为一种复杂主观题型,其误差控制问题相较其他类型的主观题型更为棘手,也更早受到研究者关注(刘远我,张厚粲,1998)。有研究发现,评分员对作文评分宽严程度同样存在着显著差异(刘红云,陈阅,骆方,王云峰,2010)。
主观题评分的信度受到许多因素影响,包括题目难度、评分程序复杂程度、评分者间差异等等。有作者指出评分者误差复杂性最高(王博,卞冉,车宏生,王蓉,2012)。评分者因为不能很好地掌握评分标准,造成他们在评分过程中认知负荷过大,对不同等级评分标准认识模糊,从而扩大了评分误差;另一方面,为了减少认知负荷,评分者可能形成保守的打分策略,使考生评分结果难以进行区分(Gilfert &Harada,1992)。王博等(2012)对某大型人事考试评分分析中,首次描述了保守现象的“习得”过程。可以预见的是,作文的评分过程可能存在更为严重的失真现象。因此,在有效评价主观评分误差的基础上,有必要通过优化评分流程来降低作文评分的误差程度。
1.2 分步增值评分模式
在此背景下,国外研究者提出了分步增值评分模式(rating augmentation)以进行有效的流程控制(Johnson,Penny,& Gorden,2000)。王博等(2012)在国内首先对这种评分模式进行了介绍。分步增值评分模式首先在较为宽泛的档位上(bench mark)对试卷进行打分,比如1 至4 档;然后评分者通过附加分数对试卷倾向性(lean)进行评估,以“+”“-”进行表示;最后分数通过统一算法转化为数值,形成考生的原始成绩。这种方式可以帮助评分者确保评分成绩的一致性和区分性。分步增值评分模式近期在国外的作文评分和言语类考试评分中得到了较为广泛的应用(如Penny & Johnson,2011;Morgan,Zhu,Johnson,& Hodge,2014)。然而对中文数据库搜索之后,尚未发现分步增值评分模式的实证研究。
1.3 评分模式的量化考察
在另一个方面,如何选择方法更好地量化主观题的评分评价也是需要考虑的一个问题。关丹丹(2008)认为项目反应理论对于主观题的评分评价具有较明显的优势,并且特别对多面Rasch 模型(MFRM)进行了介绍。MFRM 是项目反应理论的衍生模型,可以很好地量化主观题的区分度以及评分者评分时的宽严程度和偏差程度,MFRM 模型在往期研究中较为常见(李中权等,2008;刘红云等,2010)。本文主要旨在通过MFRM 模型,分别考察传统综合评分模式和分步增值评分模式对于评分结果的区分度以及评分者的评分宽严程度和偏差程度;另外,通过引入专家评分,并假定其为评分的真分数后,进而考察综合评分模式和分步增值评分模式的误差程度;最后,通过评分用时来描述两种评分模式的评分效率。研究假设相对于综合评分模式,分步增值评分模式对评分结果的区分度更好、评分者在评分偏差程度指标上的表现更加理想,并且可以提高评分效率。
2 研究设计
研究抽取某国家级大型考试的实测作文题答卷500 份作为样本。挑选20 名评分经验在三年以上的评分者参与评分。评分种类包括了传统评分使用的综合评分模式,以及上述介绍的分步增值评分模式。其中,综合评分模式由6 名评分者参与评分,而分步增值评分模式由其余14 名评分者参与评分。在评分之前,首先对评分者进行集中培训,让所有评分者了解作文题评分的要求和标准(见表1)。而参与分步增值评分模式的评分者则附加培训了分步评分过程中的等级、档位和倾向(即“+”、“-”)标准(见表2)。评分者分为综合评分组和分步评分组,他们的评分过程在下文中详细介绍。

表1 综合评分法的评分标准
综合评分组:随机选择6 名评分者采用双评方式独立对500 份试卷进行评价,要求评分者按照表1 中的分制直接给考生打分。如果两名评分者的评分结果超出误差允许范围,则要求第三名评分者进行评分。考生的最终成绩取自两名评分者评定成绩的平均值,或者第三名评分者和与其评分最接近的评分成绩的平均值。
分步评分组:评分过程共分两个阶段。第一阶段随机选择4 名评分者对500 份试卷参照表1 中的等级标准进行定级工作;第二阶段,对已经定好等级的试卷,在每个等级内再分为三档,评分者对照各等级内挑选的档位标杆卷进行归档,归档原则是判断当前试卷水平与哪份档位标杆卷水平更为接近;评分者从整数水平对文章进行归档后,还须进一步指出文章是否有必要通过“+”和“-”进行额外评分。如果标记“+”,则代表比标杆卷的能力水平要高;反之则要低(见表2)。评分者按照等级评分结果分成了四种类型,其中1 类卷(8.3%)每组由2 人评分,2 类卷(58. 2%)每组由3 人评分,3 类卷(30.5%)每组由3 人评分,4 类卷(3.0%)每组由2人评分。上述两阶段均采用评分者独立评分的双评方式。

表2 分步评分分数转换对应表
需要说明的是,在分步评分中,对于第一阶段评分者12 评给出等级不一致的情况,先保留各自评判等级到第二阶段,在第二阶段分别在不一致的等级上再进行双评,即在定档阶段会出现12 评和1234评两种情况。这么处理是因为,对于大多数判等不一致卷而言,由于有可能试卷本身就处于等级临界水平上下,如果第二阶段定档时各评分者分歧不大,且所给出的档位也在这个临界点附近,第一阶段定级的不一致就是可以接受的。另外,在第二阶段如果认为待评卷定级不够准确,可以做出“裁定”操作,不再进行归档,重新回到第一阶段进行定级工作。
3 研究结果
3.1 评分等级不一致性
对两种评分模式下的评分结果进行等级不一致分析。其中综合评分组不一致评分卷数为177 份(占35.40%),分步评分组不一致评分卷数为185 份(占37.00%)。两种评分模式下评分不一致情况没有显著差异(χ2=0.22,p=0.64,odds ratio=1.03)。
3.2 评分成绩水平分布

图1 综合评分组及分步评分组评分成绩的直方图和密度线
如图1 所示,综合评分组的评分成绩(M =27.91,SD =3.92)相比分步评分组的评分成绩(M=24. 14,SD = 6. 18)偏高,t(998)= 11. 51,p <0.001。并且综合评分的峰度(Kurtosis=5.31,SE=0.22)相对分步评分的峰度(Kurtosis = -0.12,SE =0.22)更高,因此成绩相对更为集中。另外,综合评分的偏度(Skewness = -1.47,SE =0.11)相比分步评分(Skewness= -0.28,SE =0.11)显示出更高的负偏态趋势。另外,相比综合评分组12 评的相关性(r=0.67,p <0.001),分步评分组12 评的相关性更高(r=0.76,p <0.001)。并且,以1 评作为因变量,一般线性模型发现2 评成绩 × 组别(综合、分步组)的交互作用显著,F =33. 26,p <0. 001,η2=0.59,说明两组相关系数大小存在显著差异。
3.3 评分成绩的多面Rasch 模型分析
使用Facets 3.71.4 学生版对两种评分模式下的平均评分结果进行多面Rasch 模型分析。首先将两种评分模式成绩划分为12 个档位,通过概率曲线进行描述。理想情况下,概率曲线的峰值在每个档位的分布比较均匀,如果概率分布过高或过低则表明档位较难以区分。从图2A 的档位概率曲线可见综合评分成绩在低档位较难区分,然而分步评分成绩的概率曲线相比较综合评分却较为均匀。将12个档位归并成6 个分数段之后,结果显示分步评分成绩的概率曲线依然较为理想(见图2B)。
继而对评分者的宽严程度、偏差程度以及区分度进行分析(Linacre,2014)。分析选取综合评分1评成绩和分步评分第二步1 评成绩作为因变量,考察各自1 评评分者的宽严程度、偏差程度和分数的区分度。由于在分步增值评分模式中,每个评分者分别对某一等级的答卷进行评分,故被给予高分答卷的评分者在宽严程度的结果上自然会“更高”或“更低”,因此并不能有效评定评分者的宽严程度,因此本研究只对综合评分组评分者的宽严程度进行分析。结果如表3 所示。
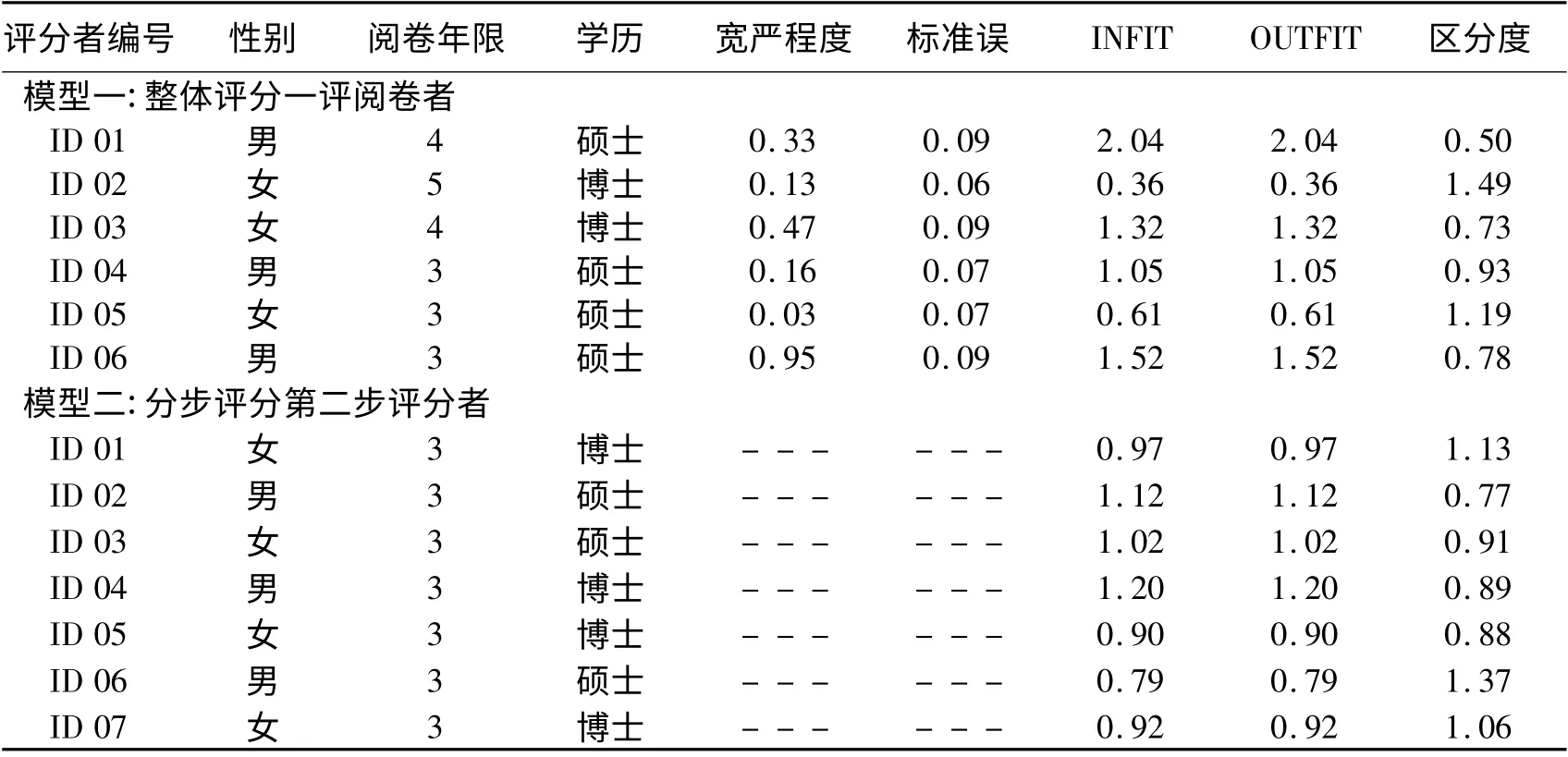
表3 评分者的宽严程度、偏差程度以及区分度

续表3
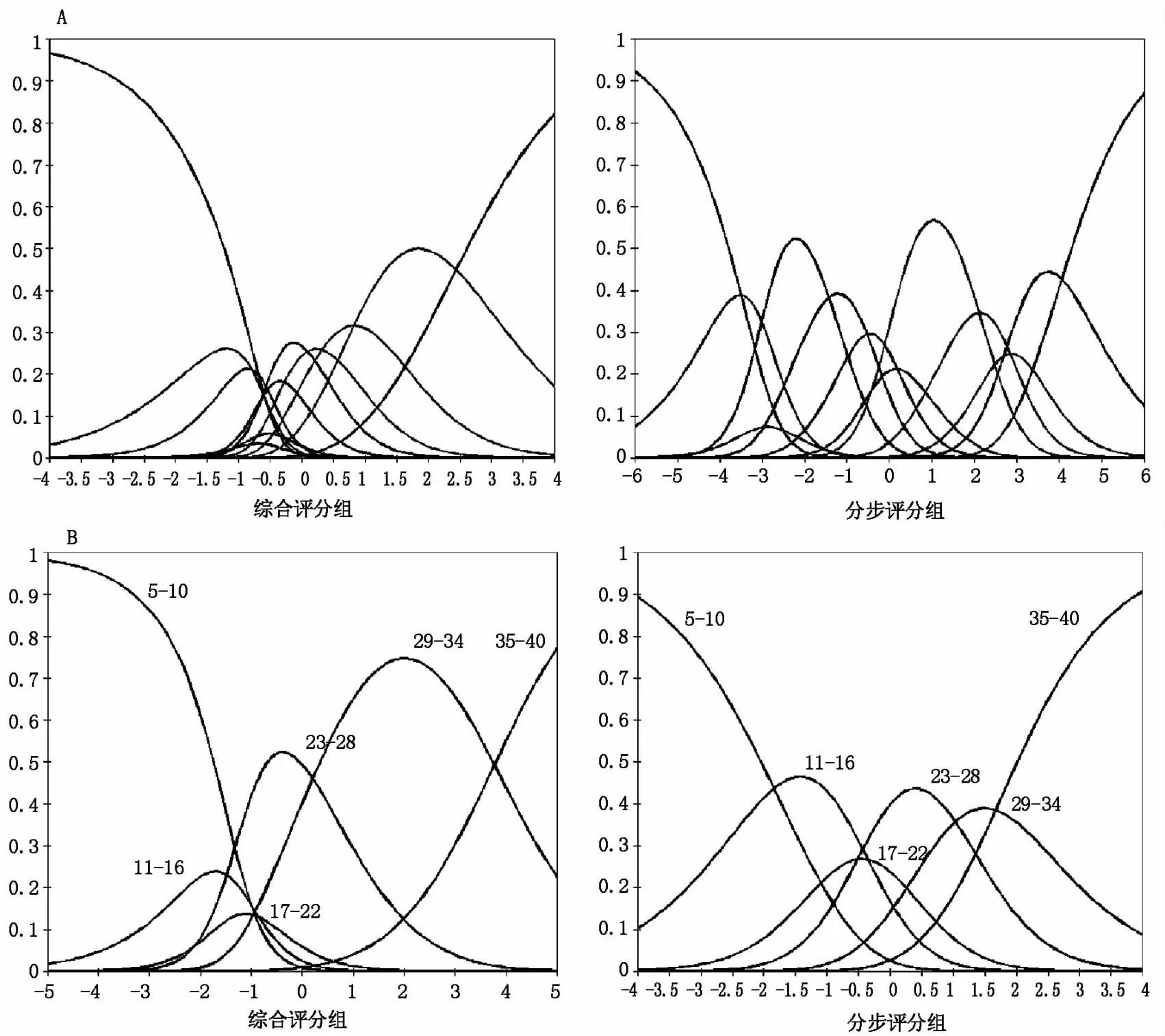
图2 不同评分成绩层次的概率曲线
宽严程度指标(severity estimate)是对某个评分者总体对评分是否呈现偏低或偏高的趋势(大于0为评分宽松,反之亦然),而宽严程度所对应的标准误可以判断评分的稳定程度。从表3 中的宽严程度指标来看,所有综合评分组评分者在这个指标的分值都为正,因此说明评分存在过于宽松的现象。
偏差程度,或偏差诊断指标(misfit diagnosis)由OUTFIT 和INFIT 卡方指标来进行评价。其中,OUTFIT 对位于两端的成绩比较敏感,而INFIT 则对所有成绩等级中存在的偏差现象比较敏感,可以诊断成绩中不可预期的复杂特性。如果OUTFIT 和INFIT 分数在0.5 和1.5 之间,则说明成绩比较合理;如果分数高于1.5,则说明在某个成绩段上存在评分偏差,而如果分数低于0.5,则可能说明评分者没有用所有的分数段进行评分。结果显示,综合评分组评分者ID 01 和ID 06 的偏差程度超出了可接受的范围,说明评分偏差过高;而评分者ID 02 的偏差没有达到可接受的范围,说明可能没有使用所有的评分段来进行评分。相比之下,分步评分组评分者的评分结果却没有出现评分偏差过大或过小的现象。
区分度(item discrimination)考察的是考生的评分成绩相对于理想的区分度之间的偏差程度。区分度越接近1 越好,表明成绩的区分与档位相符合,大于1 则说明在某些成绩上的区分度比预期更高,相比合理区分度打分更为细致;而小于1 则说明在某些成绩上的区分度比预期更低,相比合理区分度打分较为粗疏。结果显示,综合评分组评分者的评分成绩的区分度较1 的偏差(M =0.29,SD =0.17),相比分步评分组偏差更大(M =0.15,SD =0.10),Cohen’s d=1.15,达到高差异水平。
3.4 评分成绩的误差分析
为了进一步探究两种评分方法在评分效果上的差异,研究选取了不同评分方法下最终成绩争议较大的试卷进行评分准确性分析。在挑选争议卷时,选取两种评分方法最终得分差值在8 分以上的试卷共94 份,由专家先进行评定。一般认为,主观阅卷双评的评分差值阈限在满分的20%以内是可接受的。专家阅卷时,并没有限定具体的评分方式,而是让专家根据自己的评分习惯进行评分。假定专家评分结果为真分数,分别计算综合评分组和分步评分组成绩和专家评分的差异,并且再由分步评分组挑出1 评成绩作为比较,其差值视为评分误差。
结果发现,综合评分组的误差值最高(M=7.11,SD=2.53),分步评分组(M=3.22,SD=2.34)和分步评分组1 评误差值较小(M=3.51,SD=2.95)。三组间的差异显著(F=64.12,p <0.001,η2=0.32),而事后检验发现综合评分组和分步评分组(MD =3.88,p<0.001,Cohen’s d =0.20)以及分步评分1 评成绩(MD=3.59,p <0.001)的差异均显著,然而分步评分组和分步评分1 评成绩之间的差异却不显著(MD =0.29,p=0.73,Cohen’s d=1.71)。
3.5 评分效率分析
实验中,对评分者的评分时间进行了测量。由于评分时间记录了装订了10 至20 份试卷的试卷本为单位,通过求平均计算了在某个试卷本中试卷评分的平均时间;另外,分步评分组试卷在第二阶段进行了不同等级的汇总,因此可以相应地计算出每个等级卷本的评分时间,并与第一阶段相应的试卷评分时间进行求和;最后求得500 份试卷在综合评分组12 评、分步评分组12 评和分步评分1 评中所用的总评分时间进行比较。
结果发现,综合评分组的平均用时(秒)较短(M=112.20,SD=23.31),分步评分组的平均用时较长(M=169.49,SD =26.89),而分步评分1 评的总评分时间却比综合评分12 评所用的总时间更短(M=91.68,SD=19.59)。三组间的差异显著(F =1478.82,p <0.001,η2=0.66),而事后检验发现综合评分组评分效率比分步评分组更高(MD=57.29,p <0.001,Cohen’s d =0.60),但却不如分步评分1评(MD= -20.52,p <0.001,Cohen’s d=0.17)。
4 讨论
4.1 主观题的评分误差问题
实证结果显示,作文题成绩的确存在大量评分等级不一致情况。这样的结果和往期作文题或其他主观题成绩研究结果是相互吻合的(关丹丹,2008;刘远我,张厚粲,1998;刘红云,陈阅,骆方,王云峰,2010)。这说明虽然主观题能更好地反映考生能力,然而对主观题评分进行控制存在问题。刘红云等(2010)通过多面Rasch 模型对作文综合评分模式下评分者的宽严程度和区分度进行了量化分析,然而现在尚没有探讨作文评分模式的其他实证研究文献。
4.2 分步增值评分模式的优越性
通过引入分步增值评分模式进行流程控制(王博等,2012),我们发现分步评分组相对于传统综合评分组的评分分布情况确实存在一些优越性,并且12 评的一致性程度也更高。概率曲线结果进一步表明,分步评分相较于综合评分的平均值在不同难度上区分程度更好。这样的结果说明,分步增值评分模式是一种有价值的尝试,或许可以有效解决主观题(特别是作文题)中的评分质量问题。
从各个评分者评分宽严程度、偏差程度和区分度的角度而言,分步评分组相较于综合评分组同样更加优越,而综合评分组某些评分者的偏差程度指标则出现过高或过低的异常现象,说明存在评分不稳定或者某些分数段数值太少的不利现象。因此,分步增值评分模式不仅对于总体评分成绩有积极影响,对评分者导致评分成绩差异的现象或许也可以起到良好的控制作用。然而,为何分步评分组相比综合评分组在评分者的偏差程度和区分度层面有更好的控制作用呢?这样的差异或许来自于主观题考试对评分尺度的选择层面。
值得注意的是,我国国家级作文题一般采用15分以上的大量尺评分量表。而陈睿(2011)、关丹丹等人(2011)的实证研究认为大尺度评分量表下评分者间的一致性有待提高。在保持大尺度评分的前提下,分步增值评分模式将难以区分的评分标准细化成可控制的等级和档位尺度,将大尺度评分化简为不同阶段的小尺度评分。如同王博等(2012)文中的介绍,我们的研究结果证实分步评分优化了评分流程且提高了作文评分的质量;而评分成绩分布的合理性以及对评分者差异性的降低,或许来自对大尺度评分认知负荷和保守打分策略的有效控制(Gilfert & Harada,1992)。
4.3 分步增值评分模式的实用性
在评分的实用性方面,研究抽取了分步评分1评和综合评分12 评的情况进行比较。结果发现分步评分1 评比综合评分12 评的误差程度还要低,而分步评分1 评和分步评分12 评的误差程度却不存在显著差异。然而分步评分单评所用的时间却要比综合双评所用的时间更短。因此,分步增值评分模式不仅是一种更为准确的评分方式,还是一种更为经济有效的评分策略。
5 研究结论
虽然主观题(特别是作文题)总是存在着评分不一致的问题,然而分步增值评分模式能够有效的控制评分的质量问题。这种新的评分模式相对于传统综合评分模式的优越性表现在评分成绩分布的合理性以及对评分者差异有效控制这两个层面。其次,分步增值评分模式不仅能降低评分成绩的误差,还能有效提高评分程序的效率,或许可以视为一种更为实用的评分模式。
6 不足及建议
研究中抽取了500 份作文主观题答卷,未来可以抽取样本量更大的答卷来进行分析,并且分别对不同类型主观题评分成绩的情况进行分析。后期访谈中,笔者发现部分评分者对定级和定档的标准有时把握不准,也就是在相邻等级或相邻档位水平的试卷评定上有时把握不太稳定。如何更好地规范评分者评分的准确性也是未来流程设计需要改进的方向。另外,研究中的评分时间以装订试卷本为单位,未来研究或许可以通过网络评分手段,对每一份试卷的评分时间进行单独测量。最后,本次研究并没有对评分过程中的认知加工过程进行深入分析。通过引入与认知加工能力相关的行为测试,或许可以更好地考察认知个体差异对试卷评分的影响情况。
陈睿.(2011).国内外写作评分量表的对比研究.考试研究,6,59 -67.
关丹丹,陈睿,张开,赵静宇. (2011). 两种评分量表的评分效应比较研究.教育研究与实验,4,92 -96.
关丹丹.(2008). 主观题评分质量的估计方法评述.中国考试,10,52 -55.
李中权,孙晓敏,张厚粲,张立松.(2008).多面Rasch 模型在主观题评分培训中的应用.中国考试,1,26 -31.
刘红云,陈阅,骆方,王云峰. (2010). 学业水平测试中作文评分误差的多面Rasch 分析.心理科学,33(4),925 -927.
刘远我,张厚粲. (1998). 概化理论在作文评分中的应用研究.心理学报,30,211 -218.
王博,卞冉,车宏生,王蓉. (2012). 主观评分保守现象的形成机制与控制研究.心理学探新,32(5),429 -438.
Gilfert,S.,& Harada,K. (1992). Two composition swcoring methods:The analytic vs. holistic method. Bulletin of Faculty of Foreign Languages,1,17 -22.
Johnson,R. L.,Penny,J.,& Gordon,B. (2000). The relation between score resolution methods and interrater reliability:An empirical study of an analytic scoring rubric.Applied Measurement in Education,13,121 -138.
Morgan,G. B.,Zhu,M.,Johnson,R. L.,& Hodge,K. J.(2014). Interrater reliability estimators commonly used in scoring language assessments:A monte carlo investigation of estimator accuracy.Language Assessment Quarterly,11,304 -324.Penny,J. A.,& Johnson,R. L. (2011). The accuracy of performance task scores after resolution of rater disagreement:A Monte Carlo study.Assessing Writing,16,221 -236.
