基于扩展主题特征库的领域主题爬虫
2015-12-23吴岳廷李石君
吴岳廷,李石君
(武汉大学 计算机学院,湖北 武汉430072)
0 引 言
与传统的通用爬虫不同,领域主题爬虫的目标在于抓取与指定主题相关的网页集。目前计算网页与特定主题的相关性通常采用的是基于静态关键词项的页面量化与向量空间模型相结合的方法。然而,这种方法忽略了页面语义层面与主题领域之间的关系,片面地通过计算词频作为网页过滤的依据,容易造成爬取的结果与主题偏离,引入大量的噪音页面从而降低领域主题爬虫的抓取效率和实用性[1]。
为了提高目标网页爬取的准确度和效率,综合考虑现有模型和方法的优缺点,将扩展主题特征库引入网页相关度计算过程中,提出一种基于扩展主题特征库的领域主题爬虫。该爬虫基于扩展主题特征库定义网络空间中的页面。为了能够实时调整对主题相关页面的捕获粒度,提高对噪音页面的识别精度,在网页抓取过程中动态地更新主题库,通过动态的扩展主题项和网页相关度计算算法量化页面的主题相关度,剔除不相关或相关性较弱的网页,从而弥补了传统的领域主题爬虫对网页语义层次处理的不足。最后通过对新旧方法的实验结果进行分析与比较,验证改进后的主题爬虫的优势。
1 标签块节点
1.1 标签块节点数据结构
在网络空间中,网页是由各种类型的HTML 标签和嵌入在其中的文本内容所组成,不同种类的标签放置在网页的不同区域体现其对页面的不同作用[3]。例如突出强调重要信息,划分文本块结构或者装载子标签形成嵌套复杂结构 (类似容器)等多种功能,而同类型的标签通常在页面的表现形式中发挥类似的作用。例如,<strong>、<b>、<h1>、<i>都在页面中起到对重点内容进行突出展示的作用,而<p>、<div>、<span>起着类似于文本容器的作用。正因为网页与HTML标签存在紧密的联系,且标签可以根据其功能划分成不同的类型集,因此可以将网页抽象成重要标签块和标签块相互之间关系集的节点集模型

根据Web站点中不同种类的网页从中抽取出所有代表性的标签,表示成标签块节点 (tag-block node),所有标签块节点及其相互之间的关系构成整体页面。具体表示如下所示

式中:TN——页面中的所有标签块节点的集合,Block(m)——由标签块节点的详细结构,m——页面中标签块的数目。BlockId——标签块节点编号,是对页面中特定位置特定类型标签的唯一标识,BlockName——标签块的名称,BlockDetail——对标签块的描述信息,BlockContent——标签块内的文本内容,BlockType——标签块节点类型,由块内标签的功能特点决定。AttributeSet——标签块的属性集合,KeyTagSet——节点中的重要标签集合,weight——标签节点的权重,impact——标签块节点的影响因子。
1.2 标签块节点的影响因子和权值
各标签块节点的影响因子 (impact factor)和权值(weight)不同,在计算其影响因子和权值之前,首先给出影响因子和权值的定义。
定义1 标签块节点影响因子标签块节点p 的影响因子Block.impact是对节点p 对页面主题的语义和结构方面综合影响力的量值。由块所含有的标签和其在页面中的所在的区域特征等因素所构成。
通常而言,页面的任意一区域块,如果其含有的重要标签数目越多,则其重要性即影响因子越大;块中的标签和文本内容对块类型贡献出的语义特征越显著,其影响因子相应地也越大。根据这两点,可以将标签块节点的影响因子的数值量化成二者的加权组合求和。计算方法如式(3)所示

式中:Block.impact0由块节点中含有的重要信息标签的数量决定,——Block.impact0对应的权值,计算公式如下所示
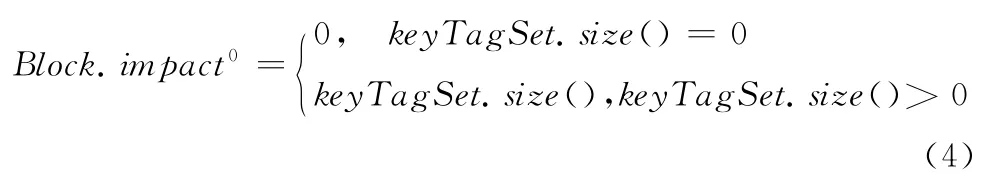
式中:keyTagSet——标签块中含有的所有关键标签集,keyTagSet.size ()——标签块节点中关键标签的个数。Block.impact1根据经验值设定,根据标签块节点Block-Type的不同设置不同的数值。
定义2 标签块节点权值标签块块节点权值指其影响因子在其所在的页面所有标签块影响因子数值总和中的比例。
块节点的影响因子具有可传递性。如果某个块含有关键标签和重要文本信息,即其影响因子较大,则该区域块的外层嵌套块的影响因子也随之受影响而相应较大。类似于这种情形,如果随着网页主题的转移某一标签块的重要性发生变化,则影响因子会扩展到其相邻的或内包含的区域块,最终影响块节点权值。mj的权值计算公式如下所示

在网页WP 中统计得出块mj中关键词j 的词项频率WTfij,即可以计算出词项j的权值

式中:m——网页中所有的重要词项总数,NT——WP-m页面模型中标签块节点的总数。
2 扩展主题特征库
传统爬虫的主题特征库是一个静态的常量。根据特定专业领域的特点由富有经验的领域专家建立,结合网页相关度计算策略来筛选网页,以决定网页是否下载到本地文件系统或者数据库中。静态的主题特征库 (static topic feature library,STFL)由于在爬虫爬取网页的过程中不能根据爬取的深度和已处理的站点规律作出适应性变化,所以缺乏灵活性和可变性。而且单纯根据独立的关键词项来筛选网页还忽略了对页面语义层次的相关度考量,易漏掉很多不属于静态主题特征库但含有很多与特征库中的关键词项同义或近义词的网页集。
为了提高主题特征关键词的区分能力和移植性,在相对较少的时间内搜索少而准确的网页集,同时尽可能动态地在爬取过程中适应主题多变性的要求,这就要求与主题相关的特征项是动态变化的,且包含体现页面语义的特征项。具备这样特点的特征库称之为动态主题特征库 (dynamic topic feature library,DTFL)。将静态和动态的主题特征库结合起来形成了扩展主题特征库 (extended topic feature library,ETFL),如下所示
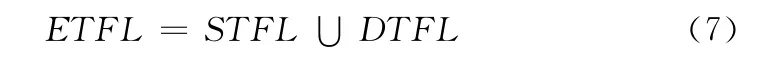
2.1 专业领域主题特征项
主题特征项通常包括事物主体、时间、地点以及详情信息等要素。为了精确地描述专业领域内的特定概念和事件,主题特征项应该至少包含事物发生的主体,专业领域内的专用词汇以及有利情报的判定词。事物发生的主体定义了事物涉及的团体或机构,专用词汇则限定事物的范围,具有指向性强和专业领域分辨度高等特点,情报判定词则在一定程度上定义了信息的有效性和重要性,结合3种关键词项可以最基本地描述一个领域主题。以税务领域为例,涉税主体包括国税机关,地税机关在内的征税主体和个体工商户、企业集团在内的纳税主体;涉税专业词汇包括印花税、对物税等,这类词大量应用于税务领域,对辨别税务信息非常有效。
另一方面,由于税务信息种类繁多,为了从多而繁杂的涉税信息中爬取到税收情报相关信息,有必要对页面信息作价值性判定分析。因此需要在主题特征库中引入体现税收情报信息特点的判定词项,这类词对网页内容是否具备税务情报特点具有较强的引导和分辨力,能决定页面是否具有情报利用价值。涉税主题特征词项的示例见表1。

表1 涉税信息的主题特征词项示例
2.2 网页主题特征项提取算法
因为不同位置和类型的标签对网页主题的贡献重要性不同。例如同样是标题,网页标题和段落标题对网页主题的贡献度不同,对超链接进行描述的锚文本和网页正文对网页的重要性也不一样。可以重要性不同的标签划分到不同的标签块节点中,因为其对所属主题的区分贡献度不同,所以在主题特征项的提取过程中需要对不同的标签进行区别对待。下面是本文提出的网页主题动态提取算法的伪代码:


2.3 扩展主题特征库生成算法
基于静态主题特征库进行爬取被证实存在诸多缺陷,要改进网页过滤算法首要要对主题特征库进行扩展。扩展主要采取如下两种方案。
一种方案是基于Wikipedia,HowNet等电子资料库来生成动态主题特征库,这种方法通过采用包含同义词和上下位相关联词在内的同义词典的方式来扩展特征库[9]。第二种方案是通过在Google、百度等主流的搜索引擎的搜索框中输入原始的静态主题特征项,在搜索引擎返回的搜索结果中选择前top L 篇文档作为预选页面,利用2.2所示的网页主题特征提取算法从上述页面中抽取扩展特征项;
以第二种方案为例,其执行过程是,针对原始主题特征库中的每一个特征项,在Google等搜索引擎中输入词rw,Google基于词rw 返回一个结果列表,其中包括一系列与rw 相关的URL列表,选取前Top L 个URL,下载至本地文件系统中,构成与词项rw 相关的网页集WSet。然后对WSet中的网页进行正文抽取,去除正文中的停用词和主题噪音词,采用式 (6)所示的加权的TF*IDF 公式计算出的权值Wek对结果进行排序,选择词频排在前Top n位的扩展词构成词集 {e1,e2,...,en},作为基于rw 词项扩展的主题特征项集。在经过用户的辨别,筛选和编辑后,加入到扩展主题库特征库中

式中:w——词项,f (ek)——词w 在页面中的词频,fmax——页面中所有词词频的最大值。采用两种方案相结合的方法生成扩展主题特征库的算法描述如下所示:
设Topic表示某一主题的名称,TD 表示对主题Topic的描述字符串,SE 表示Google、百度等主流搜索引擎集合,OL 表示Hownet、Wikipedia等在线语料库集合,IW为用户手动输入的主题特征项集,EW 表示通过方案一提取出的扩展词项,SW 表示通过方案二提取出的扩展词项,UT 为主题特征项待选集,CT 为经过用户确认后的主题特征项集,CT_s为涉税主体特征项集,CT_t为涉税专业特征项集,CT_i为税务情报判定特征项集,RS 经过用户确认后的种子URL 集。SU 表示主题Topic的种子URL(爬虫最开始爬取的站点)待选集,CU 为经过用户确认后的种子URL集合。
接着定义一些方法来描述主题特征集动态扩展算法中的子过程。
方法fq(U)表示将网页下载到本地文件系统中或者将网页相关信息存储到数据库中的过程。
σ(p)表示从网页P 中下自动抽取出主题特征词项的过程。
方法fe(UT)表示用户对主题特征项的辨别,筛选和编辑后,形成最终主题特征项集的过程。
方法fc(CT)表示根据税务主题的特点对主题特征项进行分类的过程。
主题特征库动态扩展的算法描述如下所示:


3 网页过滤
3.1 网页相关度计算
因为不同类型的标签块节点对网页主题的贡献度不同,所以对各部分进行加权求和,公式如下所示
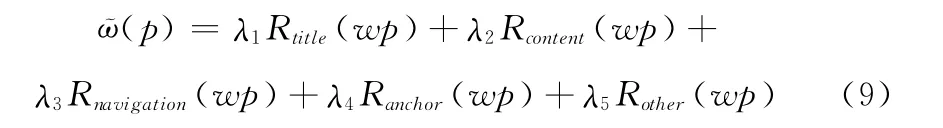
式中:Rtitle(wp)——标题的主题相关度,Rcontent(wp)——正文的主题相关度,Rnavigation(wp)——网页导航栏的主题相关度,Ranchor(wp)——网页内锚文本的主题相关度,Rother(wp)——其它类标标签块节点的主题相关度。
其中,各标签块节点主题相关度的计算方法是采用向量空间模型 (vector space model,VSM)和TF-IDF算法相结合的方法。使用VSM 将网页wp表示为各词项权重组成的主题特征向量。即wp ={w1,w2,…,wn},其中wt表示词项t在网页中的权重值。
在扩展特征库中,将领域主体Fb,领域专业词Fs,领域情报判定词Fv表示成主题特征向量

通过TF-IDF算法对页面中各词项的权重值进行计算,计算公式如下所示
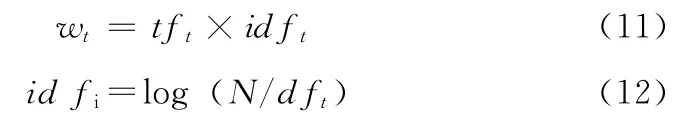
上述公式中的tft为词项t页面中出现的频数,idft为词项的逆文本频率。为了避免网页文本内容的篇幅的长短给权值计算造成的影响,对权值进行归一化处理,计算方法如式 (13)所示
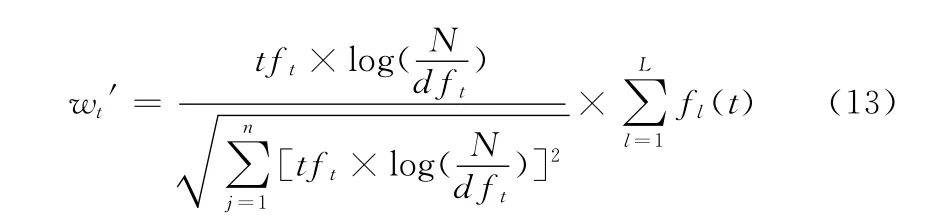
式中:fl(t)——特征项t所在的标签块节点l 的位置权值,L——f(t)所在的标签块总数。越能体现网页主题且与其它标签块的区分度越高的节点,其fl(t)的值越大,反之则越低。
fl(t)的计算方法如式 (14)所示

最后使用余弦相似度计算式 (15)计算网页Pj与相应主题T 的相关度

根据主题T 的特点设置相关度的阈值η,若sim(Pj,T)≥η,则任务页面Pj与主题T 相关,爬虫允许其通过各处理链,最终下载到文件系统或数据库中;否则网页过滤模块将其丢弃。
3.2 基于扩展主题特征库的网页过滤
令L= {L1,L2,…,Ls}表示经过上述算法生成的扩展主题特征库,其中,Li为扩展主题特征项,s为主题特征项个数,WP = {wp1,wp2,…,wpt}表示网页集。
基于扩展主题特征库的网页过滤算法的基本思路是:首先对网页pj进行分析,表示成如1.1小节所示的标签块节点集模型,并抽取出重要的词项构成精简的网页文本集sj,将sj中与扩展项ei具有同义或者上下相关的词项替换成主题概念ci,通过使用主题概念代替固定的关键词,从而使对网页与主题的相关性评定转化为语义层次的页面文本概念集与扩展特征库的相关度计算。算法描述如下:
对于网页集WP 中的每一个网页WPj,基于扩展的主题特征集k形成基于概念的新页面WPj’,在算法开始执行时,WPj’与原始页面基本相同。
记扩展主题特征库为E= {E1,E2,…,En},Ei={ei1,ei2,…,ein},其中eij(1≤i≤n,1≤j≤t)表示根据关键词ei扩展出的同义词或者上下相关联词;对每个原始词ei将Ei的每一项存入template;
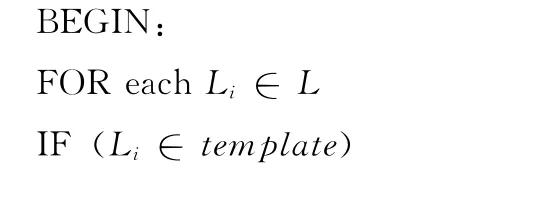

根据式 (13),可以计算出基于概念的新页面WP’j的特征向量 (w1,j’,w2,j’,...,wn,j’)。设定θ为阈值,如果网页WPj的主题相关性sim(Pj,T)≥θ,则认为页面为主题相关,应该下载。
4 实验结果分析与比较
为了检验本文中提出的领域主题爬虫在网页过滤方法上的有效性,选定税务领域为示例,将基于扩展主题特征库的涉税主题爬虫与基于静态关键词的涉税主题爬虫在相同的实验环境中进行爬取,然后对结果进行分析和比较。
实验采用CentOS6.2作为操作系统,选用Sybase ASE 15.0.3for Linux作为数据库管理系统,开发集成环境为InteliJIDEA+jdk-6u10-rc2。
衡量主题爬虫网页过滤策略是否优良的一个重要指标是页面抓取精度RR (relevance ratio),页面抓取精度RR=涉税主题爬虫实际抓取的主题相关网页数目relevant_pages/领域主题爬虫实际抓取的主题相关网页数目/领域主题爬虫爬取的网页总数total_crawled。除此之外,衡量爬取抓取结果的两个重要指标为准确率precision和召回率recall,准确率precision =领域主题爬虫实际抓取的主题相关网页数目relevant_pages/经过爬虫判定为主题相关后下载的主题相关网页的数目fetch_pages,召回率recall =领域主题爬虫实际抓取的主题相关网页数目relevant_pages/网络空间中实际存在的与主题相关的网页数目existing_relevant_pages,为了能够综合体现准确率和召回率的指标性,引入指标F,计算公式如下所示
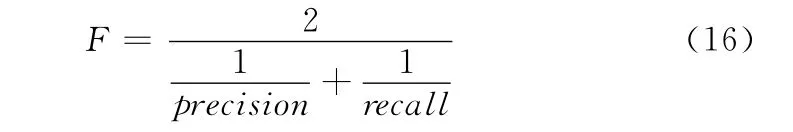
实验结果如表2和图1所示。
由表2的实验结果分析得出,相对于传统的静态特征库,采用扩展特征库的涉税主题爬虫准确率precision 对比传统主题爬虫提高了23.74%,召回率recall 提高了24.28%,二者的综合因素F 对比提高了24.43%,爬取结果中主题相关性网页的比例明显增大。而从图1网页抓取精度和已爬取网页总数的动态变化趋势图可以看出,在网页抓取初期阶段,由于初始URL 和根据链接分析得出的URL离主题相关性资源集中域较近,所以两种爬虫中的网页的抓取精度都比较高而且差距较小,而随着爬虫的运行,处理的页面网址偏离主题资源区域的概率增大,抓取精度下降比较快,且差距增大。观察可知,随着爬虫的运行,基于扩展主题特征库的主题爬虫网抓取精度均比基于静态主题库的高,而且上下浮动比较小,表明爬取精度较为稳定;而静态主题库爬虫的实验结果上下浮动比较大,表示判定主题相关性网页的稳定性不足,易引入主题噪音页面。

表2 两次采集实验结果对比

图1 静态主题库与动态主题库对比
因此,通过实验结果表2和图1的分析和比较可知,相比于传统的基于静态关键词项的领域主题爬虫,基于扩展主题库的主题爬虫能够更精准地对主题相关性页面进行下载,对主题噪音页面进行过滤,使网页抓取更加高效和实用。
5 结束语
在领域主题爬虫中,传统的方法仅根据网页的静态主题特征库来定义主题相关性网页,缺乏对隐藏在主题特征项之间语义层次关系的处理。本文提出一种基于扩展主题特征库的新型领域主题爬虫。该爬虫通过标签块节点集模型定义页面,通过在线语料库和从扩展页面中动态提取特征项等方式对主题特征项进行扩充,生成扩展主题特征库,并结合改进的网页相关性判定算法对网页进行过滤。这种方法综合了特征项的词频与页面主题概念两方面的因素,弥补了传统方法对网页语义和概念层次上的缺失。实际测试和项目应用结果表明,引入扩展主题特征库的领域主题爬虫在网页抓取中具有较强的定向性和准确度。下一步将对网页正文的抽取和主题噪音页面模式的识别方面进行研究,以进一步提高爬虫对目标页面抓取的效率和精确度。
[1]HUANG Ren,WANG Liangwei.Research on focused crawler based on topic-related concept and page segmentation[J].Applica-tion Research of Computers,2013,30 (8):2377-2380 (in Chinese).[黄仁,王良伟.基于主题相关概念和网页分块的主题爬虫研究[J].计算机应用研究,2013,30 (8):2377-2380.]
[2]Ramiz MA.A new sentence similarity measure and sentence based extractive technique for automatic text summarization [J].Expert Systems with Application,2009,36 (4):7764-7772.
[3]HUANG Chenghui,YIN Jian,HOU Fang.A text similarity measurement combining word semantic information with TFIDF method [J].Chinese Journal of Computers,2011,34(5):856-863 (in Chinese). [黄承慧,印鉴,侯昉.一种结合语义信息和TF-IDF方法的文本相似度量方法 [J].计算机学报,2011,34 (5):856-863.]
[4]JIN Mingzhu,DING Yuewei.Topic crawler based on dynamic topic knowledge base [J].Journal of Computer Application,2009,29:45-46 (in Chinese).[金明珠,丁岳伟.基于动态主题库的主题爬虫 [J].计算机应用,2009,29:44-46.]
[5]JU Shiguang,LV Xia,WANG Jing.Temporal link-analyze based on Web page ranking algorithm [J].Application Research of Computers,2009,26 (7):2438-2441(in Chinese). [鞠时光,吕霞,王婧.基于时间链接分析的页面排序优化算法 [J].计算机应用与研究,2009,26 (7):2438-2441.]
[6]WANG Zhihua,WEI Bin,LI Zhanbo,et al.Web information extraction system based on ontology [J].Computer Engineering and Design,2012,33 (7):2634-2639 (in Chinese).[王志华,魏斌,李占波,等.基于本体的Web研究 [J].计算机工程与设计,2012,33 (7):2634-2639.]
[7]JIN Mingzhu,DING Yuewei.Research and implementation for topic crawler using statistic model[J].Computer Engineering and Design,2010,31 (16):3700-3704 (in Chinese).[金明珠,丁岳伟.基于模型统计的主题爬虫的研究与实现 [J].计算工程与设计,2010,31 (16):3700-3704.]
[8]GUAN Huifen,SHI Jun.Focused crawler technology based on ontology [J].Computer Simulation,2009,26 (10):123-126 (in Chinese).[关慧芬,师军.基于本体的主题爬虫技术研究 [J].计算机仿真,2009,26 (10):123-126.]
[9]TIAN Xuan,LI Dongmei.Probability estimation for semantic association on domain ontology [J].Computer Engineering and Application,2011,47 (27):136-140 (in Chinese).[田萱,李冬梅.领域本体中概念间语义相关度的概率估计 [J].计算机工程与应用,2011,47 (27):136-140.]
[10]DAI Kuan,ZHAO Hui,HAN Dong,et al.Theme feature extraction of Chinese Web page based on vector space model[J].Journal of Jilin University,2014,32 (1):88-93 (in Chinese).[代宽,赵辉,韩东,等.基于向量空间模型的中文网页主题特征项抽取[J].吉林大学学报,2014,32 (1):88-93.]
