基于DOM 树序列值比对的SQL注入漏洞检测
2015-12-23罗明宇
罗明宇,凌 捷
(广东工业大学 计算机学院,广东 广州510006)
0 引 言
SQL注入漏洞被利用的典型是从数据库中盗取敏感信息或擅自添加数据库中的账户,以获取操作数据库的权限[1-3],这种攻击具有较强的隐蔽性,容易造成敏感信息的泄露或破坏。因此,对SQL注入漏洞检测方法的研究已成为提高网站安全防护能力的热点问题。近年来,研究SQL注入攻击检测和防御的文献有不少,但大多都存在效率不高、误报率较高的情况。例如SQL 注入检测中的静态分析法,该方法是指通过在Web应用程序中分析SQL查询语句以检测并防止SQL注入攻击,其重点是检测用户的输入类型而不是检测SQL注入攻击,如果攻击者使用正常的类型和语法,该方法就不能够有效发挥作用。不同于静态分析法,动态分析法在不对应用程序做任何修改的前提下,能够找到SQL注入攻击漏洞,但该方法只能找到已经得到开发者确认的漏洞,不能全部发现那些没有预先定义的漏洞[4]。本文在研究网页比对算法基础上,提出了一种基于DOM 树叶子节点序列值的快速比对的判定技术,设计并实现了相应的SQL注入漏洞检测原型系统,实验结果表明该方法不仅能够提高对于SQL漏洞检测的准确率,更在一定程度上提高了检测的效率。
1 SQL注入漏洞的检测
Web应用程序可简单的认为是Web 浏览器运行的程序,它一般具有三层结构:表示层、CGI层和数据库层。
(1)表示层:主要接收用户的输入和显示经过处理的结果。它可以被认为是图形用户界面。Flash、HTML 及Java的脚本都是表示层的一部分,它直接与用户进行交互。
(2)CGI层:也称为服务器脚本程序。数据库发送数据存储备份到CGI层,并最后发送到表示层,呈现给用户观看。
(3)数据库层:这层只有存储和检索的所有数据。由于这层直接连接到CGI层并没有在数据库中做任何安全检查,如果CGI层的攻击成功,数据将会被发现并可以被修改[5]。
目前常用的SQL注入漏洞检测的方法可分为入侵前检测与入侵后检测[6]。入侵前检测一般应用在客户端,主要方法就是在有参数传入的地方输入 “and 1=1”、 “and 1=2”或 “‘”等字符。入侵后检测主要应用在服务端,包括:数据库检查、IIS日志检查、其它相关信息判断。
本文提出的漏洞检测技术属于应用在客户端的入侵前检测。通过对URL的检测参数添加 “and 1=1”的正常页面与对URL的检测参数添加 “‘”或 “and 1=2”返回的页面进行对比,若相同,则判定该页面不存在SQL 注入漏洞,若不同,则判定存在SQL注入漏洞。研究的关键问题是如何快速准确地比对正常页面与返回页面,提高SQL 注入漏洞检测的效率和正确率,其中网页相似度的度量在漏洞检测中有重要应用。
由于网页具有一定的结构特性,可以通过比较网页的结构特性来度量网页的相似性。网页的DOM (document object model)树结构在一定程度上反映了页面的内容以及内容间的关系。典型的网页结构相似度度量算法主要有3种:基于编辑距离的网页相似度度量算法、基于链路统计特征的网页相似度度量算法和基于结点统计特征的网页相似度度量算法[7]。基于这3种经典的相似度度量方法,衍生了许多改进算法,从效率或准确率上进行提升。文献[8]提出了基于局部标签匹配的网页相似度计算方法,在分析DOM 树的网页层次结构特征的基础上,计算两棵DOM 树所对应的标签串的距离加权后作为两个网页的编辑距离,以衡量两个网页的相似性,降低了树编辑距离计算复杂度。文献 [9]提出了一种改进的基于树路径匹配的网页结构相似度算法,通过网页间的最佳树路径匹配计算结构相似度,比传统树路径方法区分差异较小的网页更有效。
2 改进的基于序列值比对算法
2.1 序列值比对算法
文献 [10]提出一种基于DOM 树快速比对的判断方法,不比较DOM 树的全部节点序列,仅选能体现出这些变化的部分关键节点序列进行比对。在执行SQL 注入时,存在漏洞的Web页面其布局结构或内容就会发生改变,这种改变会导致DOM 树的结构或对应的内容发生改变。所以快速比对算法主要比对的是DOM 树的叶子节点序列,若不同,则说明DOM 树发生了变化,判定DOM 树不同。若相同,则随机抽取包含文本信息的3个叶子节点,依次比对到该叶子节点的链路标签序列是否相同,若都相同,则说明DOM 树相同。这种DOM 树快速比对算法的本质是比较两棵DOM 树是否相同,用尽可能少的时间准确地判定两棵DOM 树的异同是该算法的核心。对于复杂的Web页面来说,其构成的DOM 树拥有大量的叶子节点,比对叶子节点序列需要耗费大量时间,执行SQL注入时,DOM树变化有可能只是微小的,导致某个标签里的内容发生了改变,算法平均消耗时间较长。其次,对于拥有大量的叶子节点的DOM 树来说,仅仅随机抽取3个叶子节点进行链路标签序列的对比,并不具备代表性,不能因此说明两棵DOM 树是否相同,会造成结果的误差。本文提出一种改进的基于序列值的快速比对算法,算法流程图如图1 所示,具体描述如下:
(1)按某种遍历方式遍历两棵目标DOM 树,分别获取叶子节点标签序列及每个叶子节点到根节点的路径的长度;
(2)比较两棵DOM 树叶子节点序列的长度,若长度相同,则转到步骤 (3),若长度不同,则转到步骤 (6);
(3)根据步骤 (1)获得的叶子节点序列及每条路径的长度,分别算出每个标签的序列值,计算出两组标签序列有几种标签,并根据质数列对标签进行赋值;
(4)根据序列值公式计算出每个标签的序列值,累加每个标签序列值,得到整个序列的序列值;
(5)比较两棵DOM 树叶子节点序列的序列值,若相等,则转到步骤 (7),若不等,则转到步骤 (6);
(6)判定两棵DOM 树不同,结束;
(7)判定两棵DOM 树相同,结束。
下面提出本文计算DOM 树叶子节点序列值的相关参数及序列值的相关计算公式。对于一组标签序列

QueV(Pi)表示它的序列值

quev(pi)表示标签pi在序列Pi中的序列值

式中:st(pi)——标签pi的标签值;i——标签pi所在序列中的位置;len(pi)——根节点到pi的路径的长度。

图1 序列值比对算法流程
标签值st(pi)主要通过质数列来构成,从对比的两棵DOM 中取其中一组叶子节点序列并用质数列 (1除外)对它依此进行赋值,若出现重复的标签则跳过且该标签的标签值为第一个出现时所赋的值。另一组节点序列则参照第一组标签值对其每个节点进行赋值,若出现了新的标签,则继续用质数列对其赋值。从式 (2)得,一组标签序列的序列值是由每个标签在此序列中的序列值累加得到的,而从式 (3)得,每个标签的序列值quev(pi)是由st(pi)(标签值)、i(该标签在序列中的位置)和len(pi)(根节点到节点pi的路径长度)这3个部分组成的,分别体现了标签的差异、位置与树结构这3种影响因素。例如图2 (a)和图2 (b),有两棵简单的DOM 树。
可以得到叶子节点序列分别为

因为两个叶子节点序列Pi、Pj总共出现了4种不同的标签,所以根据质数列,得到的标签值见表1。由式 (2)、式 (3)可得Pi的序列值QueV(Pi)为0.9126,Pj的序列值QueV(Pj)的序列值为0.8824。虽然标签序列Pi与Pj长度相同、各种标签出现的次数相同,但是由于标签序列的次序不同,所以序列值也不同,因此判定两棵DOM 树不相同。
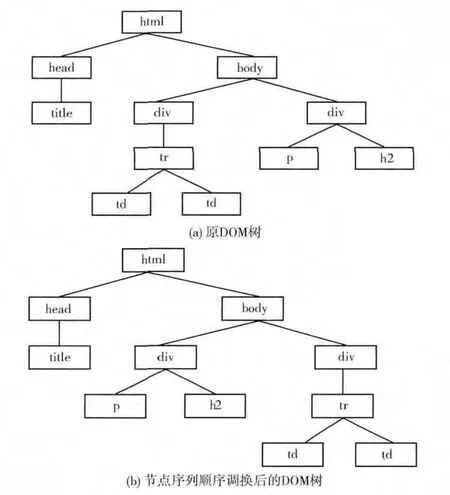
图2 节点序列顺序不同的DOM 树

表1 标签值
2.2 算法效率分析
文献 [10]提出的快速比对算法,对于不同的DOM 树也是仅仅比对3个叶子节点的路径是否相同,对于拥有大量叶子节点的DOM 树来说,不能准确地区分不同结构却拥有相同叶子节点序列的DOM 树。本文提出的改进的基于序列值比对算法,不仅仅比对了叶子序列的异同,更引进了每个叶子节点的路径长度作为计算序列值的其中一个参数,也就是说DOM 树的结构会影响最终得出的序列值,不同的DOM 树结构即使有着相同的叶子节点序列,得到的序列值应该是不同的。上面的例子说明序列值比对算法能够区分拥有相同叶子节点序列且结构不同的DOM 树。若DOM 树能够以近似一一映射关系对应于序列值,避免序列值的碰撞,有利于提高算法的准确性[11]。本文算法标签值的设置见表1,采用了质数列可减少序列值的碰撞。算法在叶子序列长度相等的前提下,分别计算出叶子节点序列的序列值,再通过比较序列值,判断两组序列是否相等,从而判断两棵DOM 树的异同。若两棵DOM 树叶子节点序列长度不等,则直接判定不同。在判断DOM 树的过程中,传统算法是基于全部节点的个数或者叶子节点的对比,算法复杂度较大,本文算法改进为数值的比对,减少了时间复杂度。
3 实验及结果分析
本 文 实 验 环 境 如 下:①CPU 为Intel Core i3,2.40GHz;②内存为2GB;③操作系统使用Windows XP;④使用C#实现算法。实验选择节点序列比对算法、快速比对算法与本文算法进行比较。
首先在互联网上选取一个存在SQL 注入漏洞的网页。该网页对应的DOM 树共有324 个节点,其中叶子节点为116个,最大路径长度为8。经过SQL 注入测试后返回的网页对应的DOM 树共有307 个节点,其中叶子节点134个,最大路径长度为5。分别采用基于节点序列的比对算法、快速比对算法以及本文算法进行对比,所消耗的时间见表2。可以看出,本文算法所消耗时间约为节点序列比对算法的29%,为快速比对算法的75%,验证了改进算法提高了效率。

表2 算法消耗时间
生成节点数为10、20、50、70、100和120的DOM 树各一对。分别利用上面3种算法分别进行比对,并统计出相同节点比对所消耗的时间情况如图3所示。
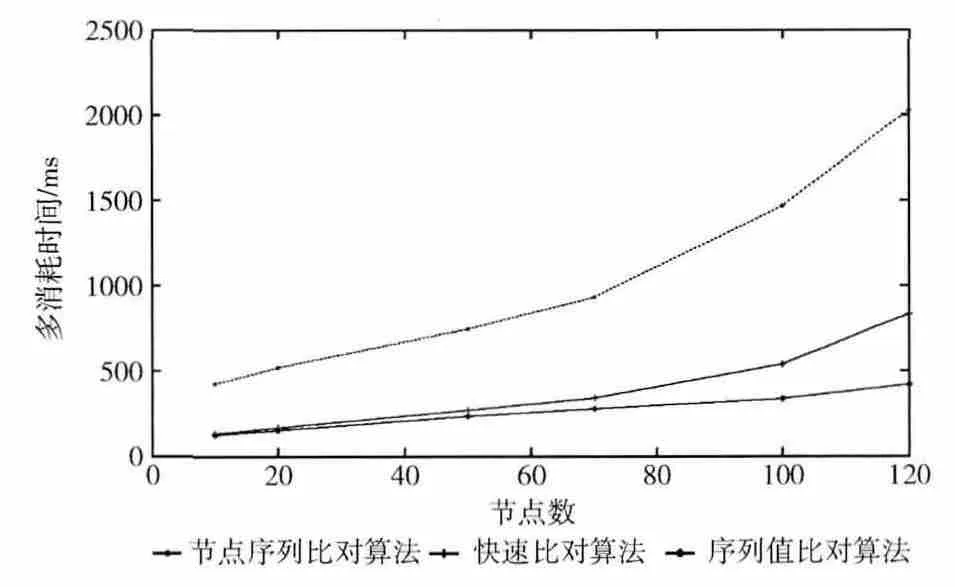
图3 算法效率比较
从图3可以看出,节点序列比对算法和快速比对算法消耗时间呈指数级增长,而本文提出的序列值比对算法呈线性变化。对于节点序列比对算法,其时间复杂度为O(n2),其中n为两棵DOM 树对应节点的序列长度的最小值,效率偏低。对于快速比对算法,该算法的时间复杂度为O(n×N)+3O(L),其中N 为两棵DOM 树中叶子节点数目的最小值,L 为两棵DOM 树待对比链路节点序列长度的最大值。本文算法中比较两棵DOM 树是否相同,只需计算出叶子序列的序列值,然后比较叶子的序列值,不需要花费过多的时间对叶子节点进行一一比对,时间复杂度为O(n),比对时间不会随着网页节点数的增加而迅速增大。
为了验证本文提出的序列值算法应用在漏洞检测系统中的有效性,作者对序列值比对算法进行了实现,并与当前常用的两款检测工具BSQL Hacker和Pangolin进行比较实验,分别对测试样本进行检测。首先通过表3的关键语句在Google中搜索出一定的URL 以构建测试样本集;然后对获取的URL 测试样本进行SQL 漏洞检测,根据对获取的URL添加不同的注入命令的返回页面与正常页面的异同来判定URL是否存在漏洞,如果判定存在,则通过人工注入进一步确定。实验结果见表4。

表3 不同关键语句获得的URL数量

表4 与不同检测工具的比较
从上面的结果可以看出,基于序列值比对算法的检测系统在正确率上明显高于其它两种工具,在消耗时间上开销比其它两种检测工具要大,但消耗时间还在可接受范围之内。
4 结束语
SQL漏洞检测技术在网络安全中具有重要的实用价值,本文提出了一种改进的网页比对算法,定义了DOM 树序列值的计算方法,把DOM 树叶子节点标签值与每个叶子节点路径长度作为计算DOM 树序列值的关键参数,计算出DOM 树的序列值。通过比较序列值的异同来判断DOM树是否相同,进而可以判断两个页面是否相同。该算法相较于传统网页比对方法,更加适合在SQL 漏洞检测中,能够准确、高效的比对网页异同,把树结构对页面异同影响体现出来,又通过比对数值的方法来取代一一比对节点的方法,有效地提高了比对效率。不足之处在于对于返回的页面未进行详尽的分析,会对结果产生一定的误差,另外与当前常用检测工具的效率上存在一定差距。接下来将会对算法过程进行改进,优化检测过程,提高检测效率。
[1]MA Xiaoting,HU Guoping,LI Zhoujun,et al.Research on detection and prevention technologies for SOL injection vulnerability [J].Network and Computer Security,2010,10 (11):18-24 (in Chinese).[马小婷,胡国平,李舟军,等.SQL 注入漏洞检测与防御技术研究 [J].计算机安全,2010,10(11):18-24.]
[2]Shar Lwin Khin,Tan Hee Beng Kuan.Defeating SQL injection[J].Computer,2013,46 (3):69-77.
[3]Indrani Balasundaram,Ramaraj E.An efficient technique for detection and prevention of SQL injection attack using ASCII based string matching [J].Procedia Engineering,2012,30:183-190.
[4]CHENG Xiaoli.The research and realization of SQL vulnerability detection system for web application [D].Chengdu:Southwest Jiaotong University,2013 (in Chinese). [成晓利.Web应用SQL注入漏洞测试系统的研究与实现 [D].成都:西南交通大学,2013.]
[5]Inyong Lee,Soonki Jeong,Sangsoo Yeo,et al.A novel method for SQL injection attack detection based on removing SQL query attribute values [J].Mathematical and Computer Modelling,2011,55 (1):58-68.
[6]CHEN Xiaobing,ZHANG Hanyu,LUO Liming,et al.Research on technique of SQL injection attacks and detection [J].Computer Engineering and Application,2007,43 (11):150-152 (in Chinese).[陈小兵,张汉煜,骆力明,等.SQL注入攻击及其防范检测技术研究 [J].计算机工程与应用,2007,43 (11):150-152.]
[7]ZHANG Ruixue.Research & application of web similiarity based on DOM tree [D].Dalian:Dalian University of Technology,2011 (in Chinese).[张瑞雪.基于DOM 树的网页相似度研究与应用 [D].大连:大连理工大学,2011.]
[8]LI Rui,ZENG Junyu,ZHOU Siwang,et al.Improved webpage clustering algorithm based on partial tag tree maching [J].Journal of Computer Applications,2010,30 (3):818-820 (in Chinese).[李睿,曾俊瑀,周四望,等.基于局部标签树匹配的改进网页聚类算法 [J].计算机应用,2010,30 (3):818-820.]
[9]LIAO Haowei,YANG Yan,JIA Zhen,et al.An improved web structure similarity based on matching algorithm of tree paths [J].Journal of Jilin University (Science Edition),2012,50 (6):1199-1203 (in Chinese). [廖浩伟,杨燕,贾真,等.一种改进的基于树路径匹配的网页结构相似度算法[J].吉林大学学报 (理学版),2012,50 (6):1199-1203.]
[10]ZHANG Chen,WANG Yongyi,WANG Xiong,et al.SQL injection vulnerability detection based on webpage DOM tree comparison [J].Computer Engineering,2012,38 (18):111-115 (in Chinese).[张晨,汪永益,王雄,等.基于网页DOM 树比对的SQL注入漏洞检测 [J].计算机工程,2012,38 (18):111-115.]
[11]LIU Shuyi.Strategy of eliminating duplicated web pages based on text similarity [J].Computer Applications and Software,2011,28 (11):229-229 (in Chinese). [刘书一.基于文本相似度的网页消重策略 [J].计算机应用与软件,2011,28(11):228-229.]
