基于擦除码的高效云存储数据冗余方案
2015-12-20吴庆涛张旭龙郑瑞娟张明川
崔 敏,吴庆涛,张旭龙,郑瑞娟,张明川
(河南科技大学 信息工程学院,河南 洛阳471023)
0 引 言
如何提高分布在众多弹性节点中的数据可用性同时降低数据冗余度已成为云存储[1-5]中一个重要问题。目前的冗余灾备[6-8]方案,将整个数据文件复制3份以上分别存储于不同位置的服务器节点上,对其主文件进行操作后同步到其它各节点的副本上进行修改。在存储备份时对大文件的多数据块分布式存储管理忽略了安全可用性,一旦存储数据块的节点发生故障将影响整个数据文件的可用性;而对于云存储系统中大文件的复制将占用额外的存储空间且呈倍数增加,对存储资源不断提出需求,造成存储成本负担增大。因此优化冗余存储是保障云存储系统可扩展性的关键。
Wang等提出了一种基于工作负载的选择性云架构云RAID,对主存储和备份存储采取不同的RAID 方法,与传统的三通复制相比减少了存储开销,但是忽略了存储资源的异构性[9];文献 [10]介绍了异构配置下优化冗余的云存储方案,通过分析分布式冗余方案在异构节点上的优化部署,提出了一种衡量数据可用性的方法。考虑到编码冗余的优势,很多学者致力于将编码冗余应用到云存储系统中,文献 [11-13]在分布式存储系统中,使用网络编码对存储节点上的数据进行编码和重构,一定程度上降低了存储冗余度,但是计算消耗和流量消耗增大。
本文提出一种高可用的云存储方案以降低存储空间的冗余度。主要工作包含以下两个方面:采用编码方式进行数据文件冗余容错;优化用户读取数据时数据块的检索及恢复效率。
1 基于擦除码的云存储系统模型
1.1 云存储系统模型
云存储系统可以用一个有向图G= (V,E)表示,其中V 是顶点的集合,E 是连接两个点的边的集合。把云存储系统中的所有存储节点以及终端看作顶点,节点与节点之间的网络连接看作为图中的边。如图1所示,顶点集合V 根据节点的不同被分为3 个类别:服务器节点 (VS={S1,S2,…,Sn})拥有存储系统里每个文件的原始副本;存储节点 (VN= {N1,N2,…,Nm})接收并存储每个文件产生的R 个副本;终端节点 (VT= {T1,T2,…,Ts})是那些需要获得数据文件的节点或用户端。边集合E 根据传输数据的类别可分为两大类:从服务器节点向存储节点传输数据的ES,以及从存储节点向终端节点传输数据的ET。而有向图边的方向为数据的流动方向。
存储节点和服务器节点构成的网络就是一个简单的云存储模型,终端节点是连接到云的客户端。服务器节点上包含一系列的数据文件Fn,而每个存储节点上接受并存储随机量的数据文件Fn的分块Fin,对于终端节点可从不同的存储节点上获取到一定量所需的数据文件分块进行数据文件恢复。因此需要相应的存储节点连接到所有的包含源数据文件的服务器即存在关系Fin∪Si∈SFSi。每一个终端节点必须连接到一组能够下载到完整副本的一组存储节点。
为了使云存储模型简化,并不失一般性,我们提出以下几点假设:
(1)每一个文件的原始副本只存在于某一个服务器节点中,即各服务器节点Si与Sj之间的交集不属于文件Fn,即Si∩SjFn。
(2)一个节点的类型是单一的,相同类型的节点之间不进行通信。事实上,一个节点可以作为文件1的服务器节点,文件2的存储节点以及文件3的终端节点。我们在这里对其类型进行划分,将多重类型的节点扩展为多个单一类型的节点。
(3)假定云存储系统中每个文件有R 个副本来提供数据冗余,这里的R 是备份因子。
图1中标出的方向不是数据链路,而是云存储模型中的数据流的流向,模型中不涉及链路的重新分布,由于目标应用是一个存储系统,链路带宽只影响数据的传送速度。
1.2 数据编码存储与恢复

图1 一个简单的云存储系统模型
擦除码 (erasure coding)是将原始数据文件编码成一个数据流 (包含多个编码数据分块),由接收者进行重构他们获取到的额定数量数据分块后得到原始数据文件。在传输过程中编码后的数据块的丢失是相互独立的。图2为基于擦除码的云存储系统。
对于数据文件F,首先进行擦除码,将编码后的数据块分发到各个存储节点N 上,如图2所示,假如这4个存储节点有一个出现故障而不工作时,可以从余下的存储节点上取额定数量的数据块进行解码,从而得到终端节点需要的数据文件F。同时可利用正常存储节点上的数据块进行编码对出错节点上的数据块进行恢复或转存其它存储节点。
为了保障数据的高可用性以及存储空间的低消耗,我们在擦除码时需要调整冗余因子,冗余因子太大存储空间将过度消耗,而冗余因子过小则会导致可用性降低。图3为一个简单的数据文件编码过程。
k个原始数据块经过编码生成k+m 个数据块,然后将k+m 个数据块分散的存储到云存储系统中的多个存储节点上。其中有m 个是冗余的数据块,但是具有容错的能力;k个数据块具有恢复数据的功能,即对于任意丢失不超过m个的数据块,这k个数据块都能将它们恢复成原始的数据。该编码器是利用 “生成矩阵 (C)和向量组 (F)”的乘法运算进行实现的。其中C 是一个k+m 行k 列的矩阵,F 是由相同大小的原始数据块组成的向量组。
有限域[14]的线性运算是编码器的核心运算,构造有限域是编码过程的第一步。对于编码器的构造采用Vandermonde[15]矩阵作为生成矩阵的源矩阵,根据Vandermonde矩阵的行列式性质构造出源矩阵G(n,k),如式 (1)所示


图2 基于擦除码的云存储模型

图3 一个简单的数据文件编码过程
由Vandermonde矩阵的性质可知,从式 (1)中任意抽取的k个行向量相互之间是线性独立的。于是将式 (1)经过行变换得到式 (2),作为生成矩阵C

在生成矩阵的作用下,对原始数据生成冗余项。假设需要进行存储的文件是F,它由 (F1,F2,F3,…,Fk)k个同样大小 (最后一块若不是整块进行填充)数据块组成,经过编码器的生成矩阵后,生成冗余数据 (D1,D2,D3,…,Dm),于 是 (F1,F2,F3,…,Fk,D1,D2,D3,…,Dm)则构成一个新的冗余存储向量组,该向量组和生成矩阵C 满足式 (3)
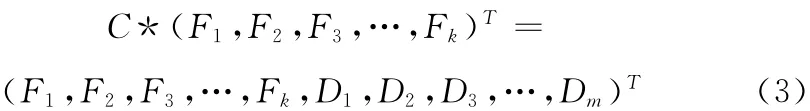
当存储在云端的数据冗余分块中任意数据发生改变,式 (3)就不成立,因此利用此方法可以验证云存储数据的完整性,以增强存储的安全性。
由式 (2)和式 (3)可推出式 (4)
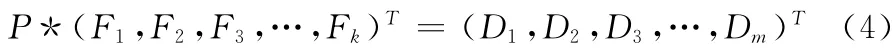
式 (4)中说明了m 个数据冗余块可由原始数据分块经行变换矩阵计算得到,因此在小范围修改数据时可利用该原理,将被修改的数据块单独标记并进行计算,最终将生成的对应冗余数据块和源数据块单独分发到存储节点即可,不需要重新将所有数据块都进行销毁再计算以及重新分发部署存储节点。
数据解码与数据编码是一个逆过程,需要将从存储节点上检索到的多个同项目数据块进行解码并合并为用户需要的数据文件。分别设编码前原始数据块个数和经过编码后的数据块总数为k和n,并设各个数据块的块长为z,其n行k 列的生成矩阵表示为C(n,k)。而编码对象D(k,z)即k行z 列的原始数 据 矩阵,E(n,z)表 示 编 码 后得 到 的n 行z 列 的编码数据矩阵,则编码过程如式 (5)所示

令R(k,z)表示E(n,z)中任意k 行组成的新矩阵,那么由生成矩阵中的对应的k行可生成R(k,z)如式 (6)所示

C(n,k)是 由Vandermonde 矩 阵 转 换 得 到,因 此 利 用Vandermonde矩阵性质可以得出解码矩阵T(k,k),如式 (7)所示

于是式 (8)成立
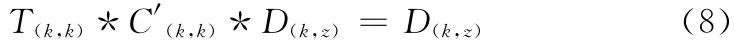
将式 (6)代入式 (8)可得解码过程
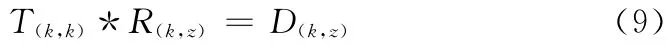
利用式 (9)可完成对用户所需要的数据进行恢复。
1.3 数据块高效检索
在云存储系统中,原数据文件在编码分成数据块分散存储到存储服务器节点上后,在需要取回数据文件时,就需要在众多的存储服务节点中检索对应数据文件的数据编码分块。在传统的简单拷贝冗余备份中,检索相对简单,只需要找到其中一份就能完成请求响应。而在擦除码的分布式存储冗余备份下,需要取回额定数量的数据块才能还原出原数据文件,因此对数据块检索提出很高的要求。
为了提高数据块检索效率,我们采用Chord协议[16,17]的点对点检索方法,设计了基于Chord的快速资源定位方法,存储节点通过对自身的属性做SHA-1运算得到一个m位的标识号记作ID,然后根据ID 的大小顺序组成一个逻辑环,即Chord环。下面给出相关定义:
定义1 主节点环 (master chord),为云存储系统中的每一个存储节点构建一个逻辑环,将各主节点的物理信息进行哈希后映射到Chord,其对应哈希函数设为Hash-Master。
定义2 存储节点环 (storage chord),为定位一个文件分割编码后的多个数据块的存储位置而在存储相关数据块的节点之间构建逻辑环,将相同文件的数据块所在的存储节点信息哈希到Chord 中,其对应哈希函数设为HashStorage。
通过Master Chord可以快速定位存储文件所在的主存储节点,然后利用Storage Chord快速检索对应文件分块所存放的存储节点。Chord环中的每一个节点都需要维护一个路由表,路由表中记录了环中其它节点的信息,在查找的时候其时间复杂度为O (log N)。而随着节点的弹性变化,在增加或减少存储节点时,只需要O (1/N)数量级的节点便信息变更。
按照如下方法将数据资源对象分配到云存储节点上。所有文件哈希后与主节点信息哈希后组成的Chord环进行挂载,随着文件的创建与删除主节点环中的Chord节点也会不断匹配新文件。所有数据分块进行哈希后生成专属ID,按照ID 递增的顺序组成一个环,与环上每个节点记录的存储节点信息组成键值对,同一个存储节点可供不同主节点环连接。
令Chord环中的每个节点对应维护一个Chord路由表,这可以更加方便的定位数据块资源,减少资源查找的时间。每个路由表有m 个表项。Chord中节点n 的路由表结构见表1。
为了寻找节点k的后继,当节点n中路由表没有节点k的键值时,则进行以下操作:节点n 从路由表中选择离k最近的节点m,然后通过节点m 查找更接近于k 的节点。通过重复该操作,最终可以定位到所需资源。

表1 Chord路由表结构
存储节点的资源定位在算法1中给出了相应伪码。该算法通过递归来判断节点n是不是资源k的前驱,路由表中找不到所需资源时,就寻找与目标资源所在节点最近的节点n′,并由节点n′继续重复该算法,直到找到目标资源为止。
从Chord路由表的构造和存储节点资源定位算法可以看出,每次寻找最近节点后,新找到的节点离资源对象的距离通常比原来少一半,通常情况下最多寻找最近节点logN次就可以定位成功,因此能够加速存储节点的数据块定位。

算法1 资源定位算法1. n.findSuccessor(k)2. if(k(n,n.successor])3. return n.successor;4. end if 5. for(i=m;i>1;i--)6. if(finger[i].node in(n,k))7. return finger[i].node;8. end if 9. end for 10. n′=n;11. return n′.findSuccessor(k);
当m=4,n=2,k=14时的查找示例如图4所示。
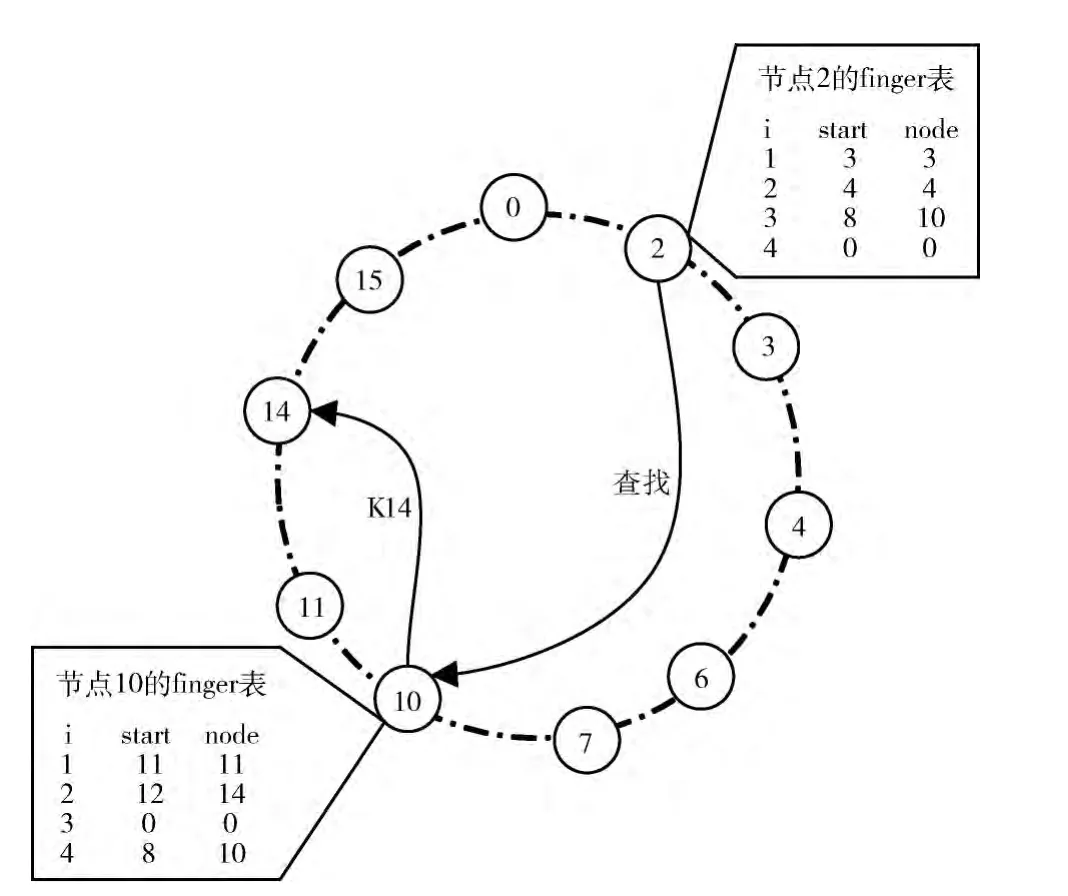
图4 资源定位
2 实验与结果分析
为了云存储方案的验证,我们利用3台服务器构建了基于Hadoop的云存储平台,平台中3个服务器作为3个云数据中心,并对每个数据中心的物理机进行了虚拟化。云存储平台总共包含3个数据中心,24个虚拟机。表2为数据中心1的资源配置情况。

表2 云存储平台的数据中心资源配置
在Hadoop构建的私有云存储平台基础上,我们进行了存储方案Java实现,主要是以云任务的形式提交给数据中心进行云存储服务数据存储过程处理实验。我们的擦除码模块主要是负责对提交的存储文件进行编码分块,检索数据模块提供虚拟节点中数据分块的快速取回并进行合并解码处理,具体操作的实现由各数据中心主机分配给工作节点完成,所有的操作由主节点进行调度。图5为数据中心上多个云任务在3台虚拟机上的时间运行。
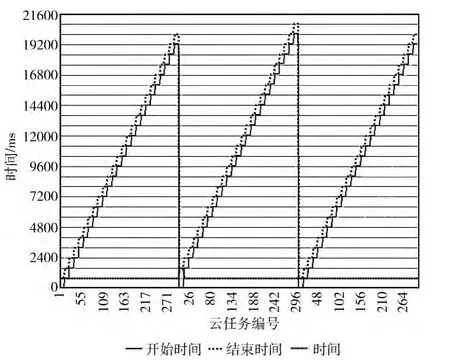
图5 数据中心云任务虚拟机分配运行时间
从图5可以看出300个云任务提交到云端分配给3台虚拟机进行处理时,它们以分时并行的作业调度机制将云任务Map到各运算节点,最后由主节点进行Reduce操作,从而完成整个存储服务的需求响应。
为了验证擦除码存储方案的效能和冗余消耗,我们在不同的冗余因子下进行了存储编解码实验,在高可靠性的要求下冗余度越高越好,这样能够保障在节点发生故障时其它节点能够提供备份,但高冗余度导致存储查找取回解码产生巨大消耗。因此,需要选择适当的冗余因子来保障存储数据的高可用性以及存储编解码的高效性。在Hadoop云存储的基础上,我们将数据编码模块和资源检索定位模块接入云任务调度,选取一个大小为1005kb的图片文件,将其作为一个云存储请求进行处理,图6是在数据分块个数N=10,不同冗余因子下文件的编解码时间以及存储空间的消耗。
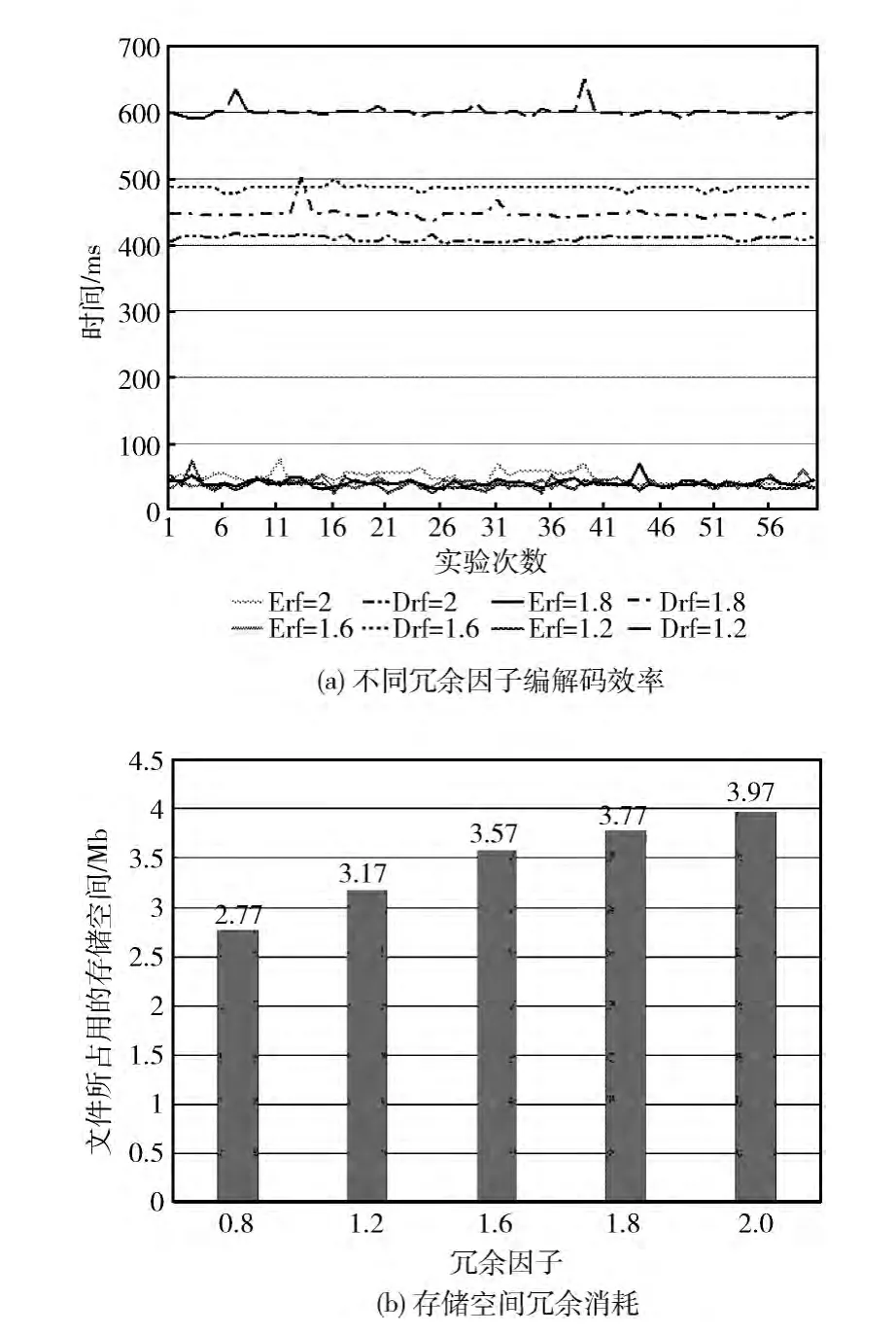
图6 不同擦除码冗余因子的云存储效率与冗余消耗
从图6 (a)中可以看出,在60次重复实验中,对于1 Mb大小的图片文件进行编码时,不同冗余度对编码的时间要求变化不大,基本保持在平均40ms左右,而从分散的存储节点取回额定数据块进行合并解码时,随着冗余因子的减小解码响应时间随之增大。而对于存储空间的占用从图6 (b)中可以明显看出1 Mb大小的图片文件在不同的冗余因子作用下所占用的存储空间逐渐增多。与单文件三备份相比显然节省了大量的存储空间,同时增加了存储节点的灵活性与机动性。
为了比较我们提出的存储方案与三备份的可用性,首先定义数据可用性R,可用性为访问数据时所有可用资源成功交付的概率。设定每个存储节点的出错退出概率为p,则三备份存储方案的可用性为Rt=(1-p3)C3n。而我们提出的方案的可用性为Re=(1-pm+1)Ck+mn。当Re=Rt时,即(k=1,m=2)而此时我们的方案冗余度为0,三备份冗余度为2。随着冗余因子增大,可用性Re不断增大,而Rt保持不变。显然我们提出的方案在理论上能够保证较高的可用性同时降低冗余度。
由于云存储中数据的格式以及大小多样性,我们针对不同大小规模以及不同格式的数据文件进行了上传存储与云端取回响应时间实验。实验中选取的文件、大小及数据类型见表3。

表3 不同格式及大小的数据文件
实验中对表3中的文件分别进行上传存储,云端取回操作。在数据分块为10,冗余因子为1.2时,记录不同大小文件的存储响应时间如图7所示。

图7 不同大小文件存储与取回响应时间
从图7中可以看出,在相同冗余因子和文件数据分块下,对于小于50 M 的数据文件其编解码和查找所用的时间都较短,上传存储时间与取回响应时间相当,但取回响应时间要比上传存储时间长。随着数据文件的不断增大,由于上传存储所需要的编码数据量加大,向异地存储节点分发需要的时间增加,所以上传存储的时间较大幅度的增加。而采用Chord的检索在云端数据取回时提高了检索效率,降低了检索的时间,同时由于编码冗余的特性,使得只需要检索到额定数量的数据块就可以合并解码出原始文件。因此,取回响应时间虽数据块的增大变化较缓慢。
目前已经有一些相关的研究,针对云存储冗余优化方案有传统的三备份,以及网络编码冗余和喷泉码等。为了检验我们提出的基于擦除码以及Chord协议的云存储优化方案 (C擦除码)的性能。针对同样的存储文件在同样的存储条件下进行了三组对比实验。主要从文件上传与取回所消耗的时间和上分别进行实验,结果如图8和图9所示。
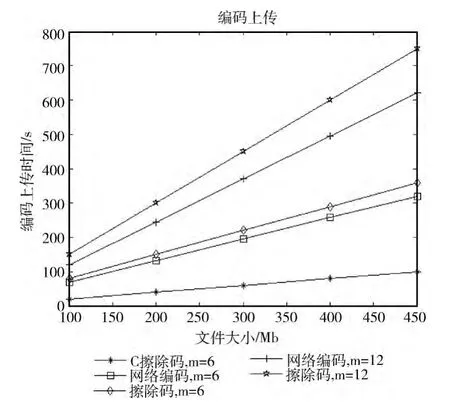
图8 不同编码方式下上传云端存储的响应时间
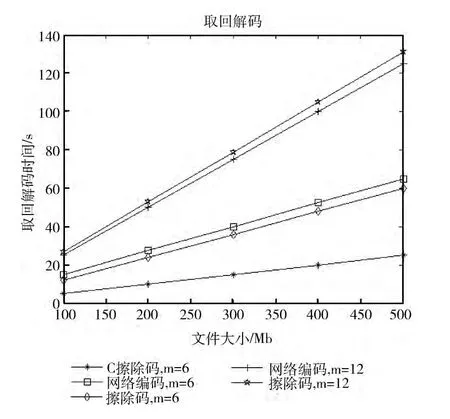
图9 不同编码方式下从云端取回解码的响应时间
通过实验,我们提出的云存储方案 (C 擦除码)能够有效的降低云端存储的冗余度,同时保障用户数据的可靠性。该方法适宜于云端大数据的存储共享,可以保障数据在云存储平台中的有效性,能够支持多用户以只读的方式快速获取大文件文件,对于小文件的读写能够高效响应,但是在对大数据文件修改上传时还需要进一步优化,以提高分布式存储编码同步效率。
3 结束语
本文提出了一种基于擦除码的高效云存储数据冗余方案,研究了云存储服务器以及运算服务器和终端节点组成的云存储系统的数据冗余优化问题。在服务器节点对原始数据文件进行擦除码,将编码后的数据块分发到各个存储节点上,在终端节点取回解码并恢复成用户所需要的数据文件。利用Chord环的分布式存储逻辑结构,提高终端节点与云存储平台间的上传与存储取回效率。该方案保障了用户云端数据可靠性的同时,降低云端存储数据的冗余度,增强了存储节点容错能力以及可伸缩性。
[1]Zhang Y,Ren SQ,Chen SB,et al.DifferCloudStor:Differentiated quality of service for cloud storage [J].IEEE Transactions on Magnetics,2012,49 (6):2451-2458.
[2]Spillner J,Müller J,Schill A.Creating optimal cloud storage systems[J].Future Generation Computer Systems,2013,29(4):1062-1072.
[3]Baldor SA,Quiroz C,Wood P.Applying a cloud computing approach to storage architectures for spacecraft [C]//Aerospace Conference,2013:1-6.
[4]Chen W,Zhao YL,Long SQ,et al.Research on cloud storage security [J].Applied Mechanics and Materials,2013,263:3068-3072.
[5]Wang C,Wang Q,Ren K,et al.Toward secure and dependable storage services in cloud computing [J].IEEE Transactions on Services Computing,2012,5 (2):220-232.
[6]AlZain MA,Soh B,Pardede E.A New approach using redundancy technique to improve security in cloud computing [C]//International Conference on Cyber Security,Cyber Warfare and Digital Forensic(CyberSec),2012:230-235.
[7]Zhu C,Xin-ran L,Yi-xian Y,et al.A redundant scheduling algorithm based on trust model for internet-based virtual computing environment [J].Advances in Information Sciences and Service Sciences,2012,4 (12):394-404.
[8]Huang Z,Lin Y,Peng Y.Robust redundancy scheme for the repair process:Hierarchical codes in the bandwidth-limited systems[J].Journal of Grid Computing,2012,10 (3):579-597.
[9]Wang J,Gong W,Varman P,et al.Reducing storage over-head with small write bottleneck avoiding in cloud RAID system[C]//ACM/IEEE 13th International Conference on Grid Computing,2012:174-183.
[10]Pamies-Juarez L,García-López P,Sánchez-Artigas M,et al.Towards the design of optimal data redundancy schemes for heterogeneous cloud storage infrastructures [J].Computer Networks,2011,55 (5):1100-1113.
[11]Zakerinasab MR,Wang M.An update model for network coding in cloud storage systems[C]//50th Annual Allerton Conference on Communication,Control,and Computing(Allerton),2012:1158-1165.
[12]Oliveira PF,Lima L,Vinhoza TTV,et al.Coding for trusted storage in untrusted networks[J].IEEE Trans Inf Forensic Secur,2012,7 (6):1890-1899.
[13]Cao N,Yu S,Yang Z,et al.Lt codes-based secure and reliable cloud storage service[C]//Proceedings IEEE INFOCOM,2012:693-701.
[14]Grange P,Mathiot JF,Mutet B,et al.Aspects of finetuning of the Higgs mass within finite field theories [J].Physical Review D,2013,88 (12):125015.
[15]Respondek JS.Recursive numerical recipes for the high efficient inversion of the confluent Vandermonde matrices [J].Applied Mathematics and Computation,2013,225:718-730.
[16]Zhang Y,He H,Teng J.Chord-based semantic service discovery with QoS [C]//Fifth International Conference on Measuring Technology and Mechatronics Automation,2013:365-367.
[17]Jie Y.A spiral curve based chord enabling resource sharing for wireless mesh networks:A location awareness and cross-layering approach [J].IEICE transactions on Communications,2013,96 (2):508-521.
