基于时间序列的PDM 文件数据块分布算法
2015-12-20夏秀峰
夏秀峰,张 羽
(1.沈阳航空航天大学 计算机学院,辽宁 沈阳110136;2.沈阳航空航天大学 辽宁省通用航空重点实验室,辽宁 沈阳110136)
0 引 言
为解决RDB (relational data base)高并发读写和水平扩展限制、PDM (product data management)数据高效存储和访问问题,将NoSQL 数据库和企业私有云存储技术应用到PDM 系统中,构建基于企业私有云环境下的PDM 文件系统,以满足海量数据存储和访问的要求是一种有益的探索和尝试。
HDFS (Hadoop distributed file system)对数据块副本采用随机放置策略,数据块分布不能根据系统运行情况而发生动态变化。随机放置策略造成文件数据块存储集中在某个节点,不仅降低系统容错性,且造成集群节点资源未能充分利用。
考虑到企业私有云环境下,影响数据节点服务性能的主要因素为文件访问数量,而非网络距离和存储空间,据此,本文提出基于时间序列的PDM 文件数据块分布算法,算法根据数据块访问量进行数据块的动态迁移,在实现数据块合理分布的同时均匀分布文件数据块副本,从而有效提高系统的容错性。
1 时间序列分析
时间序列分析方法通过对数据的动态处理及分析,根据建模方法建立相应的数据拟合模型去近似描述数据特点。通过对数据发展趋势的预测,从而采取合理的方法实现有效控制的目的。文献 [1]详细介绍了时间序列的相关知识、常用时间序列模型和预测方法。
1.1 白噪声过程
若随机过程 {Xt} (t∈T)满足以下条件则称为白噪声过程。
(1)E(Xt)=0;
(2)Var(Xt)=σ2<∞,t∈T;
(3)Cov(Xt,Xt-k)=0,(t-k)∈T,k≠0。
白噪声是平稳的时间序列,平稳时间序列的行为不会随着时间的变化而变化,因此可以通过过去的行为对未来的行为进行预测。
1.2 基本时间序列模型
p阶自回归模型AR(p)

式 (1)称为p阶自回归模型,其中i(1≤i≤p)称为自回归参数,μt 是白噪声过程。式 (1)引入滞后算子后表示为

(L)=1-1L-2L2-…-PLP称为特征方程或者自回归算子,如果特征方程(L)=0的所有根均在单位圆之外,则AR(p)模型具有平稳性。
q阶移动平均模型MA(q)

式 (3)称为q阶移动平均模型,其中θj(1≤j≤q)称为回归参数,μt 为白噪声过程。式 (3)引入滞后算子后表示为

MA(q)是由q+1个白噪声变量的加权和组成。因此有限阶移动平均过程总是平稳的,其中θ(L)=1-θ1Lθ2L2-…-θqLq。如果特征方程θ(L)=0所有根在单位圆之外,则MA(q)模型具有可逆性。
ARMA(p,q)模型是AR(p)和MA(q)的混合模型,一般描述为
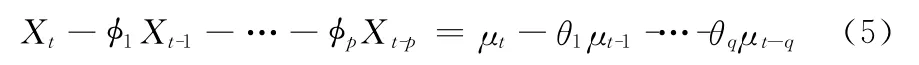
引入滞后算子后式 (5)表示为
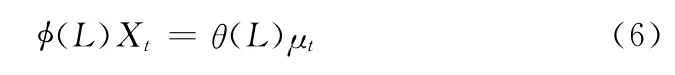
AR、MA、ARMA 模型只适用于平稳时间序列的拟合,对于非平稳时间序列则需要通过差分将其变换为平稳的时间序列。如果一个随机时间序列经过d次差分后可以变换为一个平稳的自回归移动平均过程,则该随机序列被称为自回归单整移动平均过程ARIMA(p,d,q)。
因篇幅有限,本文仅对时间序列模型做简单介绍。时间序列分析在负载均衡预测方面被广泛应用。文献 [2]介绍了常用的预测方法,并对常用时间序列模型的建立进行了详细说明。文献 [3]介绍了预测模型在云计算资源管理中的应用并展望了预测模型的发展方向。文献 [4,5]分别对预测模型进行改进,预测精度明显提高。文献 [6]通过对集群系统中节点负载特点的分析,提出服务器集群负载预测模型,有效提高了集群系统的利用率。文献 [7]介绍了时间序列模型与预测相关内容,通过实验分析对比了各时序模型在网络流量中的预测效果。
本文通过对数据块访问次数时间序列的分析,拟合出适当的数学模型预测数据块访问趋势,使用预测结果为数据块合理分布提供依据。
2 数据块分布算法
通常,HFDS采用机架感知策略实现数据块放置,将数据块优先放置于本地节点或相同机架的节点中。默认放置策略优先考虑网络传输代价,提供一种通用的放置策略。但在企业私有云环境下,网络传输代价并不是影响用户访问质量的关键因素。而且PDM 文件系统中用户访问并不是随机进行,现阶段生产和设计相关数据的访问量明显大于历史数据的访问量。因此需要根据数据块访问量合理分布数据块,以解决数据块随机放置造成的节点访问量不均衡问题,从而实现集群的负载均衡。
为提高云存储系统性能及数据的合理分布,文献 [8]提出基于一致性哈希数据分布和节点容量感知的负载均衡方法,该策略改善了存储资源负载均衡程度并优化了系统整体性能。文献 [9]基于节点网络距离和数据节点负载两种因素计算节点的负载评价值,根据评价值选择最佳的放置节点。文献 [10]综合考虑节点的存储性能和网络距离两种因素进行数据节点的选择,算法改善了数据块放置的均衡性。文献 [11]根据数据节点的状态信息动态选择节点以实现负载均衡。
结合PDM 文件访问特点和企业私有云环境优势,本文提出基于时间序列的PDM 文件数据块分布算法,将数据块访问量作为分布依据。算法在保证节点访问量平均的前提下,使文件数据块副本均匀分布在各数据节点中,从而实现集群的负载均衡并提高系统的容错性。
为减少频繁迁移对系统的影响,使用拟合数据模型对数据块访问量进行多步预测。算法根据多步预测结果选择合理的数据节点进行数据块迁移,减少频繁数据块迁移造成系统的额外开销。
下面给出算法描述,预测步长为m 步:
(1)计算当日节点平均访问量x,访问量大于等于x的节点加入S队列,小于x的节点加入T 队列,计算得到S队列和T 队列。如果n大于m,转 (10);
(2)如果S队列为空或T 队列为空,n++,转 (1);
(3)从S队列中取出节点Si;
(4)从Si中取出一个数据块赋值给变量b,找出T 队列中保存数据块b 所属文件的数据块数目最少的数据节点Tj;
(5)如果Tj已保存数据块b的副本,转 (4);
(6)数据块b加入移动集合中,将数据块b中目标节点数组中Tj值加1,从Si中删除数据块b;
(7)如果Si的访问量小于x,则将Si从S队列中删除,转 (2);
(8)如果Tj的访问量大于等于x,则将Tj从T 队列中删除,转 (4);
(9)转 (4);
(10)如果移动集合为空,则转 (13);
(11)从移动集合中取出一个数据块赋值给变量b,选择数据块b的目标数组中出现次数最多的节点作为目标节点,并将数据块b迁移至目标节点中;
(12)将数据块b从移动集合中删除,转 (10);
(13)结束。
基于时间序列的PDM 文件数据块分布算法以平均数据节点访问量为目标。算法在数据块移时避免文件数据块副本集中存储在某个节点中,使文件数据块副本分布更加均匀,因此有效提高了系统的容错性。同时算法综合考虑数据块未来多日访问量进行迁移,有效减少了数据块的频繁迁移。
3 实验结果分析
本节对文中提出的基于时间序列的PDM 文件数据块分布算法进行仿真实验。通过对本文算法、默认算法和基于存储空间的数据块分布算法 (以下简称基于存储空间分布算法)3种算法进行比较,验证本文算法的有效性。实验使用拟合数据模型预测未来五日的数据块访问量作为实验数据。在多次实验数据中随机选择一组实验进行3种算法的数据对比。
数据节点存储数据块数目对比如图1所示。从图1中看出基于存储空间分布算法使数据块均匀分布到各数据节点中。默认算法和本文算法基本实现数据块均匀分布,但与基于存储空间分布算法有一定差距。基于存储空间分布算法实现了数据节点存储空间的合理利用,但并未解决数据节点访问量不均衡问题。

图1 数据节点存储数据块数目对比
默认算法数据节点访问量如图2所示。默认算法作为一种通用的数据块放置策略能够将数据块较均匀的分布到数据节点中,但数据节点访问量差距较大容易造成集群负载不均衡问题的出现。
基于存储空间分布算法数据节点访问量如图3所示。算法能够较好的实现数据节点存储空间的均衡。但由于PDM文件访问特点造成文件访问次数差别较大。因此虽然数据节点保存数据块数目接近,但未解决数据节点访问量不均衡问题。

图2 默认算法数据节点访问量

图3 基于存储空间分布算法数据节点访问量
本文算法数据节点访问量如图4所示。算法使数据节点访问量更加平均,同时让迁移数据块均匀分布在数据节点中,有效提高了集群的容错性。
数据块迁移结果见表1,文件14数据块分别被本文算法和基于存储空间分布算法选中进行迁移,因此更容易对比实验效果。
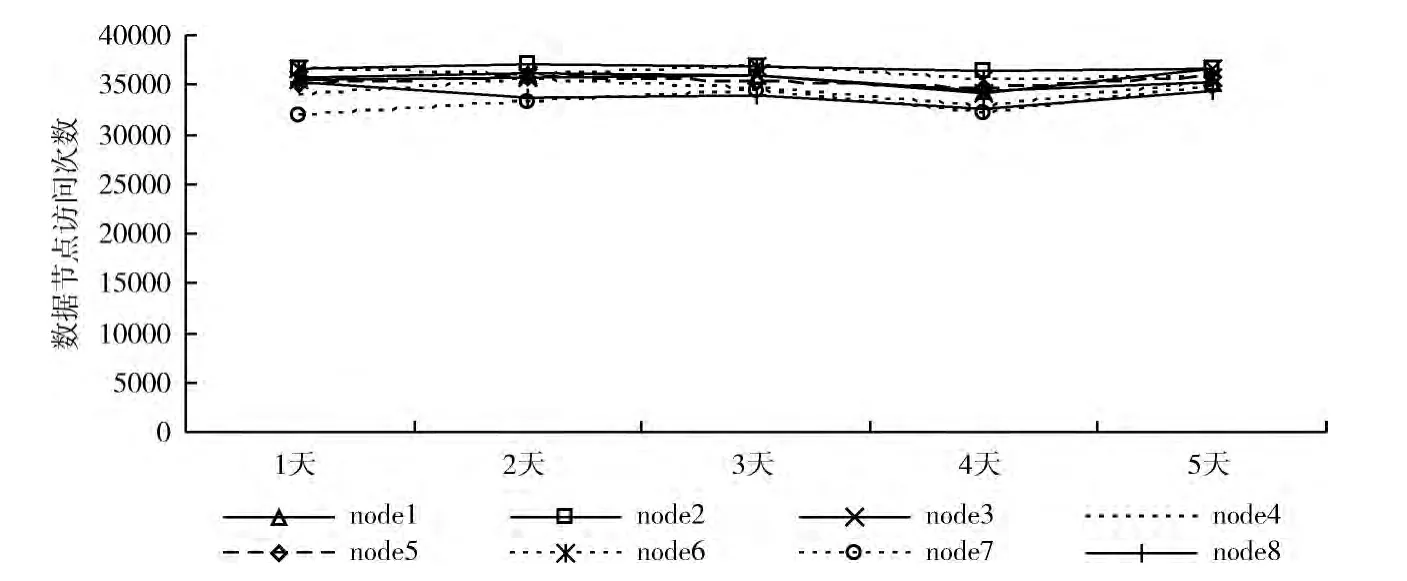
图4 本文算法数据节点访问量
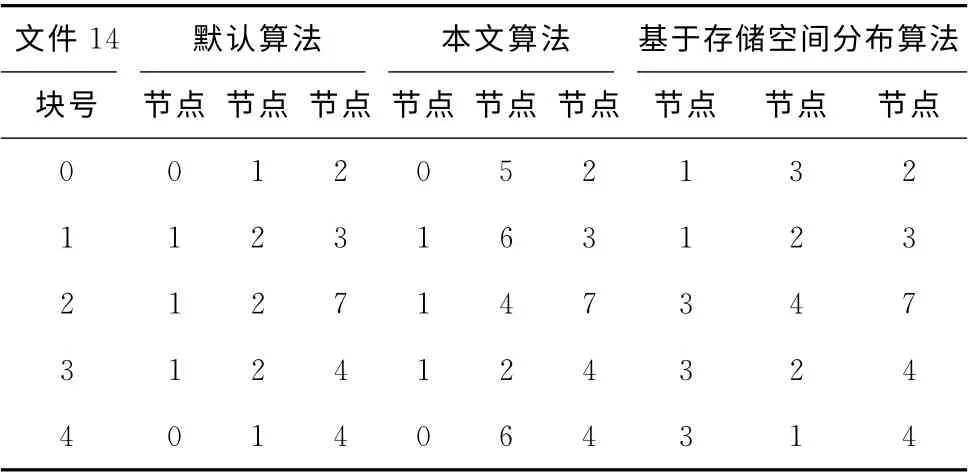
表1 数据块迁移结果
默认算法随机放置数据块,节点1存储了文件14全部数据块,节点2存储4个数据块,因此数据块存储过于集中。本文算法和基于存储空间分布算法分别对文件14进行了数据块迁移。本文算法将数据块从节点1分别迁移至节点5、节点6,同时将数据块从节点2迁移至节点6、节点4,从而使文件数据块更均匀的分布在各数据节点中。而基于存储空间分布算法使用存储空间作为评判因素,将文件数据块大量迁移至节点3中,造成节点3存储文件的全部数据块,并未有效解决迁移中数据块存储集中的问题。
实验通过数据节点访问量和数据节点存储数据块数目两方面对3种算法进行了对比。默认算法使用随机放置策略数据块基本均匀分布,但存在文件数据块存储集中的问题而且数据节点访问量差别较大;基于存储空间的数据块分布算法能够较好的实现数据节点存储空间的平均使用,但存在与默认算法相同的问题;本文算法实现数据节点访问量平均的同时减少了文件数据块存储集中的问题,有效提高了系统的容错性。
4 结束语
针对HDFS默认数据块分布算法在PDM 文件系统中存在的不足,提出基于时间序列的PDM 文件数据块分布算法。算法使用数据块历史访问记录建立拟合模型预测未来数据块访问趋势,从而进行数据块的合理分布并减少文件数据块存储集中问题的出现。通过实验对比本文算法、默认算法及基于存储空间分布算法3种算法实验数据,验证了本文算法的有效性及合理性。
[1]WANG Yan.Applied time series analysis[M].Beijing:Chi-na Renmin University Press,2012 (in Chinese).[王燕.应用时间序列分析 [M].北京:中国人民大学出版社,2012.]
[2]WU Wei,LIU Xiyu,YANG Yi,et al.Analysis method of time array and two models of ARMA and GARCH [J].Computer Technology and Development,2010,20 (1):247-249(in Chinese).[武伟,刘希玉,杨怡,等.时间序列分析方法及ARMA,GARCH 两种常用模型 [J].计算机技术与发展,2010,20 (1):247-249.]
[3]ZHANG Feifei,WU Jie,LV Zhihui.Survey on prediction models in cloud resource management schemes[J].Computer Engineering and Design,2013,34 (9):3078-3083 (in Chinese). [张飞飞,吴杰,吕智慧.云计算资源管理中的预测模型综述 [J].计算机工程与设计,2013,34 (9):3078-3083.]
[4]GAO Xingwang,WANG Qiong,OUYANG Yiming.Algorithm research of load balancing based on blending prediction model[J].Computer Engineering and Design,2010,31(16):3557-3561 (in Chinese). [高兴旺,王琼,欧阳一鸣.基于混合预测模型的负载均衡算法研究 [J].计算机工程与设计,2010,31 (16):3557-3561.]
[5]LIN Huijun,XU Rongcong.Time series prediction based on mixture of ARMA and SVR model[J].Computer and Modernization,2009,25 (8):19-22 (in Chinese).[林慧君,徐荣聪.组合ARMA 与SVR 模型的时间序列预测 [J].计算机与现代化,2009,25 (8):19-22.]
[6]QIAO Guojuan,CHEN Guang.A load balance algorithm based on prediction model[J].Computer and Modernization,2014,30 (8):91-95 (in Chinese). [乔国娟,陈光.一种基于预测模型的负载均衡算法 [J].计算机与现代化,2014,30(8):91-95.]
[7]JIANG Ming,WU Chunming,ZHANG Min,et al.Research on the comparison of time series models for network traffic prediction [J].ACTA Electronica Sinica,2009,37 (11):2353-2358 (in Chinese). [姜明,吴春明,张旻,等.网络流量预测中的时间序列模型比较研究 [J].电子学报,2009,37(11):2353-2358.]
[8]ZHOU Jingli,ZHOU Zhengda.Improved data distribution strategy for cloud storage system [J].Journal of Computer Applications,2012,32 (2):309-312 (in Chinese). [周 敬利,周正达.改进的云存储系统数据分布策略 [J].计算机应用,2012,32 (2):309-312.]
[9]LIN Weiwei.An improved data placement strategy for Hadoop[J].Journal of South China University of Technology (Natural Science Edition),2012,40 (1):152-158 (in Chinese). [林伟伟.一种改进的Hadoop数据放置策略 [J].华南理工大学学报 (自然科学版),2012,40 (1):152-158.]
[10]WANG Yongzhou,MAO Su.A blocks placement strategy in HDFS [J].Computer Technology and Development,2013,23 (5):90-96 (in Chinese).[王永洲,茅苏.HDFS中的一种数据放置策略 [J].计算机技术与发展,2013,23 (5):90-96.]
[11]YE Xianglong,HUANG Mengxing,ZHU Donghai,et al.A novel blocks placement strategy for Hadoop [C]//IEEE/ACIS 11th International Conference on Computer and Information Science.Shanghai:IEEE,2012:4-7.
