基于模糊规则的免疫算法在网络入侵中的应用
2015-12-20白鹏翔张清华杨忠明
白鹏翔,张清华,段 富,杨忠明
(1.太原理工大学 计算机科学与技术学院,山西 太原030024;2.广东石油化工学院 计算机与电子信息学院,广东 茂名525000;3.广东科学技术职业学院 计算机工程技术学院,广东 珠海519090)
0 引 言
到目前为止,基于最基本的入侵检测系统[1]可以分为两类,一类是误用检测[2],即首先建立一个已知的攻击片段的数据集,通过将监测到的行为与该数据集中的攻击数据进行匹配来判断该行为是否异常;另一类是异常检测[3],即首先为系统建立一个正常行为的文件集,通过将检测到行为与之比对做出判断。然而,不论是误用检测还是异常检测都会在检测系统中产生大量的报警,其中有绝大部分的报警是误报警,给管理人员和系统造成巨大的压力,因此找到能够减少误报警数量的方法是很迫切的。文献 [4]提出了一种利用信息熵的方法来降低误报率,大量减少误报警个数;文献 [5]中介绍一种混合的方法来降低误报率;文献 [6]中提出了利用收集机制来降低入侵系统中的误报警数量;文献 [7]中提出了利用基于Agent的关联模型来过滤误报警。在此基础上,本文通过研习人工免疫算法具有强大的自学习能力以及很好的鲁棒性等特点,在模糊规则的基础上提出一种免疫算法模型来对网络入侵中产生的报警进行二次优化,以达到减少报警的个数从而减轻系统的负载。通过实验仿真并与一些算法比较验证了本文方法具有一定的可行性和高效性。
1 模糊规则
假定给定一个目标问题P 和一个条件库T ,为了解决目标问题P,我们从条件库中选择一些满足问题的P 的条件t,由这些条件t组成的一条路径可以称为一条模糊规则[8,9],由这些条件在不同的情况下可以相互组合成为不同的模糊规则,进而这些模糊规则组合在一起成为模糊规则库。所谓模糊规则库,是模糊系统中重要的组成部分,模糊系统基于模糊规则的使用在模糊控制、图像处理以及通信和模式识别方面具有重大的应用;鉴于模糊规则的广泛使用性,将其应用在本文对网络入侵误报警的研究中,以此获得高性能的方法。因此,将模糊规则作为一种判定准则引入进来具有其特定的优势:
(1)模糊规则if-then 模式是一种比较普遍的规则,在为某两个事件的相似性上提供相关知识时,它要比基于距离的匹配函数更加灵活;拥有更丰富、更完整的模糊规则可以更好的对事件进行评价,从而获得更好的实用性并使其应用在更广阔的问题空间中;
(2)包含有模糊规则的规则库的本质是利用模糊规则可以从多源的地方获取知识,从而使规则库更加完善;同时我们不仅可以采用知识工程的方法从单个或者多个专家领域中获取更高质量的模糊规则,而且也可以通过机器学习和数据挖掘的方法从某个事件中的现有数据中学习得到模糊规则;
(3)通过个体语言规则的解释方式,模糊知识库可以被很好的理解。因此,用户可以通过回顾检查已有的模糊规则很简单的明白是如何并且为什么选择该事件,这就为用户和动态的系统之间提供一个机会,使用户和系统之间能够更好的交互。
2 基于模糊规则的人工免疫算法模型
2.1 特征选取
假定报警a2是由入侵检测系统产生的一个报警,a1是从已经存在的报警中选取的一个报警;为了确定报警a2与报警a1之间的关联程度,我们需要从两个报警中选取一些特征,从而产生一个特征向量。基于此,选取以下的5 个特征[10]作为我们本实验的特征:
(1)F1:报警a1与报警a2之间源IP 的相似度,在0到1之间;
(2)F2:报警a1与报警a2之间目的IP的相似度,在0到1之间;
(3)F3:报警a1与报警a2之间目的端口的相似度,或为0或为1;
(4)F4:报 警a1的 目 的IP 与 报 警a2的 源IP 的 相 似度,或为0或为1;
(5)F5:报警a1比报警a2早产生的程度,在0 到1之间。
对于特征F1和F2,首先将报警a1和a2的十进制IP地址转化成二进制的IP地址,之后得到两个报警高序位的相同个数再除以32就可得到F1和F2的值,例如两个报警的IP为19.168.20.43和192.168.34.17,则其对应的有18个相同的高序位,则相似度为0.56;对于特征F3可以判断a1与a2的端口号是否相同,相同则为1,不同则为0;对于特征F4,是一个比较重要的特征,因为在一个多步攻击的环境中,第一步的成功攻击往往是后续攻击的开始,黑客可以通过攻击某一个主机后攻击与之相连的主机,即a1的目的IP与a2的源IP要么相同要么不同,因此F4的值或为0或为1;对于特征F5,可以表示两个报警在1小时内产生的先后顺序,F5的计算方式如式 (1)所示
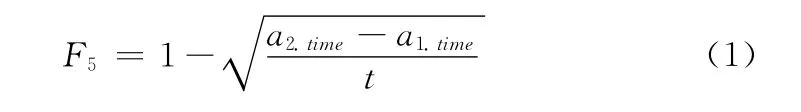
其 中,t的值 为3600,a1.time与a2.time分别 为报 警a1与a2产 生的时间。
假定报警a1与a2产生的事件分别为3:16:30与4:09:27,则特征F5的值约为0.06。
2.2 关联概率
由上一小节中的特征值可以得到两个报警之间的关联概率即为F1,F2,F3,F4,F5,用Pi,j(k)表示,其中k的取值范围为1,2,3,4,5,i与j 分别表示第i 个和第j个报警。由此可以通过式 (2)计算得到两个报警之间的相关权重为
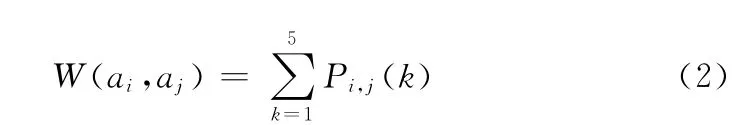
假定产生的报警为a1,a2,…,an,则由上式可以得到一个报警关联矩阵,如式 (3)所示
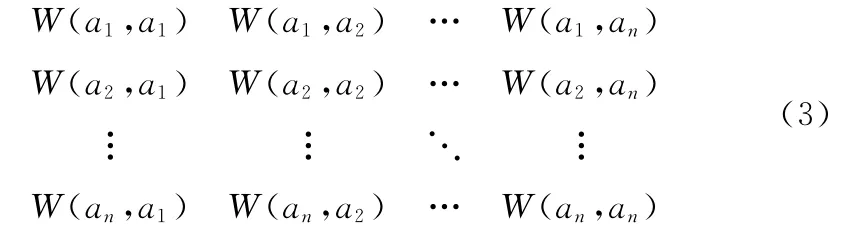
为了对两个报警之间的关联概率做更进一步的研究,需要运用第一节中提到的模糊规则。这些模糊规则可以定义上述5个特征值与分类等级间的对应关系。例如,如果两个报警之间的源IP地址与目的IP地址的相似程度很高、两个报警之间的目的端口号也是不同的、以及第一个报警的目的IP地址与第二个报警的源IP 地址也不相同、第一个报警比第二个报警产生的事件早,那么由这些特征值组成的特征向量的分类等级可表示为C。每个规则的形式可以如下表示
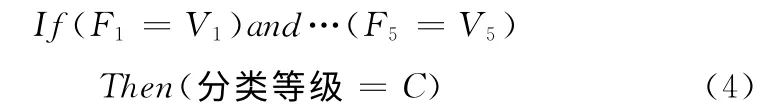
其中,V1,…,V5为关联概率F1,…,F5对应的值。
为了给定义的等级转化成一个数字表示,采用映射函数对其进行处理,如式 (5)所示
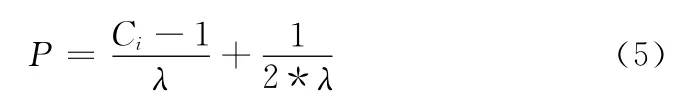
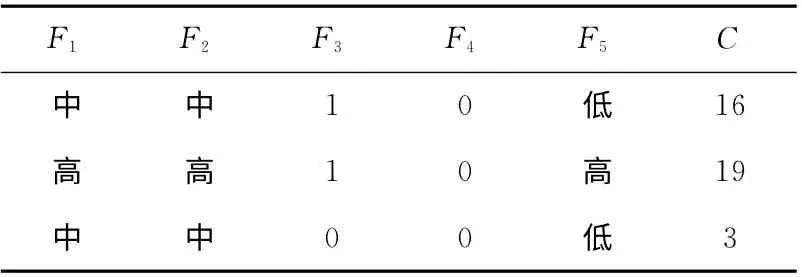
表1 部分规则
为了将输入的特征向量进行归类处理,将其与规则中的每条规则进行相容性计算,计算方式如式 (6)所示
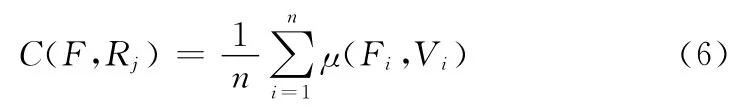
式中:n——特征数量,Fi——第i个特征值,Vi——对应规则部分的值,μ——在规则上的隶属度函数。
2.3 人工免疫优化算法
本文中采用的人工免疫算法是由Watkins提出的监督学习算法[11],算法的目的是通过对训练集中的数据进行训练产生大量的记忆细胞,从而对测试集中的数据进行分类。该方法包含多个免疫系统中的多个组成部分,有克隆选择、亲和度匹配、记忆细胞存储。
在本算法中,外来的特征向量被看作是抗原 (Ag),系统中的单元被当作抗体 (Ab),相似的抗体可以看作是识别球。该方法包含3 个阶段:产生识别球,资源竞争,选取候选记忆细胞。具体步骤如下所示:
(1)将特征向量作为抗原输入到训练系统中,使系统产生大量的记忆细胞,并对那些频繁的被刺激的记忆细胞进行复制克隆,将其储存在识别球存储单元中;产生的克隆数量依赖于抗原与记忆细胞之间亲和度的大小,亲和度是由欧氏距离所决定,如式 (7)所示
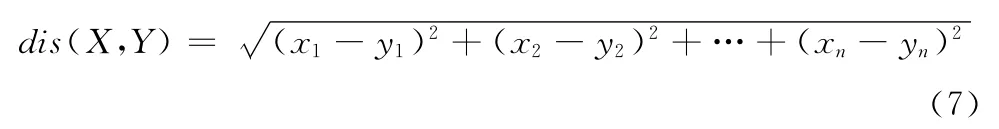
(2)接下来,将训练抗原再次与识别球存储单元中的识别球进行匹配,根据识别球与抗原之间的亲和度距离的大小来对识别球进行标记,直到将所有的识别球标记完毕后,选择将那些不具有竞争资源能力的识别球从存储单元中删去,将剩下的识别球作为对测试抗原的元素保留下来。
(3)将受刺激度大的识别球作为候选记忆细胞,如果它与训练抗原之间的亲和度比 (1)中最初的记忆细胞与训练抗原的亲和度要高,则该识别球替代原来的记忆细胞并将其放倒记忆池中;否则保留原先记忆细胞。如此重复执行直到达到预定的记忆细胞个数。
为了后续的实验需要将前面所述的模糊规则中的非数值进行转化处理为数值,以便做数值计算,例如将表1中的文字‘高’‘中’‘低’做处理后可得到对应的数值表,见表2。
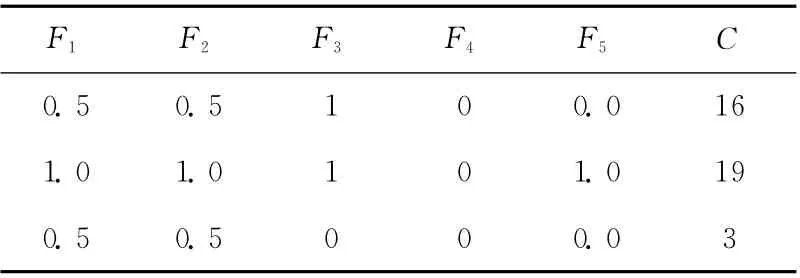
表2 处理后数值
2.4 算法流程及其步骤
综上所述可以得到本文算法的基本流程如图1所示。

图1 本文算法基本流程
流程图对应的算法步骤如下所示:
步骤1 产生初始的报警流,令初始值i=0;
步骤2 将报警流中的报警依次与先前报警进行关联处理产生特征向量,并计算关联概率;
步骤3 把计算所得的关联概率P 与所给模糊规则阈值r 做比较:如果P <r,则输入的报警是真报警,并对i进行i++计算后判断,若i<Max,转到步骤2,否则转到步骤5;如果P >r,则转到步骤4;
步骤4 将特征向量输入到免疫算法系统中并计算亲和度A 的大小:如果A >T,则报警为真报警,否则为假报警,并对i进行i++计算后判断,若i<Max,转到步骤2,否则转到步骤5;
步骤5 如果满足i>Max,Max 为报警流中报警的个数,则算法运行结束。
3 实验仿真与结果分析
为了验证本文所提的基于模糊规则的免疫算法在过滤误报警时所起的作用,实验选用1999年美国国防部高级研究计划局 (DARPA)入侵检测数据作为原始网络流量数据,并使用Snort产生报警数据作为本实验的实验数据。
本实验从DARPA99数据集中选取2000条正常的和异常的数据作为初始训练数据,利用Snort产生报警并对报警作标记,选取100条标记的真报警和400条标记的假报警作为本文算法的训练样本集;同理,从DARPA99 数据集选取10 000条正常与异常的数据作为初始测试数据,经过Snort产生报警并对其作标记,从中选取400条标记的真报警和1600条标记的假报警作为本文算法的测试样本集,将测试样本集分为200条、400条、600条、800条测试集来对算法做测试。所谓真报警即入侵检测系统正确判断异常数据为入侵并产生报警;假报警即为入侵检测系统错误判断正常数据为入侵并产生报警。本实验选取平均检测率、平均漏检率、平均测试时间、训练时间为评判标准并与KNN 分类算法作比较来对本文算法做出评估,检测率和漏检率的定义如式 (8)、式 (9)所示

其中,检测出的误报警表示正确判断误报警对应的数据为正常数据,漏检的真报警表示将异常数据判定为正常数据。实验平台为Windows7,Matlab,经过实验仿真参数设置为r=0.9,T =0.7效果较好,最大迭代次数为20,所得结果见表3。
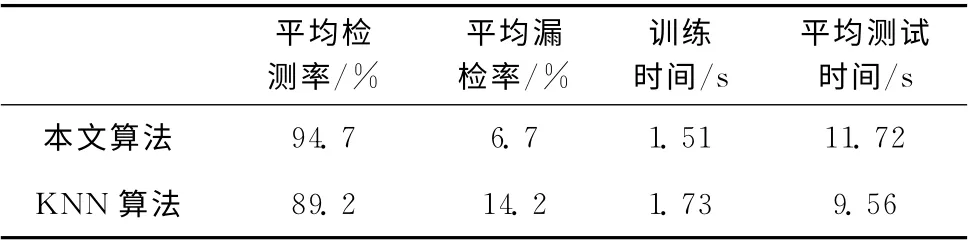
表3 两种算法的实验比对
4 结束语
本文通过采用模糊规则的方法对网络入侵中的误报警数量进行约减,在此基础上再次利用免疫优化算法进行二次约减,并与KNN 算法相比较具有一定的先进性,同时实验仿真效果表明本文算法具有一定的高效性,但是本文算法在测试时间上面仍略显不足,同时在漏检率中虽比KNN算法低,却仍然偏高,另外本文只选取报警行为的部分特征进行研究,不能全权代表所有的报警行为,因而会出现少许偏差,仍需要进行改进。
[1]JI Xiangmin,JING Lin,SHU Zhaogang.Study on intrusion detection system for next-generation internet [J].Computer Simulation,2013,30 (10):337-340 (in Chinese).[纪祥敏,景林,舒兆港.下一代互联网络入侵检测系统研究 [J].计算机仿真,2013,30 (10):337-340.]
[2]Bahrbegi H,Navin A H,Ahrabi A,et al.A new system to evaluate GA-based clustering algorithms in Intrusion detection alert management system [C]//Second World Congress on Nature and Biologically Inspired Computing.IEEE,2010:115-120.
[3]Mahdi Mohammadi,Ahmad Akbari,Hassan Asgharian.A fast anomaly detection system using probabilistic artificial immune algorithm capable of learning new attacks [J].Evolutionary Intelligence,2014,6 (3):135-156.
[4]XIA Qin,WANG Zhiwen,LU Ke.A method to detect network attacks using entropy in the intrusion detection system[J].Journal of Xi’an Jiaotong University,2013,47 (2):14-20 (in Chinese). [夏秦,王志文,卢柯.入侵检测系统利用信息熵检测网络攻击的方法 [J].西安交通大学学报,2013,47 (2):14-20.]
[5]Beng L Y,Ramadass S,Manickam S.A comparative study of alert correlations for intrusion detection [C]//International Conference on Advanced Computer Science Applications and Technologies.IEEE,2013:85-88.
[6]Al-Saedi K H,Ramadass S,Almomani A,et al.Collection mechanism and reduction of ids alert[J].International Journal of Computer Applications,2012,58 (4):40-48.
[7]Taha A E,Ghaffar I A,Eldin A M B,et al.Agent based correlation model for intrusion detection alerts [C]//Proceeding of IEEE International Conference on Intelligence and Security Informatics,2010:89-94.
[8]Ning Xiong.Learning fuzzy rules for similarity assessment in case-based reasoning [J].Expert Systems with Applications,2011,38 (9):10780-10786.
[9]SHI Xiaomei,MEI Hongyan,ZHU Tianhua,et al.A new fuzzy rule extraction method [J].Journal of Liaoning University of Technology (Natural Science Edition),2012,32 (1):22-26 (in Chinese).[史晓梅,梅红岩,朱田华,等.一种新的模糊规则提取方法 [J].辽宁工业大学学报 (自然科学版),2012,32 (1):22-26.]
[10]Huwaida Tagelsir Elshoush,Izzeldin Mohamed Osman.Alert correlation in collaborative intelligent intrusion detection sys-tems—A survey [J].Applied Soft Computing,2011,11(7):4349-4365.
[11]SHU Zhenqiu,ZHAO Chunxia,ZHANG Haofeng.Sparse coding based supervised learning and its application to data representation [J].Control and Decision,2014,29 (6):1115-1120 (in Chinese).[舒振球,赵春霞,张浩峰.基于监督学习的稀疏编码及在数据表示中的应用 [J].控制与决策,2014,29 (6):1115-1120.]
