基于改进分组遗传算法的虚拟机初始化放置算法
2015-12-18李俊涛周其力
李俊涛,周其力
(杭州电子科技大学计算机学院,浙江杭州 310018)
“云计算”作为近来IT产业发展的新热点,受到广泛关注,数据中心作为云服务的最终承载者,为应用提供资源和服务等基础性支撑,然而这些大规模计算的基础设施却消耗着大量的电力资源,并且呈逐年增长趋势。根据Amazon的估计[1],数据中心的能源消耗占其维护成本的42%。此外,不断增加的能源消耗还导致二氧化碳排放量的大幅增加,如何减少能源消耗是数据中心所面临亟需解决的问题。虚拟化技术[2]则提供了一个有效的方法来管理云计算数据中心中的资源,目前数据中心广泛采用虚拟化技术实现资源调度的实体由粗粒度的服务器向细粒度的虚拟机的转化。虚拟机的放置问题有两种情况:虚拟机的初始化放置和虚拟机的动态管理。其中初始化放置主要解决在一个没有负载的数据中心或物理服务器中放置若干个虚拟机。而动态管理主要解决由于系统条件的改变或客户应用负载的动态变化所引起的虚拟机重新分配的问题。因此,如何有效放置虚拟机资源成为云计算平台的一个研究重点。
1 相关研究
如何将云计算数据中心的虚拟机放置到合适的主机中这一问题,一般将其建模为装箱问题,而装箱问题被证明是NP问题,研究者大多采用启发式算法来进行全局化搜索[3-5],解决虚拟机的初始化放置问题。然而启发式方法大多是基于贪心算法,并配合使用一些简单规则,比如,次优配合,优先配合或最佳配合等。文献[6]将虚拟机的放置看成一维装箱问题,采用改进后的FFD算法解决虚拟机的放置问题。文献[3]通过对BF算法的改进,将其应用在大规模的云计算环境中的虚拟机放置。文献[7]使用改进的BFD算法对虚拟机放置阶段进行优化。启发式算法的优点是简单易实现,但易陷入局部最优解,难以获取全局优化解,且可能完全无法产生任何解。遗传算法作为解决NP问题的方案之一,一直被学术界所关注,一些研究已实现利用遗传算法搜索虚拟机优化放置的最优解。文献[8]提出利用遗传算法并结合模糊逻辑解决虚拟机放置到物理节点的组合优化问题。文献[9]提出了一种基于遗传算法的任务调度模型,利用迭代的遗传操作优化任务调度。尽管如此,由于遗传算法的可改进性,使得遗传算法效率并没有发挥到最大。
本文主要关注虚拟机的初始化放置问题。提出了一种改进的遗传算法来解决虚拟机的初始化放置问题,通过对其编码方式、交配过程和突变方式进行改进,以提升算法的效率。通过实验性能分析,改进后的遗传算法在能源利用率上比传统的分配算法有所提高。
2 问题描述及数学建模
可以将虚拟机的初始化放置问题描述如下:数据中心拥有多台物理主机可供分配使用,同时可以根据用户的请求产生需要分配的虚拟机若干,算法所解决的问题及即将这若干虚拟机分配到数据中心的物理主机中。假设向量P{p1,p2,…,pj}表示数据中心的物理主机序列,向量V{v1,v2,…,vi}表示需要放置的虚拟机序列,Vpj表示主机pj中的所有虚拟机。本文只考虑CPU和内存两个方面。具体符号表示如表1所示。

表1 文中所需符号的含义
由此,可知物理主机pj的CPU利用率为uj


图1 基于分组的染色体编码方式
进而可以定义当物理主机pj的CPU利用率为uj时,该主机的能源消耗为E(pj)
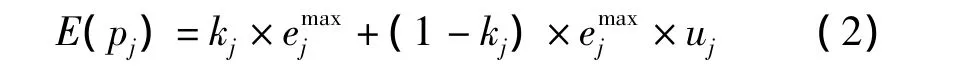
其中,kj为物理主机j空闲时能源消耗的比例;emaxj表示物流主机CPU利用率100%时的能源消耗。物理主机和虚拟机的约束条件如下
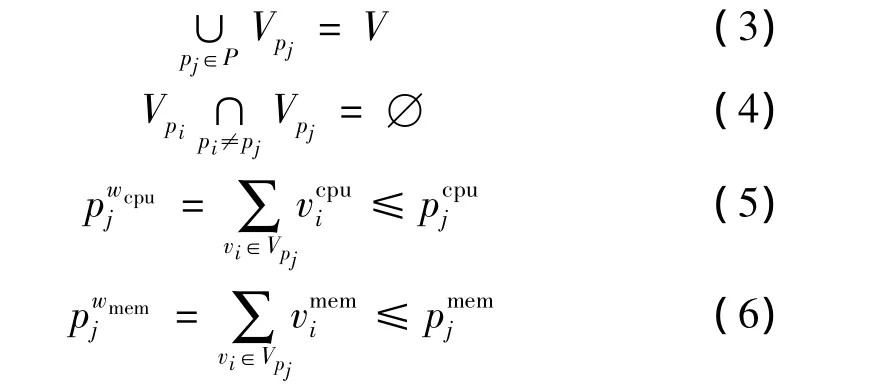
约束式(3)和式(4)保证每个虚拟机放置在唯一的一台物理主机中,约束式(5)和式(6)能够保证该物理主机中所有虚拟机的CPU利用率和内存之和不会超过物理主机的硬件条件限制。
3 算法设计与实现
3.1 染色体编码
编码选择是影响算法搜索效果和效率的重要因素,编码实现从问题的解到染色体的映射,在此表示虚拟机放置到物理节点的解。针对装箱问题,遗传算法有3种染色体编码方式:基于箱子的编码,基于物品的编码和基于分组的表示[10]。传统的遗传算法一般采用前两种编码方式,更多是面向单个物品的,不利用成本函数的优化。本文采用基于分组的编码方式,图1给出了该方法的一个具体实例。
假设数据中心含有12个虚拟机,若干台物理主机,一种情况下,可将它们划分为4个组,每组包含不同数目的虚拟机,图中上半部虚拟机2、4、7在物理主机A中,同样的虚拟机1、9、6在物理主机B中,虚拟机8、10、11、12在物理主机 C 中,虚拟机3、5在物理主机D中,但对应的染色体基因只有4个;另一种情况下,虚拟机被分为3组,每台物理主机包含4个虚拟机,可以看到此时虚拟机的分配达到一种理想的状态。此外使用这种编码方式将算法的操作中心从面向单个的虚拟,转变为包含虚拟机的组。
3.2 交叉算子
交叉算子所支配的交配过程在遗传算法中的主要作用是使后代能够继承父代双方的优秀基因,产生更优秀的后代。分组遗传算法的交配过程是通过随机选择两个父代,假设为X、Y,采用随机法选择X父代中的一段基因,将其加入到父代Y中,从而产生新的子代编码。向Y中插入新的基因时,由于是基于分组的编码,可能相同的虚拟机会出现在不同的物理主机中,如果出现就将包含相同虚拟机的物理主机从染色体编码中删除,此时会产生由于物理主机删除而出现没有分配的虚拟机,需要为这些未分配的虚拟机重新分配编码中的物理主机。具体交叉过程如图2所示。

图2 交叉产生子代的过程
3.3 变异算子
遗传算法的基本思想是通过模拟自然界生物的进化过程来求解,那么变异对产生优秀个体具有重要的作用。在本文的分组遗传算法中,摒弃通过随机删除编码中的物理主机来实现变异过程,而是采用资源效用函数式(7)来决定删除哪个主机。此函数能反映该物理主机资源的综合使用情况,如果该主机中的虚拟机放置越合理,则其资源利用率就越高,函数值也就越大,删除的概率就越小
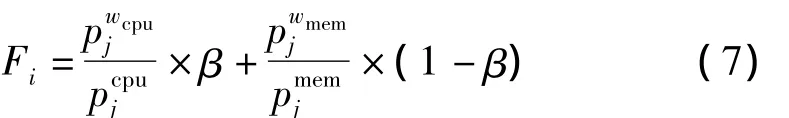
如此,每次变异过程删除的物理主机的Fi值都是最小的,保证了每次变异都是向着更优化的方向前进,对于由于删除造成的未分配的虚拟机采用上述方法将其加入到编码的物理主机中。
3.4 适应度函数
适应度函数是评价群体中个体好坏的标准,是模拟自然选择的唯一依据,适应度函数的选取直接影响到遗传算法的收敛速度以及是否能够找到最优解。根据适应度的大小,对个体进行优胜劣汰,是驱动遗传算法的动力。本文以实现资源的高效利用为目标,因此采用式(8)作为遗传算法的适应度函数
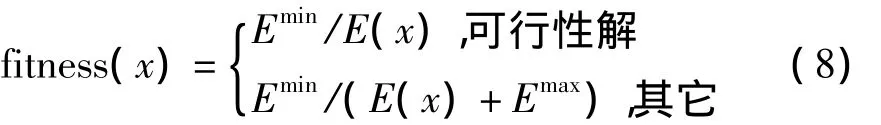
其中,Emin为主机能源消耗的最低值;Emax为主机能源消耗的最大值;而E(x)代表在演化过程中针对一种可行性解时,主机资源消耗的总和。此适应度函数能够保证能源消耗越小,适应度函数值越大。
4 仿真实验与分析
遗传算法采用Java语言实现,由于所解决问题为虚拟机的初始化放置,暂时还没有实际数据可用,所以本文使用随机产生的数据,通过一系列的实验来评估算法的性能和稳定性。具体的实验环境如表2所示,虚拟机所需的CPU和内存的大小为[300,3 000]之间的随机数,而物理主机的CPU和内存的大小则从集合{1 000,1 500,…,55 000}中随机选取,反映数据中心能源消耗的式(2)中kj值及资源效用函数式(7)中的β值均取取0.7。对于每次实验设定初始种群的规模为200,终止条件为连续进行20次迭代没有产生更好的解。

表2 实验环境参数
为了更好的对比评估,本文也实现了降序首次适应算法(FFD),以及传统的遗传算法(GA)作为评估所提算法(MGA)的基准。FFD作为最流行的一种启发式算法,一般用于解决虚拟机的放置问题[8],GA算法是所有改进遗传算法的基础,经常用来评估改进算法的性能优劣。因为每个实验的数据都是随机产生的,所以每个实验都重复10次,尽可能减小随机数据带来的影响,计算10次实验的平均值作为本次实验的最终数据。本文主要考虑能源消耗和花费时间这两个方面,具体的实验结果如图3~图4所示。
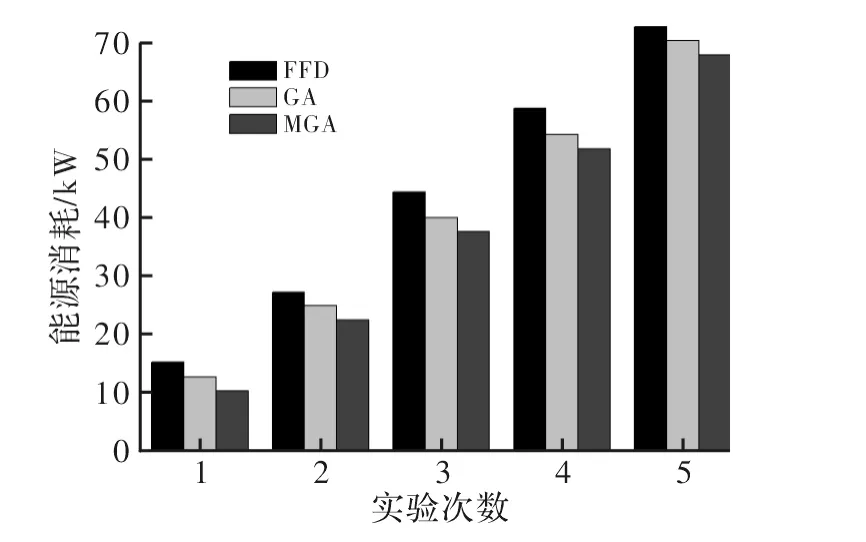
图3 能源消耗对比
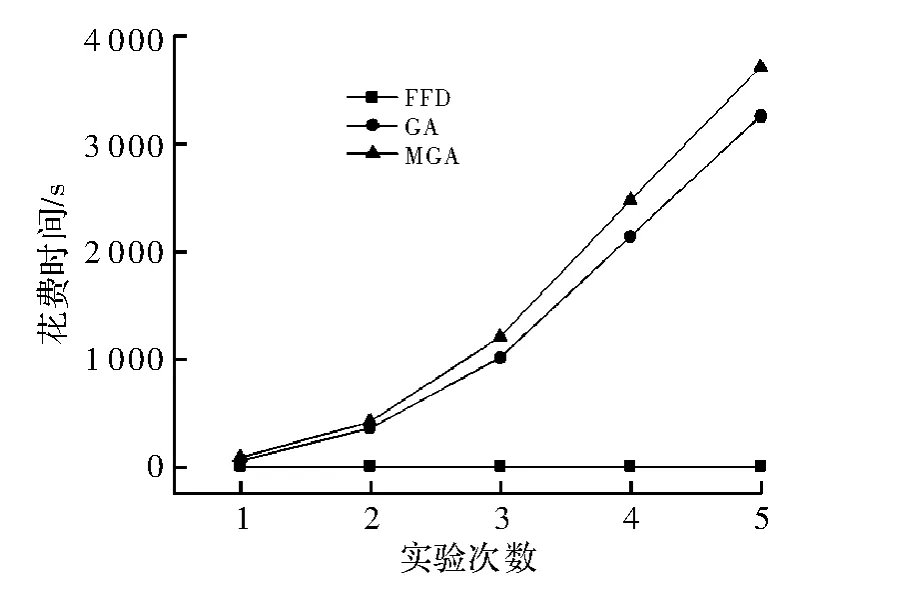
图4 花费时间对比
从图3可以看出,本文的MGA算法对于传统的GA算法以及FFD算法在能源消耗方面有明显的下降,平均下降幅度分别达到了8.5%和16.8%。说明本文算法在虚拟机的初始化配置方面实现了更好的优化,从而减少了能源消耗。而对于花费时间方面,如图4所示,FFD算法的花费时间均<1 ms,具体原因可理解为FFD算法具有确定性,针对每次试验FFD都能在短时间内达到稳定状态。而GA和MGA算法的花费时间均超过了1 ms,并且随着虚拟机总数的增加呈线性增大,MGA算法相对于GA算法的花费时间所增加的时间相差不大,考虑到MGA算法在能源消耗方面的优势以及算法运用在虚拟机初始化放置的具体环境,时间的增加幅度可以接受。
5 结束语
本文提出的改进的遗传算法采用分组方式的虚拟机编码方式,先以物理主机为粒度采用资源调度,然后再对重复虚拟机进行个别插入,使得数据中心的资源分配更加细化,同时引入效用函数作为变异算子,通过能源相关的适应度函数的驱动,仿真实验结果显示,该算法在能源消耗方面比FFD算法和传统的GA算法具有明显的优越性。在此后的工作中,需在多个指标方面对算法进行优化改进,进一步提高算法的性能和可扩展性。
[1] Kusic D,Kephart J O,Hanson J E,et al.Power and performance management of virtualized computing environments via lookahead control[J].Cluster Computing,2009,12(1):1 -15.
[2] Goldberg R P.Survey of virtual machine research[J].Computer,1974,7(6):34 -45.
[3] Li B,Li J,Huai J,et al.Enacloud:an energy - saving application live placement approach for cloud computing environments[C].IEEE International Conference on Cloud Computing,2009:17 -24.
[4] Ajiro Y,Tanaka A.Improving packing algorithms for server consolidation [C].International CMG Conference,2007:399-406.
[5] Gupta R,Bose S K,Sundarrajan S,et al.A two stage heuristic algorithm for solving the server consolidation problem with item-item and bin-item incompatibility constraints[C].IEEE International Conference on Services Computing,2008:39-46.
[6] Verma A,Ahuja P,Neogi A.pMapper:power and migration cost aware application placement in virtualized systems Middleware 2008[M].Berlin Heidelberg:Springer,2008.
[7] Beloglazov A,Buyya R.Energy efficient resource management in virtualized cloud data centers[C].Proceedings of the 2010 10th IEEE/ACM International Conference on Cluster,Cloud and Grid Computing,IEEE Computer Society,2010:826-831.
[8] Xu J,Fortes J A B.Multi- objective virtual machine placement in virtualized data center environments[C].Green Computing and Communications(GreenCom),2010 IEEE/ACM Int'l Conference on & Int'l Conference on Cyber,Physical and Social Computing(CPSCom),IEEE,2010:179 -188.
[9] Jang S H,Kim T Y,Kim J K,et al.The study of genetic algorithm -based task scheduling for cloud computing[J].International Journal of Control and Automation,2012,5(4):157-162.
[10] Cecchet E,Chanda A,Elnikety S,et al.Performance comparison of middleware architectures for generating dynamic web content[C].New York:Proceedings of the ACM/IFIP/USENIX 2003 International Conference on Middleware,Springer- Verlag,2003:242 -261.
