自然场景文本区域定位
2015-12-15黄晓明高陈强田阳阳
黄晓明,高陈强,田阳阳
(重庆邮电大学信号与信息处理重庆市重点实验室,重庆400065)
0 引言
智能拍照手机的广泛普及,使得人们获取场景中高质量的图像变得十分便利。现实中,自然场景的文本分布广泛,如路标、商店名称、海报、招牌等。这些文本提供了有关场景的重要信息,是理解图像内容的重要线索。定位和识别场景中的文本能够应用于多种场合,如搜索引擎、翻译或导航中。自然场景中文本定位的难点在于场景的多样性和文本的多样性,不同的场景有不同的干扰,如窗户、玻璃,树木等,而文本可能存在光照不均、倾斜、污染、颜色,大小不同的情况。
当前场景文本定位的方法可以粗略地分为3种。第1种是基于学习的,文献[1-2]首先将图像分割成一系列片段,然后提取片段的特征,如纹理、小波、梯度直方图等,最后用一些常见的分类器,如支持向量机,AdaBoost(adaptive boosting)将片段分为文本和非文本,最后将文本片段组成一个完整的文本。基于学习的方法通常需要在多个尺度空间上进行,所以运算时间很长,并且学习很容易受训练样本的限制;第2种是基于连通域,文献[3]先将图像灰度化,然后同时在灰度化和取反的图像进行二值化,之后再进行连通域分析,最后根据连通域的位置关系将文本进行定位。文献[4]首先利用局部颜色散布分析,框出存在文字的区域,然后对文字的区域合并和筛选,最后定位出文本的区域。基于连通域的方法虽然不需要学习,但是存在较多参数和阈值的设定,并且有着经验性,无法自适应图像的大小;第3种是两者的结合,文献[5]首先利用文本区域检测器来估计文本的位置和尺度,并用二值化的方法将文本分割成一系列的候选文本,接着训练一个条件随机场模型,然后利用这一模型将非文本区域滤除。虽然这一方法结合了前面2种方法的优点,但训练过程时间长,同时,也存在参数较多的问题。为此,我们提出了基于最大极值稳定区域[6]、颜色聚类和视觉显著性的自然场景文本定位的方法。
分析自然场景文本的特点,发现文本内部的灰度变化都比较小,而文本和背景的灰度对比度一般都很大,是属于图像中的极值稳定区域。最大极值稳定区域算法能够提取出区域内部灰度变化不明显但和背景对比强烈的连通部分。另外从设置自然场景文本的目的考虑,自然场景文本区域大部分是为了引起人们的视觉注意,所以在颜色、纹理等方面和邻域相比更加突出。而视觉显著性能够评估区域在视觉中的独特性和稀缺性,可以利用来滤除非文本区域。
本文首先将彩色图像转换成灰度图像,然后在灰度图像上提取最大极值稳定区域,将提取的区域二值化后得到候选的字符连通域。然而,最大极值稳定区域缺少对图像颜色信息的处理,这可能导致在提取时遗漏候选区域。为此,对原始的彩色图像进行聚类,再对聚类后图像进行二值化得到新的候选字符连通域,对于这2部分候选区域进行非显著性区域滤除以及先验信息的限制,最后将候选字符连成文本行。本文方法涉及文本连通域分析,不需要大量训练数据和漫长的训练过程。而合理的显著性区域提取方法的利用能够有效地判定文本和非文本区域,所以不需要大量严格的先验信息。最后在公开发表的ICDAR 2003[7]文本定位竞赛数据集上进行测试,验证了本文方法的有效性。
1 自然场景文本定位系统设计
本文提出的整个文本定位系统如图1所示。为了充分利用场景文本中图像的信息,系统利用2种方法进行候选连通域的提取。首先,提取的是图像的最大极值稳定区域的二值化模板,然后对二值化模板进行连通域的分析,得到候选的连通域。最大极值稳定区域是在灰度图像上提取,所以没有利用彩色信息。而彩色信息在文本定位中有很重要的作用,经观察,文本中的颜色一般跟周围背景对比很鲜明。因此,采用quick shift[8]进行颜色聚类,同样对聚类后的图像二值化,然后,进行连通域的分析,得到候选的连通域。对于得到的每个连通域计算其显著性映射值,将其与整个图像的显著性均值进行比较,超过一定阈值的连通域则保留。最后,依据文本的一些先验信息得到包围文本区域的包围盒。

图1 系统结构框图Fig.1 Block diagram of system structure
1.1 基于最大极值稳定区域的候选区域提取
最大极值稳定区域(maximally stable extremal regions,MSER)是由Matas[6]等提出的一种仿射特征区域提取算法。MSER先将图像转换成灰度图像,然后在一定的阈值下将图像转换成一系列的二值图像,随着亮度阈值的增加或者减少,区域不断地出现、生长和合并。2个不同阈值间的区域变化不超过一定阈值就能够被认为是稳定的。MSER的数学定义:定义图像I为区域D到灰度S的映射I:D∈Z2→s,其中,s满足全序结构。定义像素间的邻接关系A⊂D×D。则图像中的区域Q⊂D可定义为图像上满足连接关系的连通子集,即对于任意点p,q∈Q,有(1)式成立
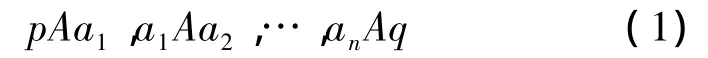
(1)式中,ai∈Q,i=1,2,…,n。
定义Q边界的∂Q为

对于∀p∈Q和∀q∈∂Q,有I(p)>I(q)成立,则称Q为极大值区域,反之为极小值区域。对于一组相互嵌套的极值区域Q1,Q2,…,Qi-1,Qi,…。如果其面积变化率为

在i处取得局部最小值,则称Qi为最大极值稳定区域。
MSER能够同时提取图像中最大极值稳定区域和最小极值稳定区域,最小极值稳定区域是在灰度图像反转后提取的。得到极值稳定区域后,将稳定区域赋值为1,将其余区域赋值为0,得到MSER的二值化模板。对二值化模板进行连通域分析,就得到了候选的连通域。最大极值稳定区域算法能够提取跟背景亮度对比强烈的文本,但如果文本跟背景亮度相差不大或者图像存在模糊时,其效果会下降很多。MSER区域提取如图2所示,图2a背景和前景对比鲜明,MSER提取的效果很好,文本区域明显。图2c背景复杂,提取出的MSER区域将文本区域和背景混肴在一起。
1.2 基于颜色聚类的候选区域提取
最大极值稳定区域只在灰度图像上进行处理,
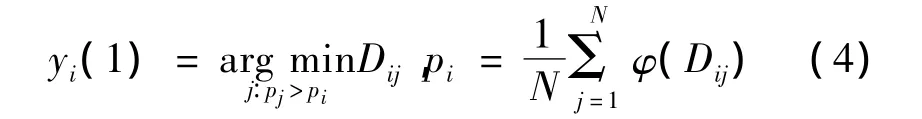
(4)式中:yi(1)代表的是特征空间中点的下一个位置;Dij=d2(xi,xj)代表的是2点之间的距离;φ(.)是核函数,一般选择高斯核函数;N是特征空间中点的个数。通过不断移动,所有点连成了一颗树,再通过一定的阈值将树分割成一个森林,这样森林里的每棵树就是一个聚类。特征空间是一个五维空间,包含转换到Lab空间的3个颜色分量和2个空间信息。
本文首先采用quick shift算法对图像进行聚类。每个像素都有一个相对应的类别标签,一般认为图像中整个字符区域都有相似的颜色。经过聚类后,颜色的类别数大大减少了,从而增大了字符区域和背景的对比度。这样,图像灰度化后经过类似MSER的处理,即对灰度图进行2次二值化处理,2次处理是为了获得亮文本和暗文本。获得聚类图像的二值化结果之后,对它们进行连通域分析,就得到文本区域的候选区。
基于颜色聚类的候选区域提取结果如图3所示,从图3中可以看出,经聚类后如图3a所示,将图3a的结果经过灰度化后,再将灰度范围[0,255],用颜色蓝到红之间映射可以得到结果如图3b所示(在彩色情况下显示)。从图3b可以看出,暗文本区域占据的是蓝色区域,其对应的背景占据的是红色区域。亮文本区域占据的是红色区域,而对应背景占据的为黄色区域,于是设定阈值为灰度范围中值。暗文本图3c是将高于中值的区域赋值为1,低于中值的为0。亮文本图3d则反之。
1.3 显著性滤除和先验信息限制
上面的2种方法能够把大部分的文本检测出来,但是同时也引进较多的非文本区域,另外我们也需要把单独的字符连成文本词,这样有利于后续的处理。所以忽略了文本和背景间的颜色对比,但这一信息在文本定位中起重要作用,采用颜色聚类分析能够和灰度图像上提取的最大极值稳定区域构成互补。颜色聚类采用的算法是quick shift。
quick shift是由mean shift[9]改进而来的。mean shift的思想是将数据点分配给隐含概率密度函数的某个模型。它的优点是聚类的类别数不需要预先知道,并且聚类的结构可以是任意的,它的缺点是计算复杂度太高。quick shift改进了这一缺点,它不需要使用梯度来寻找概率密度的模式,而仅仅是将每个点移动到使概率密度增加的最近的点来获得,公式为

图3 基于颜色聚类的候选区提取Fig.3 Region extraction based on color cluster
对于较多非文本区域的问题,从显著性区域考虑:一方面,文本定位应用一般是为场景字符识别做基础,于是当我们拿着智能手机或者摄像机来获取这些图像时,一般会对准字符,以便使字符落在镜头里;另一方面,从人们设置场景文本目的出发,场景中的文本集中于海报、广告牌、店名、提示、警告等,所有这些都是为了引起人们的注意,所以,文本大部分是场景中的显著区域。从这2个方面出发,可以利用目前较好的显著区域检测方法来滤除非文本的连通区域。
为了将显著性用于滤除非文本区域,首先要计算出整幅图像的显著性均值,在得到候选的连通域后,再计算连通域所包围的原图部分的显著性均值。如果这部分均值大于整幅图像的,那么就保留相应的连通域,否则丢弃。整个过程如图4所示。
这里的显著性映射是将图像抽样成一些随机的感兴趣区域[10]。采用这种方法的理由主要是这一方法仅需要调节一个参数,运算时间中等,并且能够在原图上进行操作。其流程如图5所示,对于一幅图像,第1步,用高斯滤波器进行滤波并将三原色(red,green,blue,RGB)空间转换成Lab空间;第2步,随机生成n个窗口,对于每个窗口,计算出面积Area与灰度和sum的比,即
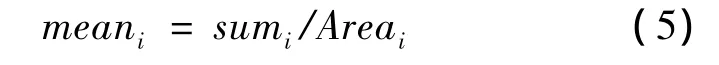
然后,依据(6)式计算窗口中每个像素Ii,j的显著性映射


图4 基于显著性的区域滤除Fig.4 Region filter based on saliency
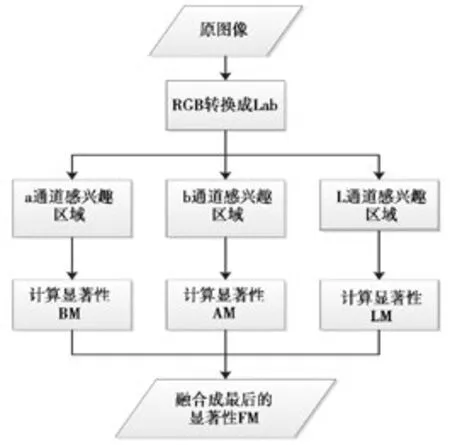
图5 显著性提取流程图Fig.5 Flow of saliency extraction
第2步是在3个通道上分别进行的,所以最后的显著性映射要采用欧式距离把颜色空间的显著值融合在一起。
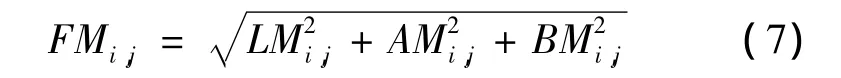
此外,采用字符的先验信息如大小、长宽的比例来滤除,但没有像一般连通域分析方法那样引入众多参数来进行滤除。有了前面的基础,我们可以仅仅用大小和长宽比这2个先验信息来滤除。而字符连成文本词,也没有采用训练的方式获取字符间的连接关系来得到文本词,而是采用形态学的膨胀腐蚀来实现。显著性滤除和文本行构造如图6所示,图6a表示显著性映射的灰度图,同样,将灰度范围用颜色蓝到红进行映射得到图6b,从图6b可以看出,文本区域属于红色区域,代表其显著值高,而背景部分属于蓝色,代表其显著值低。将图3得到的亮暗文本经过显著性滤除后可以得到图6c,对图6c进行水平方向膨胀,然后根据文本行的长宽比进行滤除可以得到图6d。

图6 显著性滤除Fig.6 Filter based on saliency
2 实验结果及分析
为了验证本文方法的有效性,采用的是公开发表的ICDAR 2003文本定位竞赛数据集[7]。该数据集包含2部分:一部分用来训练;另一部分用于测试。由于没有采用学习的方式,我们利用测试部分的数据进行实验。测试部分数据包含251张来自不同场景,不同光照和不同像素大小的图片。评价标准采用的是正确率和召回率,可以表示为
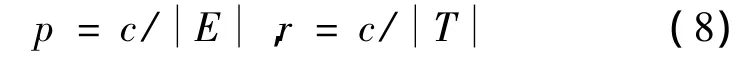
(8)式中:正确率p等于正确估计的目标个数c除以总共估计的目标总数;召回率r为正确估计的目标个数c 除以图像中原有的目标总数。因为定位系统标记的方框无法和人类标记的一模一样,所以为了使评价标准更加合理,ICDAR2003文本定位竞赛重新定义了正确率和召回率。首先,定义2个矩形(e1,e2)的重合度ma为2倍的交叉面积除以各自面积的和,即
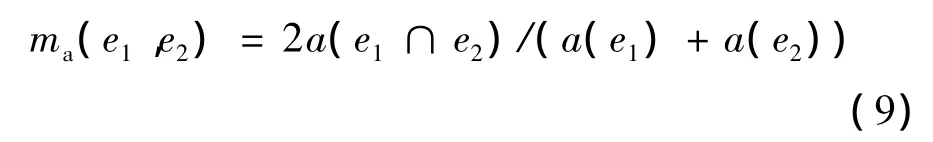
(9)式中,a(e)是矩形e的面积。对于一系列的矩形E,某个矩形e与其的最佳匹配为
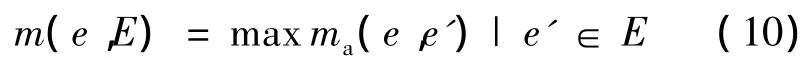
新的正确率和召回率可定义为

另外,综合了正确率和召回率的f测量可定义为

表1列出不同算法在ICDAR2003数据集上的性能,文献[11]是采用连通域分析的方法,文献[11]中定义了6个不同类型的先验信息,如文本区域的大小、区域的交叉比例、区域轮廓梯度等来滤除非文本区域。有了显著性的评估,本文仅采用2个更加合理的先验信息来滤除非文本,分别为文本区域的大小和高宽比,本文设定为
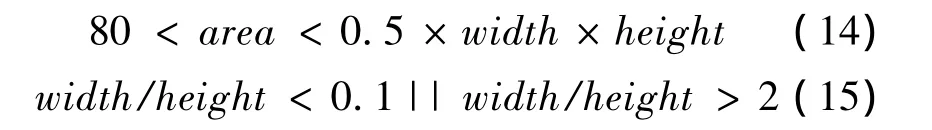
(14)—(15)式中:area代表文本连通域的大小;width代表图像的宽度;height代表图像的高度。

表1 文本定位算法评估Tab.1 Evaluation of text detection algorithm
文献[2]是采用训练的方法,这一方法需要在多个尺度上对图像进行处理,而且必须预先有训练的样本。本文方法能在原图上进行处理,无需训练的数据和流程。从表1可以看出,后4行是一些参加竞赛的算法。前2种方法也都是基于训练的,采用的分类器为支持向量机,不同的是提取的特征,分别为边缘特征和纹理特征。后面2种是基于连通域分析和先验信息滤除。从表1可以看出,本文算法正确率达到了68%,召回率为60%,优于其他的算法。部分定位效果如图7所示,分别选取了几种不同的情况,分别为大字体、侧面角度、草地干扰、一般情况以及窗户干扰。从图7可以看出,本文方法能够有效地去除砖头、草地、窗户等影响。

图7 一些文本定位的例子,文本区域由蓝色标记Fig.7 Some example results of text localization,and the localized text regions are marked in blue
3 结束语
最大极值稳定区域对于区域的视点、尺度、光照的变化有较强的鲁棒性,但是对于图像模糊和灰度对比度不强烈的区域效果下降很多,这时通过对原图进行聚类,然后二值化,能够进一步将潜在的字符区域提取出来。而引入的非字符区域能够通过显著性和一些先验信息进行有效地滤除。本文在公开发表的ICDAR 2003文本定位竞赛数据集上进行测试,验证了本文方法的有效性。
[1]LEE J J,LEE P H,LEE S W,et al.AdaBoost for Text Detection in Natural Scene[C]//CHAUDHURI B B.ICDAR.Los Alamitos:IEEE Computer Society,2011:429-434.
[2]GRZEGORZEK M,LI C,RASKATOW J,et al.Texture-Based Text Detection in Digital Images with Wavelet Features and Support Vector Machines[C]//BURDUK.Proceedings of the 8th International Conference on Computer Recognition Systems CORES 2013.Wroclaw:Springer International Publishing,2013:857-866.
[3]GATOS B,PRATIKAKIS I,KEPENE K,et al.Text detection in indoor/outdoor scene images[C]//Proc.First Workshop of Camera-based Document Analysis and Recognition.Seoul:IEEE Computer Society,2005:127-132.
[4]周慧灿,刘琼,王耀南.基于颜色散布分析的自然场景文本定位[J].计算机工程,2010,36(8):197-199.
ZHOU Huican,LIU Qiong,WANG Yaonan.Text Location in Natural Scenes Based on Color Distribution Analysis[J].Computer Engineering,2010,36(8):197-199.
[5]PAN Y F,HOU X,LIU C L.A hybrid approach to detect and localize texts in natural scene images[J].Image Processing,IEEE Transactions on,2011,20(3):800-813.
[6]MATAS J,CHUM O,URBAN M,et al.Robust widebaseline stereo from maximally stable extremal regions[J].Image and vision computing,2004,22(10):761-767.
[7]LUCAS S M,PANARETOS A,SOSA L,et al.ICDAR 2003 robust reading competitions:entries,results,and future directions[J].International Journal of Document A-nalysis and Recognition(IJDAR),2005,7(2-3):105-122.
[8]VEDALDI A,SOATTO S.Quick shift and kernel methods for mode seeking[M].Berlin Heidelberg:Springer International Publishing,2008:705-718.
[9]COMANICIU D,MEER P.Mean shift:A robust approach toward feature space analysis[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2002,24(5):603-619.
[10]VIKRAM T N,TSCHEREPANOW M,WREDE B.A saliency map based on sampling an image into random rectangular regions of interest[J].Pattern Recognition,2012,45(9):3114-3124.
[11]YI C,TIAN Y.Assistive text reading from complex background for blind persons[M].Berlin Heidelberg:Springer International Publishing,2012:15-28.
