网络舆情事件的主动感知实践
2015-12-14黄炜姚嘉威
黄炜++姚嘉威


〔摘要〕随着网络时代的到来,网络数据呈指数爆炸式增长,主题的模糊性越来越明显。同时多元非结构性的数据使得传统的聚类算法在网络舆情事件的发现越来越困难,不能满足高效,精准,及时、有效的感知需求。本文引入LDA聚类算法,基于主题生成模型,挖掘数据背后的语义关联,设计并且实现舆情事件的热点主动感知系统。通过数据实验表明,该系统能够快速、高效地发现事件主题,克服偏移词的干扰,从而实现网络舆情事件热点的主动感知。
〔关键词〕网络舆情;热点事件;LDA;聚类
DOI:10.3969/j.issn.1008-0821.2015.10.002
〔中图分类号〕TP391〔文献标识码〕A〔文章编号〕1008-0821(2015)10-0007-05
Research on Detection of Network Public Opinion EventHuang Wei1,2Yao Jiawei1
(1.School of Economy and Management,Hubei University of Technology,Wuhan 430068,China;
2.School of Management,Wuhan University of Technology,Wuhan 430070,China)
〔Abstract〕With the era of cloud computing and data arrival,the amount of data the exponential explosion,ambiguity and complexity increase and the theme of the more obvious,and massive multiple non-structured data,the traditional clustering algorithm is found and perceived significantly more and more limitations in the event of network public opinion,can not meet the high efficiency,accurate,timely,effective demand.This paper introduced the modern LDA clustering algorithm,which was based on the theme of generation model,capable of semantic association mining behind the data,through the continuous evolution of reasoning,in order to explore the data hidden value,design and implementation of public opinion events hot perception system.Through a large number of experimental data obtained,the system could efficiently and quickly found the data subject,accurately grasp the core essentials,and ignore the interference of individual words,so as to determine the perception of Internet public opinion hotspot.
〔Key words〕network public opinion;hot topic event;LDA;clustering
网络信息的爆发式增长,传统的分析方法已经不能适用这样的环境。很多垃圾信息充斥着互联网,导致越来越多的信息资源并没有被人们所利用。与此同时,泛在网络和自媒体的快速发展正改变着传统信息传播的媒介和方式,凭借其开放性、实时性和自由性,迅速占领了网络应用市场,例如微博和微信。人们利用这些工具进行随时随地的信息发布和传播,从而使社会的各种矛盾通过网络不断展现和放大,产生了较大的负面影响。如何及时发现和感知人民群众所关心和关注的热点,促进网络文明社会的和谐发展,在新形势下显得格外重要。
基于主题发现的LDA[1]文本聚类在此需求下应运而生,旨在辅助用户快速有效地找到所需资源,提供更精准的主题信息服务。本文引入LDA聚类算法进行海量数据处理,分类汇总,提炼数据背后的关联主题,从而提高信息检索和主题发现的精准率,为准确把握网络舆情事件的热点主题服务。
1LDA与舆情热点感知
11LDA主题模型
一般传统聚类算法按照处理方式的不同通常可以分为6类:层次法,划分法,密度法,网格法,模型法和约束法[2]。而基于概率法的LDA(Latent Dirichlet Allocation),简称隐含狄利克雷分配,是近年来发展起来的一种重要的离散数据集合的建模方法[3]。LDA基于一个常识性假设,文档集合中的所有文本均共享一定数量的隐含主题。基于该假设,它将整个文档集特征化为隐含主题的集合,而每篇文本被表示为这些隐含主题的特定比例的混合。LDA作为新型数据挖掘和人工智能领域已经成为热门技术,广泛应用于信息检索,机器学习,自然语言处理研究,已经取得一些成果[4-7]。在文本聚类领域引入LDA算法,是一种在无监督学习下,突破传统聚类方法以词语重复度作为相似计算的依据,发现文字背后的语义关联,解决同义词和多义词噪声问题,完成大数据计算环境下的降维。在海量数据中提取精准的主题,使信息检索与主题发现更加智能化,网络舆情事件热点特征的感知与提取更加精准[8]。endprint
2015年10月第35卷第10期现?代?情?报Journal of Modern InformationOct,2015Vol35No102015年10月第35卷第10期网络舆情事件的主动感知实践Oct,2015Vol35No1012舆情热点感知
随着网络自媒体数据量的不断增加,网民逐渐成为互联网主宰者,他们的言论往往是实时的最有影响的舆论来源。话题发现与跟踪技术(TDT)[9]就是在这种环境下产生,它是针对信息发现和信息过载提出一套解决方案,目的是通过对文章主题的发现与跟踪,把各种分散的信息有效地进行汇集并组织线索,以提供给用户进行查阅等高层次服务,文本聚类方法是TDT重要组成部分。网络热点话题发现[10-11]是从各种网络源信息中发现某段时间内各个领域发生的引起人们较大关注的话题,发现并监控热点话题有助于让大众知晓某段时间内的社会焦点。网络舆情[12]具有内容多元、主体主导、群体极化和虚实互动等特征,容易导致群体性事件的产生。及时地发现社会舆情,为政府监管部门制定相关政策提供理论依据,对提高虚拟社会管理水平具有重要意义。
2基于LDA的网络舆情事件热点感知方法
网络舆情事件热点感知的本质就是文本集自动聚类技术,发现内部隐藏主题。热点发现往往采用这4个模型[13]:布尔模型、向量空间模型、概率模型、语言模型。布尔模型采用两个文档共现的索引项,通常作为聚类算法的辅助工具。向量空间模型将文章以向量形式表示,文章相似性采用向量之间的距离,权值通常采用TF-IDF,两篇文章共现词越多,权重越大,相似距离越近,但容易丢掉文章的语义关联。概率模型使用概率构建主题模型,通过特定算法进行主题模型驱动,自动生成归类,非常适用在网络舆情信息源数据量大、主题模糊性高、事件个数不确定性的情况[14]。本文使用的LDA属于概率模型。
21网络舆情事件热点分析
网络舆情事件,一般属于敏感话题范畴,与广大人民群众的利益相关,即或者人们感兴趣的话题。因此一经发布,他的影响力和扩散力是不可估量的。大多数舆情事件都有这样的特征:速度传播快、影响力大、转发转载用户比较多。由于网络数据更新速度快,网络舆情热点事件生存周期更短,因此对网络资源的处理速度也需要与时俱进,时时更新,并挖掘数据背后隐藏的内容[15]。一般网络舆情事件以新闻形式出现,或由门户网站转发,因此它的关注度比较大。其热点往往以时间、地点、人物、事件的形式出现[16]。为了精准地发现热点,热点对应特征词的识别很重要。本文采用将事件的热点由若干特征词构成的序列方案,词与词之间的关系集合构成一个热点事件。
22网络舆情事件热点感知的LDA方法
221文本预处理
LDA采用词作为特征项,通常文本可以看成特证词的数组构成,因此进行文本聚类之前,首先采用特殊数据结构来构造特定的数据集。舆情事件热点系统分词子系统中采用ICTCLAS 2014版本,ICTCLAS(又称NLPIR汉语分词系统)主要功能包括中文分词;词性标注;命名实体识别;用户词典等功能。ICTCLAS 2014新增了微博分词、新词发现与关键词提取,而且效率高,分词速度快,准确率好。由于ICTCLAS采用持续共享模式,便于通过调用API进行二次开发。ICTCLAS的API功能强大,可以去除标点符号,引入用户词典进行特定分词,进行新词的提取等任务。因此本研究只需建立一个过滤词表进行常用词过滤,形成网络舆情特征数据集,并且可以降低文本特征的维数,提高文本处理速度。
222文本特征抽取
分词过滤之后,剩下的就是文本的核心数据,但是并不是所有单词都能准确反应文本信息、时间、地点、人物、事件等不同时期不同热点具有不同侧重点。我们不能肯定地说文本中的某一个单词就能100%表征这篇文档,只能说这个单词能以某种程度来“表征”[17]这篇文档,这个程度具体衡量的标准就是概率。概率越大,说明这个单词越能表征这篇文档;反之则越不能表征这篇文档,当概率小到一个阀值(人为设定)的时候,这个单词就可以舍弃了,通过此方法可以适当降低文本特征维数。
(1)主题概率化分析
LDA是一个3层贝叶斯概率模型,采用主题生成模型。它是在传统的聚类算法文本——词分布引入主题空间,形成3层架构,认为文本是有很多主题构成的,且各主题之间都有一定的概率。 文档到主题服从Dirichlet分布,主题到词服从多项式分布 。一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语[18],一篇文章3层贝叶斯结构(隐含主题)模型示意图如图1。
图1文档3层贝叶斯结构模型示意图因此如果我们要生成一篇文档,它里面的每个词语出现的概率为:
文档序列概率化表示:D={d1,d2,d3,…,dn};
主题序列概率化表示:T={t1,t2,t3,…,tn};
单词序列概率化表示:W={w1,w2,w3,…,wn},P{WjDt}=P{WjTj}P{TjDt}。
LDA对主题的混合权重θ进了Dirichlet先验,用一个超参数α来产生参数θ,即参数的参数。
(2)主题词抽取
基于LDA主题模型,是利用统计学的知识,分析文档集内部信息,将文本映射到基于隐含主题的特征空间[19]。对于每一篇文档,从主题分布中抽取一个网络舆情主题,从被抽取的主题所对应的单词分布中抽取一个主题词,重复上述过程直至遍历文档中的每一个单词。这就是推理演化前期的准备工作,提供迭代的数据。
(3)推理演化
主题模型的初始化
输入:文档——主题分布概率;单词——主题分布概率
迭代推理:更新主题和估计参数,直至收敛
对于任意文本:基于主题模型中参数Beta以及文档——主题分布;endprint
计算该文档中每个单词在主题上的分布;
基于LDA模型参数Alpha和单词——主题分布;
计算文档的主题分布
输出:优化的LDA主题模型Beta和Alpha参数
完成LDA主题模型的参数推演
(4)中间产品
经过推理演化,生成文本——主题概率分布和主题——单词概率分布产品,他们都是迭代收敛的最终结果,以矩阵形式存在,包含主题概率的详细信息。
(5)聚类结果
聚类的产品属于矩阵,可以按照矩阵处理算法和相关的对应关系,将主题、文本、单词概率分布有机的整合起来,形成最终的聚类结果[20]。文本文件按主题分类归并以文件夹形式存放,并且对应的文件夹包含特定的主题文件,包含相应的单个类的准确率和总准确率。
3原型系统与实验
31基于LDA的网络舆情事件热点感知原型系统
原型系统采用java语言开发,使用Eclipse集成开发环境设计并且实现热点感知系统,系统流程如图2所示。
图2基于LDA的网络舆情事件热点感知原型系统
本系统借助LDA开源架构进行二次开发,实现热点的感知具有较高的准确率。
32实验设计与结果
321实验环境
CPU,Intel双核15GMHz以上;内存2G;硬盘320G;操作系统Windows Xp sp2以上。编程语言Java;集成开发平台Eclipse;开源工具ictclas 2014分词系统。
322实验数据
新浪中文新闻文本分类语料,包括环境、计算机、交通、教育等十大类别的27 816条网页文本。
323实验结果
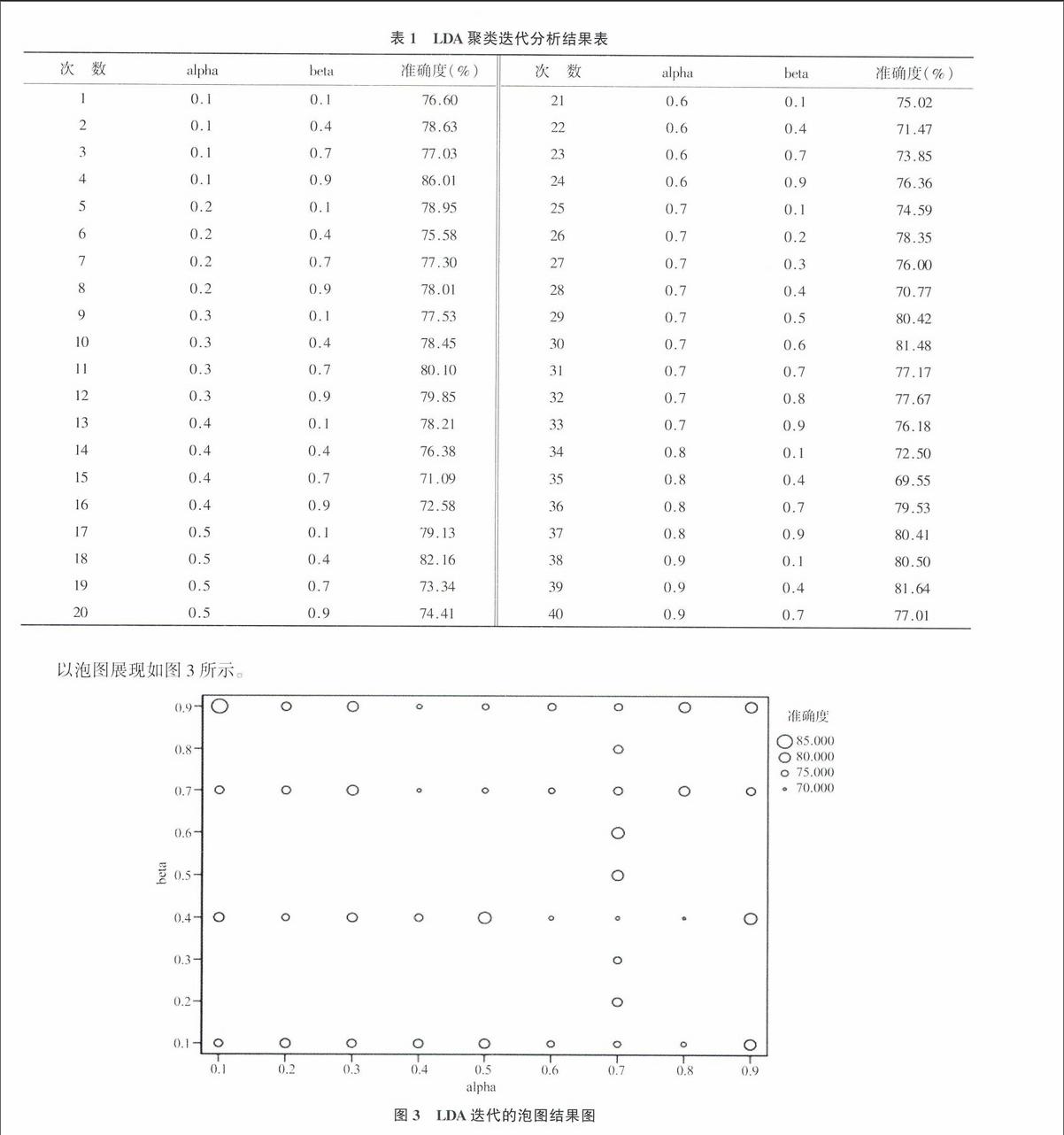
LDA中文聚类测试数据,同时均迭代40次,结果如表1所示。
K-means聚类测试结果,同时均迭代10次,结果如图4所示。
33实验结果分析
LDA聚类算法利用主题模型的特性,在传统机械统计词频的基础上加入了文本的深层语义知识,从而让聚类过程更加精准,降低错误率。通过实验笔者发现聚类算法需要基于文本的主题分布,事先了解主题向量的维度,准确率才会达到更高。作为测试数据,已知Topic number是个准确的常量,通过测试Alpha,Beta两个参数的变化,可知LDA基于语义算法效率有所提升。而且发现准确率的分布图4K-means迭代结果图
呈现不确定性和随机性,这是由于采用贝叶斯概率统计方法所决定的。Alpha,Beta之间没有直接关系,通过分析得知01~09分布效果最好,至少在70%。
而传统的k-means聚类算法的初始点选择不稳定,是随机选取的,这就引起聚类结果的不稳定。VSM模型仅利用词频建立向量,同样也会丢失部分语义信息,通过实验可以看出在面对新闻语料长文本中丢失的信息量很大,导致准确率较低,最低在20%。
4结语
本文将LDA主题模型引入网络舆情文本聚类领域,性能和效果都优于传统K-means算法。文本聚类主要在文本建模、文本相似度计算以及聚簇描述3个方面。LDA能够比较精准提炼并且发现主题。文本相似度计算可以尝试将传统VSM模型与LDA主题模型进行结合,使用连续性方式或非连续性方式,建立多个文本特征空间,增强文本的向量表示,从而提高文本聚类的质量。在网络舆情热点发现领域,为了进一步提高准确率,今后考虑使用外部语义资源库,尝试引入本体语义知识。
参考文献
[1]Blei David M.,Ng Andrew Y.,Jordan Michael I.,Lafferty John.Latent Dirichlet Allocation[J].Journal of Machine Learning Research,2003,3(4):993-1022.
[2]范云满,马建霞.利用LDA的领域新兴主题探测技术综述[J].现代图书情报技术,2012,(12):58-65.
[3]单斌,李芳.基于LDA话题演化研究方法综述[J].中文信息学报,2010,24(6):43-49.
[4]唐晓波,王洪艳.基于潜在狄利克雷分配模型的微博主题演化分析[J].情报学报,2013,32(3):281-287.
[5]胡勇军,江嘉欣,常会友.基于LDA高频词扩展的中文短文本分类[J].现代图书情报技术,2013,(6):42-48.
[6]阮光册.基于LDA的网络评论主题发现研究[J].情报杂志,2014,33(3):161-164.
[7]刘振鹿,王大玲,冯时,等.一种基于LDA的潜在语义区划分及Web文档聚类算法[J].中文信息学报,2011,25(1):60-65.
[8]林萍,黄卫东.基于LDA模型的网络突发事件话题演化路径研究[J].情报科学,2014,32(10):20-23.
[9]Huang,B.,Yang,Y.,Mahmood,A.,& Wang,H..Microblog topic detection based on LDA model and single-pass clustering[J].In Rough Sets and Current Trends in Computing.Springer Berlin Heidelberg,2012:166-171.
[10]李青,朱恒民,杨东超.微博网络中舆情话题传播演化模型[J].现代图书情报技术,2013,(12):74-80.
[11]浦娇华,朱恒民,刘凯.基于动态网络的微博舆论观点演化模型研究[J].情报杂志,2014,33(8):168-172.endprint
[12]唐晓波,宋承伟.基于复杂网络的微博舆情分析[J].情报学报,2012,31(11):1153-1162.
[13]胡吉明,陈果.基于动态LDA主题模型的内容主题挖掘与演化[J].图书情报工作,2014,58(2):138-142.
[14]Chen,Y.,Amiri,H.,Li,Z.,& Chua,TS..Emerging topic detection for organizations from microblogs[C].In Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval,ACM,2013:43-52.
[15]唐晓波,向坤.基于LDA模型和微博热度的热点挖掘[J].图书情报工作,2014,58(5):58-63.
[16]王勇,肖诗斌,郭?秀,等.中文微博突发事件检测研究[J].现代图书情报技术,2013,(2):57-62.
[17]Efron,M..Information search and retrieval in microblogs[J].Journal of the American Society for Information Science and Technology,2011,62(6):996-1008.
[18]Vosecky,J.,Jiang,D.,Leung,KWT.,& Ng,W..Dynamic multi-faceted topic discovery in twitter[C].In Proceedings of the 22nd ACM international conference on Conference on information & knowledge management,ACM,2013:879-884.
[19]Damak,F.,Pinel-Sauvagnat,K.,Boughanem,M.,& Cabanac,G..Effectiveness of State-of-the-art Features for Microblog Search[C].In Proceedings of the 28th Annual ACM Symposium on Applied Computing,ACM,2013:914-919.
[20]Miyanishi,T.,Seki,K.,& Uehara,K..Combining recency and topic-dependent temporal variation for microblog search[J].Advances in Information Retrieval,Lecture Notes in Computer Science,2013,7814:331-343.
(本文责任编辑:马卓)endprint
