低数据资源条件下基于结构信息共享的无切分维文文档识别字符建模
2015-12-13姜志威丁晓青彭良瑞刘长松
姜志威 丁晓青 彭良瑞 刘长松
1 引言
近年来,基于隐马尔可夫模型(Hidden Markov Model, HMM)的无切分文档识别方法逐渐成为主流,通过字符、文本行两级概率图模型的框架,能够有效解决困扰传统预切分文档识别方法的字符切分问题。不过,这种方法要求字符HMM建模有较高的准确度,并且需要使用大量的样本进行学习。对于维吾尔文(简称“维文”)文档而言,在上述两方面都面临着较大的困难。首先,维文字符形状变化有一百多种,并且粘连性和相似性很强,会为字符建模带来很大的困难;其次,尽管现有维文文档存量很大,但是制作样本的显现形式内容标注却非常费力、耗时。尤其是在面对一种新字体类型时,很难找到充足且有标注的同类样本来训练新模型。所以,如何解决好低数据资源条件下的字符建模问题,实现利用少量样本来建立高性能的识别系统,对当前的无切分维文文档识别领域具有迫切的需求和重要的意义。
尽管低数据资源建模的问题在语音识别领域已经有一定的研究成果[1,2],但是在无切分文字识别领域却刚刚起步。以往的研究工作中,HMM 模型优化和低数据资源建模通常被作为两个独立的问题进行研究。前者可以通过HMM状态结构优化来提高字符建模的准确度[3,4],而后者则主要采用HMM自适应的方法,通过少量新样本调整已有的通用模型来解决[57]-。但是,字符图像是一种结构性很强的2维信号,字符HMM状态是描述其结构的基本单元。所以,即使是在低数据资源的条件下,也应当充分考虑状态结构带来的影响。文献[8,9]以法文文档识别为背景,提出将HMM状态结构优化方法与模型自适应方法相结合,用以提高自适应模型对新样本的识别性能。该方法需要使用少量带有切分标注的样本进行模型自适应,以及大量无切分标注的样本用于状态结构优化。然而,在维文文档识别问题中,适应集样本规模通常都很小,而且具有粘连性的维文文本行也很难给出明确的切分位置标注,所以该方法不能用于改善维文字符建模的问题。
不过,经过观察可以发现,常用维文字体间的差异主要是形状扭曲风格的不同,在整体结构上并没有像法文字体那样的剧烈变化。于是,本文提出一种基于结构信息共享的无切分维文文档识别字符建模方法,通过在自建样本和实际样本上的相关实验结果可以表明,该方法不仅可以提高HMM模型对字符结构的描述能力,还可以有效降低模型自适应训练对新样本的依赖程度,提高识别系统对新样本类型的识别性能。
2 HMM中的字符结构信息表达与提取
2.1 基于HMM的无切分文档识别方法的基本原理
基于HMM的无切分文档识别方法可以归纳为字符层和文本行层这两个层级。在字符层面,每种字符都用一个基元HMM模型描述。字符图像首先被狭长的滑动窗口进行分帧处理,得到一连串的观测序列{Ot: t = 1,2,… , T },它们被认为是一个随机过程序列{qt:t = 1 ,2,… ,T }的输出结果。而其中的 qt都来自于一个有限的集合{sj: j = 1 ,2,…, N },其构成元素 sj被称为HMM的“状态”,如图1所示。观测与状态之间的关系只能通过条件概率Pr(Ot|qt= sj)进行估计,本文采用混合高斯模型(Gaussian Mixture Model, GMM)来描述这一概率,如式(1)所示。其中,Mj为状态 sj观测的GMM混合分量数,cjm, μjm和Σjm分别为该GMM中第m个高斯分量的权重、均值向量和协方差矩阵。此外,状态之间在概率上构成一阶马尔科夫链,用起始概率πi=Pr(q1= si) 和转移概率 pij= P r(qt= sj|qt-1= si) 共同描述,其中 i, j = 1 ,2,… , N 。
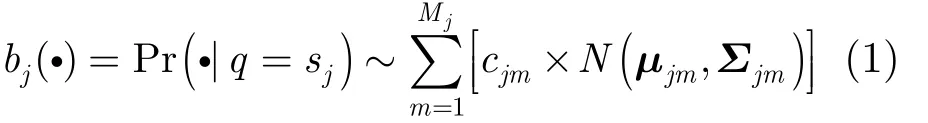

图 1 基于HMM的字符图像建模原理示意图
当文本行图像被用于模型训练时,由于字符模型之间的跳转可以被作为状态间的跳转对待,因此不需要字符间的切分标注信息,即可更新其包含的各个基元模型的参数,这种训练方法被称为嵌入式训练。而当文本行图像需要解码识别时,只要寻找到与该图像观测序列对准匹配最佳的字符基元模型组合,其组合内容就是文本行的识别结果,而模型间的跳转时刻,就对应着文本行图像中的字符切分位置。
2.2 状态的物理意义与字符结构信息的提取
HMM 作为一种概率图模型,其状态的物理意义是对一段图像观测序列进行有序聚类的结果,它们在全局上形成概率图模型的结构,用以描述字符的整体结构;在局部上实现概率图模型的统计平均,用以描述字符的区域变化风格。为了使每个状态都被有效用于描述稳定的局部字符结构观测,避免产生冗余的状态,状态自身需要具有典型性;同时,为了降低状态在与观测序列对准匹配时所产生的误差,保证模型对字符图像进行准确的编码和解码,状态之间也需要具有鉴别性。于是,根据上述两条性质,就可以设计出相应的状态优化方法,使得HMM 能够准确地提取出字符图像观测序列中的结构信息。
状态的典型性可以采用信息熵的形式估计状态活跃度来评价[10],如式(2)所示,其中 H ( p ) = -p lg p ,α, β和γ是和为1的归一化因子。由于描述复杂字符结构的 HMM 通常采用自底向上的状态优化算法,即逐步减少状态数量,所以状态冗余的模型中会存在信息熵过小的非典型状态。于是,可以根据信息论中的最大熵原理,从模型中将信息熵过小的状态去除,即可完成状态的典型性优化。

状态间的鉴别性可以采用分布的KL(Kullback-Leibler)散度来衡量。但由于GMM的KL散度从理论上不具有可计算的解析形式,这里采用文献[11]中的方法,先估计出此距离的一个紧上界,如式(3)所示。其中,f和g为空间中的两个具有相同高斯分量数m的GMM 分布,a和b分别为它们的高斯分量权重;()iβ为两个GMM高斯分量间的映射关系,并要求在此映射关系下,所有高斯分量对之间的距离之和最小。然后,根据相邻状态间的距离估计和判断阈值,就可以确定哪些状态需要融合。另外,还要对最终状态数的上、下界限进行控制,以便模型能具有更合理的结构[12],并且采用文献[8]中的方法来融合相似的相邻状态。

另外,在实际的训练中,为了提高模型准确程度,GMM 高斯分量的产生通常采用自顶向下的方法,即单高斯分布的状态交替进行参数更新和高斯分裂,直至达到预定的GMM分量数。因此,上述状态优化方法可以跟随GMM的分裂过程进行,用于在每一轮参数优化之前,寻找更加准确合理的模型结构和参数,避免参数估计陷入局部极值的风险[13],提高模型对字符结构信息的描述能力。
3 低数据资源条件下基于结构信息共享的字符建模方法
3.1 HMM自适应与最大后验估计方法
HMM 自适应主要研究模型特化问题,目的是在训练样本不足条件下,使一个已有的通用模型能更好地适用于单一识别任务。模型自适应的思路主要有两种,一种是“微调”通用模型的参数,使其符合适应集样本的统计特性,如最大后验估计方法(Maximum A Posteriori, MAP)[5];另一种是假定目标模型参数与通用模型参数间存在线性变换关系,通过估计这个变换的参数,使变换后的模型适用于适应集样本的识别,如最大似然线性回归方法[6]。由于本文主要工作是研究模型参数的估计,所以这里只对MAP方法进行分析。
MAP方法以最大化 Bayes理论导出的模型后验概率作为计算准则。以状态的均值向量自适应为例,其更新公式如式(4)所示,是一个适应集样本最大似然估计μMLE与原始模型参数μori之间的线性插值结果。其中,τ为预先给定的学习速率,{ Ot:t=1,2,… ,T}为适应集中的样本观测序列,ψ(t)为样本观测帧tO在t时刻由当前待更新状态生成的概率,MLEμ的计算如式(5)所示。

从式(4)中可以看出,如果适应集样本的规模越大,则自适应的结果MAPμ就会越倾向于适应集样本的最大似然估计MLEμ;反之,则会倾向于保持原有的通用模型参数oriμ,相当于没有进行参数调整。因此,MAP方法虽然具有较好的一致性和渐进性,但是在低数据资源条件下,对模型的特化性能提高效果十分有限,难以充分利用新样本中所包含的信息。
3.2 基于结构信息共享的字符建模方法
针对常用维文字体在字符的整体结构上一致性较高、在变化风格上差异性较大的特点,可以采用先共享通用训练样本的字符结构信息,向这些样本“借数据”,再利用Bootstrap原理学习少量适应集样本字符变化风格,向这些样本“要数据”的策略,使得模型最大似然估计对样本的依赖性得到降低,这就是本文所提方法的主要思路。该方法的流程框图如图2所示,上方的圆边矩形表示训练所采用的样本,下方的矩形表示训练所得的HMM模型;另外,中间5个带编号的箭头表示流程中的5个操作步骤,其中①②③为准备步骤,④⑤为新样本学习步骤。下面将会逐一对各个步骤进行说明。
为了准确地向通用样本“借数据”,需要确定字符结构共享的时机,既要让模型从通用样本中充分提取出结构信息,又要避免模型在通用样本上过度特化(步骤①)。在上一节所述的字符结构信息提取过程中,由于高斯数增长的初期,大量冗余状态因缺乏典型性或鉴别性而被去除或合并,所以状态数将会骤减,模型状态结构也迅速向相应字符结构的统计特性靠近。当高斯数增长到一定程度后,各个状态已具有充分的典型性和鉴别性,所以状态数将不再变化,各个状态也开始对字符结构的统计特性进行精细描述,使模型逐步特化于当前的训练样本。因此,字符结构共享时机应当选择从通用样本提取字符结构信息的过程中,所有模型的结构变化刚刚趋于稳定的时刻。此时,将会得到一个低高斯数的基础模型。
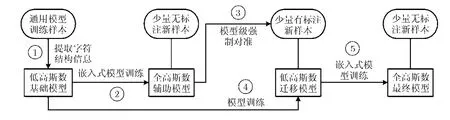
图 2 低数据资源条件下基于结构信息共享的字符建模方法流程图
为了高效地向适应集样本“要数据”,需要生成适应集样本的切分标注。这些标注信息能够使文本行图像样本转化为字符图像样本,帮助模型向新样本的字符变化风格进行迁移。对于切分标注的生成问题,可以采用 Bootstrap方法来解决[14]。首先,基于前文所得到的低高斯数基础模型,用适应集样本直接训练得到一个全高斯数的辅助模型(步骤②)。然后,用该模型对适应集样本进行模型级强制对准(步骤③),即可获得这些样本的切分标注信息。
完成上述准备步骤后,即可采用经典的Baum-Welch算法,在逐个模型上进行参数的最大似然估计,完成字符变化风格的迁移学习(步骤④),其原理如下所述。先来分析该算法中样本观测 Ot在t时刻由状态 sj生成的概率表达式,如式(6)所示。其中,αi(t) 和 βi(t ) 分别表示t时刻观测处于状态 sj的前向概率和后向概率。由于式(6)的分母仅用于结果归一化,所以在观测与状态进行合理对准匹配的情况下, ψj(t ) 的结果将主要取决于分子中 bj( Ot) 这一项。如果观测 Ot服从状态 sj当前的概率分布,则ψj(t)的计算结果会趋向于1;反之,则会趋向于0。因此,这个过程相当于以基础模型的状态为中心,对适应集样本的观测序列进行有序聚类,并更新模型统计参数的过程。又因为基础模型中包含了通用样本的字符结构信息,各个字符模型对应的样本也能够被切分标注进行分离,所以步骤④仅使用少量的适应集样本,就可以实现基础模型对新样本字符变化风格的迁移学习,得到一个迁移模型。

最后,按照经典的HMM嵌入式训练方法,再对迁移模型交替进行多次参数最大似然估计和GMM 高斯分裂操作[15],直到模型的高斯数达到预设值为止(步骤⑤),就可以得到适用于新样本类型的全高斯数最终模型。由于在前一个步骤中,得到的迁移模型已经偏向于适应集样本,因此这里可以直接使用无切分标注的适应集样本进行模型嵌入式训练。
4 实验与结果分析
本文实验主要使用剑桥大学公开的 HTK[16]工具包完成,其它原创性工作通过C代码实现,并由Perl脚本控制执行流程。实验中,基于文献中已有的28维特征提取方法[17],通过一阶帧间差分扩展获得56维特征向量,并采用直线型HMM进行建模。结果评价方面,利用系统识别性能间接衡量各模型准确度的思路,采用 HTK中相对严格的字符识别准确率ACC作为评价指标。该指标通过动态规划算法对齐识别结果与真值内容,然后计算正确识别字符数量与插入错误数量之差,占全部真值字符数量的百分比,并且ACC指标也等价于常用的美国国家标准与技术研究院所提出的词识别错误率WER指标,因为二者之和恒定为1。
4.1 实验相关数据集介绍
本文实验共需要两类数据样本,一类是规模较大、包含多种类型的通用集样本,用于训练和测试通用模型,以及提取字符结构信息;另一类是规模较小、类型单一的适应集样本,用于训练和测试专用模型。
通用集样本方面,由于目前维文识别文献中主要采用的传统预切分识别方法,都是以单字符图像样本数据库为主,所以尚无统一的标准维吾尔文文档样本数据库。为此,本文专门制作了 THOCRUy360数据库,其内容来源于《塔里木》杂志社的官方网站[18]。选取的维文语料被整理为360页文档,用激光打印机印刷成ALKATIP的Basma, Kitab,Journal, Tor和UKIJ的Tuzb这5种常用字体,如图3的前5行所示,并根据维文文档字号偏小的特点,选择10号字印刷。然后,再用扫描仪以300 dpi的分辨率进行扫描,经过阈值化和行切分处理后,每种字体就可以得到 7887张文本行图像,包含264583个字符。

图3 本文实验所用的维文文本行样本字体类型示例
适应集样本方面,直接使用真实的《中共中央关于制定国民经济和社会发展第十二个五年规划的建议》(维文版)书籍扫描图像作为样本,如图 3的最后一行所示,并请维文专家给出相应的内容标注。从图中可以看出,实际书籍所采用的字体与通用集中的5种字体均不相同,主要体现在文本行图像的质量、字符连接紧凑度、笔画宽度、孔状结构尺度、某些字符形状等多个方面。该样本集包括 42页文档,采用与通用集样本相同的阈值化和行切分方法。按照文献[8]中的建议,仅选取正文的字体类型,而不考虑标题等极少的特殊字体。于是,最终的适应集样本共包含1075个文本行图像、55363个字符。
另外,本文实验样本数据覆盖维文字母105种、数字10种、各类标点符号14种,共129种字符基元。
4.2 通用样本的字符结构信息验证实验
本小节实验在通用集样本上进行,需要将5种字体的文本行样本在内容相同的前提下,随机按照70%(5523行,185349字符),15%(1182行,39622字符),15%(1182行,39612字符)的比例进行划分,分别作为训练集、验证集和测试集。
为了形象地说明字符结构信息提取原理,这里以单字体Basma识别系统下维文字符“NG”图像为例,将其观测序列进行状态强制对准,并在对应的图像中标记出状态跳转的位置,展示当前模型的状态分配情况。模型的起始状态数被设置为15,均为单高斯模型。由于状态数量冗余,所以经过初始化后,状态分配十分零碎。不过,每个状态都被用于描述一种明确的字符局部结构,如图 4(a)。经过状态典型性优化后,描述字符中间尖端部分的3个状态会被去除,仅留下必要的典型状态,如图4(b)。随后,状态鉴别性优化将模型精简为10个状态,它们彼此之间都具有明显的差异性,如图 4(c)。随着混合高斯数的增长,模型状态数也会进一步减小直至稳定。再经过嵌入式训练,最终模型的状态分配如图 4(d)所示。可见,HMM 状态中所包含的结构信息,既对应着2维字符图像所具有的局部结构,也符合状态是观测聚类的物理意义。
下面,本文将比较几个识别系统在5种字体测试集上的性能,它们分别是5种字体样本分别直接训练得到的“单字体基线系统”,5种字体样本混合后直接训练得到的“多字体基线系统”,以及采用本文基于字符结构信息的模型优化方法所得到“单字体优化系统”和“多字体优化系统”,相关测试结果如表1所示。

表 1 不同识别系统在通用样本测试集上的识别准确率评价结果(%)
对于两个基线识别系统,它们均采用状态数一致的HMM建立基元模型,并通过在验证集上的系统识别性能来选择最佳的状态数。通过结果比较可以看出,前者使用单一类型的训练样本能保证稳定的识别性能,但是未经优化的HMM模型结构会使其对字符的描述能力受到限制;而后者虽然出现模型偏离个别字体的情况,如Basma, Tor,但在其他字体上的识别性能却会出现反超,如Kitab, Journal,Tuzb,这说明不同字体间确实存在某种可以被共享的信息,但直接混合多字体样本的方法是不能有效利用这种信息的。
对于两个优化识别系统,它们均采用了本文方法对模型结构和参数进行联合优化。由于多字体优化系统能够共享5种字体之间的共性字符结构,提高字符模型在多字体样本融合中的准确性,因而其识别性能要优于多字体基线系统,甚至是单字体基线系统。这不仅说明了多字体样本之间所共享的正是共性的字符结构信息,也验证了本文提取字符结构信息方法的有效性。另外,单字体优化系统表现出了最好的识别性能,这也说明在训练样本充足的情况下,还是应当优先考虑建立单字体的专用识别系统。

图4 单字体识别系统中维文字符“NG”在不同模型下的状态强制对准结果
此外,为了更加直观地说明不同字体之间共享字符结构信息的效果,下面再次以维文字符“NG”为例,在多字体基线系统和优化系统下,分别对 5种字体的该字符图像进行状态强制对准。可以看出,在基线系统中,状态与观测的对准匹配关系相对杂乱,而且冗余程度较高,如图 5(a)所示。而在优化系统中,虽然不同字体的图像观测存在变化风格上的差异,但各个状态都能对准匹配到相似的字符结构上,如图5(b)所示。因此,本文方法的“借数据”思路能为HMM自适应训练,提供更加丰富且稳健的字符结构先验知识。
4.3 低数据资源条件下的字符建模实验
本小节实验需要将适应集样本划分为 4个子集,~分别对应书籍1~10页(253行,~13116字符),1120页(266行,13594字符),2130页(257行,13321字符),31~42页(299行,15332字符)的内容。4.3.1不同样本规模下字符建模方法对比实验 为了研究低资源样本对字符建模方法的影响,从前3个子集中选取1个、2个和3个子集,它们的规模分别约为通用模型训练集的1/14, 1/7, 1/5。其中,随机抽取90%的文本行样本作为训练集,剩下的10%作为验证集。然后,将4号子集作为测试集,用于比较不同识别系统的性能,实验结果如表2所示。

图5 5种字体的维文字符“NG”在不同模型下的状态强制对准结果
第1, 2列结果来自于新字体的基线系统和优化系统,它们只利用适应集中的新样本来训练新模型。由于样本规模很小,所以性能都不是很高。但经过字符结构优化的系统,其识别性能要明显优于基线系统。第3, 4列结果来自于上一小节中多字体的基线系统和优化系统。由于它们并没有使用新字体的样本训练过,所以其识别性能降低至80%左右。第5, 6列结果对应的系统,是用MAP方法对两个多字体系统进行自适应训练所得到的。由于优化系统的模型能更准确地描述字符结构,所以自适应优化系统的识别性能也要高于自适应基线系统4%~5%。而第7列结果来自于本文方法所得到的系统,其识别性能在3种设置下均超过90%,高于采用MAP方法自适应所得到的两个系统,再次说明字符结构信息对于字符建模的重要作用。
4.3.2 模型迁移学习性能交叉验证实验 为了更加准确地评估上述几种识别系统的性能,这里对表 2中第3种数据集设置进行交叉验证实验,即轮流将4个子集中的1个作为测试集,其余3个子集则用于训练和验证,实验结果如表3所示。

表 2 不同样本规模下各系统对适应集测试样本的识别准确率评价结果(%)

表 3 各系统对适应集测试样本的识别准确率交叉验证结果(%)
通过横向比较可以看出,本文方法所得系统的识别性能最高,在测试集上的平均识别准确率为95.05%,能够实现对新字体类型的高性能识别。同时,相比于新字体优化系统、自适应优化系统,它在平均识别准确率上也有 1.55%和 6.24%的提高,即识别错误率相对降低 23.85%和 55.76%,证明了本文方法的有效性。
5 结束语
低数据资源条件下的字符建模问题,是当前无切分文档识别领域中的一个重要研究方向,与实际应用中的样本规模限制密切相关。因此,本文提出了一种向相对稳定的字符结构“借数据”、向低资源样本的切分标注估计结果“要数据”的方法。通过对自制样本和实际书籍样本的识别测试实验可以说明,该方法能够有效解决低数据资源条件下,维文字符建模所存在的关键问题,对提高无切分维文文档识别系统在新样本类型的适用性上具有重要意义。同时,我们后续也会尝试将该方法应用于其他民族文字的识别任务中。
[1] 钱彦旻. 低数据资源条件下的语音识别技术新方法研究[D].[博士论文], 清华大学, 2012: 67-85.Qian Yan-min. Study on new speech recognition technology under low data resource conditions[D]. [Ph.D. dissertation],Tsinghua University, 2012: 67-85.
[2] 钱彦旻, 刘加. 低数据资源条件下基于优化的数据选择策略的无监督语音识别声学建模[J]. 清华大学学报(自然科学版),2013, 53(7): 1001-1004.Qian Yan-min and Liu Jia. Optimized data selection strategy based unsupervised acoustic modeling for low data resource speech recognition[J]. Journal of Tsinghua University(Science and Technology), 2013, 53(7): 1001-1004.
[3] Gunter S and Bunke H. Optimizing the number of states,training iterations and Gaussians in an HMM-based handwritten word recognizer[C]. 7th International Conference on Document Analysis and Recognition (ICDAR), Edinburgh,Scotland, UK, 2003: 472-476.
[4] Geiger J, Schenk J, Wallhoff F, et al.. Optimizing the number of states for HMM-based on-line handwritten whiteboard recognition[C]. 12th International Conference on Frontiers in Handwriting Recognition (ICFHR), Kolkata, India, 2010:107-112.
[5] Qing H, Chan C, and Chin-Hui L. Bayesian learning of the SCHMM parameters for speech recognition[C]. IEEE 19th International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Adelaide, USA, 1994, I: 221-224.
[6] Leggetter C J and Woodland P C. Maximum likelihood linear regression for speaker adaptation of continuous density hidden Markov models[J]. Computer Speech & Language,1995, 9(2): 171-185.
[7] 刘杰. 序列模型中的迁移学习研究[D]. [博士论文], 南开大学计算机与控制工程学院, 2008: 66-89.Liu Jie. Research on transfer learning on sequence model[D].[Ph.D. dissertation], Nankai University, 2008: 66-89.
[8] Ait-Mohand K, Paquet T, and Ragot N. Combining structure and parameter adaptation of HMMs for printed text recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(9): 1716-1732.
[9] Ait-Mohand K, Paquet T, Ragot N, et al.. Structure adaptation of HMM applied to OCR[C]. 20th International Conference on Pattern Recognition (ICPR), Istanbul, Turkey,2010: 2877-2880.
[10] Jiang Zhi-wei, Ding Xiao-qing, Peng Liang-rui, et al..Analyzing the information entropy of states to optimize the number of states in an HMM-based off-line handwritten Arabic word recognizer[C]. 21st International Conference on Pattern Recognition, Tsukuba, Japan, 2012: 697-700.
[11] 王欢良, 韩纪庆, 郑铁然. 高斯混合分布之间K-L散度的近似计算[J]. 自动化学报, 2008, 34(5): 529-534.Wang Huan-liang, Han Ji-qing, and Zheng Tie-ran.Approximation of Kullback-Leibler divergence between two Gaussian mixture distributions[J]. Acta Automatica Sinica,2008, 34(5): 529-534.
[12] Bicego M, Murino V, and Figueiredo M A T. A sequential pruning strategy for the selection of the number of states in hidden Markov models[J]. Pattern Recognition Letters, 2003,24(9): 1395-1407.
[13] Seymore K, McCallum A, and Rosenfeld R. Learning hidden Markov model structure for information extraction[C].AAAI-99 Workshop on Machine Learning for Information Extraction, Orlando, USA, 1999: 37-42.
[14] Jiang Zhi-wei, Ding Xiao-qing, Peng Liang-rui, et al..Modified bootstrap approach with state number optimization for hidden Markov model estimation in small-size printed Arabic text-line recognition[C]. 10th International Conference on Machine Learning and Data Mining in Pattern Recognition, St. Petersburg, Russia, 2014: 437-441.
[15] Young S, Evermann G, Gales M, et al.. The HTK Book (for HTK Version 3.4)[M]. Cambridge, UK, Cambridge University Engineering Department, 2009: 97-147.
[16] Cambridge University Engineering Department. Hidden Markov Model Toolkit (HTK)[OL]. http://htk.eng.cam.ac.uk/.2014.
[17] Al-Hajj M R, Likforman-Sulem L, and Mokbel C. Combining slanted-frame classifiers for improved HMM-based Arabic handwriting recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(7): 1165-1177.
[18] Official website of magazine “Tarim”[OL]. http://www.tarimweb.com/index.html. 2014.
